1、DML(Data Manipulation Language):数据操纵语句,用于添
加、删除、修改、查询数据库记录,并检查数据完整性
- INSERT:添加数据到数据库中
- UPDATE:修改数据库中的数据
- DELETE:删除数据库中的数据
- SELECT:选择(查询)数据
- SELECT是SQL语言的基础,最为重要。
2、DDL(Data Definition Language):数据定义语句,用于库和表的创建、修改、删除。
- CREATE TABLE:创建数据库表
- ALTER TABLE:更改表结构、添加、删除、修改列长度
- DROP TABLE:删除表
- CREATE INDEX:在表上建立索引
- DROP INDEX:删除索引
3、DCL(Data Control Language):数据控制语句,用于定义用户的访问权限和安全级别。
- GRANT:授予访问权限
- REVOKE:撤销访问权限
- COMMIT:提交事务处理
- ROLLBACK:事务处理回退
- SAVEPOINT:设置保存点
- LOCK:对数据库的特定部分进行锁定
SQL的语言分类
DQL(Data Query Language):数据查询语言selectDML(Data Manipulate Language):数据操作语言insert 、update、deleteDDL(Data Define Languge):数据定义语言create、drop、alterTCL(Transaction Control Language):事务控制语言commit、rollback
常见命令
命令都是基于mac
mysql.server startmysql.server stopmysql 【-h主机名 -P端口号 】-u用户名 -p密码
1.查看当前所有的数据库show databases;2.打开指定的库use 库名3.查看当前库的所有表show tables;4.查看其它库的所有表show tables from 库名;5.创建表create table 表名(列名 列类型,列名 列类型,。。。);6.查看表结构desc 表名;7.查看服务器的版本方式一:登录到mysql服务端select version();方式二:没有登录到mysql服务端mysql --version或mysql --V
DQL
基础查询
use myemployees;select `last_name`, salary, emailfrom employees;# 查询函数select version();# 起别名select 100 % 98 as 结果;select last_name 姓from employees;# 去重:所有部门编号select distinct department_idfrom employees;# +号的作用 只是运算符不能拼接# 工号和姓名连成一个字段 并显示为姓名# select null + 0 只要一方为null结果肯定为nullselect concat(last_name, employee_id) as 姓名from employees;# 显示出表employees的全部列,各列之间用逗号连接,列头显示成OUT_PUTselect concat(first_name, ',', last_name, ',', ifnull(commission_pct, 0)) OUT_PUTfrom employees;
条件查询
条件查询:根据条件过滤原始表的数据,查询到想要的数据语法:select要查询的字段|表达式|常量值|函数from表where条件 ;分类:一、条件表达式示例:salary>10000条件运算符:> < >= <= = != <>二、逻辑表达式示例:salary>10000 && salary<20000逻辑运算符:and(&&):两个条件如果同时成立,结果为true,否则为falseor(||):两个条件只要有一个成立,结果为true,否则为falsenot(!):如果条件成立,则not后为false,否则为true三、模糊查询likebetween andinis null示例:last_name like 'a%'# 第三个字符为eselect last_namefrom employeeswhere last_name like '__a%';# 第二个字符为下划线的 转义select *from employeeswhere last_name like '_\_%';select *from employeeswhere last_name like '_$_%' escape '$';# 员工编号在100在120之间select *from employeeswhere employee_id between 100 and 120; # 包含临界值# in# 查询员工工种编号 IT_PROG AD_VPselect last_name, job_idfrom employeeswhere job_id in ('IT_PROG', 'AD_VP');# is null# =或<>不能判断null值# 查询没有奖金的员工select last_name, commission_pctfrom employeeswhere commission_pct is null;# is not nullselect last_name, commission_pctfrom employeeswhere commission_pct is not null;# 安全等于 <=> 可读性差select last_name, commission_pctfrom employeeswhere commission_pct <=> null;# IS NULL:仅仅可以判断NULL值,可读性较高,建议使用# <=> :既可以判断NULL值,又可以判断普通的数值,可读性较低
排序查询
语法:select要查询的东西from表where条件order by 排序的字段|表达式|函数|别名 【asc|desc】
常见函数
一、单行函数1、字符函数concat拼接substr截取子串upper转换成大写lower转换成小写trim去前后指定的空格和字符ltrim去左边空格rtrim去右边空格replace替换lpad左填充rpad右填充instr返回子串第一次出现的索引length 获取字节个数2、数学函数round 四舍五入rand 随机数floor向下取整ceil向上取整mod取余truncate截断3、日期函数now当前系统日期+时间curdate当前系统日期curtime当前系统时间str_to_date 将字符转换成日期date_format将日期转换成字符DATEDIFF 日期差4、流程控制函数if 处理双分支case语句 处理多分支情况1:处理等值判断情况2:处理条件判断5、其他函数version版本database当前库user当前连接用户二、分组函数sum 求和max 最大值min 最小值avg 平均值count 计数特点:1、以上五个分组函数都忽略null值,除了count(*)2、sum和avg一般用于处理数值型max、min、count可以处理任何数据类型3、都可以搭配distinct使用,用于统计去重后的结果4、count的参数可以支持:字段、*、常量值,一般放1建议使用 count(*)5、和分组函数一同查询的字段要求是group by后的字段
查看引擎:
show variables like ‘%storage_engine%’;
效率:
MYISAM存储引擎下 ,COUNT()的效率高
INNODB存储引擎下,COUNT()和COUNT(1)的效率差不多,比COUNT(字段)要高一些
分组查询
语法:select 查询的字段,分组函数from 表group by 分组的字段特点:1、可以按单个字段分组2、和分组函数一同查询的字段最好是分组后的字段3、分组筛选针对的表 位置 关键字分组前筛选: 原始表 group by的前面 where分组后筛选: 分组后的结果集 group by的后面 having4、可以按多个字段分组,字段之间用逗号隔开5、可以支持排序6、having后可以支持别名
连接查询
含义:又称多表查询,当查询的字段来自于多个表时,就会用到连接查询
笛卡尔乘积现象:表1 有m行,表2有n行,结果=m*n行
发生原因:没有有效的连接条件
如何避免:添加有效的连接条件
分类:
按年代分类:
- sql92标准:仅仅支持内连接
- sql99标准【推荐】:支持内连接+外连接(左外和右外)+交叉连接
按功能分类:
内连接:
等值连接<br /> 非等值连接<br /> 自连接
外连接:
左外连接<br /> 右外连接<br /> 全外连接
交叉连接
一、sql92标准
1、等值连接
① 多表等值连接的结果为多表的交集部分
②n表连接,至少需要n-1个连接条件
③ 多表的顺序没有要求
④一般需要为表起别名
⑤可以搭配前面介绍的所有子句使用,比如排序、分组、筛选
2、为表起别名
①提高语句的简洁度
②区分多个重名的字段
注意:如果为表起了别名,则查询的字段就不能使用原来的表名去限定
3、两个表的顺序可以调换
4、可以加筛选
5、可以加分组
6、可以加排序
7、可以实现三表连接
二、sql99语法
语法:
select 查询列表
from 表1 别名 【连接类型】
join 表2 别名
on 连接条件
【where 筛选条件】
【group by 分组】
【having 筛选条件】
【order by 排序列表】
分类:
内连接(★):inner
外连接
左外(★):left 【outer】
右外(★):right 【outer】
全外:full【outer】
交叉连接:cross
一)内连接
语法:
select 查询列表
from 表1 别名
inner join 表2 别名
on 连接条件;
分类:
等值
非等值
自连接
特点:
①添加排序、分组、筛选
②inner可以省略
③ 筛选条件放在where后面,连接条件放在on后面,提高分离性,便于阅读
④inner join连接和sql92语法中的等值连接效果是一样的,都是查询多表的交集
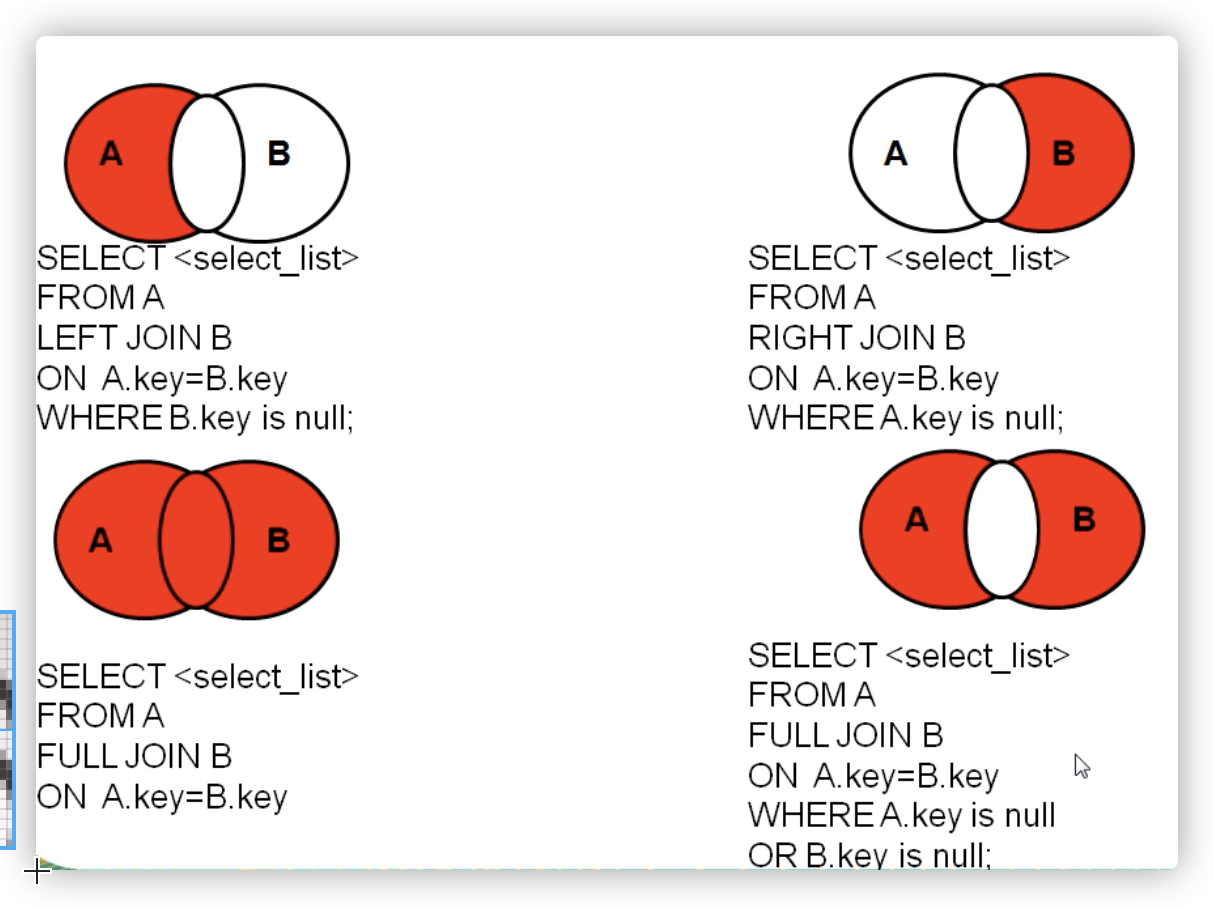
二)外连接
应用场景:用于查询一个表中有,另一个表没有的记录
特点:
1、外连接的查询结果为主表中的所有记录
如果从表中有和它匹配的,则显示匹配的值
如果从表中没有和它匹配的,则显示null
外连接查询结果=内连接结果+主表中有而从表没有的记录
2、左外连接,left join左边的是主表
右外连接,right join右边的是主表
3、左外和右外交换两个表的顺序,可以实现同样的效果
4、全外连接=内连接的结果+表1中有但表2没有的+表2中有但表1没有的
sql92和 sql99pk
功能:sql99支持的较多
可读性:sql99实现连接条件和筛选条件的分离,可读性较高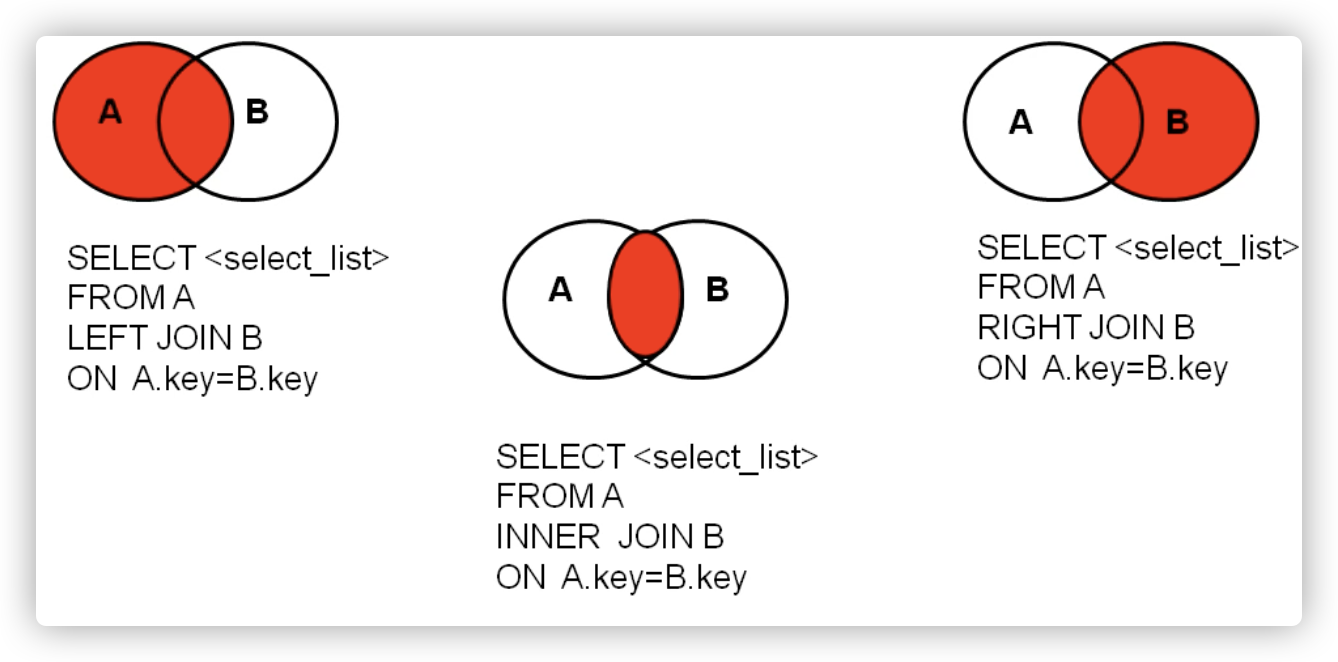
子查询
含义:
出现在其他语句中的select语句,称为子查询或内查询
外部的查询语句,称为主查询或外查询
分类:
按子查询出现的位置:
select后面:
仅仅支持标量子查询
from后面:
支持表子查询
where或having后面:★
标量子查询(单行) √
列子查询 (多行)√
行子查询
exists后面(相关子查询)
表子查询
按结果集的行列数不同:
标量子查询(结果集只有一行一列)
列子查询(结果集只有一列多行)
行子查询(结果集有一行多列)
表子查询(结果集一般为多行多列)
一、where或having后面
1、标量子查询(单行子查询)
2、列子查询(多行子查询)
3、行子查询(多列多行)
特点:
①子查询放在小括号内
②子查询一般放在条件的右侧
③标量子查询,一般搭配着单行操作符使用
> < >= <= = <>
列子查询,一般搭配着多行操作符使用
in、any/some、all
④子查询的执行优先于主查询执行,主查询的条件用到了子查询的结果
二、select后面
仅仅支持标量子查询
三、from后面
将子查询结果充当一张表,要求必须起别名
四、exists后面(相关子查询)
语法:
exists(完整的查询语句)
结果:
1或0
分页查询
应用场景:当要显示的数据,一页显示不全,需要分页提交sql请求
语法:
select 查询列表
from 表
【join type join 表2
on 连接条件
where 筛选条件
group by 分组字段
having 分组后的筛选
order by 排序的字段】
limit 【offset,】size;
offset要显示条目的起始索引(起始索引从0开始)
size 要显示的条目个数
特点:
①limit语句放在查询语句的最后
②公式
要显示的页数 page,每页的条目数size
select 查询列表
from 表
limit (page-1)*size,size;
size=10
page
1 0
2 10
3 20
联合查询
union 联合 合并:将多条查询语句的结果合并成一个结果
语法:
查询语句1
union
查询语句2
union
…
应用场景:
要查询的结果来自于多个表,且多个表没有直接的连接关系,但查询的信息一致时
特点:★
1、要求多条查询语句的查询列数是一致的!
2、要求多条查询语句的查询的每一列的类型和顺序最好一致
3、union关键字默认去重,如果使用union all 可以包含重复项
DML
数据操作语言:
插入:insert
修改:update
删除:delete
插入
方式一:
语法:
insert into 表名(列名,…) values(值1,…);
方式二:
语法:
insert into 表名
set 列名=值,列名=值,…
两个方式对比:
1、方式一支持插入多行,方式二不支持
2、方式一支持子查询,方式二不支持
更新
1.修改单表的记录★
语法:
update 表名
set 列=新值,列=新值,…
where 筛选条件;
2.修改多表的记录【补充】
语法:
sql92语法:
update 表1 别名,表2 别名
set 列=值,…
where 连接条件
and 筛选条件;
sql99语法:
update 表1 别名
inner|left|right join 表2 别名
on 连接条件
set 列=值,…
where 筛选条件;
删除
方式一:delete
语法:
1、单表的删除【★】
delete from 表名 where 筛选条件
2、多表的删除【补充】
sql92语法:
delete 表1的别名,表2的别名
from 表1 别名,表2 别名
where 连接条件
and 筛选条件;
sql99语法:
delete 表1的别名,表2的别名
from 表1 别名
inner|left|right join 表2 别名 on 连接条件
where 筛选条件;
方式二:truncate
语法:truncate table 表名;
delete pk truncate【面试题★】
1.delete 可以加where 条件,truncate不能加
2.truncate删除,效率高一丢丢
3.假如要删除的表中有自增长列,
如果用delete删除后,再插入数据,自增长列的值从断点开始,
而truncate删除后,再插入数据,自增长列的值从1开始。
4.truncate删除没有返回值,delete删除有返回值
5.truncate删除不能回滚,delete删除可以回滚.
DDL
库和表的管理
一、库的管理
创建、修改、删除
二、表的管理
创建、修改、删除
创建: create
修改: alter
删除: drop
一、库的管理
1、库的创建
语法:
create database [if not exists]库名;
2、库的修改 更改库的字符集
ALTER DATABASE books CHARACTER SET gbk;
3、库的删除
DROP DATABASE IF EXISTS books;
二、表的管理
1.表的创建 ★
语法:
create table 表名(
列名 列的类型【(长度) 约束】,
列名 列的类型【(长度) 约束】,
列名 列的类型【(长度) 约束】,
…
列名 列的类型【(长度) 约束】
2.表的修改
语法
alter table 表名 add|drop|modify|change column 列名 【列类型 约束】;
#①修改列名ALTER TABLE book CHANGE COLUMN publishdate pubDate DATETIME;#②修改列的类型或约束ALTER TABLE book MODIFY COLUMN pubdate TIMESTAMP;#③添加新列ALTER TABLE author ADD COLUMN annual DOUBLE;#④删除列ALTER TABLE book_author DROP COLUMN annual;#⑤修改表名ALTER TABLE author RENAME TO book_author;
3.表的删除
DROP TABLE IF EXISTS book_author;SHOW TABLES;#通用的写法:DROP DATABASE IF EXISTS 旧库名;CREATE DATABASE 新库名;DROP TABLE IF EXISTS 旧表名;CREATE TABLE 表名();
4.表的复制
#4.表的复制INSERT INTO author VALUES(1,'村上春树','日本'),(2,'莫言','中国'),(3,'冯唐','中国'),(4,'金庸','中国');SELECT * FROM Author;SELECT * FROM copy2;#1.仅仅复制表的结构CREATE TABLE copy LIKE author;#2.复制表的结构+数据CREATE TABLE copy2SELECT * FROM author;#只复制部分数据CREATE TABLE copy3SELECT id,au_nameFROM authorWHERE nation='中国';#仅仅复制某些字段CREATE TABLE copy4SELECT id,au_nameFROM authorWHERE 0;
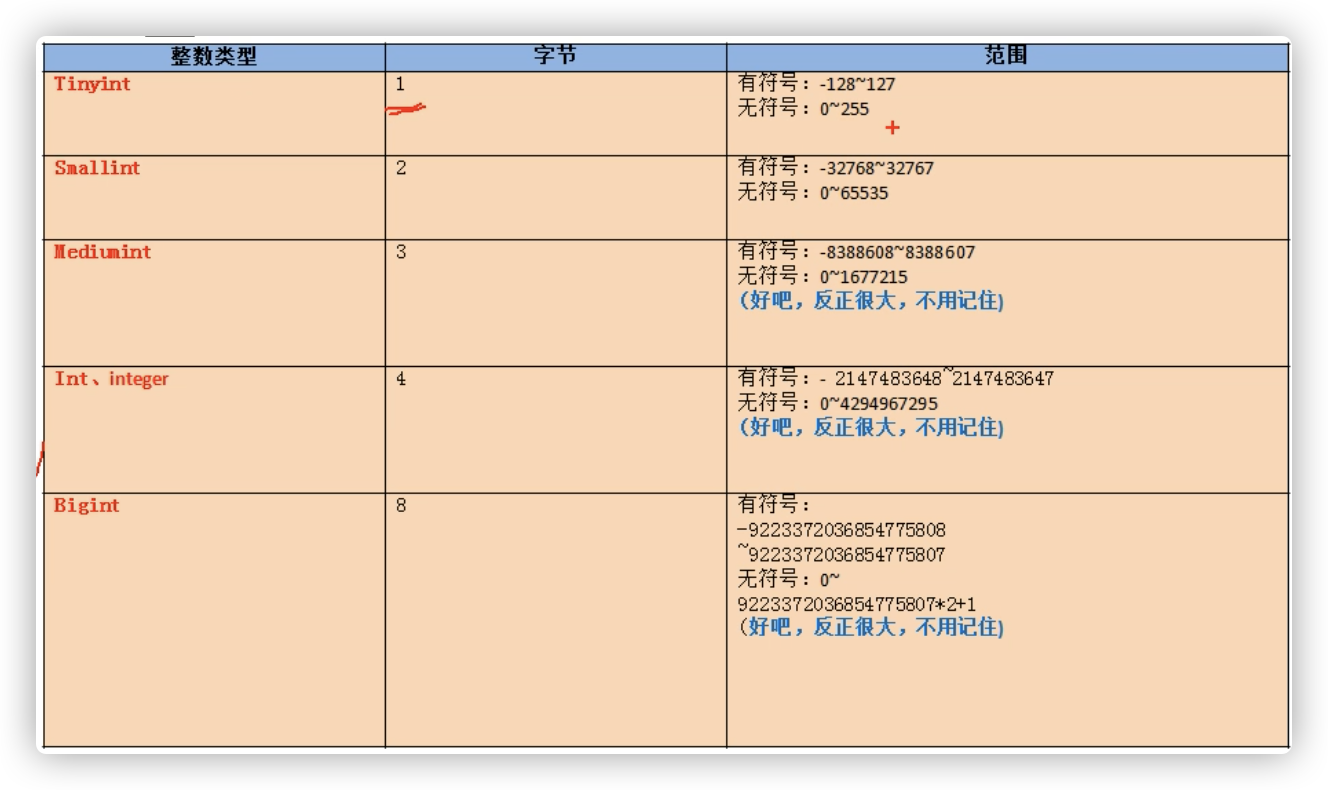
数据类型
数值型:
整型
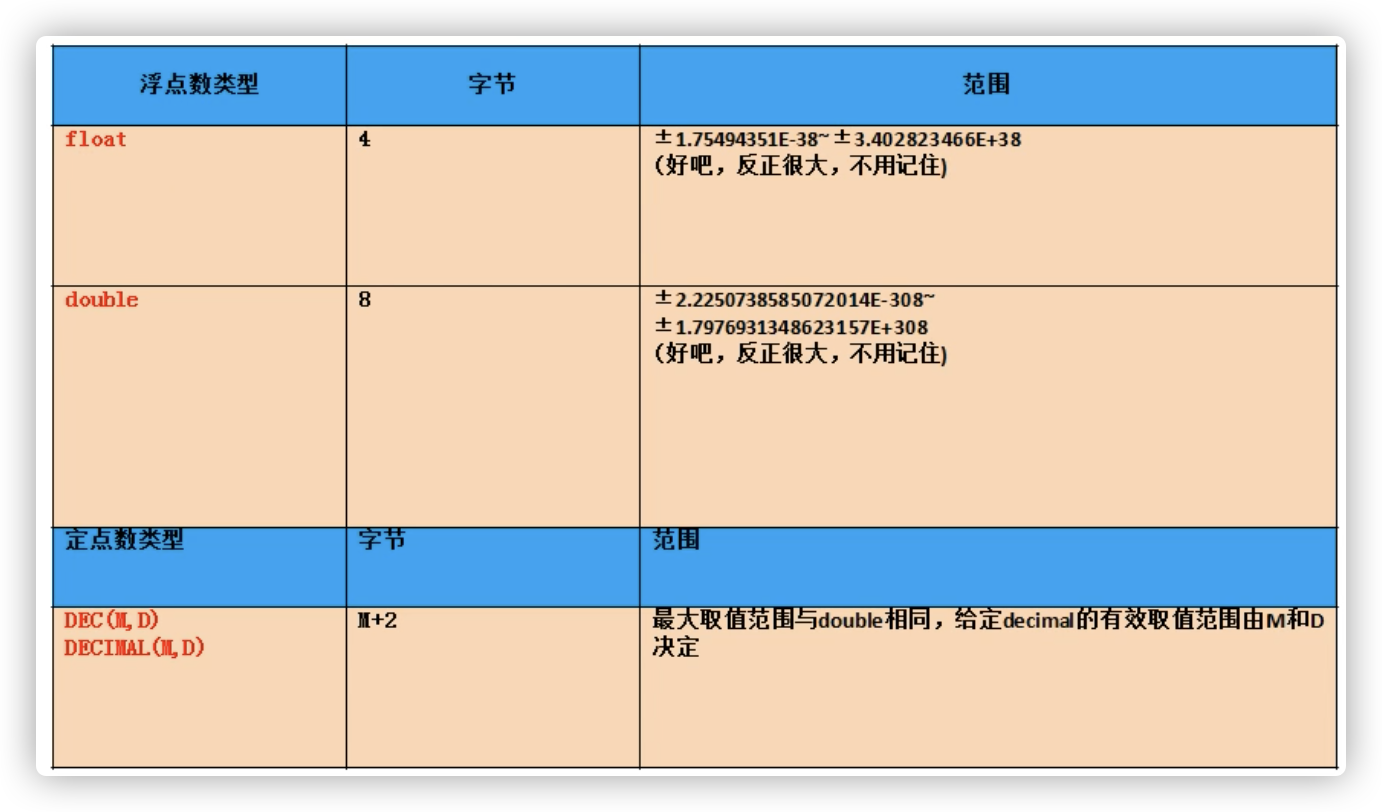
小数:
定点数
浮点数
字符型:
较短的文本:char、varchar
较长的文本:text、blob(较长的二进制数据)
日期型:
整型
特点:
① 如果不设置无符号还是有符号,默认是有符号,如果想设置无符号,需要添加unsigned关键字
② 如果插入的数值超出了整型的范围,会报out of range异常,并且插入临界值
③ 如果不设置长度,会有默认的长度
长度代表了显示的最大宽度,如果不够会用0在左边填充,但必须搭配zerofill使用!
小数
特点:
①
M:整数部位+小数部位
D:小数部位
如果超过范围,则插入临界值
②
M和D都可以省略
如果是decimal,则M默认为10,D默认为0
如果是float和double,则会根据插入的数值的精度来决定精度
③定点型的精确度较高,如果要求插入数值的精度较高如货币运算等则考虑使用
原则:所选择的类型越简单越好,能保存数值的类型越小越好
字符型
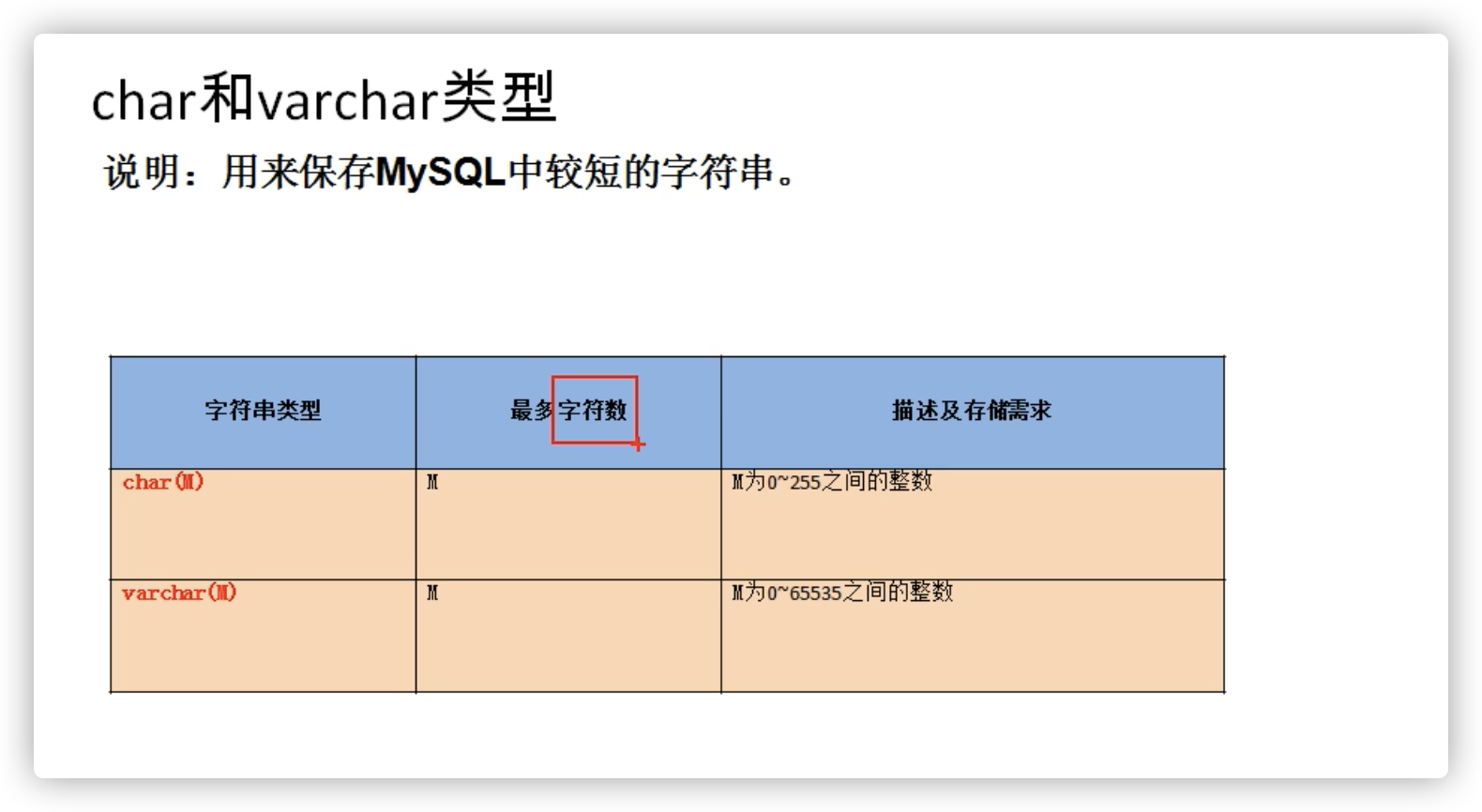
较短的文本:
char
varchar
其他:
binary和varbinary用于保存较短的二进制
enum用于保存枚举
set用于保存集合
较长的文本:
text
blob(较大的二进制)
特点:
写法 M的意思 特点 空间的耗费 效率<br />char char(M) 最大的字符数,可以省略,默认为1 固定长度的字符 比较耗费 高
varchar varchar(M) 最大的字符数,不可以省略 可变长度的字符 比较节省 低
日期
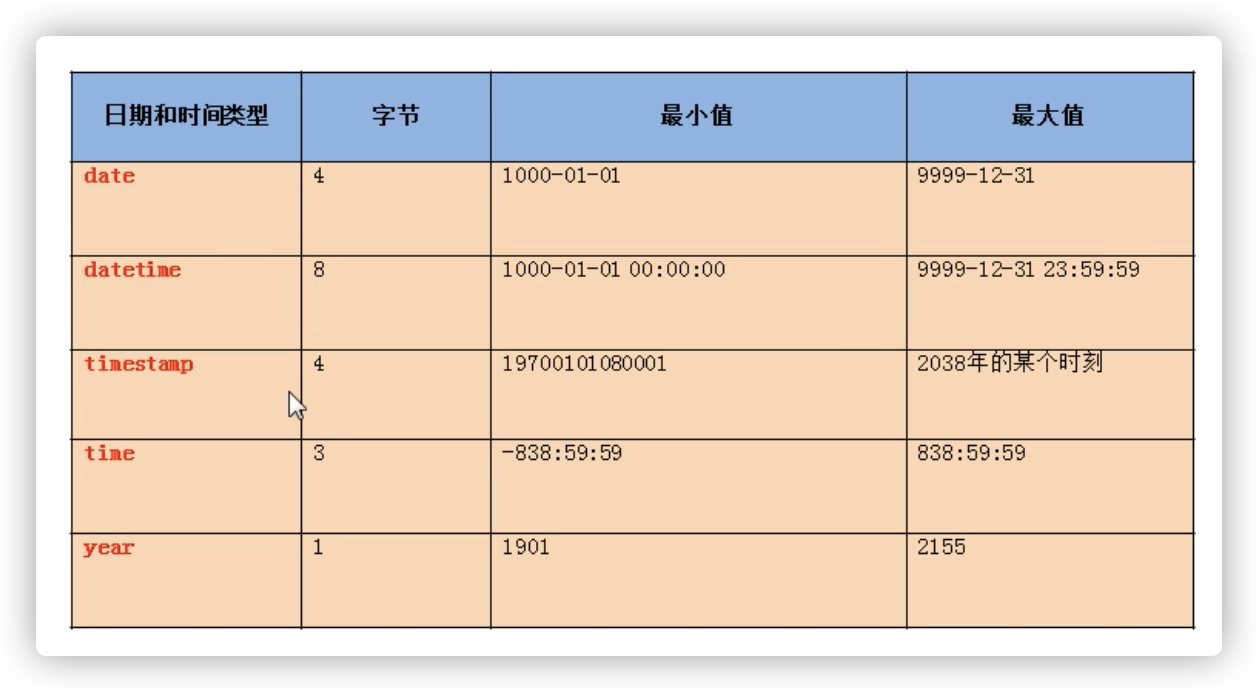

SHOW VARIABLES LIKE 'time_zone';SET time_zone='+9:00';

若有收获,就点个赞吧
0 人点赞
