背景
目前实时的需求越来越多,由于前期需求比较急,人力不够,没有时间去完善监控系统,Flink 任务基本上处于“裸奔”状态,只有零星的外部监控。实时作业要保证7 x 24运行,除了要在业务逻辑和编码上下功夫之外,好的监控系统也是必不可少的。现在急切地需要一个完善的指标收集&监控系统。经过调研,大部分企业选择开源的 Promethes+Pushgateway+Grafana 组合,也是目前比较流行的组合,下面是 Promethes 官网给出的 Promethes 生态系统图。
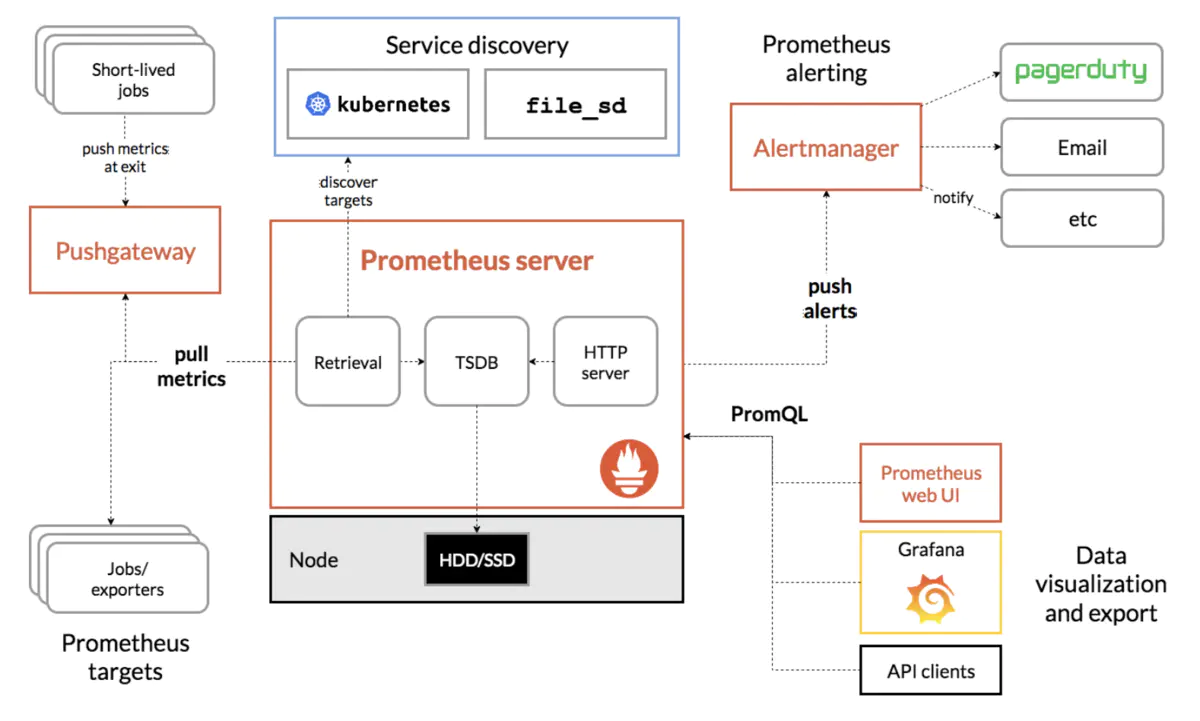
本篇文章主要记录了以上几个组件的安装过程。先介绍该组件的作用,然后记录安装过程。
软件环境
- Linux(centos) 32G 8核 单节点
- Flink 1.9.2 (后面安装pushgateway的时候需要选择合适的版本,后文会有提到)
Promethes & Pushgateway
1.介绍
Prometheus(普罗米修斯)是一套开源的监控&报警&时间序列数据库的组合,起始是由SoundCloud公司开发的。随着发展,越来越多公司和组织接受采用Prometheus,社会也十分活跃,他们便将它独立成开源项目,并且有公司来运作。Google SRE的书内也曾提到跟他们BorgMon监控系统相似的实现是Prometheus。现在最常见的Kubernetes容器管理系统中,通常会搭配Prometheus进行监控。
Prometheus基本原理是通过HTTP协议周期性抓取被监控组件的状态,这样做的好处是任意组件只要提供HTTP接口就可以接入监控系统,不需要任何SDK或者其他的集成过程。这样做非常适合虚拟化环境比如VM或者Docker 。
Prometheus应该是为数不多的适合Docker、Mesos、Kubernetes环境的监控系统之一。
输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux 系统信息 (包括磁盘、内存、CPU、网络等等),具体支持的源看:https://github.com/prometheus。
与其他监控系统相比,Prometheus的主要特点是:
- 一个多维数据模型(时间序列由指标名称定义和设置键/值尺寸)。
- 非常高效的存储,平均一个采样数据占~3.5bytes左右,320万的时间序列,每30秒采样,保持60天,消耗磁盘大概228G。
- 一种灵活的查询语言。
- 不依赖分布式存储,单个服务器节点。
- 时间集合通过HTTP上的PULL模型进行。
- 通过中间网关支持推送时间。
- 通过服务发现或静态配置发现目标。
- 多种模式的图形和仪表板支持。
Pushgateway 是 Prometheus 生态中一个重要工具,使用它的原因主要是:
- Prometheus 采用 pull 模式,可能由于不在一个子网或者防火墙原因,导致 Prometheus 无法直接拉取各个 target 数据。
- 在监控业务数据的时候,需要将不同数据汇总, 由 Prometheus 统一收集。
由于以上原因,不得不使用 pushgateway,但在使用之前,有必要了解一下它的一些弊端:
- 将多个节点数据汇总到 pushgateway, 如果 pushgateway 挂了,受影响比多个 target 大。
- Prometheus 拉取状态
up只针对 pushgateway, 无法做到对每个节点有效。 - Pushgateway 可以持久化推送给它的所有监控数据。
因此,即使你的监控已经下线,prometheus 还会拉取到旧的监控数据,需要手动清理 pushgateway 不要的数据。
2.下载 Prometheus
首先下载 promethes 的离线安装包,访问https://prometheus.io/download/ 选择合适的系统的安装包。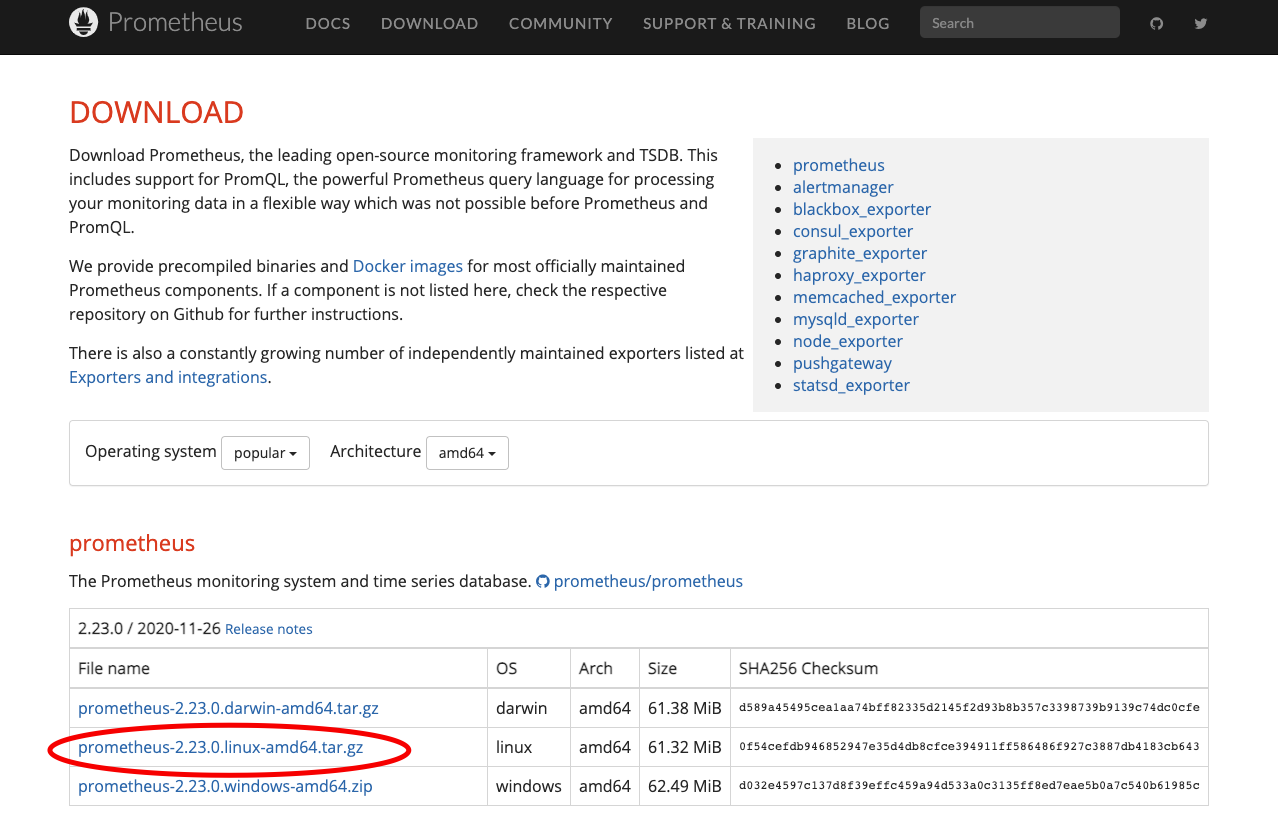
我这里选择的是 Linux 版本的。
下载完整之后,解压。
tar zxvf prometheus-2.23.0.linux-amd64.tar.gz
3.下载 pushgateway
FLINK-17132 中可以得到以下信息,Flink1.11 之前的源码使用Prometheus的版本还是0.3.0,如果我们使用了Flink1.11 之前的版本,选择pushgateway的时候,尽量选择一个低版本的稳定版。
如果你使用的是 Flink1.11 或者 Flink 1.12 可以直接安装最新的稳定版即可。
笔者文字表达能力有限,不知道我讲清楚了吗?画个流程图
如果低版本的 Flink 搭配了高版本的 pushgateway 可能出现Warn信息:
Jobmanager and TaskManager will print “Failed to push metrics to PushGateway” and throw “java.io.IOException: Response code from xxx was 200”
我们目前使用的是 Flink 1.9.2, 选择 pushgateway 0.9.1 的这一个版本。
访问 https://github.com/prometheus/pushgateway/releases 地址,下载 0.9.1 版本的 pushgateway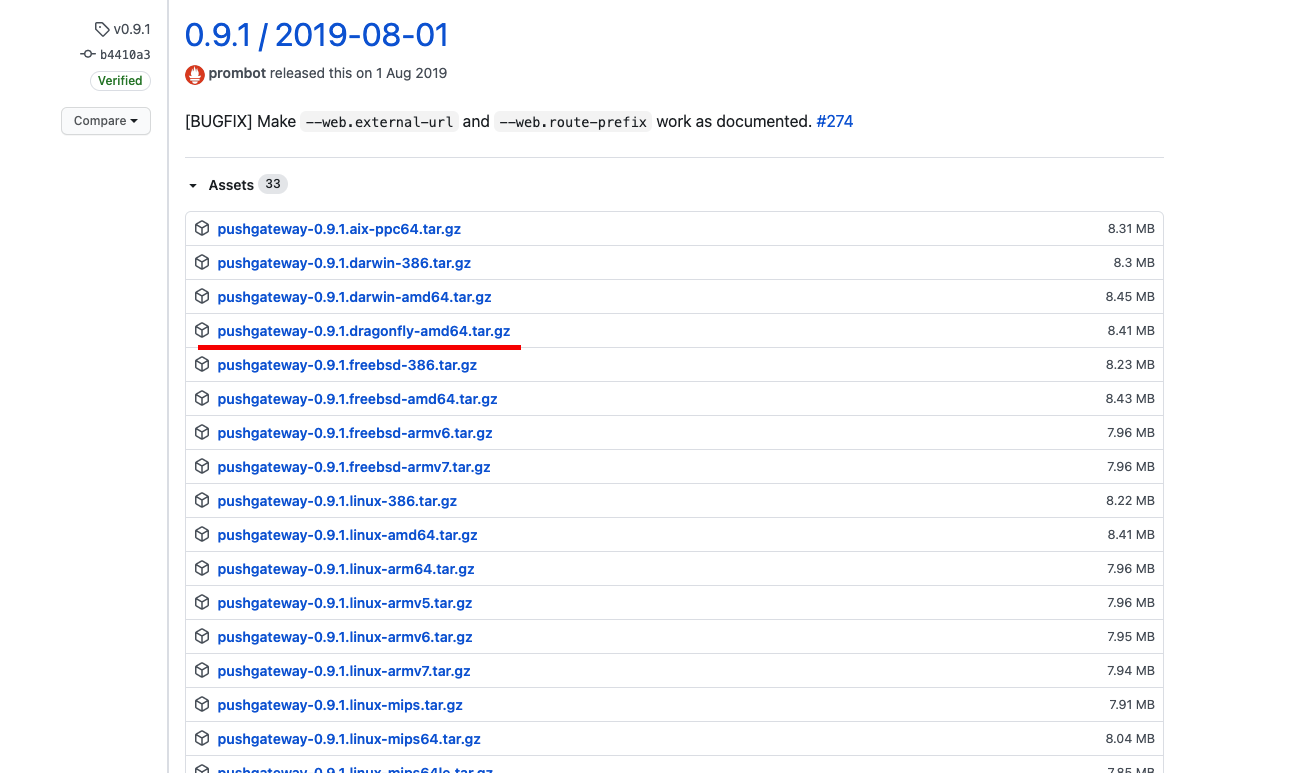
下载完整之后,解压。
4.配置 Prometheus
进入安装目录 cd prometheus-2.23.0.linux-amd64
编辑 prometheus.yml 文件,主要是修改监控间隔,以及添加PushGateway的监控配置。Prometheus的默认端口是9090,PushGateway的是9091。下面是修改之后的配置文件:
# my global configglobal:scrape_interval: 60s # Set the scrape interval to every 15 seconds. Default is every 1 minute.evaluation_interval: 60s # Evaluate rules every 15 seconds. The default is every 1 minute.# scrape_timeout is set to the global default (10s).# Alertmanager configurationalerting:alertmanagers:- static_configs:- targets:# - alertmanager:9093# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.rule_files:# - "first_rules.yml"# - "second_rules.yml"# A scrape configuration containing exactly one endpoint to scrape:# Here it's Prometheus itself.scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: 'prometheus'static_configs:- targets: ['localhost:9090']labels:instance: prometheus- job_name: 'pushgateway'static_configs:- targets: ['172.31.66.189:9091']labels:instance: pushgateway
5.启动
用nohup的方式依次启动PushGateway和Prometheus。
nohup ./pushgateway > /data/logs/pushgateway.log 2>&1 &nohup ./prometheus --config.file=prometheus.yml > /data/logs/prometheus.log 2>&1 &
6.访问web页面—验证
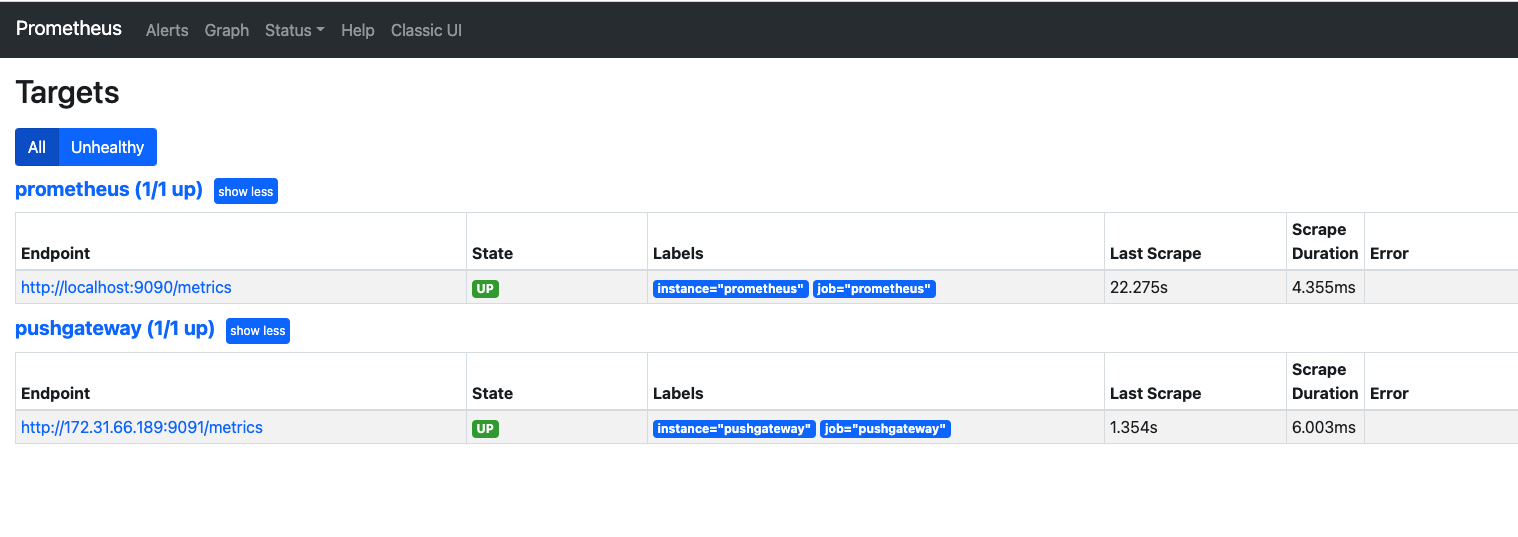
耐心等待一分钟左右。浏览器访问Prometheus所在节点的9090端口,查看Targets一项。如果两个项目都为UP状态,就是配置好了。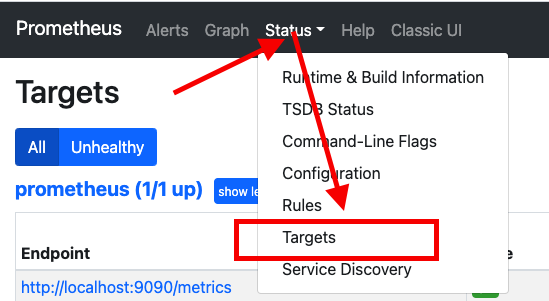
修改 Flink 配置
编辑 flink-conf.yaml 文件,加入下面的配置
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter# 这里写PushGateway的主机名与端口号metrics.reporter.promgateway.host: 172.31.66.189metrics.reporter.promgateway.port: 9091# Flink metric在前端展示的标签(前缀)与随机后缀metrics.reporter.promgateway.jobName: flink-metricsmetrics.reporter.promgateway.randomJobNameSuffix: truemetrics.reporter.promgateway.deleteOnShutdown: false
注意: 如果使用的是 Flink 1.9 、Flink 1.10 版本,还需要将安装包下面的 opt/flink-metrics-prometheus-*.jar 拷贝到 lib目录下。
Grafana
介绍
安装
访问 https://grafana.com/grafana/download,选择 Lunix 独立的离线安装包即可。
下载之后,暂时不需要配置。
解压直接启动。
nohup ./grafana-server > /data/logs/grafana-server.log 2>&1 &
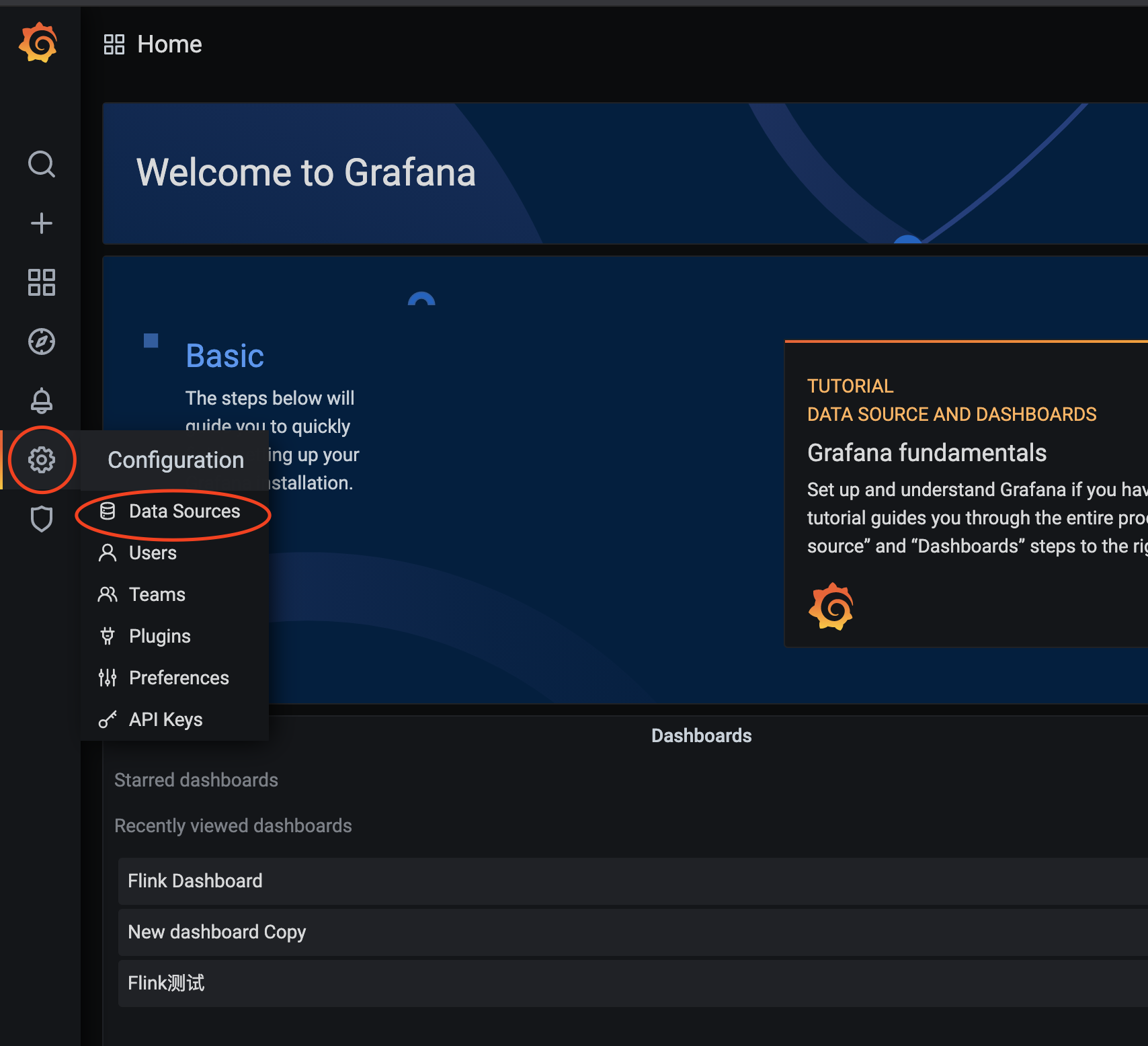
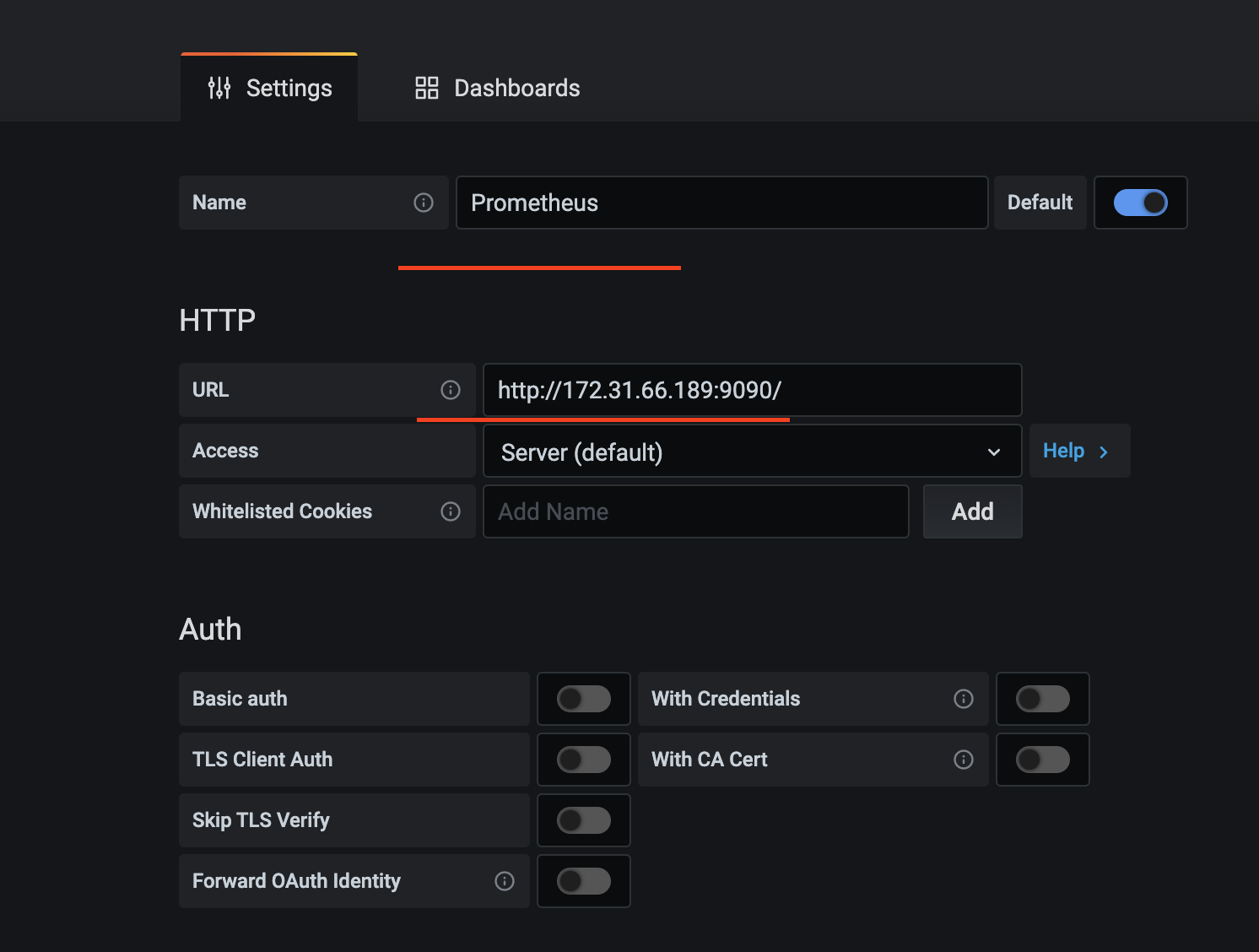
配置pushgateway的数据源
查看指标
启动一个 Flink 任务,观察指标。
参考
感谢以下文章的作者,使得安装过程变得更加高效。以下给出参考链接:
- 基于docker 搭建Prometheus+Grafana
- 基于Prometheus的Pushgateway实战
- Flink监控信息写入到PushGateway出现 java.io.IOException: Response code from http xx was 200问题
- 使用Prometheus+Grafana监控Flink on YARN作业
- Flink 1.9 Metric
- Flink 1.10 Metric
- Flink 1.11 Metric
- Flink 1.12 Metric
- https://grafana.com/
- https://developer.here.com/documentation/metrics-and-logs/user_guide/topics/flink-metrics.html
- Monitoring Apache Flink with Prometheus and Grafana
- 几个配置好的指标模板

若有收获,就点个赞吧
0 人点赞
