0.开篇
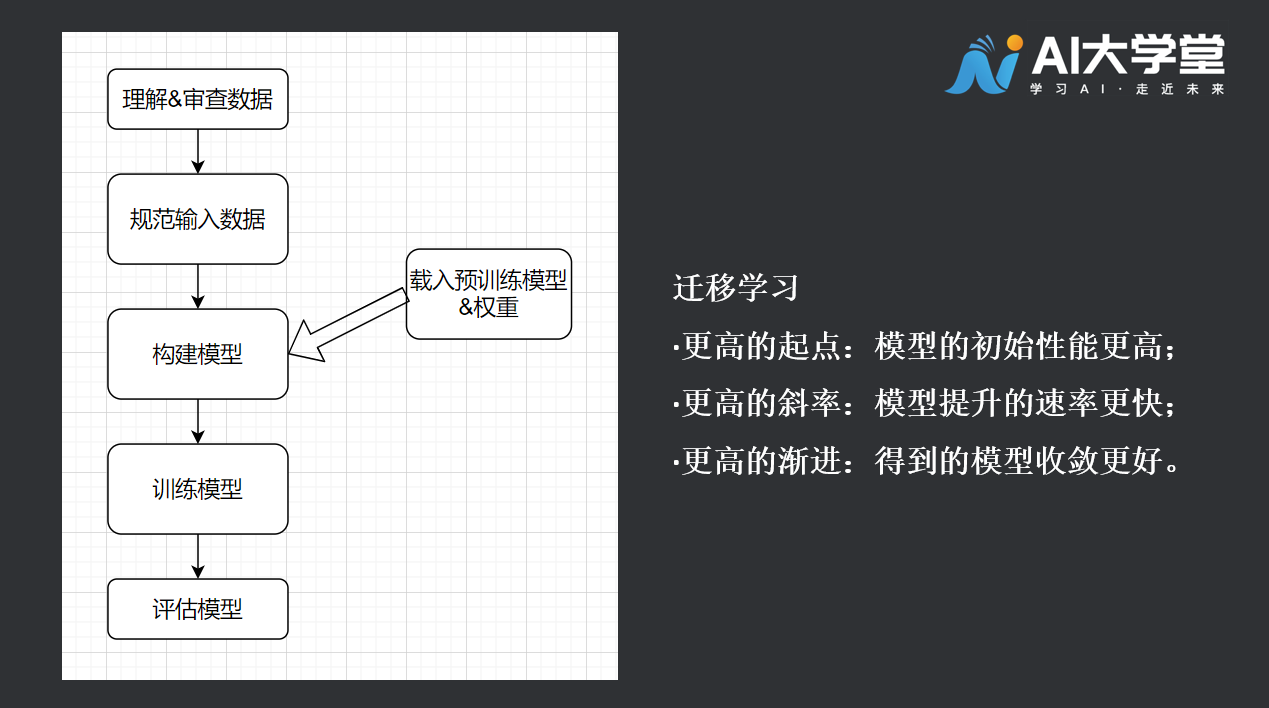
如果模型已经学会了“骑自行车”,那么让它学会“骑摩托车”是不是更容易一些呢?像这样,借鉴之前的学习经验,产生举一反三的效果,这就是迁移学习的思想。当然,实际操作上会更复杂一些,我们先对迁移学习有个大致的感觉。
1.什么是迁移学习
迁移学习,是把已训练好的模型(预训练模型)参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务都是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习。
我们来学习一个迁移学习的模型。
2.实例应用:猫狗识别
2.1数据准备
导入所需要的库:
import matplotlib.pyplot as pltimport numpy as npimport osimport tensorflow as tffrom tensorflow.keras.preprocessing import image_dataset_from_directory
数据下载,从指定的网址下载训练集和验证集。
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')train_dir = os.path.join(PATH, 'train')validation_dir = os.path.join(PATH, 'validation')BATCH_SIZE = 32IMG_SIZE = (160, 160)train_dataset = image_dataset_from_directory(train_dir,shuffle=True,batch_size=BATCH_SIZE,image_size=IMG_SIZE)
验证集数据:
validation_dataset = image_dataset_from_directory(validation_dir,shuffle=True,batch_size=BATCH_SIZE,image_size=IMG_SIZE)
至此,我们已经准备好了数据集。让我们来看看它是什么样子的,我们打开训练集的9张图片,并且显示对应的标签值:
class_names = train_dataset.class_namesplt.figure(figsize=(10, 10))for images, labels in train_dataset.take(1):for i in range(9):ax = plt.subplot(3, 3, i + 1)plt.imshow(images[i].numpy().astype("uint8"))plt.title(class_names[labels[i]])plt.axis("off")
应该得到类似下面的结果,可能我们显示的图片不尽相同,这是因为我们将数据集中的数据进行了打乱(shuffle)。
因为原始数据不包含测试集,我们手动制作一个测试集,用于检测模型的预测效果。第一句中的tf.data.experimental.cardinality是为了查看验证集中有多少数据,接下来我们在验证集中抽取20%作为测试集数据:
val_batches = tf.data.experimental.cardinality(validation_dataset)test_dataset = validation_dataset.take(val_batches // 5)validation_dataset = validation_dataset.skip(val_batches // 5)
可以查看验证集和测试集各有多少数据:
print('Number of validation batches: %d' % tf.data.experimental.cardinality(validation_dataset))print('Number of test batches: %d' % tf.data.experimental.cardinality(test_dataset))
2.2数据增广(data augmentation):
一般来说,数据集越大训练效果越好。有时候训练集数量不够多,我们可以通过数据增广的方法来提升数据集,从而达到提升训练效果的目的,通过对训练图像应用随机但真实的变换(如旋转和水平翻转),人为引入样本多样性是一种很好的做法。这有助于让模型学习训练数据的不同方面,并减少过度拟合。
data_augmentation = tf.keras.Sequential([tf.keras.layers.experimental.preprocessing.RandomFlip('horizontal'),tf.keras.layers.experimental.preprocessing.RandomRotation(0.2),])
查看一下数据增广的效果:
for image, _ in train_dataset.take(1):plt.figure(figsize=(10, 10))first_image = image[0]for i in range(9):ax = plt.subplot(3, 3, i + 1)augmented_image = data_augmentation(tf.expand_dims(first_image, 0))plt.imshow(augmented_image[0] / 255)plt.axis('off')

下载预训练模型,tf.keras.applications.mobilenetw2作为基础模型:
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
此模型要求像素值为[-1,1],但这时,图像中的像素值为[0,255]。要重新缩放它们,放缩的方法如下,offset参数是偏移量,当原始像素除以127.5之后,图像从[0,255]放缩到了[0,2],此时只需要将坐标轴向左方平移一个单位即可得到[-1,1],这就是offset参数设置为 -1 的意义。
rescale = tf.keras.layers.experimental.preprocessing.Rescaling(1./127.5, offset= -1)
从预先训练的模型基础上,创建新的基础模型,我们将从谷歌开发的MobileNet V2模型创建基础模型。这是在ImageNet数据集上预先训练的,这是一个由140万张图像和1000个类组成的大型数据集。ImageNet是一个研究培训数据集,包含多种类别。这个知识库将帮助我们从特定的数据集中对猫和狗进行分类。
首先,我们需要选择将用于特征提取的哪一层。最后一个分类层不是很有用。取而代之的是,展平操作之前的最后一层。该层称为“瓶颈层”。与头部相比,瓶颈层功能保留了更多的通用性。
随后,实例化一个MobileNet V2模型,该模型预先加载了在ImageNet上训练的权重。通过指定include_top=False参数,可以加载顶部不包含分类层的网络,这对于特征提取非常理想。
如果你对以上的解释比较困惑,没关系,通俗的说,我们通过一系列“厉害”的操作让一个小白模型学会了骑自行车,接下来就是让它通过现有数据自己再学会骑摩托车。
# Create the base model from the pre-trained model MobileNet V2IMG_SHAPE = IMG_SIZE + (3,) # (160,160)→(160,160,3)base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,include_top=False,weights='imagenet')
该功能提取器将每个160x160x3图像转换为5x5x1280特征图。可以这么理解:1280个5x5的特征图是3个160x160原始图片的信息浓缩。让我们看看它对一批示例图像的作用:
image_batch, label_batch = next(iter(train_dataset))feature_batch = base_model(image_batch)print(feature_batch.shape)
base_model是之前模型训练好的特征提取部分,这部分模型已经得到很好的优化,我们想要借用它。在训练的过程中,为了避免我们的数据对这部分模型产生破坏,因此我们把它冻结住。
base_model.trainable = False
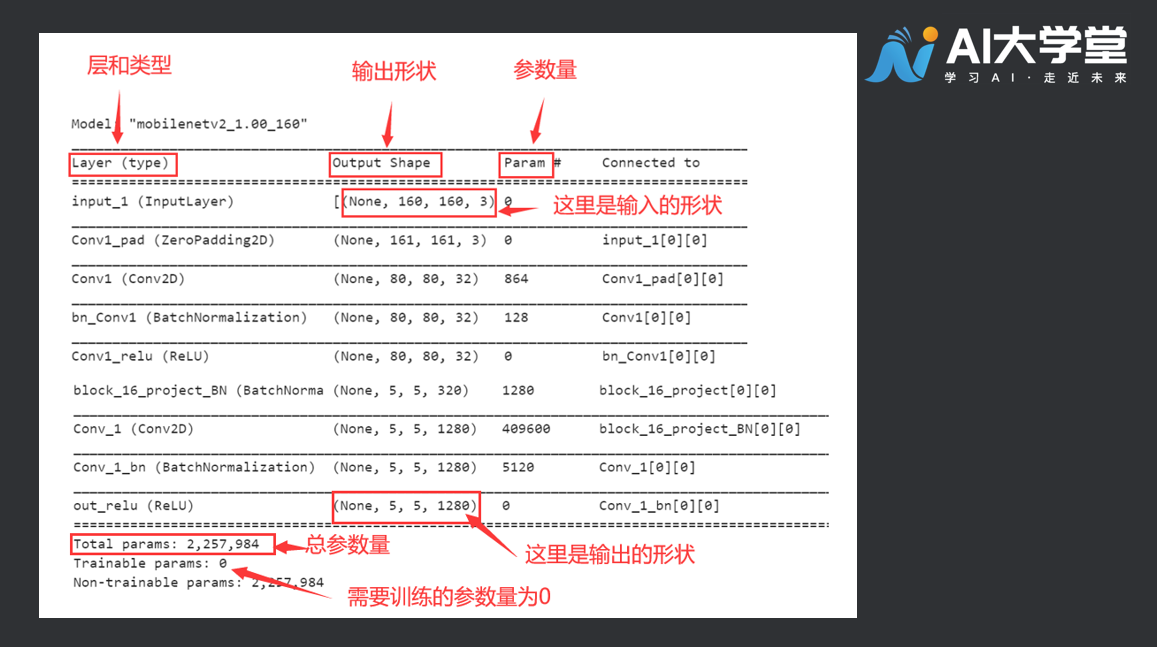
可以看看现在模型是什么样子的:
base_model.summary()
构造分类器,这里生成了一层全局平均池化层,它的功能类似全连接层,功能是为最终的分类效果做准备。
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()feature_batch_average = global_average_layer(feature_batch)print(feature_batch_average.shape)
应用 tf.keras.layers.Dense 将这些特征转换为每个图像的单个预测。这里不需要激活函数,输出正数预测类别1,负数预测类别0。
prediction_layer = tf.keras.layers.Dense(1)prediction_batch = prediction_layer(feature_batch_average)print(prediction_batch.shape)
2.3构建模型
创建模型的过程中,将数据增广、基础模型、剪枝操作串连起来。
inputs = tf.keras.Input(shape=(160, 160, 3))x = data_augmentation(inputs)x = preprocess_input(x)x = base_model(x, training=False)x = global_average_layer(x)x = tf.keras.layers.Dropout(0.2)(x)outputs = prediction_layer(x)model = tf.keras.Model(inputs, outputs)
编译模型,设置学习率,选择优化器和损失函数,设置评价策略。
base_learning_rate = 0.0001model.compile(optimizer=tf.keras.optimizers.Adam(lr=base_learning_rate),loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),metrics=['accuracy'])
评估模型,在这里模型是有基础模型的权重的,因此可以在训练之前对模型进行评估。
initial_epochs = 10loss0, accuracy0 = model.evaluate(validation_dataset)
看看模型的准确率
print("initial loss: {:.2f}".format(loss0))print("initial accuracy: {:.2f}".format(accuracy0))
2.4训练模型:
history = model.fit(train_dataset,epochs=initial_epochs,validation_data=validation_dataset)

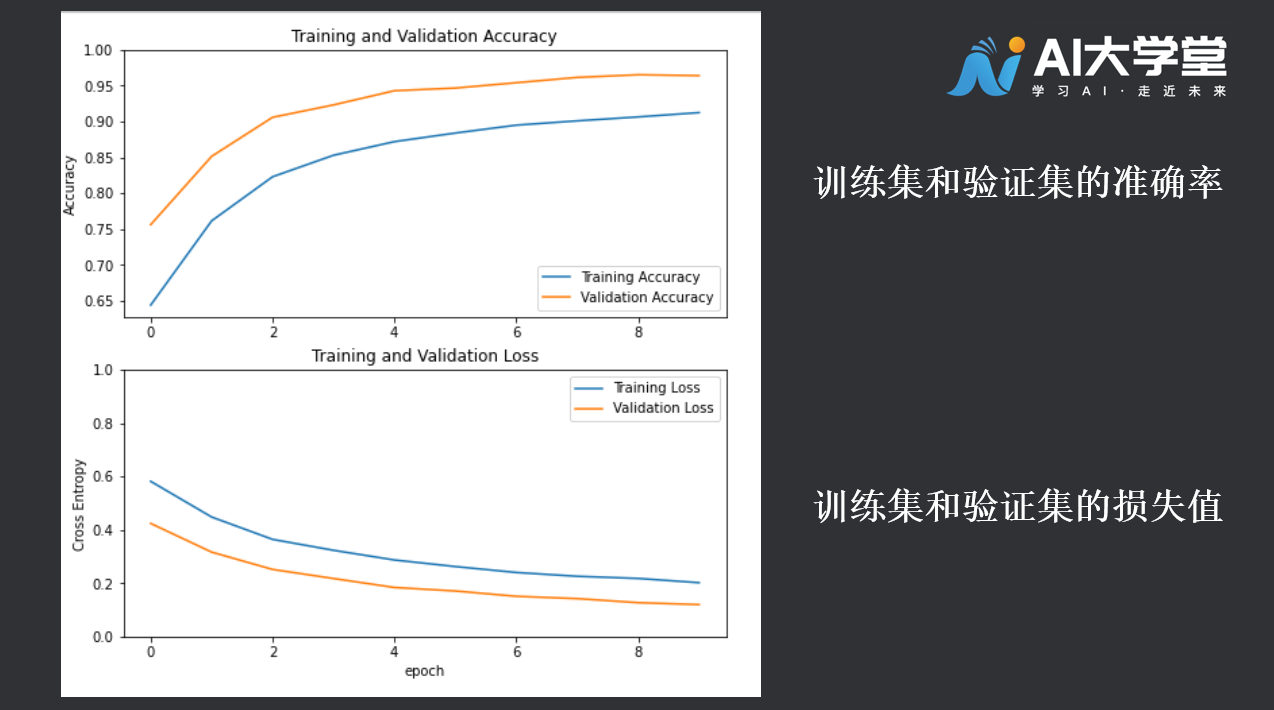
2.5绘制学习曲线:
acc = history.history['accuracy']val_acc = history.history['val_accuracy']loss = history.history['loss']val_loss = history.history['val_loss']plt.figure(figsize=(8, 8))plt.subplot(2, 1, 1)plt.plot(acc, label='Training Accuracy')plt.plot(val_acc, label='Validation Accuracy')plt.legend(loc='lower right')plt.ylabel('Accuracy')plt.ylim([min(plt.ylim()),1])plt.title('Training and Validation Accuracy')plt.subplot(2, 1, 2)plt.plot(loss, label='Training Loss')plt.plot(val_loss, label='Validation Loss')plt.legend(loc='upper right')plt.ylabel('Cross Entropy')plt.ylim([0,1.0])plt.title('Training and Validation Loss')plt.xlabel('epoch')plt.show()
2.6完整代码:
import matplotlib.pyplot as pltimport numpy as npimport osimport tensorflow as tffrom tensorflow.keras.preprocessing import image_dataset_from_directory_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')train_dir = os.path.join(PATH, 'train')validation_dir = os.path.join(PATH, 'validation')BATCH_SIZE = 32IMG_SIZE = (160, 160)train_dataset = image_dataset_from_directory(train_dir,shuffle=True,batch_size=BATCH_SIZE,image_size=IMG_SIZE)validation_dataset = image_dataset_from_directory(validation_dir,shuffle=True,batch_size=BATCH_SIZE,image_size=IMG_SIZE)val_batches = tf.data.experimental.cardinality(validation_dataset)test_dataset = validation_dataset.take(val_batches // 5)validation_dataset = validation_dataset.skip(val_batches // 5)data_augmentation = tf.keras.Sequential([tf.keras.layers.experimental.preprocessing.RandomFlip('horizontal'),tf.keras.layers.experimental.preprocessing.RandomRotation(0.2),])preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_inputrescale = tf.keras.layers.experimental.preprocessing.Rescaling(1./127.5, offset= -1)# Create the base model from the pre-trained model MobileNet V2IMG_SHAPE = IMG_SIZE + (3,) # (160,160)→(160,160,3)base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,include_top=False,weights='imagenet')image_batch, label_batch = next(iter(train_dataset))feature_batch = base_model(image_batch)print('48\n')base_model.trainable = Falseglobal_average_layer = tf.keras.layers.GlobalAveragePooling2D()feature_batch_average = global_average_layer(feature_batch)# print(feature_batch_average.shape)prediction_layer = tf.keras.layers.Dense(1)prediction_batch = prediction_layer(feature_batch_average)#print(prediction_batch.shape)inputs = tf.keras.Input(shape=(160, 160, 3))x = data_augmentation(inputs)x = preprocess_input(x)x = base_model(x, training=False)x = global_average_layer(x)x = tf.keras.layers.Dropout(0.2)(x)outputs = prediction_layer(x)model = tf.keras.Model(inputs, outputs)base_learning_rate = 0.0001model.compile(optimizer=tf.keras.optimizers.Adam(lr=base_learning_rate),loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),metrics=['accuracy'])initial_epochs = 10history = model.fit(train_dataset,epochs=initial_epochs,validation_data=validation_dataset)
3.拓展阅读
3.1为什么数据集要进行打乱操作(shuffle)
假设我们的猫狗识别训练集呈现如下分布:
Dog,Dog,Dog,... ,Dog,Dog,Dog,Cat,Cat,Cat,Cat,... ,Cat,Cat
如果不进行打乱操作,那么模型在训练的一段时间内只看到了Dog,必然会过拟合于Dog,一段时间内又只能看到Cat,必然又过拟合于Cat,这样的模型泛化能力(举一反三能力)必然很差。

若有收获,就点个赞吧
0 人点赞
