第二部分:分散式資料
一個成功的技術,現實的優先順序必須高於公關,你可以糊弄別人,但糊弄不了自然規律。
—— 羅傑斯委員會報告(1986)
在本書的 第一部分 中,我們討論了資料系統的各個方面,但僅限於資料儲存在單臺機器上的情況。現在我們到了 第二部分,進入更高的層次,並提出一個問題:如果 多臺機器 參與資料的儲存和檢索,會發生什麼?
你可能會出於各種各樣的原因,希望將資料庫分佈到多臺機器上:
可伸縮性
如果你的資料量、讀取負載、寫入負載超出單臺機器的處理能力,可以將負載分散到多臺計算機上。
容錯 / 高可用性
如果你的應用需要在單臺機器(或多臺機器,網路或整個資料中心)出現故障的情況下仍然能繼續工作,則可使用多臺機器,以提供冗餘。一臺故障時,另一臺可以接管。
延遲
如果在世界各地都有使用者,你也許會考慮在全球範圍部署多個伺服器,從而每個使用者可以從地理上最近的資料中心獲取服務,避免了等待網路資料包穿越半個世界。
伸縮至更高的載荷
如果你需要的只是伸縮至更高的 載荷(load),最簡單的方法就是購買更強大的機器(有時稱為 垂直伸縮,即 vertical scaling,或 向上伸縮,即 scale up)。許多處理器,記憶體和磁碟可以在同一個作業系統下相互連線,快速的相互連線允許任意處理器訪問記憶體或磁碟的任意部分。在這種 共享記憶體架構(shared-memory architecture) 中,所有的元件都可以看作一臺單獨的機器 [^i]。
[^i]: 在大型機中,儘管任意處理器都可以訪問記憶體的任意部分,但總有一些記憶體區域與一些處理器更接近(稱為 非均勻記憶體訪問(nonuniform memory access, NUMA)【1】)。 為了有效利用這種架構特性,需要對處理進行細分,以便每個處理器主要訪問臨近的記憶體,這意味著即使表面上看起來只有一臺機器在執行,分割槽(partitioning) 仍然是必要的。
共享記憶體方法的問題在於,成本增長速度快於線性增長:一臺有著雙倍處理器數量,雙倍記憶體大小,雙倍磁碟容量的機器,通常成本會遠遠超過原來的兩倍。而且可能因為存在瓶頸,並不足以處理雙倍的載荷。
共享記憶體架構可以提供有限的容錯能力,高階機器可以使用熱插拔的元件(不關機更換磁碟,記憶體模組,甚至處理器)—— 但它必然囿於單個地理位置的桎梏。
另一種方法是 共享磁碟架構(shared-disk architecture),它使用多臺具有獨立處理器和記憶體的機器,但將資料儲存在機器之間共享的磁碟陣列上,這些磁碟透過快速網路連線 [^ii]。這種架構用於某些資料倉庫,但競爭和鎖定的開銷限制了共享磁碟方法的可伸縮性【2】。
[^ii]: 網路附屬儲存(Network Attached Storage, NAS),或 儲存區網路(Storage Area Network, SAN)
無共享架構
相比之下,無共享架構【3】(shared-nothing architecture,有時被稱為 水平伸縮,即 horizontal scaling,或 向外伸縮,即 scaling out)已經相當普及。在這種架構中,執行資料庫軟體的每臺機器 / 虛擬機器都稱為 節點(node)。每個節點只使用各自的處理器,記憶體和磁碟。節點之間的任何協調,都是在軟體層面使用傳統網路實現的。
無共享系統不需要使用特殊的硬體,所以你可以用任意機器 —— 比如價效比最好的機器。你也許可以跨多個地理區域分佈資料從而減少使用者延遲,或者在損失一整個資料中心的情況下倖免於難。隨著雲端虛擬機器部署的出現,即使是小公司,現在無需 Google 級別的運維,也可以實現異地分散式架構。
在這一部分裡,我們將重點放在無共享架構上。它不見得是所有場景的最佳選擇,但它是最需要你謹慎從事的架構。如果你的資料分佈在多個節點上,你需要意識到這樣一個分散式系統中約束和權衡 —— 資料庫並不能魔術般地把這些東西隱藏起來。
雖然分散式無共享架構有許多優點,但它通常也會給應用帶來額外的複雜度,有時也會限制你可用資料模型的表達力。在某些情況下,一個簡單的單執行緒程式可以比一個擁有超過 100 個 CPU 核的叢集表現得更好【4】。另一方面,無共享系統可以非常強大。接下來的幾章,將詳細討論分散式資料會帶來的問題。
複製 vs 分割槽
資料分佈在多個節點上有兩種常見的方式:
複製(Replication)
在幾個不同的節點上儲存資料的相同副本,可能放在不同的位置。 複製提供了冗餘:如果一些節點不可用,剩餘的節點仍然可以提供資料服務。 複製也有助於改善效能。 第五章 將討論複製。
分割槽 (Partitioning)
將一個大型資料庫拆分成較小的子集(稱為 分割槽,即 partitions),從而不同的分割槽可以指派給不同的 節點(nodes,亦稱 分片,即 sharding)。 第六章 將討論分割槽。
複製和分割槽是不同的機制,但它們經常同時使用。如 圖 II-1 所示。
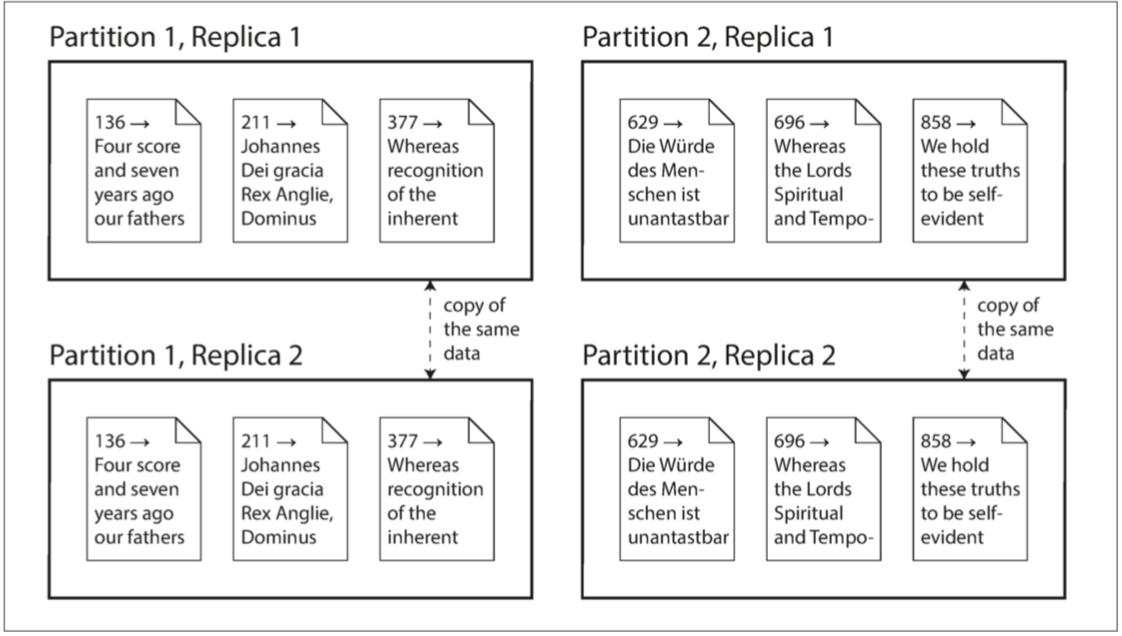
圖 II-1 一個數據庫切分為兩個分割槽,每個分割槽都有兩個副本
理解了這些概念,就可以開始討論在分散式系統中需要做出的困難抉擇。第七章 將討論 事務 (Transaction),這對於瞭解資料系統中可能出現的各種問題,以及我們可以做些什麼很有幫助。第八章 和 第九章 將討論分散式系統的根本侷限性。
在本書的 第三部分 中,將討論如何將多個(可能是分散式的)資料儲存整合為一個更大的系統,以滿足複雜的應用需求。 但首先,我們來聊聊分散式的資料。
索引
參考文獻
- Ulrich Drepper: “What Every Programmer Should Know About Memory,” akka‐dia.org, November 21, 2007.
- Ben Stopford: “Shared Nothing vs. Shared Disk Architectures: An Independent View,” benstopford.com, November 24, 2009.
- Michael Stonebraker: “The Case for Shared Nothing,” IEEE Database EngineeringBulletin, volume 9, number 1, pages 4–9, March 1986.
- Frank McSherry, Michael Isard, and Derek G. Murray: “Scalability! But at What COST?,” at 15th USENIX Workshop on Hot Topics in Operating Systems (HotOS),May 2015.
| 上一章 | 目錄 | 下一章 |
|---|---|---|
| 第四章:編碼與演化 | 設計資料密集型應用 | 第五章:複製 |

若有收获,就点个赞吧
0 人点赞
