相信小伙伴都有这个疑问,机器资源不够,也没有钱配置好的学习的机器,那么问题来了,这时候我们该怎么办呢?2020-02-25 19:00更新
我一个朋友最近也在学习 Hadoop, 学到了 Hive 了,想实际操作一下,但是没有机器,正逢某大厂的云服务器打折,就买了一台 2 核 8 G 的云主机。我打算实际给她在这台云主机上搭建一个学习环境。那么,下面开始吧:
本文档描述了如何设置和配置单个节点 Hadoop 安装,以便您可以使用 Hadoop MapReduce 和 Hadoop分布式文件系统(HDFS)快速执行简单操作。
一、环境准备
- Linux 系统(一台云主机或一台物理机)
- JDK 8
- SSH
二、安装 Hadoop 3.2.0
2.1 下载
需要下载一个软件包,镜像地址: Apache Download Mirrors (清华大学的镜像),选一个版本即可,我选的是 Hadoop-3.2.0
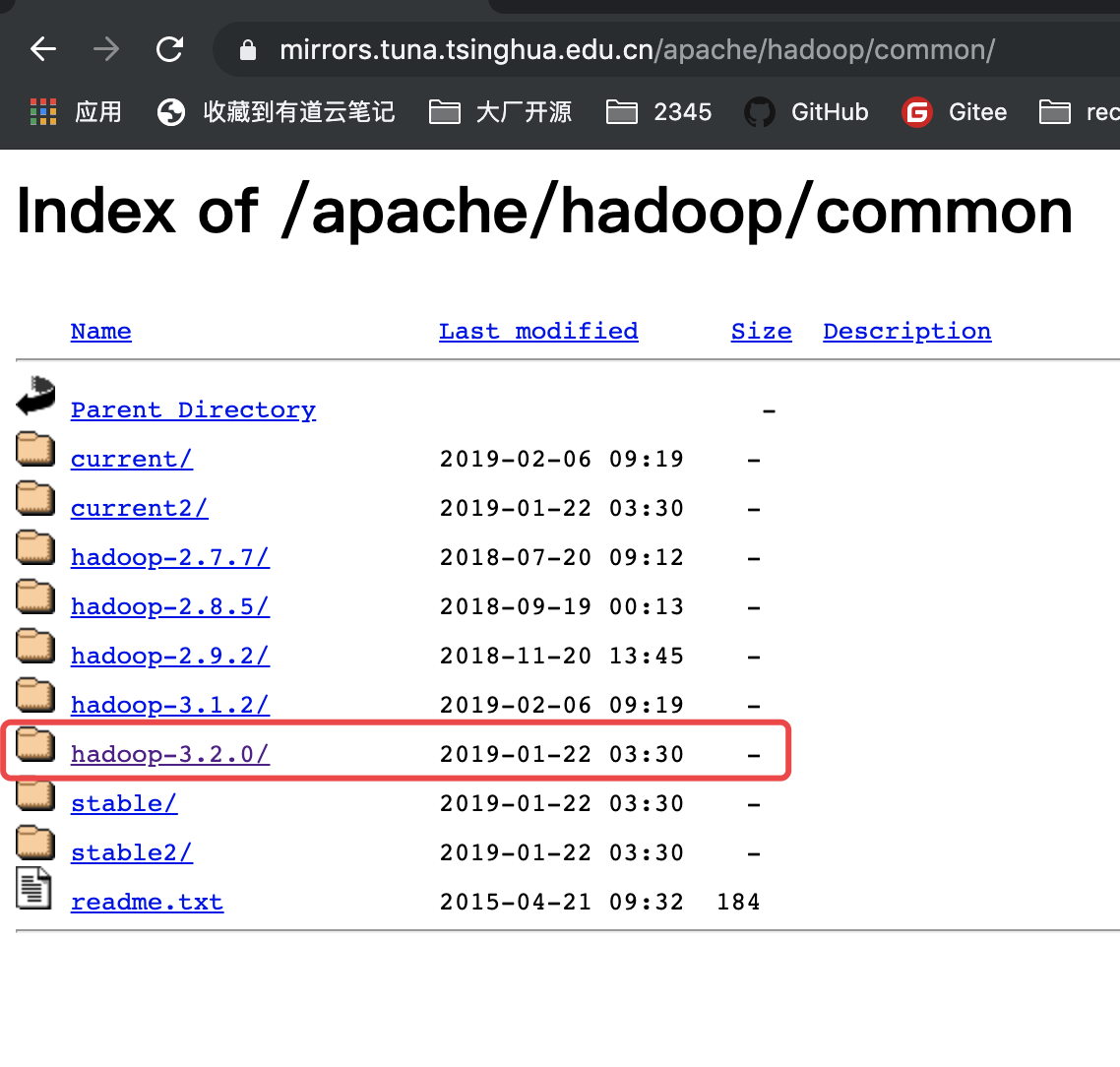
2.2 解压
解压安装包,进入安装包。
├── bin -- 存放命令脚本├── etc -- 配置文件├── include -- 头文件├── lib -- 类库├── libexec -- 类库├── LICENSE.txt├── logs -- 存放日志├── NOTICE.txt├── README.txt├── sbin -- 启动脚本└── share -- 共享
2.3 配置 Hadoop 环境变量
编辑文件:vim ~/.bash_profile ,加入 HADOOP_HOME 信息。
JAVA_HOME=/usr/local/java/jdk1.8.0_201HADOOP_HOME=/usr/local/hadoop/hadoop-3.2.0PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/binexport PATH
2.4 配置 hadoop-env.sh
执行 cd $HADOOP_HOME/etc/hadoop/hadoop-env.sh 添加如下信息: root 换成你的 linux 账户名即可,我这里是 root 用户。
# 配置 JAVA_HOMEexport JAVA_HOME=/usr/local/jdk1.8.0_201# 配置用户名export HDFS_NAMENODE_USER="root"export HDFS_DATANODE_USER="root"export HDFS_SECONDARYNAMENODE_USER="root"export YARN_RESOURCEMANAGER_USER="root"export YARN_NODEMANAGER_USER="root"
2.5 配置 core-site.xml
我们看一下启模式,有三种
默认情况下,Hadoop被配置为在非分布式模式(也就是Local 模式)下运行,作为单个Java进程。这对调试很有用。
显然,不是我想要的。在有限机器的情况下 ,所以选择了伪分布式。
执行 vim $HADOOP_HOME/etc/hadoop/core-site.xml 加入下面内容:
这里需要注意下 hadoop.tmp.dir 的属性值,默认是 /temp/hadoop-{$name} 的,但是还是建议修改成一个磁盘足够的路径。很多数据要存在这个路径下面,比如 FsImage,edits log 等。我之前就没有注意这个属性,结果导致集群后面 Namenode 报错,进入了不可以状态(safe mode),原因是默认路径没有足够的空间存在 fsimage 了。
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property><!--配置临时目录,很重要。很多配置都引用了这个变量--><property><name>hadoop.tmp.dir</name><value>/opt/hadoop_temp</value></property></configuration>
2.6 配置 hdfs-site.xml
执行 vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
机器存储资源有限,所以这里设置 HDFS 的数据块只有 1 个副本。
<configuration><property><name>dfs.replication</name><value>1</value></property></configuration>
2.7 配置 mapred-site.xml
这里,我选择使用 yarn 作为资源调度。(大多数公司的选择)
执行 vim $HADOOP_HOME/etc/hadoop/mapred-site.xml ,添加如下属性:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.application.classpath</name><value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value></property></configuration>
2.8 配置 yarn-site.xml
执行 vim $HADOOP_HOME/etc/hadoop/yarn-site.xml ,添加如下属性:
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property></configuration>
2.9 配置 SSH 免密
执行下面的命令生成秘钥对,并且把公钥加到认证文件中,最后修改权限。
如果遇到错误,请看文件结尾
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsacat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keyschmod 0600 ~/.ssh/authorized_keys
2.10 格式化 HDFS 文件系统
注意:只有第一次安装时才需要执行这个。这里我们初次安装,所以需要格式化系统。
hdfs namenode -format
2.11 使用 Hadoop
启动,Hadoop 伪集群: start-all.sh , 关闭 stop-all.sh
如何查看服务启动成功了呢?
- 查看日志文件是否有错误
- JPS 查看进程是否存在
- 界面查看是都可以访问
日志文件在 $HADOOP_HOME/logs 下面
jsp 命令可以查看 Java 进程,如图,有如下五个进程,则证明上述操作没有问题。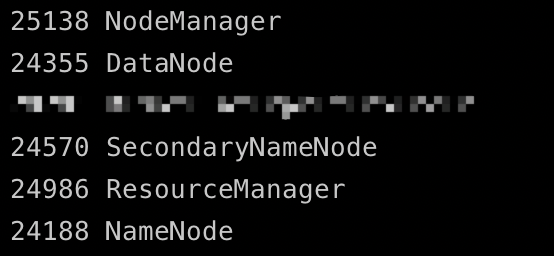
访问 web 服务
http://ip:8088 — 这是 yarn 管理界面
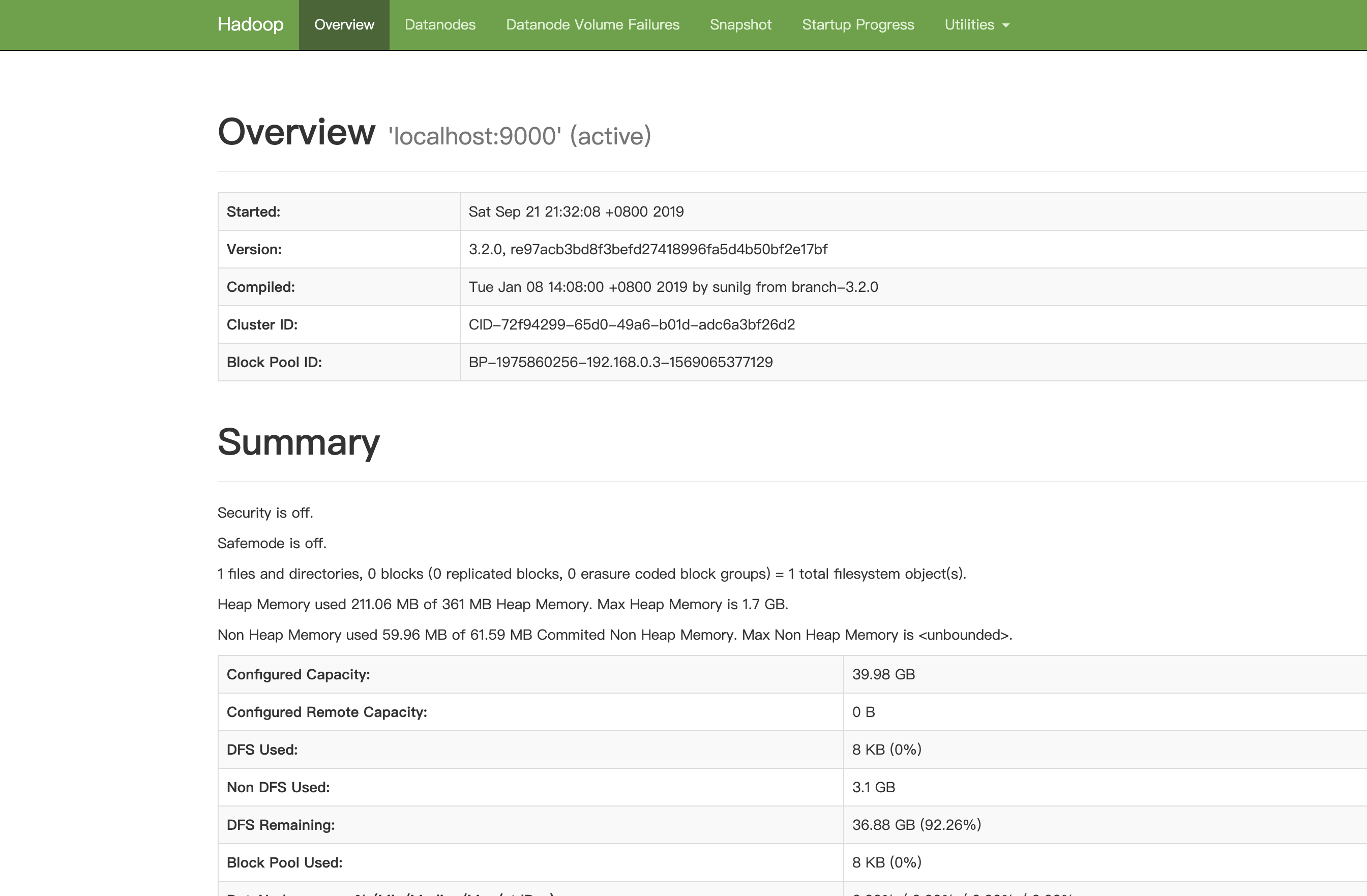
http://ip:9870 — 这是 HDFS 管理界面(hadoop 3.x 正常启动后50070访问不了,hadoop3.x把50070的默认端口修改为9870)
三、安装 mysql
如何安装 mysql 请看:安装 Mysql 教程
四、安装 Hive
4.1 下载
下载 https://mirrors.tuna.tsinghua.edu.cn/apache/hive/,因为我选的 Hadoop 是 3.x 版本的,所以这里安装的 Hive 选的 hive-3.1.2(为什么选择这个版本:http://hive.apache.org/downloads.html)
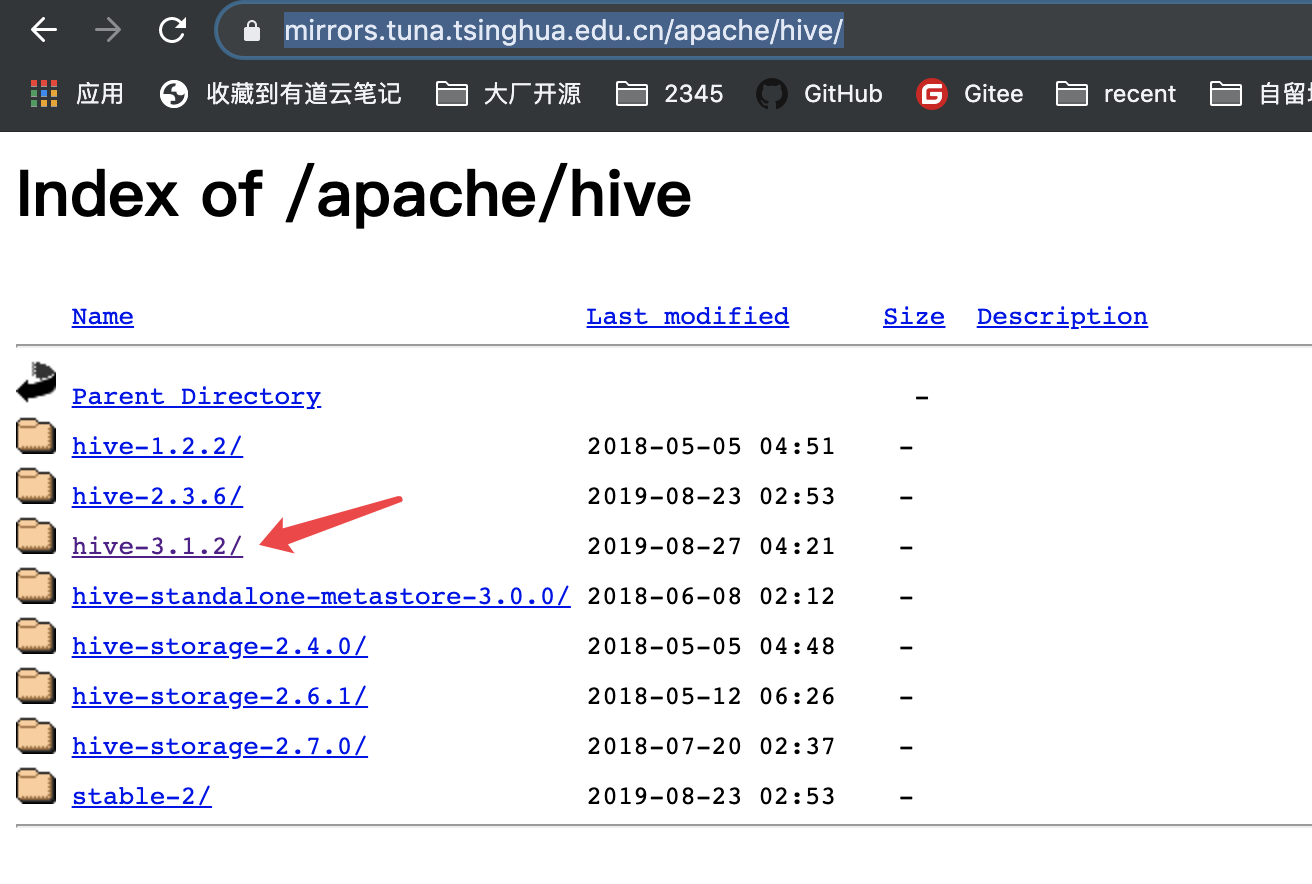
4.2 解压
解压的命令是 tar -zxvf xxx.tar.gz
├── bin -- 执行命令├── binary-package-licenses├── conf -- 配置文件├── examples├── hcatalog├── jdbc├── lib -- 类库,这里一会放置 mysql 的驱动├── LICENSE├── NOTICE├── RELEASE_NOTES.txt└── scripts
4.3 配置 Hive 环境变量。
编辑文件:vim ~/.bashprofile ,加入 HIVE_HOME 信息。配置文件如下(欢迎新成员O(∩∩)O哈哈~)
JAVA_HOME=/usr/local/java/jdk1.8.0_201HADOOP_HOME=/usr/local/hadoop/hadoop-3.2.0HIVE_HOME=/usr/local/hive/apache-hive-3.1.2-bin/PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/binexport PATHexport PATH
4.4 编辑 hive-site.xml
配置默认的文件,并重命名为 hive-site.xml
cp $HIVE_HOME/conf/hive-default.xml.template $HIVE_HOME/conf/hive-site.xml
添加如下信息:主要是配置了 MySQL 的信息、Hiveserver2 的信息
<?xml version="1.0" encoding="UTF-8" standalone="no"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- WARNING!!! This file is auto generated for documentation purposes ONLY! --><!-- WARNING!!! Any changes you make to this file will be ignored by Hive. --><!-- WARNING!!! You must make your changes in hive-site.xml instead. --><!-- Hive Execution Parameters --><!-- mysql管理元数据--><property><name>hive.metastore.db.type</name><value>mysql</value><description>Expects one of [derby, oracle, mysql, mssql, postgres].Type of database used by the metastore. Information schema & JDBCStorageHandler depend on it.</description></property><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value><description>location of default database for the warehouse</description></property><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://jd:3306/hive?createDatabaseIfNotExist=true</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><!--自己mysql的密码哦--><value>123456</value></property><!-- 配置 hiveserver2 --><property><name>hive.server2.thrift.port</name><value>10000</value></property><property><name>hive.server2.thrift.bind.host</name><value>localhost</value></property><property><name>hive.server2.enable.doAs</name><value>false</value></property></configuration>
4.5 创建 /user/hive/warehouse 目录。
hive 创建的数据表默认是放在 /user/hive/warehouse 下面的,所以我们需要在 HDFS 上创建该目录:
hadoop fs -mkdir -p /user/hive/warehouse
4.6 mysql-connector,
下载 mysql-connector, 地址:https://mvnrepository.com/artifact/mysql/mysql-connector-java/5.1.47
下完成之后,放在 $HIVE_HOME/lib 目录下。
4.7 初始化数据库
这一步如果报错无,可能是jar包冲入了。可以参考文末链接解决
Exception in thread “main” java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
schematool -initSchema -dbType mysql
4.8 验证
元数据数据库是否建立。登录 mysql 可以查看(如图,这样就表示 hive 的元数据库建立好了。)
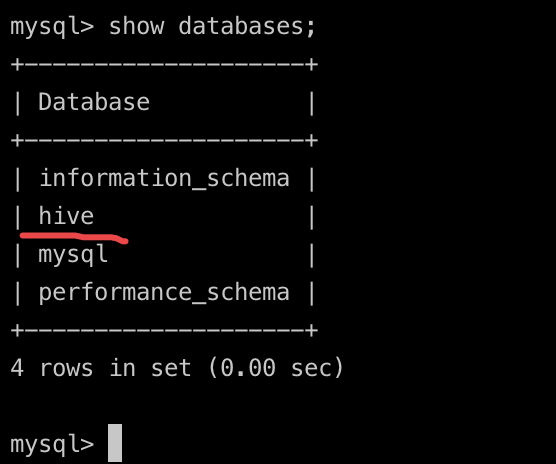
4.9 启动元数据服务
hive —service metastore &
5.0 启动 HiveServer2
HiveServer2支持多客户端的并发和认证,为开放API客户端如JDBC、ODBC提供了更好的支持。
hive —service hiveserver2 &
五、安装 zeppelin
5.1 下载
地址:http://zeppelin.apache.org/download.html
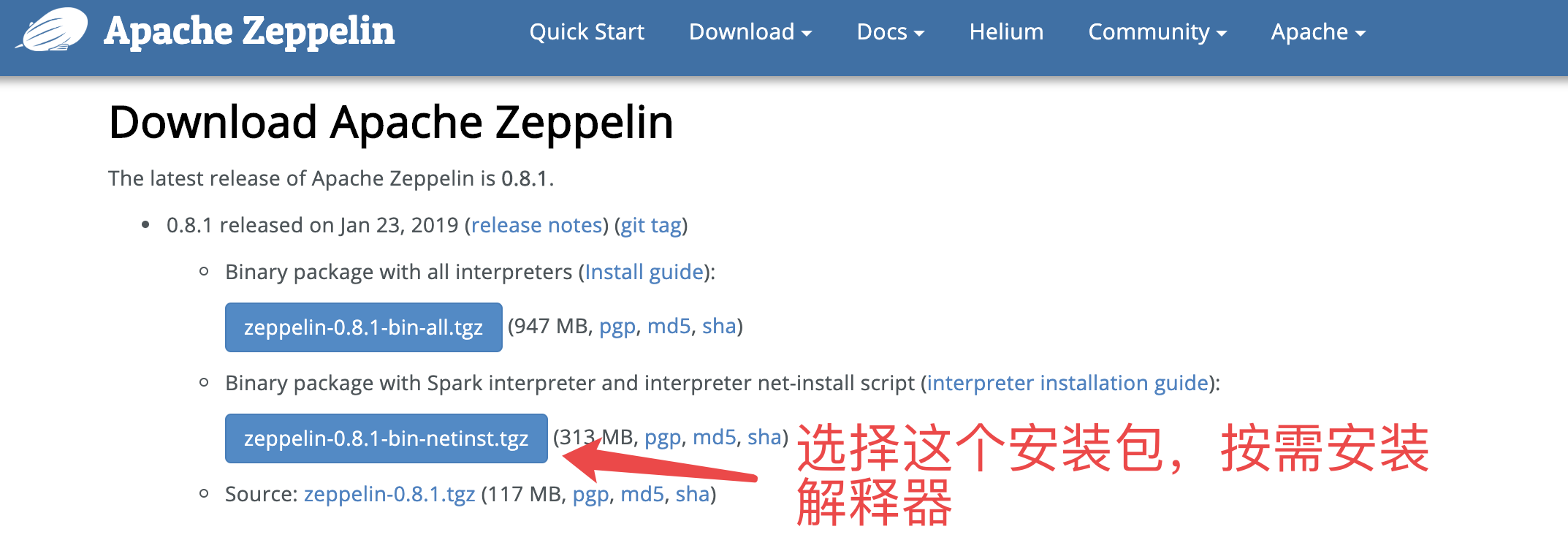
5.2 解压
5.3 安装 jdbc 解释器
install-interpreter.sh --name jdbc
等待安装成功之后,执行下一步。
5.4 配置文件
进入 conf 目录,开始修改配置文件:
1.配置端口以及ip地址 cp zeppelin-site.xml.template zeppelin-site.xml
# 修改下面这个属性,把127.0.0.1 改成主机的 hostname<property><name>zeppelin.server.addr</name><value>127.0.0.1</value><description>Server binding address</description></property>
2.配置 JAVA_HOME等其他环境变量。
cp zeppelin-env.sh.template zeppelin-env.sh
3.配置用户验证
cp shiro.ini.template shiro.ini
接着,编辑文件,修改成下面这样(仅供参考):

5.5 启动 zeppelin
zeppelin-daemon.sh start
5.6 访问 web 界面
访问 localhost:8080,可以看到这个界面,就表示启动成功了。
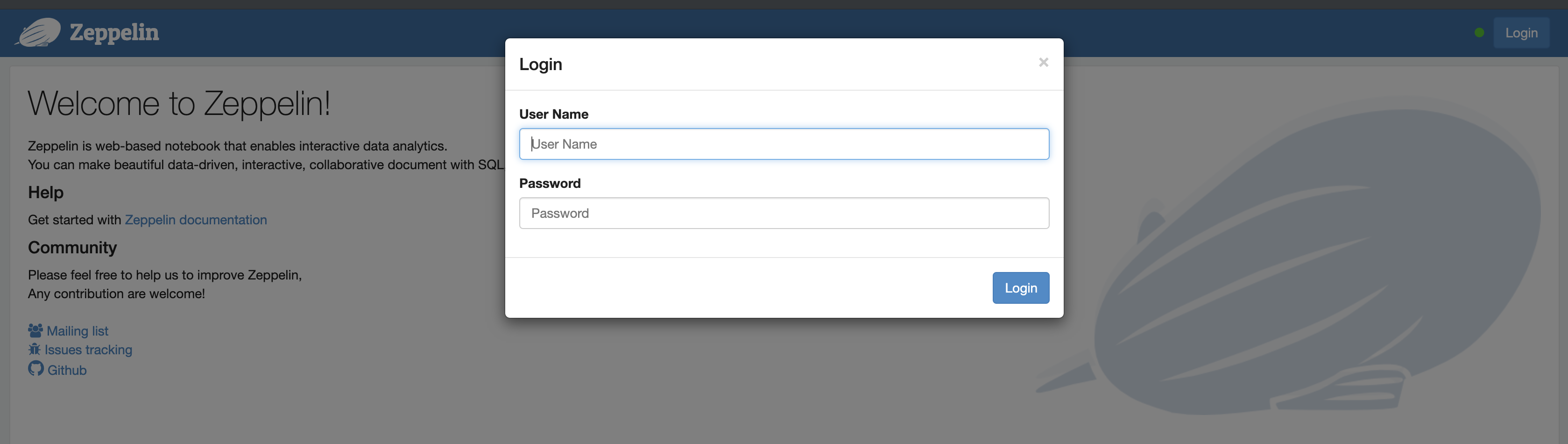
账号和密码是在 5.4 中配置的。
5.7 配置解释器
账户名下面,点击菜单项【interpreter】
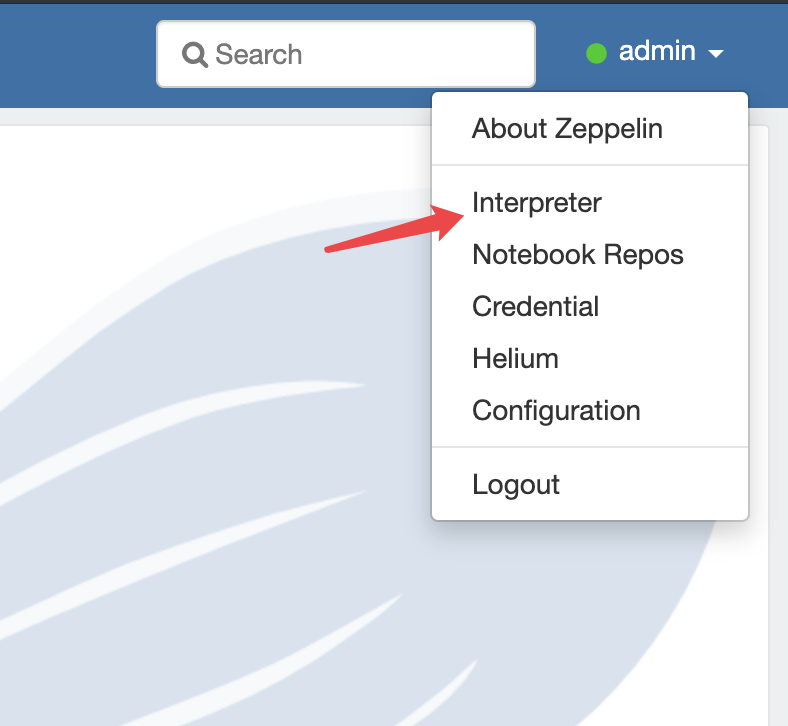
点击 Create ,填写下面标红的信息:
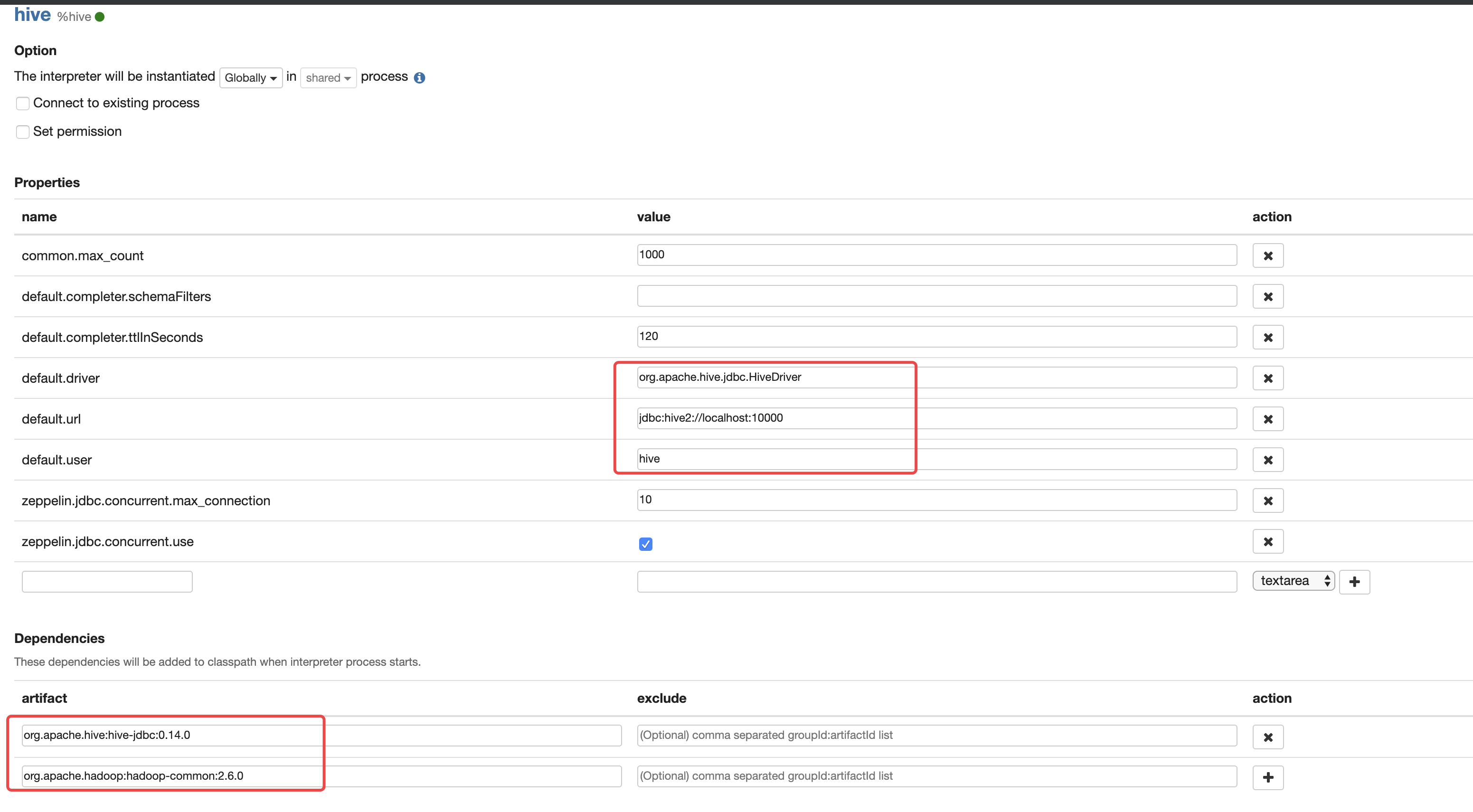
Properties
| default.driver | org.apache.hive.jdbc.HiveDriver |
|---|---|
| default.url | jdbc:hive2://localhost:10000 |
| default.user | hive_user |
| default.password | hive_password |
| default.proxy.user.property | Example value: hive.server2.proxy.user |
Dependencies
**
| org.apache.hive:hive-jdbc:0.14.0 | |
|---|---|
| org.apache.hadoop:hadoop-common:2.6.0 |
使用 zeppelin
至此,我们可以使用 notebook 来编写 sql 查询 hive 中的数据了。
六、参考 && 采坑
- Hadoop 官网
- Hive 官网
- Zeppelin 官网
- https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
- https://blog.csdn.net/qq_32635069/article/details/80859790
- https://www.cnblogs.com/biehongli/p/7693598.html
- https://www.cnblogs.com/weavepub/p/11130869.html#autoid-0-2-1 mysql初始化
- https://blog.csdn.net/u013310119/article/details/78485249 开启 metastore 和 hiveserver2
- https://blog.csdn.net/deeplearnings/article/details/77084435 用户操作ssh authorized_keys文件:Operation not permitted
- https://blog.csdn.net/iteye_20866/article/details/82549809 jps命令不能查看hadoop进程
- https://blog.csdn.net/sinat_34439107/article/details/103914449 jar包冲突
关注我


若有收获,就点个赞吧
0 人点赞
