在本节中,我们将走进用户需要了解的AI核心概念,以便更有效地玩游戏。
- 神经网络介绍
- 神经网络训练
注:下面翻译只提供原文最简单基础版本,进一步理解,可以在官网上看中等和高难度英文原文。
一.神经网络介绍(Neural Network)
为了牢固掌握如何有效地进行训练,我们认为首先要了解人工智能在学习什么。首先,我们将注意到 “AI “是一个人工神经网络。为了解释神经网络是如何学习的,我们将在本文中使用一系列交互式可视化的方法。
1.1神经网络学习什么?
神经网络是一种机器学习模型,能够学习如何执行某些任务。这些任务的范围可以从识别一封电子邮件是否是垃圾邮件到玩一个超级有趣的游戏,如AI Arena! 为了学习如何做这些事情,神经网络试图找出某些数字,使其能够将一些数据转化为其期望的结果。它所学习的数字被称为权重。我们将用一个简单的线性例子来证明这一点。
简单的线性例子
我们要做一个小实验,你可以在屏幕上拨动一堆东西,开始建立你的直觉。使用滑块来调整权重(即让人工智能学习),并拖动拳击手来测试不同场景下的结果。你的人工智能是那个长着尖尖头发的拳击手,你的对手是那个灰色的家伙。 在开始之前,有几件事需要注意。首先,在机器学习中,X通常指的是一组输入,被输入到一个模型中。因此,当你看到X1时,指的是第一个输入,X2指的是第二个输入,以此类推。在这个例子中,我们只有一个输入—相对距离—也就是你的拳手的位置减去你的对手的位置。另一件要注意的事是,当你看到滑块上方的→,这是指将输入转化为与动作相关的数字的权重。例如,如果X1→向左跑等于2.5,那么与向左跑有关的数字=X1乘以2.5。向左跑的数字越大,人工智能选择该行动的概率就越高。
在开始之前,有几件事需要注意。首先,在机器学习中,X通常指的是一组输入,被输入到一个模型中。因此,当你看到X1时,指的是第一个输入,X2指的是第二个输入,以此类推。在这个例子中,我们只有一个输入—相对距离—也就是你的拳手的位置减去你的对手的位置。另一件要注意的事是,当你看到滑块上方的→,这是指将输入转化为与动作相关的数字的权重。例如,如果X1→向左跑等于2.5,那么与向左跑有关的数字=X1乘以2.5。向左跑的数字越大,人工智能选择该行动的概率就越高。
输入Inputs:相对距离
行动Actions:[向左跑,向右跑]
目标Objective:找到一组权重,告诉你的人工智能向对手靠近,不管拳击手们在屏幕上的位置如何。
如果你想得到一点提示—试着把映射到 向左跑的数字变成一个大的正数,而映射到向右跑的数字变成一个大的负数。这样做的原因是,当你的拳手在对手的左边时,相对距离是负数。如果你用一个负数乘以一个负数,那么你就会得到一个正数。因此,通过使映射到向右跑的重量为负数,映射到向左跑的重量为正数,你就可以确保你的拳手会向对手跑去。当你的拳手在对手的右边时,试着计算一下,你会得出同样的结论 这似乎很容易……让我们把事情变得更有挑战性。
增加其它动作
我们将扩展之前的实验,增加一个额外的动作。单一冲撞。以下是新的实验规格。
输入Inputs:相对距离
动作Actions:[向左跑,向右跑,单拳]。
目标Objective:除了靠近你的对手之外,还要尝试让你的人工智能在靠近对手时增加出拳的概率。 这个实验有点难度,因为现在我们必须同时平衡两件事:向对手跑去和只在接近时出拳。如果你还没有想明白,这里还有一个提示—你可以对向左跑和向右跑的映射使用与前面实验类似的权重。但对于单次出拳的权重,你可能想尝试一个小的负数。
这个实验有点难度,因为现在我们必须同时平衡两件事:向对手跑去和只在接近时出拳。如果你还没有想明白,这里还有一个提示—你可以对向左跑和向右跑的映射使用与前面实验类似的权重。但对于单次出拳的权重,你可能想尝试一个小的负数。
增加一个变量
我们再扩展一次实验,增加另一个输入变量。面对对手。这告诉人工智能它是面对对手(+1)还是远离对手(-1)。下面是新的实验规格。
输入Inputs:[相对距离,面对对手]。
行动Actions:[向左跑,向右跑,单拳]。
目标Objective:在人工智能已经学会的基础上,尝试修改权重以增加另一个细微差别:当你的战士面对对手时,增加出拳的概率(而当它面对对手时,减少出拳的概率)。 我敢打赌,这个更难弄明白! 如果你已经试过了,需要一点帮助,你可以让X1的滑块和前面的例子一样,只调整X2的滑块。让映射到单冲的权重成为一个相对较大的正数,让映射到两个运行动作的权重成为负数,其幅度为一半。
我敢打赌,这个更难弄明白! 如果你已经试过了,需要一点帮助,你可以让X1的滑块和前面的例子一样,只调整X2的滑块。让映射到单冲的权重成为一个相对较大的正数,让映射到两个运行动作的权重成为负数,其幅度为一半。
你可能已经注意到,随着每个例子的出现,挑战变得越来越难了。随着实验的进行,这来自于三个方面。
- 行动的数量不断增加
- 输入的数量越来越多
- 策略的复杂性不断增加
你可能还注意到,随着实验的进行,很难精确地实现目标。这是因为我们使用的模型对于我们设定的目标来说过于简单。
1.2神经网络的FTW
为了处理更复杂的关系,我们需要更强大的模型。这就是神经网络的用武之地—它们使用与我们在本文中描述的完全相同的概念,但在层中应用,并使用非线性激活函数。让我们来看看一个相对较小的神经网络。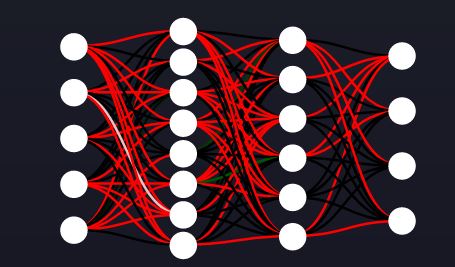
我知道你在想什么…… “为这些简单的线性方程算出权重已经够难的了,我到底怎么才能算出如何改变这些权重?” 这就是梯度下降法的神奇之处,我们将在下一篇博文中讨论这个问题。
二.神经网络训练(Neural Network Training)
在上一篇文章中,我们谈到了神经网络的学习内容。在这篇文章中,我们将谈论神经网络如何学习。需要注意的是,尽管本文中使用的例子是线性模型,但同样的概念也适用于神经网络—尽管神经网络的实现要稍微复杂一些。
2.1神经网络是如何学习的?
如果我们还记得之前的内容,神经网络使用权重来转换数据;它们接受一些输入,并通过各种数学运算产生一个输出。学习是改变权重的过程,从而使输入被转化以实现特定的输出。为了让神经网络产生所需的输出,我们为它提供了一些例子来指导它改变权重的方向。
目标函数Objective function
提供例子只是难题的一部分。我们必须做另一件事是告诉神经网络,当它看到某些例子时应该如何改变权重。一个目标函数正是这样做的—它告诉神经网络训练的目标是什么。一个典型的目标函数是平均平方误差,它告诉神经网络,它应该产生一个尽可能接近于所提供目标的输出。
下面我们用一个简化的例子来说明单个更新的流程。在我们的例子中,我们有一个输入变量和一个权重—我们将它们相乘来得到输出。为了更新权重,我们计算我们的输出和目标之间的差异(这被称为误差)。我们想使误差最小化,所以我们将权重向能产生更接近目标的新输出的方向移动。玩一玩下面的视觉效果,以巩固你的理解!
 权重更新可视化Weight Update Visualized
权重更新可视化Weight Update Visualized
现在我们了解了单一更新的流程,让我们深入到一个可视化的例子中去,使其更加清晰。首先要理解的是碗状的曲线—这是损失函数。由于我们想使误差(或损失)最小化,我们想把球(这代表权重)移到曲线的底部。你可以水平拖动小球,看着它沿着曲线移动。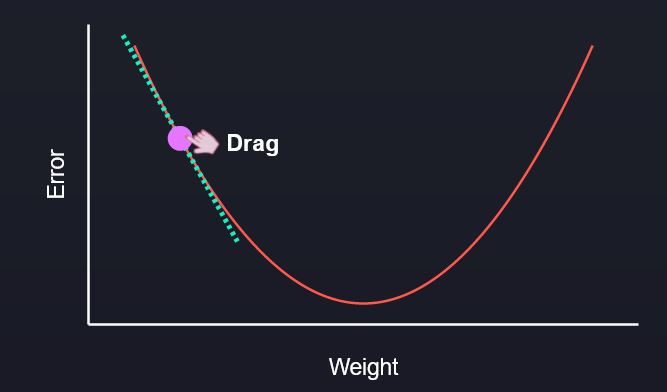
你会注意到,当你水平拖动球穿过图形时,虚线的斜率随着它接近底部而变得更平坦(当它离开时更陡峭)。这个斜率告诉模型要做多大的更新。因此,当它远离底部时,它告诉它要做一个大的更新,但当它接近底部时,它就会放慢速度,采取较小的步骤,因为否则它可能会超调。这都是内置于算法中的—相当棒,不是吗?
学习率与周期
机器学习的训练通常是一个迭代的过程。我们多次应用相同的更新规则,最终落在曲线的底部(即最小化误差)。我们在下图中用箭头显示了每次后续的更新。我们有两个数字,你可以通过切换来建立对所发生情况的直觉。第一个是学习率,它决定了每次更新的步骤大小。我们将学习率乘以前面视觉中虚线的斜率,得到更新的幅度。第二个是周期(epochs),它告诉模型要连续应用多少次更新。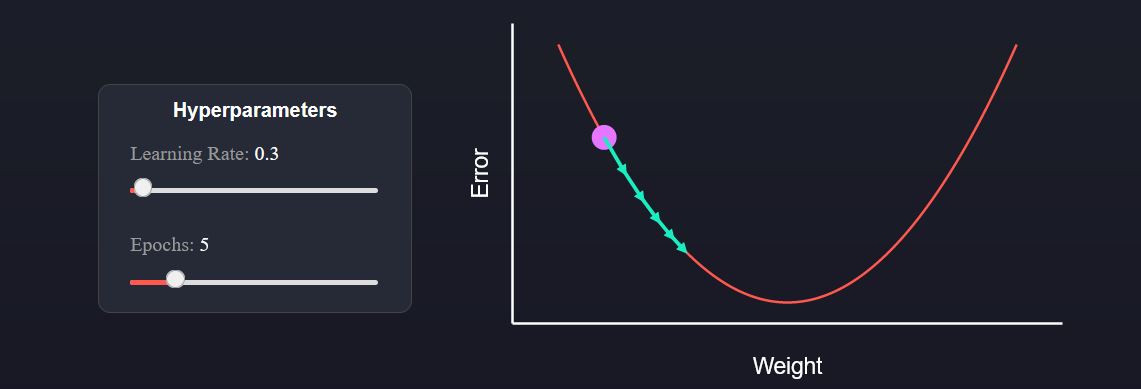 在决定训练的学习率和多少个周期数时,必须取得一个平衡。选择一个大的学习率来加快学习速度可能是很诱人的。但是你会发现,如果它太大了,就会导致更新不断过冲,永远找不到曲线的底部。然而,如果学习率太小,那么可能是一个痛苦的经历,等待很长时间的训练,却几乎看不到任何改善 在不介绍更多高级技术的情况下,我唯一能推荐的是尝试一些不同的训练方案,找到最适合你的方案。
在决定训练的学习率和多少个周期数时,必须取得一个平衡。选择一个大的学习率来加快学习速度可能是很诱人的。但是你会发现,如果它太大了,就会导致更新不断过冲,永远找不到曲线的底部。然而,如果学习率太小,那么可能是一个痛苦的经历,等待很长时间的训练,却几乎看不到任何改善 在不介绍更多高级技术的情况下,我唯一能推荐的是尝试一些不同的训练方案,找到最适合你的方案。
结语
在这一点上,你已经掌握了如何驾驭训练环境和提高战士能力的基本知识。在未来的博文中,我们会给你更多深入的提示,告诉你如何利用我们在AI Arena提供的所有训练能力。

若有收获,就点个赞吧
0 人点赞
