英文官方文档:链接
全文分为6个章节
- 开始
- 拳手属性
- 游戏机制
- 训练
- 战斗
- 融合
一.开始
大体来说,AI Arena是一个用户收集NFTs拳击手以在战斗中竞争的格斗游戏。整个应用中有很多内容,但不必担心,我们将在文档中为你介绍所有内容。
买卖
每次AI Arena投放新系列时,用户都有机会从区块链购买新的拳击手。用户可以在市场上出售他们的拳击手或购买更多的拳击手。否则,获得额外拳击手的唯一途径就是在战斗中赢取。
机器学习
当你听到人工智能(AI)这个术语时,你自然会想:它是如何获得智能的?主要有两种方法:启发式和机器学习。启发式基本上是人通过程序创建的规则。另一方面,机器学习是机器通过观察数据自行学习的地方。
每个拳击手都由人工神经网络提供动力,并使用机器学习改进其作战方式!
去中心化
AI Arena是一个去中心化应用-所有数据都存储在以太坊或IPFS上:
以太坊:NFT及其组件(dna、战斗属性、神经网络参数、令牌URI)、公平游戏验证和战斗记录。
IPFS:所有可视化资产、每个NFT的元数据、神经网络架构和网站本身。游戏概述
什么是AI Arena?
AI Arena是一与任天堂明星大乱斗和街头霸王等游戏极为相似的格斗游戏。但是,有一个重要的区别-你不能控制你的拳击手…
自治代理
如果你不能控制你的拳手,那么它是如何战斗的?每个拳手都由人工智能提供动力,人工智能会告诉它在特定情况下应该采取哪些行动。你的目标是让你的人工智能越来越好。每个拳手都有不同的人工智能,所以能不能将你的拳手训练成拳王完全取决于你!
训练你的人工智能
您可以将此游戏视为您正在训练一名准备战斗的拳手的游戏。你可以通过配置它的训练方案或与之对抗来做到这一点,这样它就学会了模仿你的动作!
收集拳手
用户可以通过赢得战斗来增加他们的拳手数量。每一场胜利都让他们有机会克隆对方拳手的智能,他们可以利用这些智能与自己的一个人工智能合并,创建一个新的拳手!二.拳手属性
我们将介绍使每个NFT拳手独一无二的所有主要属性。
视觉外观
每个拳手都有一个独特的物理外观,它是各种物理属性的组合。考虑到拳手可能具备的所有属性组合,总共有42000000种不同的视觉外观。随着我们推出专属属性和新一代拳手,独特视觉外观的数量将不断增加!
视觉外观并不是使每个NFT独一无二的唯一因素——它的战斗能力是另一部分。我们将看到,作战能力将使两个拳手NFT极不可能是相同的!
战斗能力
有几个特性会影响拳手的作战能力:
战斗属性:拳手在战斗中的优势和劣势。我们有四大类:力量、速度、防御和准确性。所有这些属性的范围从1到100不等,这意味着一个拳手可以拥有1亿种不同的战斗属性组合。我们还有火、水、电等拳手。这些还没有纳入战斗,但将在未来的版本中出现。
招式:拳手会用的所有动作。目前,我们有一套通用的招式可供所有拳手使用,但随着时间的推移,我们计划加入罕见的招式,这些招式将在拳手创建时随机分配。此外,每种类型的战斗机(火、水和电)都有一个独特的动作。
神经网络:这决定了拳手在各种情况下将采取的行动。神经网络是一种灵活的机器学习模型,理论上可以学习任何东西(在某些假设下),我们正在使用它们来帮助我们的NFT学习如何战斗!我们将会有无限多的神经网络配置,这意味着当考虑NFT的所有方面时,我们可以确定它们中的每一个都是真正独特的!物理属性
属性类别
当拳手生成时,我们使用Chainlink VFR创建一个随机DNA序列,用于提取物理属性。总的来说,我们有8个物理属性类别组成了每个拳手的视觉外观。每一代拳手在给定DNA序列的情况下都会有一套不同的属性。下面我们展示了初代拳击手的示例:
属性稀有性
每个物理属性都有一个与之相关的稀有性。共有4种珍品:青铜、白银、铂金和钻石。你会幸运地获得所有钻石属性吗?
战斗属性
优势和劣势
每个拳手都有四个影响其作战能力的属性:力量、速度、防御和准确性。所有属性都在1到100的范围内,其中100分是最好的。重要的是要注意,这些属性永远不会改变,即使训练拳手。因此,将训练视为在“天生”条件下学习战斗。要了解更多信息(并了解一些很酷的学习动态),请查看我们的博客。
力量
力量越大,拳手对对手造成的伤害就越大。每个拳手的初始生命值为100,每个拳手对其对手造成的最小和最大伤害取决于其所采取的行动。举个例子,假设一个拳手做出了一个最小伤害为5,最大伤害为30的动作。力量为1的拳手造成5点生命伤害,力量为100的拳手造成30点生命伤害。介于两者之间的任何东西都是最小值和最大值之间的线性插值。例如,如果攻击成功落地,力量为35的拳手将造成(0.35 x(30-5)+5)=13.75点生命伤害。
速度
速度越快,一个拳手在一段时间内所能覆盖的距离就越远。与力量类似,最小和最大速度分别为5%和20%。速度是指拳手在一次冲刺中可以移动的擂台百分比。我们使用百分比是因为它是一个通用的单位,在所有屏幕大小上都是一致的(不同于像素)。与力量类似,我们使用线性插值计算拳手在一次冲刺中可以覆盖多少屏幕。
防御
每个拳手都有一个防护罩,其初始生命值为20。当手持盾牌时,战士可以阻挡对手的攻击。但是,每次成功的攻击都会降低盾牌的生命值。防御越高,对盾牌造成的伤害就越小(因此,他们持有盾牌的时间越长)。
准确度
准确度是指攻击将落在对手身上的概率。因此,准确度越高,拳手对对手造成伤害的可能性就越大。例如,一个准确度为70的拳手将平均打出70%的有效攻击。招式
每一个拳手在其招式库中都有各种各样的动作。目前,拳手可用的招式相对简单,但随着时间的推移,我们计划采用更多的招式。我们认为,与其解释每一步,不如让你自己尝试一下:
交互演示人工神经网络
从状态到行动的映射
我们大多数人都过着自己的生活,不会过多地思考我们为什么要做我们所做的事情。在没有太过哲学化或技术化的情况下,我们所做的每件事都隐含着从状态到行动的映射。换言之,我们的大脑正在告诉我们的身体在每一种情况下该做什么。
例如,假设我们开车去上班,接近黄灯。在那个时间点上的所有信息都是我们的“状态”(例如:你有多晚,你是否关心准时上班,灯是否变黄等等)。所有这些信息,再加上你的大脑是如何“连接”的,将决定你在这个场景中做什么。
为什么需要神经网络?
神经网络被称为通用函数逼近器。简单地说,这意味着理论上它可以学习任何映射,这是完美的,因为我们正在尝试学习映射!为了介绍我们今后将使用的一些术语,从状态到行动的映射通常被称为策略。为了让拳手的神经网络学习策略,我们使用模拟学习和强化学习,我们将在训练部分进行讨论。
结构
我们使用前馈神经网络作为模型结构。将结构视为机器学习模型的框架是有帮助的。它由神经元、权值和激活函数组成。请注意,神经网络也使用偏差,但我们排除了它们,以使对非技术人员的解释更简单。为了更好地理解神经网络,我们强烈推荐迈克尔·尼尔森的书。我们还写了关于神经网络的互动文章,你可以看看!对于我们的应用程序,神经网络架构存储在IPFS上。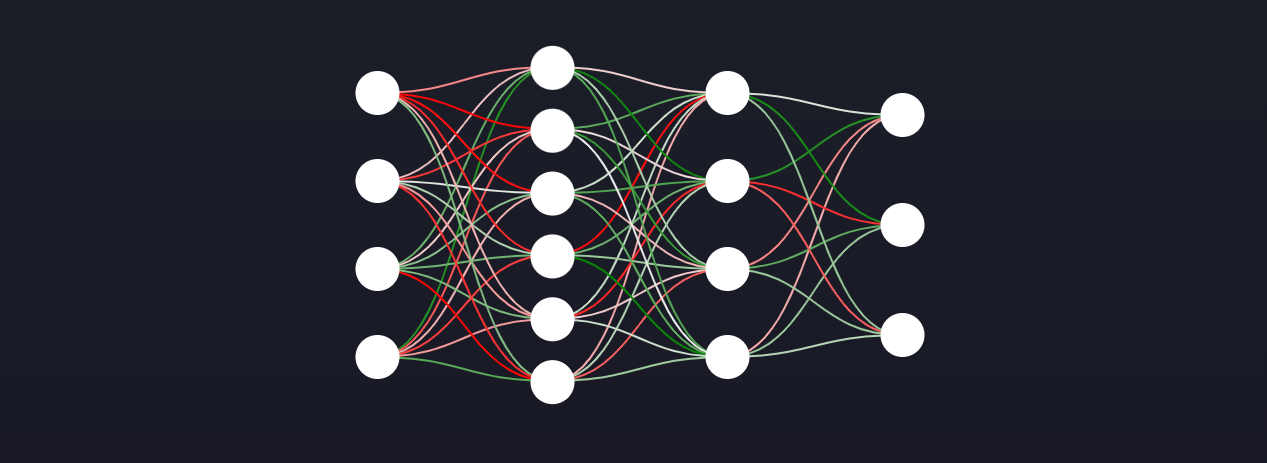
权值
在上图中,神经元之间的连接称为权值。当你听说神经网络正在“学习”时,所发生的是它正在改变权值的值。权值最终将决定状态如何映射到动作,这意味着我们可以将权值解释为“智能”。神经网络权值对于每个NFT都是唯一的,并存储在以太坊上。三.游戏机制
本节将介绍有效玩游戏所需了解的关键机制。
状态
状态是环境在任何时间点的快照。人工智能利用这一观察结果来决定做什么。换句话说,状态是神经网络决策过程中使用的输入文本。
更多细节即将公布。状态
什么是状态?
状态是环境在某个时间点的表示。它并没有封装环境的所有信息——只是研究人员认为必要的信息。例如,一些研究人员使用屏幕上的所有像素作为状态,让AI计算出像素代表什么。其他研究人员根据他们认为对决策过程重要的因素手工调制。
对于我们的游戏,我们手工制作了变量,因为我们希望限制最初使用的神经网络的大小。因此,研究人员不必担心制造大量的CNNs,因为CNNs的计算量非常大。我们关心的是为所有人提供平等的机会——我们希望奖励能够更好地训练人工智能用户,而不是奖励拥有更多资源的用户。
我们使用哪些变量?
下面是状态中包含的变量列表。需要注意的是,我们将使用下标1表示您的AI,下标2表示对手。此外,竞技场的左边界的X位置为0,右边界的X位置为1。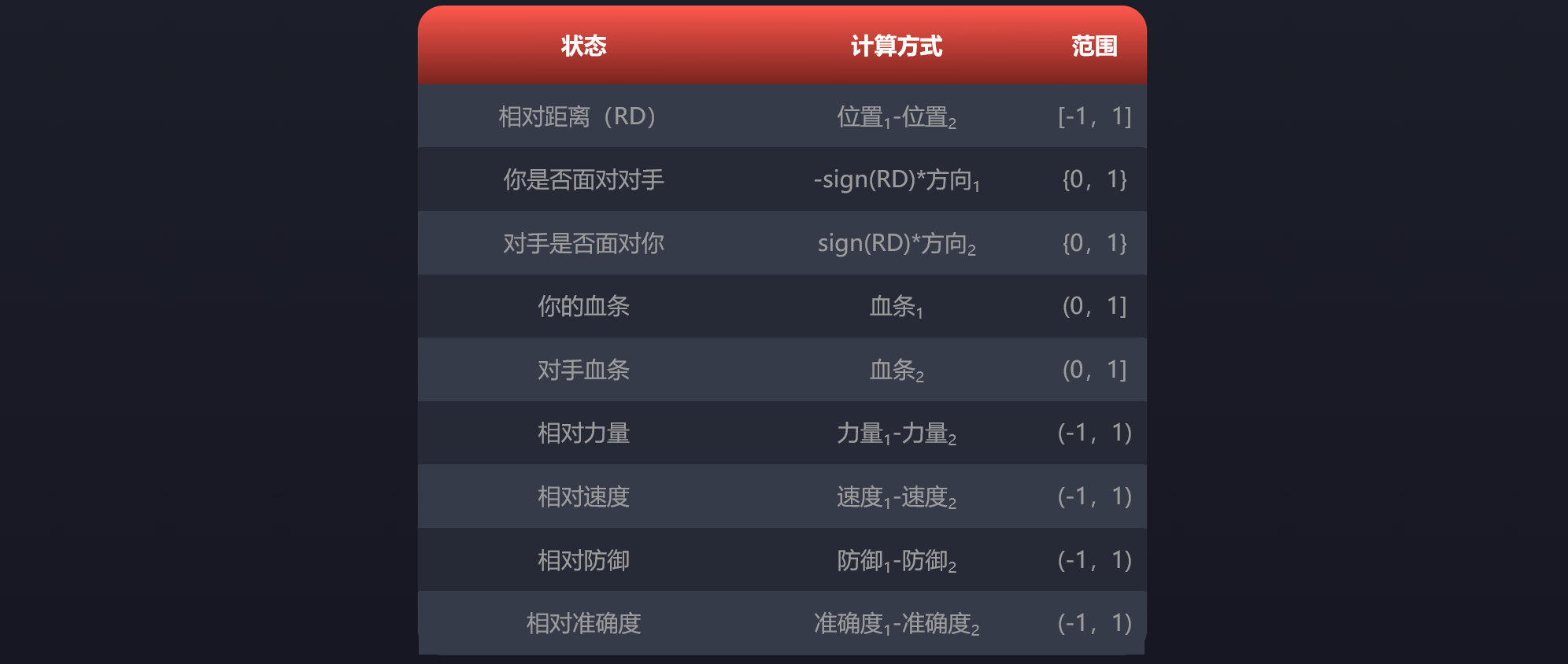
四.训练
训练概述
在本节中,我们将介绍训练的概念。这是改变神经网络中权值的过程,以使人工智能以某种方式起作用。例如,如果我们在对手面前,我们可能希望我们的战士出击。有一系列的权值可以实现这一点,训练的重点是让AI学会在特定场景中采取特定的行动。我们在应用程序中嵌入了以下培训计划:
模仿学习
为了学习如何战斗,你的AI将观察你并学习模仿你的动作。
自我学习
为了学习你无法教给它的技能,你的AI将与自己的副本对抗,以不断提高。为什么你的AI需要训练?
随机初始化
首次创建NFT拳手时,神经网络权值也随之生成。这意味着它似乎会随机采取行动,因为它不知道在什么情况下应该采取什么行动。因此,为了准备战斗,我们必须训练它,使它学会一个好的作战策略。
随机策略
正如神经网络章节中提到的,从状态到动作的映射称为策略。换句话说,策略定义了代理在某些情况下的行为方式。下面我们演示一个新初始化的拳手,它还没有学会一个好的战斗策略,所以只是随机行动:
演示模仿学习
通过观察学习
理解模仿学习的最好方法是想象你是一个师父,你的AI是一个你正在准备战斗的战士。你用你的人工智能进行搏击,它学习模仿你在特定场景中的动作。我们正在写一篇关于模仿学习的综合博文,到时候会将其链接到这里。
演示
让我们看看实际情况!你是左边的灰色斗士,你的AI在右边。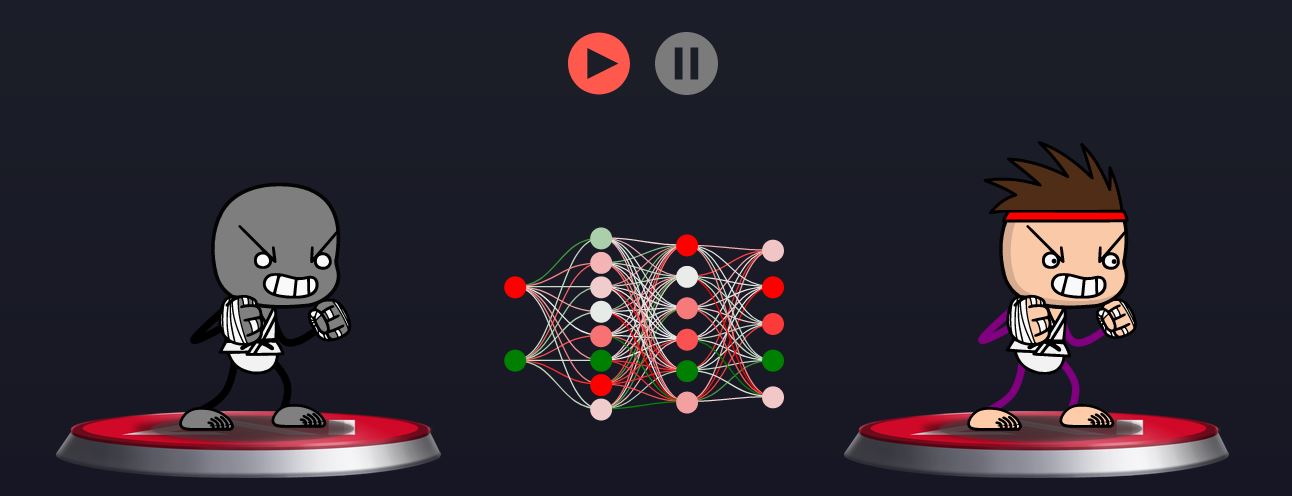 测试一些动作,观察ai如何模仿你。请注意,它不会立即出现,因为神经网络需要一点时间来学习,所以在人工智能学会之前,你可能需要重复你的动作几次。为简单起见,我们只允许您使用以下操作:向左跑、向右跑、单拳、双拳和防守。小贴士:试着与ai面向相同的方向,因为这是状态的一部分(即它在决定采取哪种行动时考虑的信息的一部分)。
测试一些动作,观察ai如何模仿你。请注意,它不会立即出现,因为神经网络需要一点时间来学习,所以在人工智能学会之前,你可能需要重复你的动作几次。为简单起见,我们只允许您使用以下操作:向左跑、向右跑、单拳、双拳和防守。小贴士:试着与ai面向相同的方向,因为这是状态的一部分(即它在决定采取哪种行动时考虑的信息的一部分)。
交互演示自我学习
完美匹配
如果有一个完美匹配的拳击搭档,那就是你自己。通过自我学习,你可以复制你的AI,并让它与克隆人对抗。这样的话,它总是在不断地挑战自己,不断地改进。
不同的学习范式
通过模仿学习,人工智能通过观看演示进行学习。在自我学习中,AI像对手一样学习和战斗没有多大意义,因为对手是人工智能本身的克隆。这就像是通过看着自己在镜子里打拳来学习如何打拳(之前没有任何关于打拳应该是什么样子的概念)。但是如果没有专家向人工智能展示如何战斗,那么它如何学习该做什么呢?人类学习的方式也是一样——通过奖励。
想象一下,你正在学习打架,有人打了你的脸——很少有人会喜欢。我们可以把这看作是一种消极的奖励。另一方面,如果你打出了一拳,我们可以将其视为积极的奖励。人工智能将学会采取行动给予它更多的正面奖励,而减少采取行动给予它负面奖励。这是强化学习中使用的典型框架。现在人工智能有了一种自己学习的方法,而没有专家告诉它该怎么做!
专业提示:我们建议在使用自我学习之前先使用模仿学习。原因是当神经网络被随机初始化时,它不知道如何战斗,并且会采取随机行动。可能需要一段时间,它才能打出一拳,并意识到这很好。但是如果我们给人工智能一个坚实的基础,它将学习得更快,因为它不需要从零开始,比如击中一拳是好的。
当应用程序中集成了自我学习时,交互式视觉效果就会出现。定制训练
Python环境
我们计划为个人研究人员引入一个python环境来训练他们自己的模型。目前,用户仅限于使用我们在应用程序中提供的两种培训方法,但随着时间的推移,我们希望应用程序成为一个研究人员可以导入其自定义培训模型并将其放入区块链的地方。
马上就来。五.战斗
我们目前有两种可用的作战模式:模拟赛和排位赛。我们计划在中短期内整合另外两种作战模式。
模拟赛
用户可以测试他们的拳手对抗竞技场预先训练的人工智能。在这种模式下,没有回报奖赏。通常,此模式用于确定您是否准备好让您的拳手投入一场具有实际经济回报/后果的战斗,或者您是否需要进行更多训练。
排位赛
用户让他们的拳手对抗来自世界各地的其他人。我们的目标是努力攀登排行榜,成为竞技场的冠军!你在排行榜上的排名越高,赢得一场战斗的边际回报就越高。
目标
虽然每种战斗模式都有其独特之处,但它们都有一个共同的目标:在指定的时间内降低对手的所有生命值。模拟赛
在模拟赛模式下,您可以在无风险的环境中测试您的AI。我们有一套经过预先培训的人工智能供您对抗。您可以使用此环境作为衡量标准,告知您是否准备好与世界各地的其他AI对抗,或者是否需要返回训练环境。
对手
我们目前有5种不同级别的人工智能,你可以在模拟赛模式下对抗它们。随着等级的增加,他们的智力和战斗属性都会提高。
PS-有三款AI的皮肤是仿照AI Arena的创始人设计的。所以如果你对游戏感到失望,来模拟模式,打败我们。。。如果你能的话。。。排位赛
排位赛可以被视为是针对来自世界各地的AIs的单边战。控制选定对手的用户不必同意这种类型的战斗——他们的AI有自己的想法,可以自己做出决定。因此,对手的战斗记录不会受到影响——只有你的会受到影响。
得分
排位赛的结果被添加到拳手的记录中。一场胜利让一名拳击手得3分,一场平局让他们得1分,一场失败让他们得0分。这些分数用于在全球排行榜上对每一位拳手进行排名。
对手选择
潜在对手将根据其在排行榜上与您的拳手的接近程度被放置在一个池中。然后从该池中随机选择一名对手。这可以确保你总是与你的AI技能水平相似的某人作战,以保持从战斗中获得代币的概率一致。
奖励
AI Arena将向排名靠前的战斗的胜利者发放代币。颁发给获奖者的代币数量取决于他们在排行榜上的排名。你的等级越高,你收到的代币越多。确切的代币经济学仍有待研究。对赌赛
对赌赛是一个用户请求与另一个用户的AI战斗的双边战斗。请求用户必须确定这场比赛的赌注,而且对手有机会对赌注进行协商。
下注
用户可以在对赌赛中投入两种资产:代币和情报。
代币下注
各方下注的代币数量不必相同。事实上,通常排名较低的拳手会比排名较高的拳手下注更多的代币,以获得与他们作战的机会,并有可能赢得他们拳手的智能。
智能下注
用户可以决定是否将其拳手的智能作为赌注。如果你输掉了一场你赌智能的比赛,你不会输掉AI。比赛的胜利者只是复制了对手拳手的智能,他们可以在以后的时间里用它来生成一个新的拳手AI。六.融合
赢得对赌赛并获得对方拳手智能的用户可以随时使用该智能生成新的拳手。为了生成一个新的拳手,用户必须克隆一个自己的拳手,并融合两种智能。接下来,我们将把克隆人和对手的智能称为来源,并将所得智能称为合并智能。这种新型拳手还将获得新的物理外观和战斗属性。
随机属性
物理属性和战斗属性都是随机生成的,其生成方式与为新购买的角色生成的方式相同-通过Chainlink VRF。
合并智能
为了得到融合的智能,我们首先要从源神经网络中提取染色体,然后进行交叉和变异。然后,我们将染色体重塑为一个神经网络,以便它可以用于战斗。要了解更多关于这些技术的信息,请查看这篇综合性的博客文章。染色体
平展权值
如前所述,神经网络的“智能”是它学习到的一组权值。因此,如果我们希望合并的神经网络包含来自这两个来源的智能,我们必须找到一种方法来组合它们的权值。第一步是创建所有权值的列表-我们将此步骤称为展平权值,因为它们自然具有3D结构(2D矩阵阵列)。
注:下面的视觉表现纯粹是为了获得直觉,理解“展平”的含义。它显示的是神经元被压扁,而不是权值,因为它太凌乱,无法直观地显示权值被展平。
演示
重组权值
在通过交叉和变异创造出一条新的染色体后,我们必须将其重塑为一个神经网络,以便在战斗中使用!交叉
为什么要交叉?
在合并过程中,我们必须做的第一件事是执行交叉。这是将两条染色体结合形成合并染色体核心的过程。有许多不同的方法来执行交叉,你可以在下面的博客文章中看到。然而,对于本应用程序,我们仅实施以下两种方法,并在繁殖时随机选择一种:
单点法
这种方法是您随机选择一个点并拆分两条染色体,然后你从每个染色体上取一半,把它们放在一起,得到合并的染色体。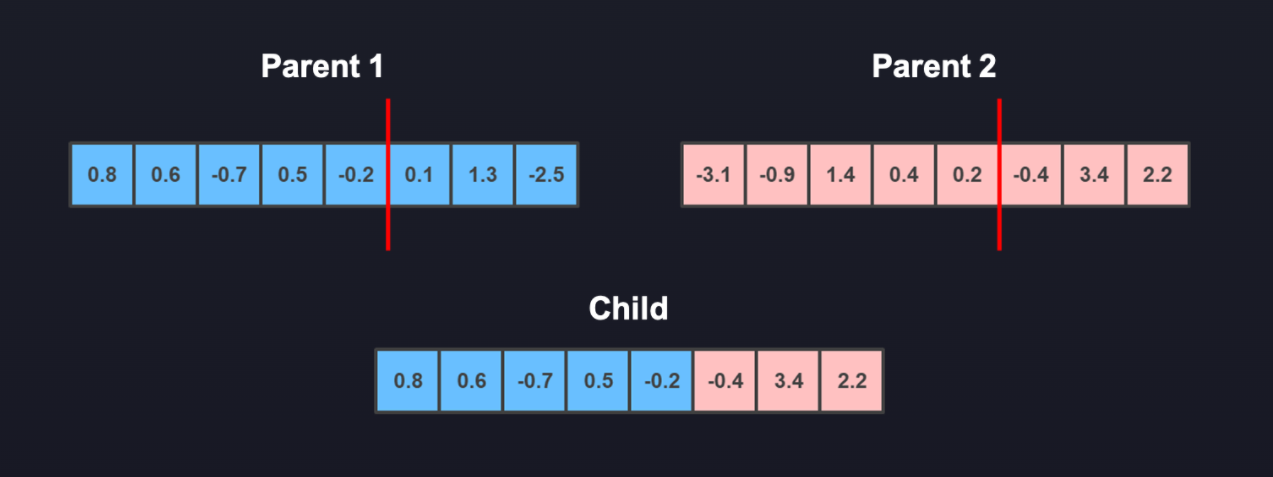
双点法
这种方法是您随机选择两个点,取一条染色体的两端和另一条染色体的中间,然后将它们结合形成合并的染色体。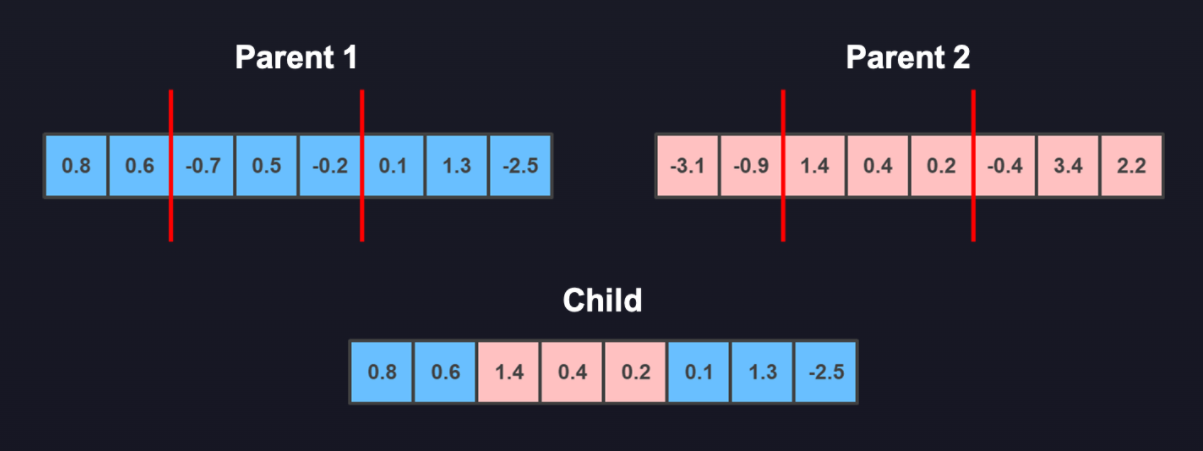
突变
为什么要突变?
虽然交叉是获得合并染色体的主要方法,但我们也进行变异以增加遗传多样性。这一点很重要,因为交叉只是源染色体的重组,这意味着合并的AI受源染色体的限制。如果我们想让合并后的人工智能比两种来源都好,我们需要变异一些基因!与交叉相似,在下面的博文中可以找到许多不同类型的变异。在本应用程序中,我们只实施以下两种方法,并在繁殖时随机选择一种:
噪音
在染色体上随机选择一个基因(个体权值)并向其添加噪声(随机数)。
交换
随机选择两个基因并交换它们在染色体上的位置。

若有收获,就点个赞吧
0 人点赞
