Variable
格式:
var``变量名``变量类型
- 变量需要
声明后才可使用 - 同作用域中不可重复声明
- 变量声明后
必须使用// 声明一个var v1 string// 批量声明var (v2 stringv3 int)
类型推导
省略类型声明时,编译器会根据类型等号右侧的值来推导变量来进行初始化
var v1 = "Daived"
短变量声明
在
函数内部可以使用更简略的:=方式声明并初始化变量
v1 := "Dong"
匿名变量
可用于函数或方法返回多个值时
忽略赋值
func foo() (int,string){return 10,"Tom"}func main(){age,_ := foo()fmt.Println(age)}
Const
格式:
const``常量名=值
- 常量在声明时必须赋值
- 声明后值不可改变
// 声明一个const PI = 3.1415// 声明多个const (E = 2.7111BASE_URL="http://www.baidu.com/")
常量计数器: iota
- 仅可在常量表达式中使用
- 常用于定义枚举常量
- 在
const关键字出现时重置为0, 每新增一行将使iota计数一次
const (January = iota // 0February // 1, 可忽略声明iota_ // 忽略本次赋值March // 3)const May = iota // 0
Base Type
整型
有符号
| int8 | -128 ~ 127 |
|---|---|
| int16 | -32768 ~ 32767 |
| int32 | -21亿 ~ 21亿, rune是int32 的别名 |
| int64 | -2^63 ~ 2^63-1 |
无符号
| uint8 | 0 ~ 255, byte是uint8 的别名 |
|---|---|
| uint16 | 0 ~ 65535 |
| uint32 | 0 ~ 42亿 |
| uint64 |
浮点型
golang支持两种浮点类型:
float32和float64
float32
- 最大范围约为
3.4e38 -
float64
最大范围约为
1.8e308-
布尔值
使用
bool声明 仅有
true真和false假两值- 无法参数数值运算,并且无法参与类型转换
- 零值为
false```go var b1 bool
b2 := true
<a name="JEFAR"></a>### 字符串> 使用`string`声明```govar s1 strings1 = "hello world"s2 := "hello"
字符串转义符
回车``单双引号``制表符等
| \r | 回车符 |
|---|---|
| \n | 换行符 |
| \t | 制表符 |
| \‘ | 单引号 |
| \“ | 双引号 |
| \\ | 反斜杠 |
s1 := `selectnamefromuser_infowhereuser_id = ?`fmt.Println(s1)
常用字符串操作
var s1 = "hello world"// 获取长度fmt.Printf("s1 len: %s \n",s1)// 拼接字符串fmt.Println("hello " + "world")fmt.Printf("%s %s \n","hello","world")// 分割字符串fmt.Printf("%+v \n",strings.Split(s1,""))// 判断是否包含if strings.Contains(s1, "hello") {fmt.Println("hello within s1")}// 前缀判断if strings.HasPrefix(s1, "hello") {fmt.Println("s1 begins with hello.")}// 后缀判断if strings.HasSuffix(s1, "world") {fmt.Println("s1 ends with hello.")}// 字符串出现位置fmt.Println(strings.Index(s1, "w"))// 连接字符串fmt.Println(strings.Join([]string{"hello","world"}," "))
byte & rune
Go中的字符
uint8类型,或者叫byte型,代表了ASCII码字符rune类型,代表UTF-8字符
当处理中文、日文或者其他符合字符时,需要用
rune类型,rune实际是个int32
// 遍历字符串func traversalString() {s := "你可真棒"// bytefor i := 0; i < len(s); i++ {fmt.Printf("%v(%c)", s[i], s[i])}fmt.Println("")// runefor _, r := range s {fmt.Printf("%v(%c) ", r, r)}}// 输出// 228(ä)189(½)160( )229(å)143(�)175(¯)231(ç)156(�)159(�)230(æ)163(£)146(�)// 20320(你) 21487(可) 30495(真) 26834(棒)
// 修改字符串func changeStr() {// bytes1 := "hello"byteS1 := []byte(s1) // string强制转[]bytebyteS1[0] = 'H'fmt.Println(string(byteS1))// runes2 := "你好"runeS2 := []rune(s2) // string强制转[]runeruneS2[0] = '谁'fmt.Println(string(runeS2))}
Array
初始化表达式:
var arr [n]T{v1,v2}定义:数据类型的固定长度序列 注意点:
- 数组长度必须是常量,一旦定义,长度不可改变
- 长度是数组的组成部分,同类型不同长度数组,为不同类型,例如:
var arr0 [4]int和var arr1 [10]int为不同类型数组- 通过下标访问,初始为
0- 下标访问越界后会出发
panic- 指针数组:
[n]*T, 数组指针:*[n]T
// 初始化数组var arr0 [5]int = [5]int{1, 2, 3, 4, 5}var arr1 = [5]int{1, 2, 3, 4, 5}var arr2 = [...]int{1, 2, 3, 4, 5} // 使用...将自动计算数组长度(仅可在初始化时使用)var arr3 = [5]string{0: "hello", 1: "world"} // 通过下标初始化, 未初始化为零值var arr4 = [...]struct {name stringage int}{{name: "Dong",age: 18,},{name: "Xi",age: 1000,},}fmt.Printf("%v\n%v\n%v\n%v\n%+v\n", arr0, arr1, arr2, arr3, arr4)
函数传值
值类型,赋值和传参会复制整个数组,并不是指针
- 尽量使用
slice替代array pointer传递,以确保最大内存共享
func noChange(arr [3]int) {// 值传递, 原变量不会改变arr[0] = 10fmt.Printf("noChange arr: %v %p\n", arr, &arr)}func change(arr *[3]int) {arr[0] = 10fmt.Printf("change arr: %v %p\n", arr, arr)}func main() {arr := [3]int{1, 2, 3}arr0 := arrfmt.Printf("arr: %v %p\n", arr, &arr)fmt.Printf("arr0: %v %p\n", arr0, &arr0)noChange(arr) // 数组值传递, 不改变原始变量change(&arr) // 指针传递, 改变原始变量}
官方也建议使用slice用来替换array pointer

遍历数组的方式
for range: 遍历数组获取下标和值for i:通过数组长度获取下标,然后获取值
for i, v := range arr {fmt.Printf("%d:%d\n", i, v)}for i := 0; i < len(arr); i++ {fmt.Printf("%d:%d\n", i, arr[i])}
Slice
表达式:
var slice []T``slice := arr[0:2]定义:切片是数组的一个引用,通过内部指针和相关属性引用数组片段 注意点:
- 切片长度可改变,因此切片为
可变数组cap内置函数可以求出切片最大扩张容量
初始化切片
// 声明切片var s1 []int// 初始化数组arr0 := [3]int{1,2,3}// 初始化切片(零容量)// :=s2 := []int{}// make(T,Len), 省略Cap时,Cap=Lens3 := make([]int,0)// make(T,Len,Cap)s4 := make([]int,0,0)// 从数组切片s5 := arr0[0:3]// 数组开始到指定下标s6 := arr0[:1] // 等于 arr0[0:1]// 数组执行下标到结尾s7 := arr0[2:] // 等于 arr0[2:3]// 数组开始到结尾s8 := arr0[:] // 等于 arr0[0:3]
通过append函数添加元素
slice := make([]int, 0)slice = append(slice, 1)fmt.Println(slice)
通过make创建切片
在切片中添加元素超出容量时,自动扩容容量的一倍( 超出原 slice.cap 限制,就会重新分配底层数组) 注意:
- 尽量
一次性分配最够大的空间,避免内存分配和数据复制的开销- 及时释放不再使用的slice对象,避免持有过期数组,造成GC无法回收
sm1 := make([]int, 9, 10)fmt.Printf("sm1 len:%d cap:%d\n", len(sm1), cap(sm1))sm1 = append(sm1, []int{1, 2, 3}...)fmt.Printf("sm1 len:%d cap:%d\n", len(sm1), cap(sm1))sm1 = append(sm1, []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16}...)fmt.Printf("sm1 len:%d cap:%d\n", len(sm1), cap(sm1))// sm1 len:9 cap:10// sm1 len:12 cap:20// sm1 len:28 cap:40
内存布局
切片来自数组时,引用数组一个片段,并指向同一内存地址 以下是切片的内存布局↓
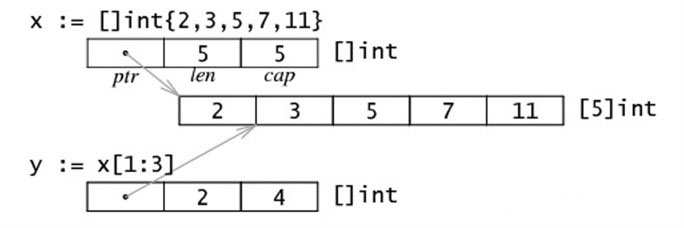
data := [...]int{1,2,3}// 从数组创建切片s1 := data[0:1]// 修改切片s1[0] = 10fmt.Printf("s1: %v",s1)// 引用数组同时改变fmt.Printf("data: %v",data)
直接修改struct slice成员属性值
s := []struct{name string}{{name: "daived"}}s[0].name = "Dong"fmt.Println(s)
切片拷贝
copy函数可在两个slice间复制数据,并且两个slice可以指向同一数组- 应及时将数据copy到较小的slice中,以便释放内存
s1 := []int{1,2,3}s2 := make([]int,0,3)s3 := []int{2,3,4}copy(s1,s2)copy(s2,s3)fmt.Printf("s1:%v %d %d\n",s1,len(s1),cap(s1))fmt.Printf("s2:%v %d %d\n",s2,len(s2),cap(s2))fmt.Printf("s3:%v %d %d\n",s3,len(s3),cap(s3))
Map
表达式:
map[KeyType]ValueType定义: map是一种无序的基于key-value的数据结构,引用类型,必须初始化后才能使用
m := map[string]string{}fmt.Println(m)// 可通过make创建// make(map[KeyType]ValueType,Cap)m1 := make(map[string]string,10)fmt.Println(m1)// 声明时初始化m2 := map[string]string{"name":"dong"}
判断某个key是否存在
value, ok := map[key]
m := map[string]string{"name":"dong"}// v: ValueType ok: Boolv,ok := m["name"]if ok {fmt.Println(v)}
根据key删除键值对
delete(map,key)
m := map[string]string{"name": "dong", "age": "18"}delete(m,"name")v,ok := m["name"]if !ok {fmt.Println("key name not found")}
遍历
m := map[string]string{"name": "dong", "age": "18"}for k, v := range m {fmt.Printf("k: %s v:%s \n", k, v)}
排序后顺序遍历
顺序遍历,因为
map本身是无序的,所以需要借用array进行排序操作后再按照key进行取值操作 生产环境中可以考虑使用struct array来替待map
m := map[string]string{"1": "dong","2": "xixi","3": "nan","4": "bei",}// 默认遍历是无序的for k, v := range m {fmt.Printf("key: %s value: %s\n", k, v)}// 获取map key切片keys := make([]string, 0)for k, _ := range m {keys = append(keys, k)}// 排序keyssort.Strings(keys)// 排序后遍历key获取valuefor _, k := range keys {fmt.Printf("key: %s value: %s\n", k, m[k])}
Pointer
表达式:
&取地址*根据地址取值
- Go语言中函数为
值拷贝,当想要修改变量值时,可以创建一个指向该变量的指针变量。- 传递数据使用指针则无需拷贝数据。
类型指针不能进行偏移和运算
指针地址
指针地址是物理内存中标识,用于操作内存中的变量
取变量指针地址:
ptr := &v
s := "hello"ptr := &sfmt.Printf("s: %v\n", s)fmt.Printf("s ptr: %p\n", ptr)
取指针变量值:
v := *ptr
s := "hello"ptr := &sfmt.Printf("ptr value: %v\n", *ptr)
指针类型
带有指针地址的变量类型
//指针取值a := 10b := &a // 取变量a的地址,将指针保存到b中c := *b // 指针取值(根据指针去内存取值)fmt.Printf("type of b:%T\n", b)fmt.Printf("type of c:%T\n", c)fmt.Printf("value of c:%v\n", c)s
创建指针类型,指针类型变量不可用
var关键字创建,否则会创建出空指针,而触发panic
s := new(string)fmt.Println(s)
函数传递指针变量
func change(arr *[3]string) {arr[0] = "hello"}func main() {arr := [3]string{"1", "2", "3"}fmt.Printf("arr: %v\n", arr)change(&arr)fmt.Printf("arr: %v\n", arr)}
Type
自定义类型
表达式:
type MyType T
// 创建自定义类型Numtype Num intfunc main() {var n Numfmt.Printf("n type is %T\n",n)}
类型别名
表达式:
type MyTypeAlias = T于自定义类型差异:
- 类型别名仅会在代码阶段存在(编译完成后不会存在
// 创建自定义类型Numtype Num int// 创建类型别名type NumT = Numfunc main() {var n1 Numvar n2 NumT// 可使用T(v)的方式转换类型if NumT(n1) == n2 {fmt.Println("n1 equla n2")}fmt.Printf("n1 type is %T\n", n1) // n2 type is main.Numfmt.Printf("n2 type is %T\n", n2) // n2 type is main.Num}
Struct
表达式:
type TypeName struct { Filed1 Type Filed2 Type }定义: 自定义数据类型,用于封装多个基础数据类型,本质上是一种聚合型的数据类型,可实现面向对象
type User struct {Name stringAge intCity,Address string // 可将字段写在一行(不建议使用,会导致tag使用不便)}
实例化
表达式:
var 结构体实例 结构体类型
type User struct {Name stringAge int}func main() {var u Useru.Name = "dong"u.Age = 18fmt.Printf("%+v\n", u)}
匿名字段
又称嵌入字段
type Student struct {ClassRoom string}type User struct {*StudentName stringAge int}func main() {u := User{&Student{"one class"}, "dong", 10}fmt.Println(u)fmt.Println(u.Student)}
匿名结构体
临时数据结构场景下使用
var u struct{Name string age int8}u.Name = "dong"u.Age = 18fmt.Printf("%+v\n", u)
指针类型结构体
通过内置方法
new创建 可直接访问结构体成员,底层实现(*u).name = "dong"语法糖
u := new(User)u.Name = "dong"u.Age = 18fmt.Printf("%+v\n", u)
键值对初始化
可选择字段初始化
u := User{Name: "dong",Age: 18,}fmt.Printf("u : %#v", u)
值列表初始化
不能同键值对初始化同用 初始值填写顺序必须与结构体声明字段顺序一致 必须初始化所有字段
u := User{"dong",18,}fmt.Printf("u : %#v", u)
构造函数
go 本身没有构造函数,可以模拟实现
func NewUser() *User{return &User{"dong",18,}}func main() {u := NewUser()fmt.Printf("%+v\n",u)}
方法与接收者
表达式:
func (接收者变量 接收者类型) 方法名(参数列表) (返回参数) {函数体}方法定义: 用作特定类型变量的函数 接收者(Receiver)定义: 特定类型变量,类似于其他语言中的this或者self
- 接收者名首字符建议小写(官方)
- 接收者可以是指针或者非指针类型(这里实例化类型可以和接收者类型不同,使用上与函数参数类似)
type user struct {name stringage int8}func NewUser() *user{return &User{"dong",18,}}func (u user) format() string {return fmt.Sprintf("user name is %s, age is %d",u.name,u.age)}func main() {u := NewUser()fmt.Println(u.format())}
指针类型接收者
用于实际修改变量属性 什么时候应该使用指针类型接收者:
- 接收者值拷贝代价比较大的对象
- 需要修改接收者值
- 保证一致性,如果某个方法使用了指针接收者,其他方法也应使用
type user struct {name stringage int8}func NewUser() *user {return &user{"dong",18,}}func (u *user) change() string {u.age = 100return fmt.Sprintf("user name is %s, age is %d", u.name, u.age)}func main() {u := NewUser()fmt.Println(u.change())}
接收者可以是任意类型
type TableName string// RS哈希取模分表func (t TableName) SubTable(id string) string {var b uint32 = 378551;var a uint32 = 63689;var hash uint32 = 0;for i := 0; i < len(id); i++ {hash = hash * a + uint32(str[i]);a *= b;}v := crc32.ChecksumIEEE([]byte(id))return fmt.Sprintf("%s_%d",t, hash&0x7FFFFFFF%20,)}func main() {tb := TableName("user")for i := 0; i < 100; i++ {fmt.Println(tb.SubTable(strconv.Itoa(i)))}}
Flow
if … else if … else
条件语句 通过指定一个或者多个
条件,并测试是否为true来决定是否执行指定语句
语法
if 布尔表达式1 {// 布尔表达式1为true时运行// 执行完成后跳出判断} else if 布尔表达式2 {// 布尔表达式2为true时运行} else {// 以上表达式均为false时运行}
示例
var name stringvar age intfmt.Printf("Please input your name and age: ")// 扫描来自标准输入文本, 使用空格分隔值fmt.Scanln(&name, &age)fmt.Printf("your name is %s\n", name)fmt.Printf("your age is %d\n", age)
switch … case … default
匹配不同值来执行不同动作,每个case语句是唯一的,从上至下逐一测试,知道匹配配置 未匹配到,执行defalut分支
语法
switch var1 {case val1:// do someingcase val2:// do someingdefault:// do default someing}
示例
var level intSTART:fmt.Printf("Please input your level: ")// 扫描来自标准输入文本, 使用空格分隔值fmt.Scanln(&level)switch level {case 1:fmt.Println("王者")case 2:fmt.Println("青铜")case 3:fmt.Println("白银")default:println("Please input 1...3!")goto START}// 同时测试多个值switch level {case 1:fmt.Println("王者")case 2:fmt.Println("青铜")case 3,4,5,6:fmt.Println("白银")default:println("Please input 1...6!")goto START}// 判断interface变量类型
select … case … default
同switch类似,不同的是随机执行一个可执行的case,如果没有case可执行会阻塞,直到case可执行 常用于等待协程执行,通过channel通知进行下一步处理
语法
- case语句必须是
channel操作(读 or 写) - default总是可用的
- 如果有
多个case可以运行,select会随机公平选取一个执行,其他不会执行select { // 不停的在这里检测case <-chanl : // 检测有没有数据可以读// 如果chanl成功读取到数据,则进行该case处理语句case chan2 <- 1 : // 检测有没有可以写// 如果成功向chan2写入数据,则进行该case处理语句// 假如没有default,那么在以上两个条件都不成立的情况下,就会在此阻塞// 一般default会不写在里面,select中的default子句总是可运行的,因为会很消耗CPU资源default:// 如果以上都没有符合条件,那么则进行default处理流程// 如果没有default,则阻塞程序}
示例-default分支
var c1 chan int // nilvar i1 intselect {case i1 = <-c1:fmt.Printf("i1 value is %d", i1)case c1 <- 1:fmt.Println("write to c1")default:fmt.Println("no communication")}
示例-case分支
var i1 intc1 := make(chan int, 1)go func() {c1 <- 1}()go func() {select {case i1 = <-c1:fmt.Printf("i1 value is %d", i1)case c1 <- 1:fmt.Println("write to c1")}}()time.Sleep(1 * time.Second)
示例-超时判断
func doSomeing(c *chan int) {time.Sleep(2 * time.Second)*c <-}func main() {c := make(chan int)go doSomeing(&c)select {case i := <-c:fmt.Printf("i value is %d\n", i)case <-time.After(3 * time.Secsond):fmt.Println("doSomeing function timeout")}}
for
循环控制语句,可根据条件循环执行
for init; condition; post {}
init: 控制变量初始值 condition: 循环控制条件 post: 控制变量赋值,增量或减量
list := [3]int{1, 2, 3}for i := 0; i < len(list); i++ {fmt.Printf("list[%d] = %d \n", i, list[i])}
for condition {}
根据控制条件循环
list := [3]int{1,2,3}i := 0for i<len(list) {fmt.Printf("list[%d] = %d \n", i, list[i])i++}
for i,v := range array {}
结合
range遍历数组
list := [3]int{1,2,3}for i,v := range list {fmt.Printf("list[%d] = %d \n", i, v)}
for {}
无限循环
list := [3]int{1,2,3}i := 0for {if i >= len(list) {break}fmt.Printf("list[%d] = %d \n", i, list[i])i++}
range
类似迭代器,返回(索引,值) 或(键,值) 结合
for可对slice``map``array``string等进行迭代循环,格式如下
for key,value := range m {fmt.Printf("key: %s value",key,value)}
可使用_忽略不想要的返回值
list := []int{1,2,3}// 忽略indexfor _,v := range list {fmt.Println(v)}// 全部忽略 仅迭代for range list {fmt.Println("do someing")}
遍历map返回key和value
m := map[string]int{"a":1,"b":2}for k,v := range m {fmt.Printf("%s:%d\n",k,v)}
注意! range会复制值的副本指针,应使用for+index的方式
list := [3]int{1, 2, 3}newList := make([]*int, 3)for i, v := range list {newList[i] = &v}fmt.Println(*newList[0])fmt.Println(*newList[1])fmt.Println(*newList[2])
c := make(chan int, 5)wg := &sync.WaitGroup{}wg.Add(2)go func() {for i := 0; i < 5; i++ {c <- i}// 停止写入后,一定到关闭channel// 否则range 语句会一直执行close(c)wg.Done()}()go func() {for v := range c {fmt.Println(v)}wg.Done()}()wg.Wait()
goto & label
slice := []int{1, 2, 3}i := 0for {if i >= len(slice) {goto END}fmt.Println(slice[i])i++}END:fmt.Println("end")
break & continue
slice := []int{1, 2, 3}for i, v := range slice {if i == 1 {continue}fmt.Println(v)}
slice := []int{1, 2, 3}for i, v := range slice {if i == 1 {break}fmt.Println(v)}
Function
函数传参
// 单参数func DoSomeing(n int) {...}// 多参数func DoSomeing(n int,s string) {...}// 多参数简写func DoSomeing(n1,n2 int,s string) {...}// 参数列表func DoSomeing(n1 int, nums ...int) {fmt.Println(n1)fmt.Printf("%T\n", nums)}func main() {DoSomeing(1,2,3,4)}
函数返回值
// 单返回值func DoSomeing(n int) int {return n / 10}// 多返回值func DoSomeing(n int) (string,int){return "取余10",n/10}// 隐式返回(命令返回参数)func DoSomeing(n int) (num int){num = n/10return}// 局部变量遮蔽命名返回参数(需要显示返回)func DoSomeing(n int) (num int){{var num = n/10return}}
匿名函数
不用定义函数名,可作为
结构体字段或在channel中传输,有很大的灵活性
sumF := func(n1,n2 int) int{return n1 + n2}sumF(1,10)
以上是go中匿名函数的简单示例,可以在代码片段复用性低的情况下合理使用,增加代码可读性
type User struct {name stringlevel int // 岗位等级workYear int // 工资年限baseSalary int // 基础薪资bonusMethod func(w,b int) int}func main() {us := []User{{"Julia",1,3,20000}{"Daived",3,4,10000}}// 根据不同等级设置不同奖金发放方法// TODO: 思考更好的使用场景for _,u := range us {switch u.level {case 1:u.bonusMethod = func (w,b int) int {return w*3*b}case 2:u.bonusMethod = func (w,b int) int {return w*1.5*b}default:u.bonusMethod = func (w,b int) int {return w*b}}}}
通过给结构体字段设置匿名函数类型,可以灵活的切换计算逻辑,如上代码,可根据不同人群设置不同的计算方式
// 这里结合上个示例,使用go runtime、channel、sync.WaitGroup{}设置并发处理奖金bonusPool := struct{total int}// 互斥锁,防止并发安全问题l := sync.Mutex{}wg := sync.WaitGroup{}for _,u := range us {wg.Add(1)go func(){l.Lock()bonusPool.total = bonusPool.total + u.bonusMethod()l.Lock()wg.Done()}()}
有的时候我们并不想即时的处理代码片段,可以像上面代码一样(虽然不是很贴切)将他们放到channel中去处理
doFs := []func(x, y int) interface{}{func(x, y int) interface{} {return x + y},func(x, y int) interface{} {return x * y},func(x, y int) interface{} {return x / y},}for _, doF := range doFs {fmt.Println(doF(1, 10))}
现在我们有一堆任务,但是他们执行的方法各不相同,可以将它们放到一个数组或者切片中等待处理
闭包
function a(){var i=0;function b(){console.log(++i);}return b;}
js中的闭包和go中的类似,只不过是基于嵌套函数实现,子函数可以引用局部变量并改变值,但go并不支持这样
def a():i = 1def b():i = i + 1print(i)return bx = a()x()x()x()
py中的闭包是对引用变量的保护,不可直接修改引用变量的值,所以在执行以上代码时会抛出UnboundLocalError
func a() func() {i := 1b := func() {fmt.Println(i)fmt.Printf("让我们看下每次调用的指针: %p\n", &i)i++}return b}func main() {c := a()// 调用c函数时因为闭包导致函数内i变量逃逸(重复引用)c()c()c()c()// 直接调用a函数,未触发闭包a()// 新函数变量会产生新的闭包,闭包之间互不影响d := a()d()}
以上代码是go中闭包的实现,在很多场景下闭包可以减少新变量的开销
// 迭代会使得i解引用,使得到值不再使用,所以会正常输出for i := 0; i < 3; i++ {fn := func() {fmt.Println(&i)}fn()}
var dummy [3]intvar f func()// 因为在循环结束时i = 3for i := 0; i < len(dummy); i++ {println(i)f = func() {println(i)}}f()// 以上循环可以理解为以下代码for i := 0; i < len(dummy){println(i)f = func() {println(i)}i++}f()
递归函数
运行的过程中调用自己
func Accumulate(n int) int {n++if n < 100 {n = Accumulate(n)}return}
func Factorial(n int) int {if n <= 1 {return 1}return n * Factorial(n-1)}
延迟调用
defer关键字,使用方法类似go关键字 作用是函数return前执行 结合闭包可以进行资源释放
func demo(n int) {num := 10 * ndefer fmt.Print(num)num = num / 3}
f,err := os.Open("./demo.txt")if err != nil {return}defer f.Close()
m := make(map[string]interface{})l := sync.Mutex{}wg := sync.WaitGroup{}for i := 0; i < 10; i++ {wg.Add(1)go func(i int) {l.Lock()defer l.Unlock()m["num"] = idefer wg.Done()}(i)}wg.Wait()fmt.Println(m)
并发情况下通常会使用互斥锁来保证变量的安全性,很容易忘记及时解锁
ns := []int{1, 2, 3, 4, 5}for _, v := range ns {defer func() {fmt.Println(v)}()}
以上代码片段同时涉及range defer``closure,通过range拷贝副本值到v, 这时defer调用的闭包函数内引用的变量v始终指向唯一副本变量,变量过程中副本变量的值会一直变化。
var n1 intdefer fmt.Printf("defer1 print: %d \n", n1)defer func() {fmt.Printf("defer2 print: %d \n", n1)}()defer func(n1 int) {fmt.Printf("defer3 print: %d \n", n1)}(n1)n1 += 10
defer在非闭包情况下不能获取最新的值
x := 0defer fmt.Println("a")defer fmt.Println("b")defer func() {fmt.Println(100 / x) // 触发异常,逐步向外层传递并终止进程gopanic()}()defer fmt.Println("d")
多个defer遵循FILO 次序(Fisrt In Last Out)先进后出的方式,遇到异常会跳出继续执行,最后抛出异常
var lock sync.Mutexfunc test() {lock.Lock()lock.Unlock()}func testDefer() {lock.Lock()defer lock.Unlock()}func main() {t1 := time.Now()for i := 0; i < 1000000000; i++ {test()}fmt.Printf("t1 use time: %v\n", time.Since(t1))t2 := time.Now()for i := 0; i < 1000000000; i++ {testDefer()}fmt.Printf("t2 use time: %v\n", time.Since(t2))}
使用defer性能竟然比平常要快,这里可能是go新版本编译器优化后的结果
func doSomeing() (i int) {i = 0defer func(){fmt.Println(i)}()return 2}
以上函数在return时会将i变量的值修改为2
func doSomeing() {var fc func() = nildefer fc()fmt.Println("test")}
在调用以上函数时,defer允许声明,然后我们会看到打印的test,结束函数时执行fc()触发空指针异常
f,err := os.Open("./demo.txt")if err != nil {fmt.Println(err.Error())}// defer f.close // panicif f != nil {defer f.close // Success}
以上代码片段在读取文件时,由于没有判断是否返回空指针,导致延迟关闭文件时触发异常,这很考验你的严谨性
func doSomeing() {f,_ := os.Open("./demo.txt")f.close()defer func() {if err := recover(); err != nil {fmt.Println(err)}}()}func main() {doSometing()fmt.Println("success")}
Panic
go语言中没有结构化异常(类似java中try catch),通过panic抛出异常,recover捕获异常 异常如未被捕获会终止下面代码运行
panic("my painc")fmt.Println("success")
以上函数由于触发异常success不被打印
defer func(){if err := recover(); err != nil{fmt.Printf("revover: %v\n",err)}}()panic("my panic")
panic不会被影响defer的执行,为了保证程序正常运行,必须手动捕获异常
panic("my panic")if err := recover(); err != nil{fmt.Printf("revover: %v\n",err)}
recover函数一定要声明在defer内,并在异常发生之前
panic("my panic")defer func(){if err := recover(); err != nil{fmt.Printf("revover: %v\n",err)}}()
以上代码中异常未被捕获,是因为延迟调用一定要在panic发生之前声明(有意识的在写代码前捕获异常,这很重要)
defer func(){func(){if err := recover(); err != nil{fmt.Printf("revover: %v\n",err)}}()}()panic("my panic")
recover只能在defer内使用,但是不能在defer内的匿名函数中使用
type User struct {name string}func(u User) info() {fmt.Printf("name : %s\n",u.name)}func main() {var u *User = nilu.info() // panic}
空指针是触发panic常见的情况,需常检查指针变量的零值或者空值,invalid memory address or nil pointer dereference
ch := make(chan int, 1)close(ch)ch <- 1
Channel通道关闭后,再写入时会出发异常send on closed channel
defer func() {fmt.Println(recover())}()defer func() {panic("defer panic")}()panic("my panic")
defer中的异常会被优先捕获
func test(x, y int) {var z intfunc() {defer func() {if err := recover(); err != nil {z = 0}}()z = x / y // x or y equal to zero, panic integer divide by zero}()fmt.Printf("x/y = %d \n", z)}func main() {test(1, 0)}
defer recover可以捕获函数中的异常,自然也可以捕获匿名函数,同时可以利用匿名函数变量引用的特性,去修复代码异常
func Try(fn func()) (catch string) {defer func(){if err := recover(); err !=nil {catch = err.(string)}}()fn()return}
通过匿名函数和recover的方式实现,recover返回的类型是接口类型,通过强制转换成string
Error
error类型可以描述函数的调用状态,同时可以使用errors包创建实现error接口的错误对象
func OpenFileTesting(filename string) error{if filename == "" {return errors.New("filename is require, and not null")}f,err := os.Open(filename)if err != nil {return errors.New(fmt.Sprintf("file open faild : %s",err.Error()))}defer f.close()return nil}
Method
Go中的没有OOP编程语言中Class声明方式,可以通过Method+Struct实现部分面向对象的特性
type User struct {Name stringAction string}func (u User) Do(){fmt.Printf("%s正在%s\n",u.Name,u.Action)}func main() {u := User{Name: "Dong",Action: "打篮球",}u.Do()}
// ...func (u *User) ChangeAction(s string) {u.Action = s}func main() {// ...u.ChangeAction("上班")}
type User struct {Name stringAction stringPerson}func (u User) Sleep() {fmt.Printf("User Sleep Method\n")}type Person struct {}func (Person) Sleep() {fmt.Printf("Person Sleep Method\n")}func main() {u := User{Name: "Dong",Action: "打篮球",}u.Sleep()}
type User struct {Name stringAction stringPerson}func (u User) Sleep() {fmt.Printf("User Method Sleep \n")}func (u *User) Eat() {fmt.Printf("User Method Eat \n")}
Interface

若有收获,就点个赞吧
0 人点赞
