https://www.bilibili.com/video/BV1qb4y1Q7db?p=8&spm_id_from=pageDriver
B树和B+树
https://www.cs.usfca.edu/~galles/visualization/BTree.html
度为3,则一个节点最多2个元素,向下可以有3个分支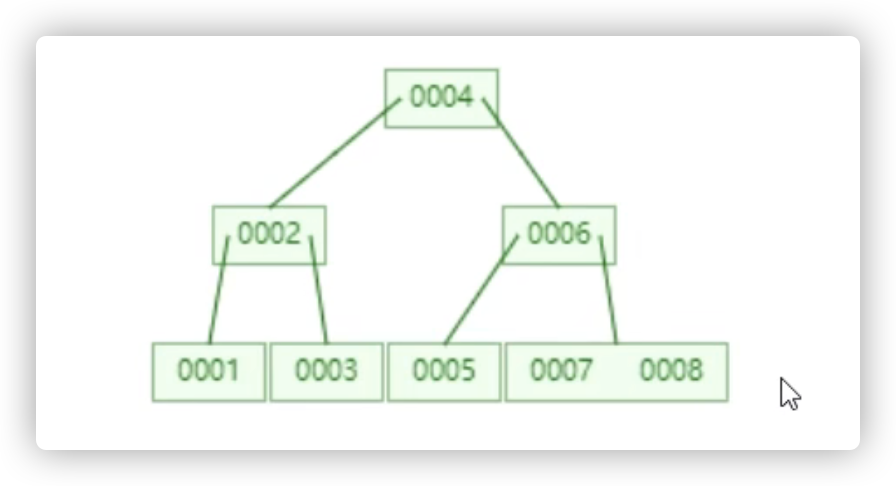
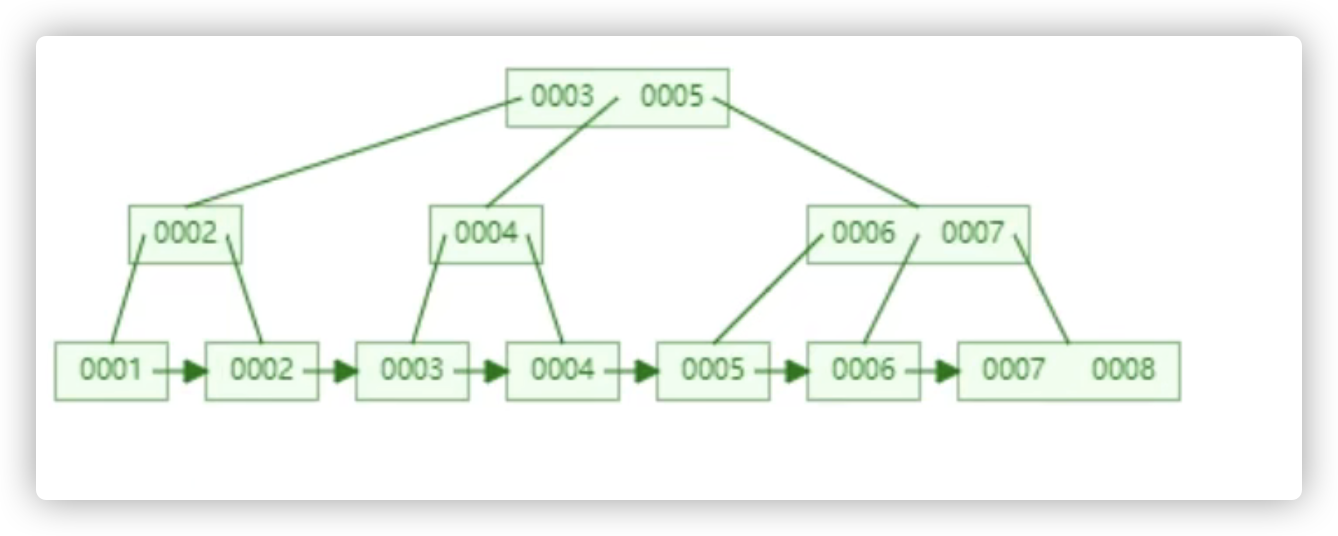
区别:
- B+树更宽
- B+树叶子节点有指针
- B+
- 数据有冗余
mysql的B+树是在B树的基础上改进,叶子节点的指针是双向的
https://dev.mysql.com/doc/internals/en/innodb-fil-header.html
innodb存储基本单位页结构
操作系统从磁盘读数据是按照一页读取的 一页最少等于4kb
show global status like 'Innodb_page_size';> 16384 = 16KB
页的作用就是mysql会一次性取16kb的数据到内存中,如果一条记录小于16KB,那么会取多条记录进入内存
页结构是逻辑结构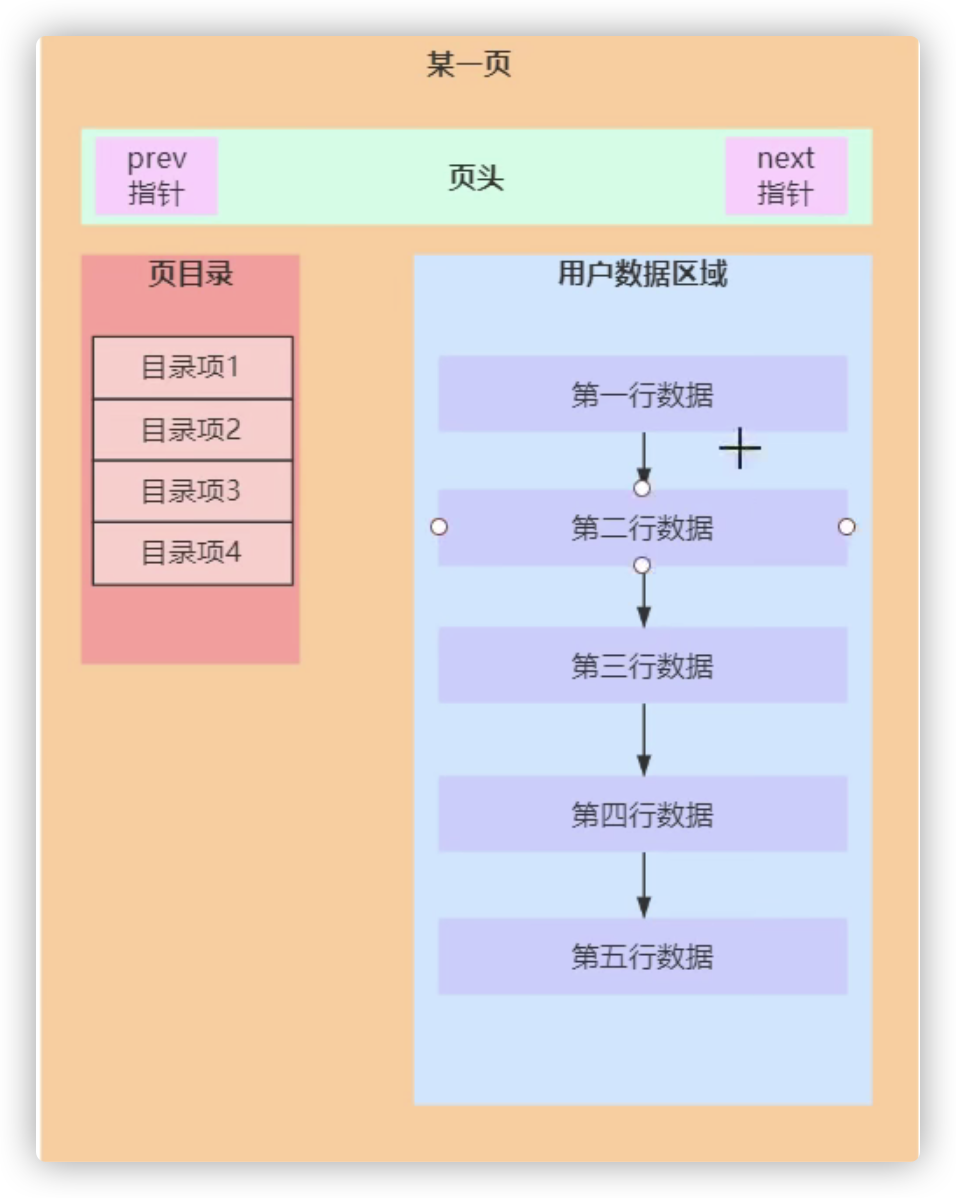
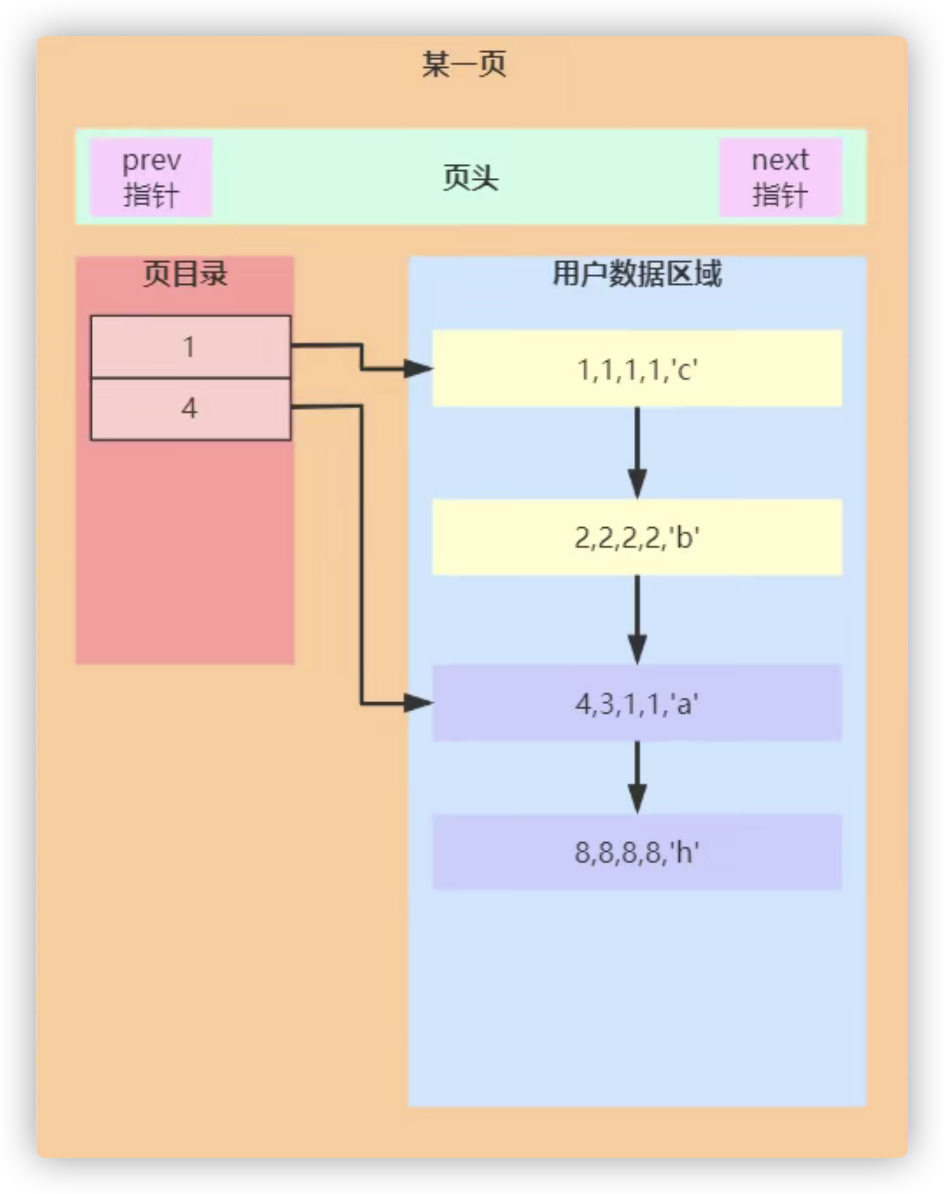
- 在插入数据的时候进行排序
- 用自增的插入好插入,不建议使用uuid
- 遍历链表慢,使用页目录优化,对数据进行分组,页目录,存储分组中的最小主键和指向该数据的指针
- 一个目录项10B,指针6B,主键int 4B
- 页目录的查找使用二分查找
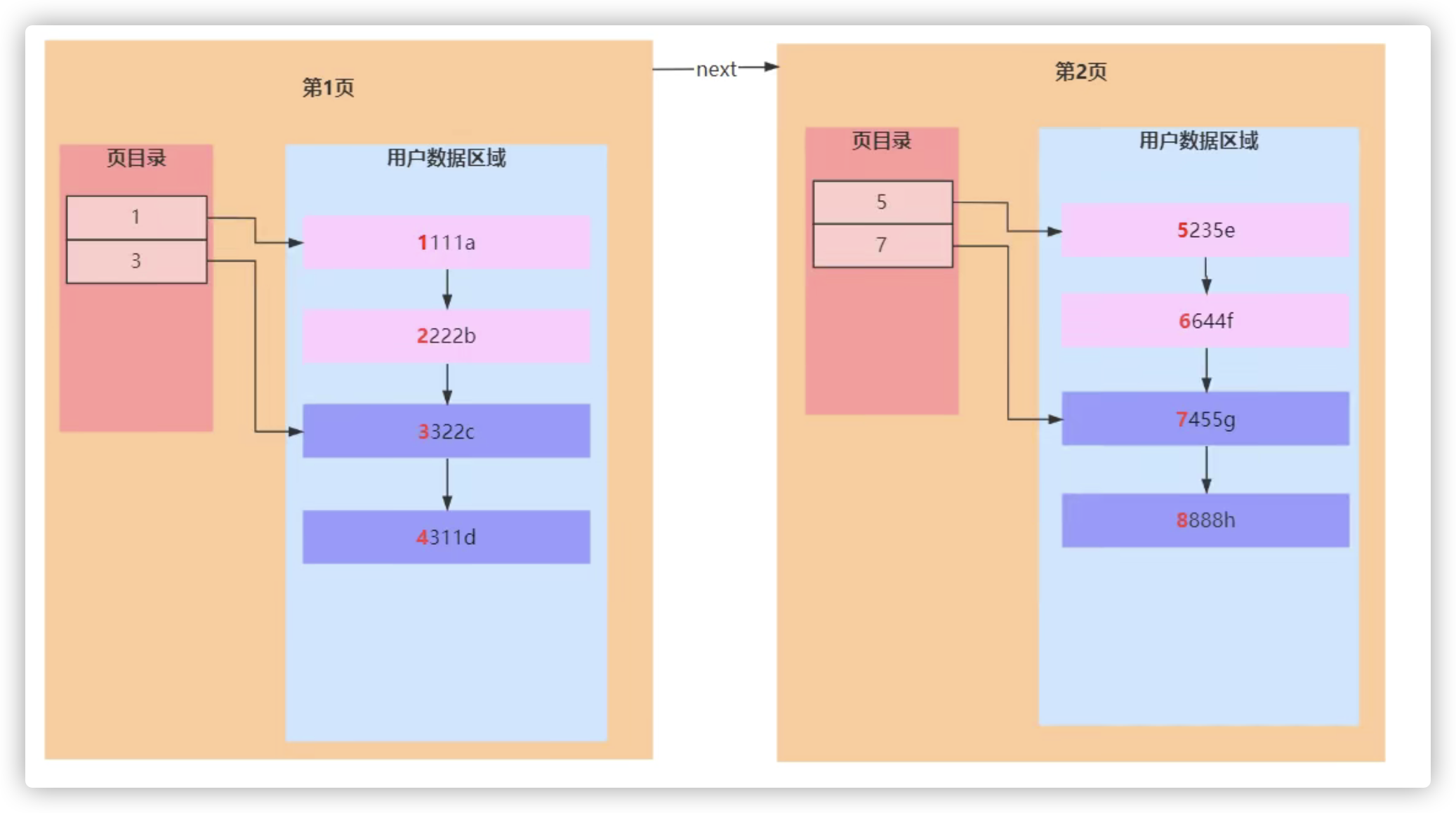
- 索引页和数据页
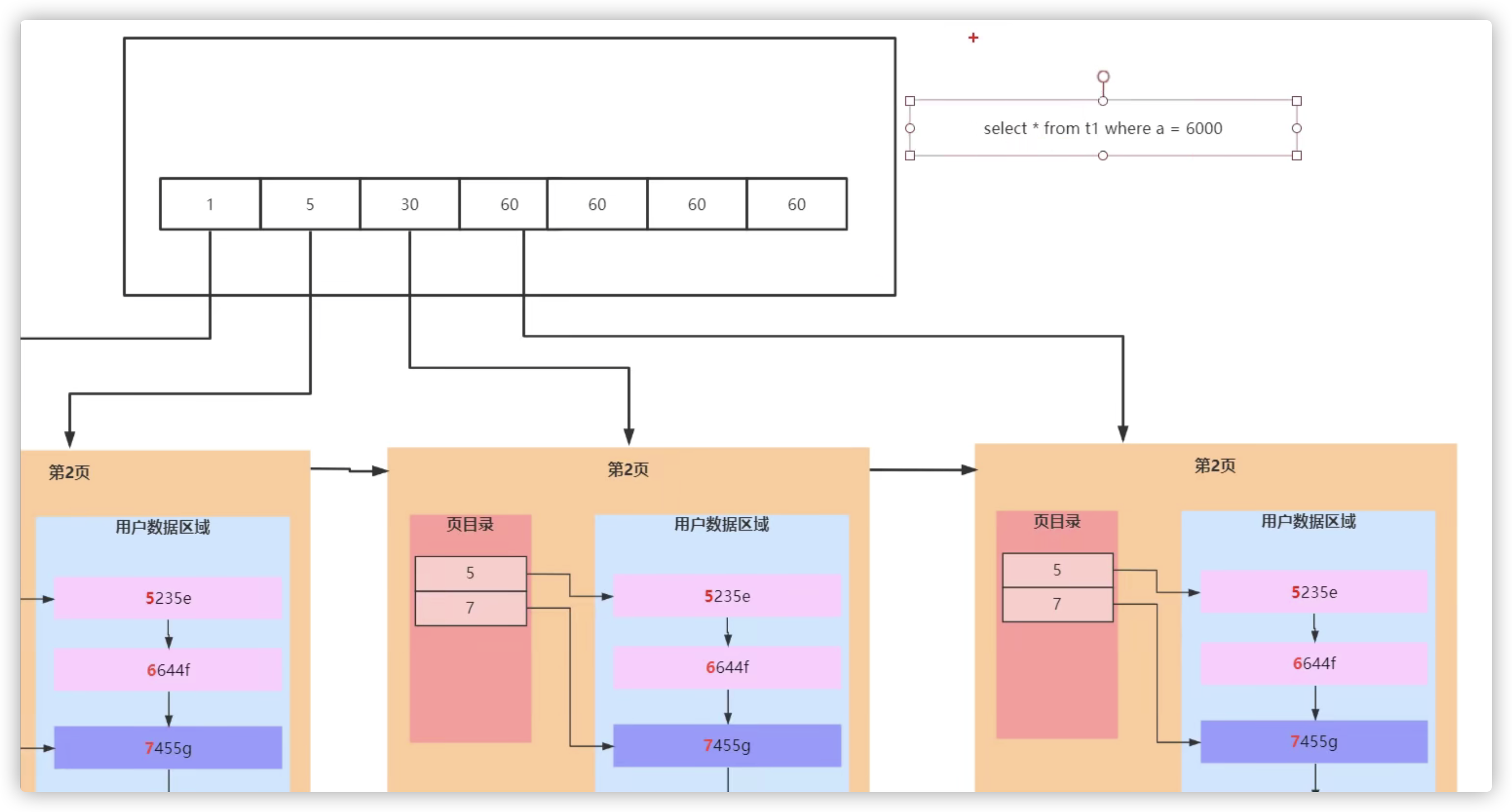
- 2500w行的数据,称为大表,此时的B+树会有三层,查询效率会慢
- 在innodb中 该索引叫聚簇索引(索引和数据是在一起的,上面三页是索引页,下面四页是数据页)
- 下面使用双向指针是为了支持范围查询
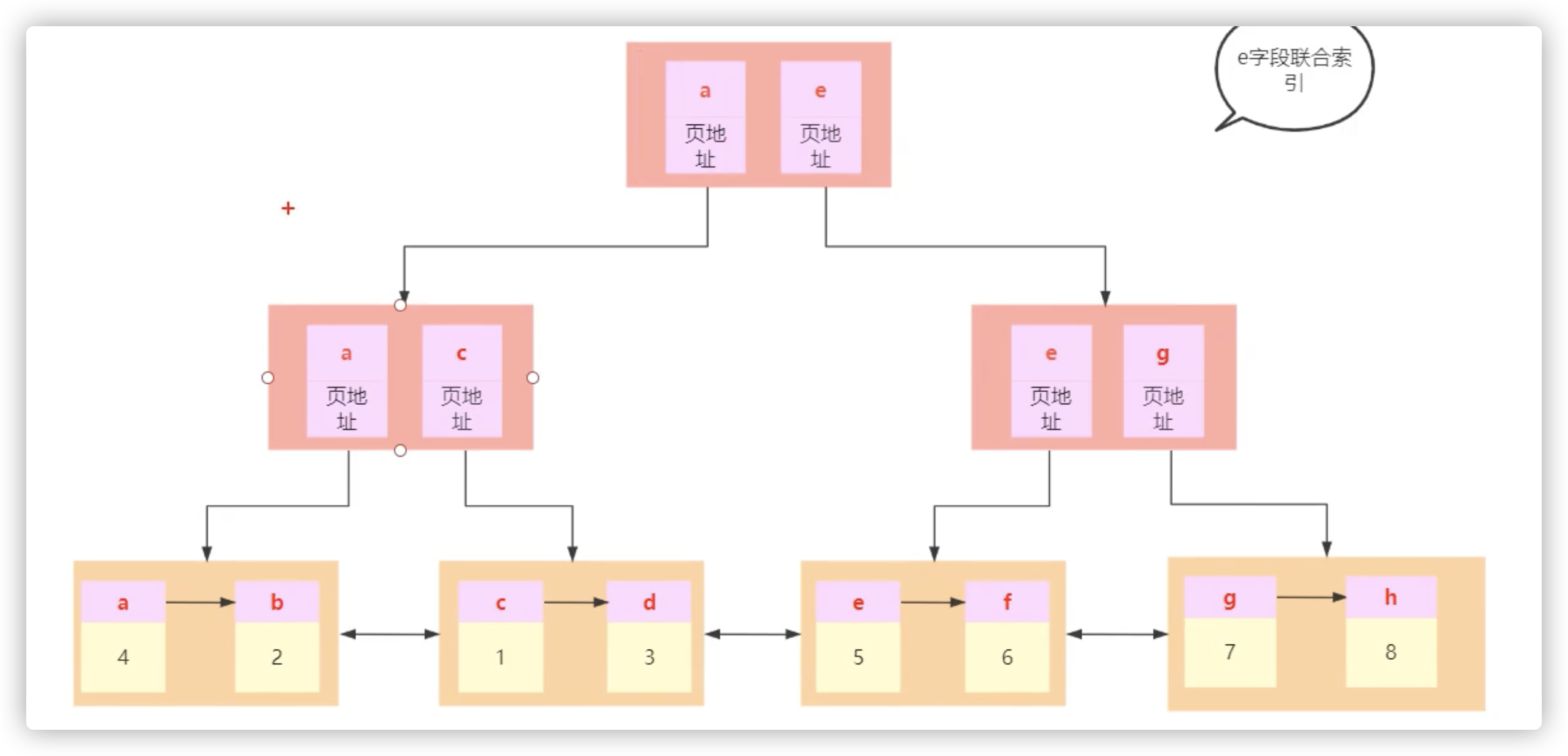
联合索引
create table t1(a int primary key,b int,c int,d int,e varchar(20)) engine=InnoDB;insert into t1 values(4,3,1,1,'a');insert into t1 values(1,1,1,1,'c');insert into t1 values(8,8,8,8,'h');insert into t1 values(2,2,2,2,'b');insert into t1 values(5,2,3,5,'e');insert into t1 values(3,3,2,2,'d');insert into t1 values(7,4,5,5,'g');insert into t1 values(6,6,4,4,'f');
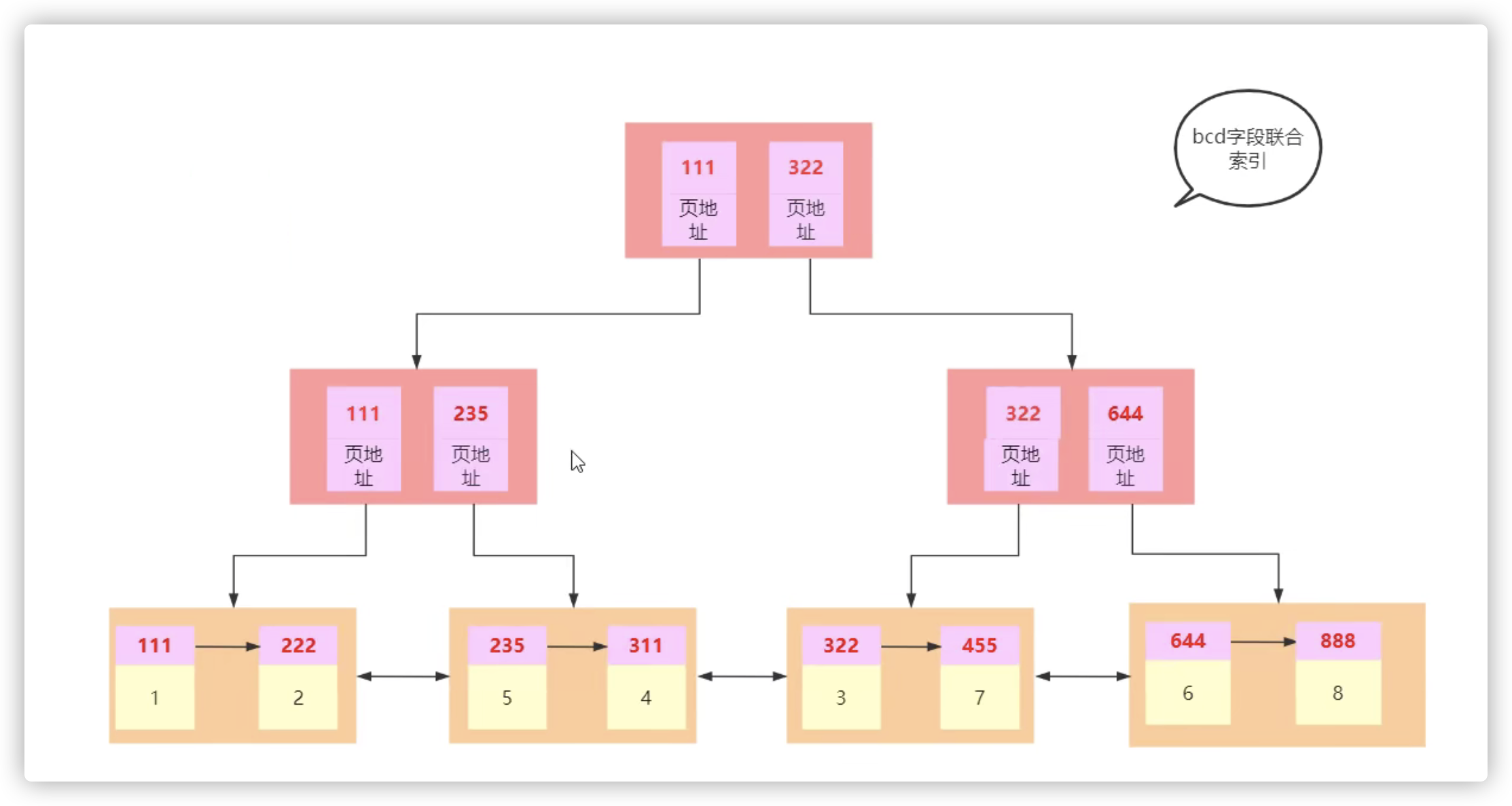
联合索引的比较规则是从左到右的,比如
create index idx_t1_bcd on t1(b,c,d);# 先比较b,再比较c,再比较d 进行排序
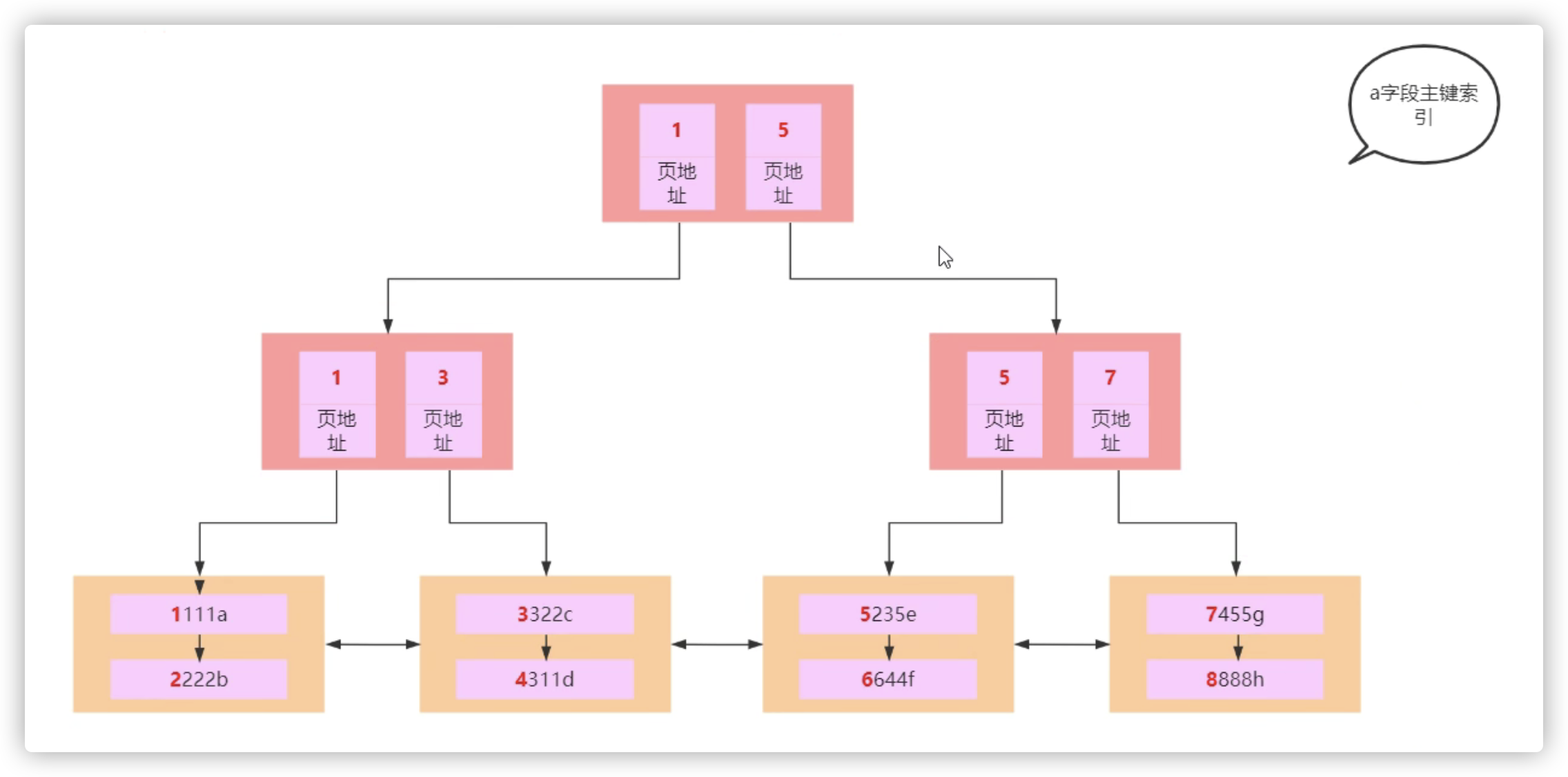
select * from t1 where b=1 and c=1 and d=1; 111
- 找到最左侧的111,叶子节点存放的是主键索引,不再存放数据
- 然后再到主键索引里找到完整的数据,这个过程叫回表,因为真实数据是存在主键索引的叶子节点中的。
索引底层原理与执行流程
explain select * from t1 where c=1 and d=1; --不走索引 不符合最左前缀原则type=ALL 全表扫码如果没有b字段,b+树不知道向左还是向右走select * from t1 where b=1 -- 走索引select * from t1 where b>1 -- 不走索引如果使用索引:索引——7次回表,因为是select *,e没有存到在叶子节点mysql会考虑使用全部扫码快还是使用索引快select * from t1 where b>6 --走索引 回表较少select b from t1 -- 走索引 type=index走全表会读取完整的记录,而走索引,不用完整的记录,可以减少io
type:systemconsteq_refrefref_or_nullindex_rangeunique_subqueryindex_subqueryrangeindexALL从上到下效率越来越低
mysql优化策略
select * from t1 order by b,c,d # 不走索引 这样不用回表,因为是*Extra=Using filesortselect b from t1 order by b,c,dtype=index Extra=Using index
create index idx_t1_e on t1(e); varchar 建立e字段索引
exlain select * from t1 where a = '1'; # 走索引exlain select * from t1 where e = 1; # 不走索引# 需要把e字段所有内容转成数字,这样会导致索引失效select 'a'=1; 0select 'a'=0; 1# 隐式装换 字符会被被转换成0
- 对字段进行操作都会导致索引失效
如何建立索引
考虑索引选择性
基数:不重复的索引值
选择性 = 基数 / 记录数
选择性越高索引的价值越大,选择性小,则代表这个列的重复值很多,不适合建立索引
性别 建索引没什么必要
前缀索引
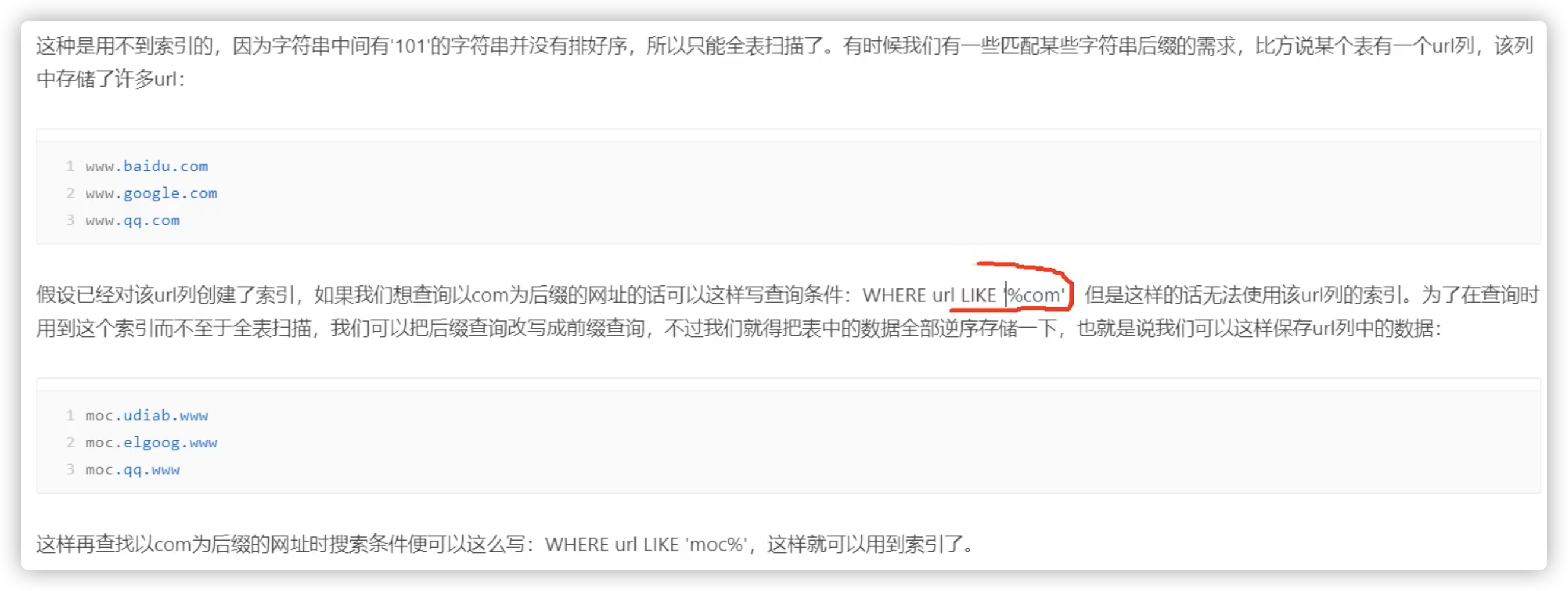
用列的前缀代替整个列作为索引key,当前缀长度合适时,可以做到既使得前缀索引的选择性接近全列索引,同时因为索引key变短而减少了索引文件的大小和维护开销。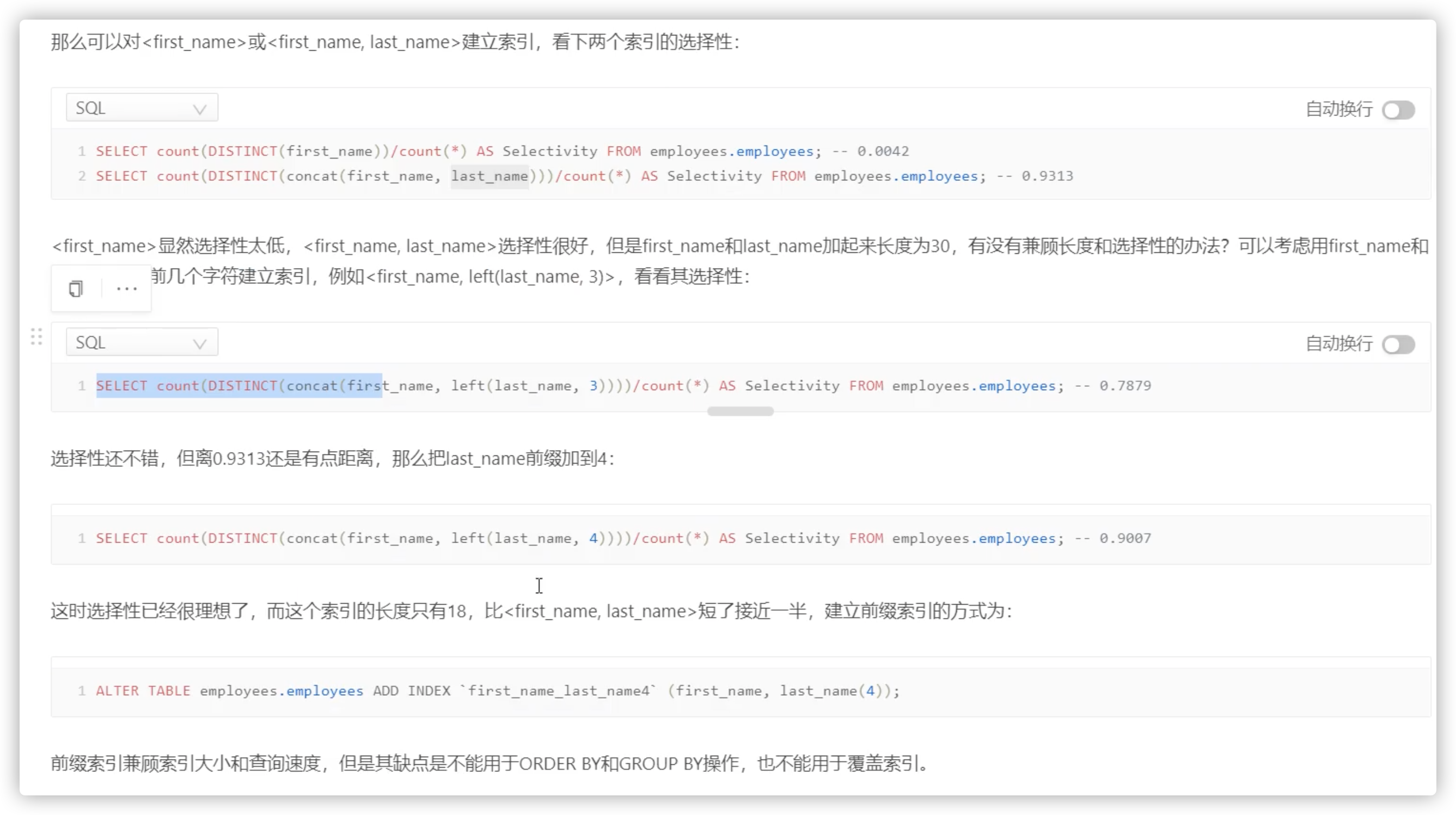

若有收获,就点个赞吧
0 人点赞
