1.简单的线性案例——房价预测
在本节课中,我们将再次熟悉机器学习的线性模型,利用TensorFlow框架搭建网络模型,掌握建立模型的方法,逐步实现网络的预测功能。在次基础之上,我们将接触更高维度的特征输入,学会在众多的输入信息中寻找到有效的区分维度,从而提升预测效果。先来看一个单一维度的简单案例。
想象一下,如果房子的定价很简单,带一间卧室的房子价格是5万+5万,那么一间卧室的房子要花10万元;两间卧室的房子就要花15万元,如此类推。
如何创建一个神经网络,来学习这种关系,让它会预测一个7间卧室的房子,价格接近40万。让我们开始吧。
1.1代码讲解
导入使用到的库:
import tensorflow as tfimport numpy as npfrom rensorflow import keras
准备好数据:
data = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], dtype=float)labels = np.array([1.0, 1.5, 2.0, 2.5, 3.0, 3.5], dtype=float)
构建网络模型:
model = tf.keras.Sequential([keras.layers.Dense(units=1, input_shape=[1])])model.compile(optimizer='sgd', loss='mean_squared_error')
训练模型:
model.fit(data, labels, epochs=1000)
预测模型:
print(model.predict([7.0]))
1.2完整代码
import tensorflow as tfimport numpy as npfrom tensorflow import kerasdata = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], dtype=float)labels = np.array([1.0, 1.5, 2.0, 2.5, 3.0, 3.5], dtype=float)model = tf.keras.Sequential([keras.layers.Dense(units=1, input_shape=[1])])model.compile(optimizer='sgd', loss='mean_squared_error')model.fit(data, labels, epochs=1000)print(model.predict([7.0]))
2.波士顿房价预测(多维度)

下面来看一个真实的案例,波士顿房价分析。波士顿房价数据集包括506条样本数据,每条样本数据均包含13个特征变量以及该地区的平均房价。
之前简化的例子房价只和卧室数目有关,卧室越多房价越高。波士顿案例中的房价更为复杂,它有13个相关变量如下表所示: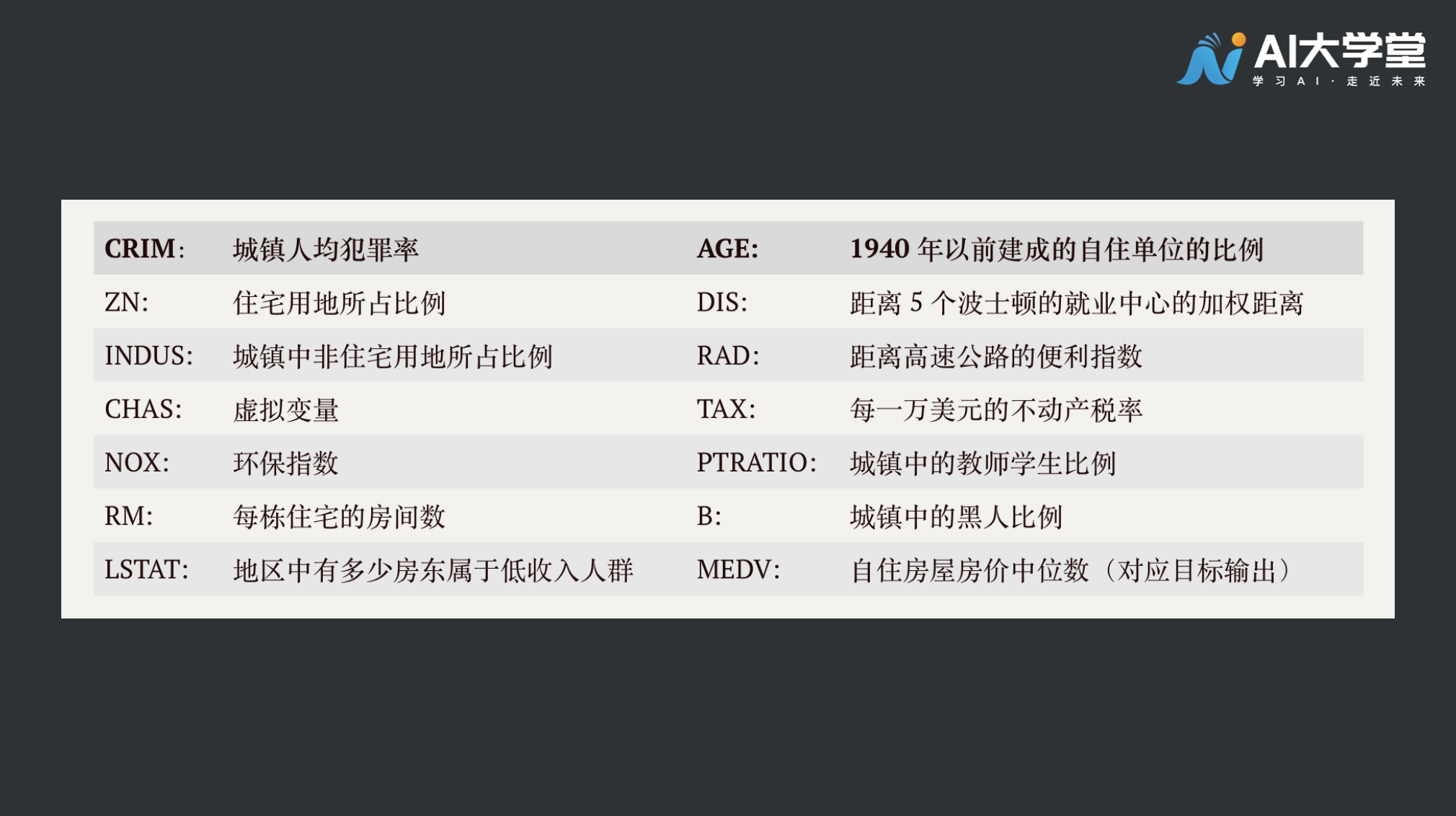
上表中 MEDV 对应上个单卧室房价预测的标签值,前面的13个指标对应着卧室数量。波士顿房价预测和之前卧室预测房价的差异你看出来了吗?
影响房价的因素数量变多了,在这个案例中,我们有13个影响因素(特征维度),现在我们让计算机去学习这些数据,看看效果怎么样。
2.1代码讲解
2.1.1数据准备
导入相关库文件:
import tensorflow as tfimport numpy as npimport sklearn.datasets as datasetsfrom tensorflow import keras
读取波士顿房价数据:
data = datasets.load_boston()
最终的价格作为标签数据,将特征变量和标签数据分开读取:
x_data = data.data #特征数据x_labels = data.target #标签数据
2.1.2模型构造
创建网络模型,units = 1 表示设置1个神经元,这里的13对应的是13个特征变量输入。想一想,之前的input_shape数值是多少?
如果我们得到的特征变量更多或更少,这里的input_shape也要相应地做出变化。
model = tf.keras.Sequential([tf.keras.layers.Dense(units=1,input_shape=[13])])
接下来设置优化器,还记得优化器是做什么的吗?
回顾一下,优化器是构建模型参数的策略,优化器会在现有模型的基础上对参数进行优化,使得模型的预测结果更加准确。它通常和损失函数搭配使用。
设置优化器,采用随机梯度下降法(SGD),学习率设为0.000001
optimizer = tf.keras.optimizers.SGD(learning_rate=0.000001, nesterov=False)
构建损失函数:
model2.compile(optimizer, loss='mean_squared_error')
2.1.3训练模型
model2.fit(x_data,x_labels,epochs=300)
2.1.4评估模型
训练结束后接下来应该做模型预测评估,但我们的数据集数量较少,在数据准备阶段并没有对数据集进行分割,因此在本节中不进行模型评估。在后面的章节中会有这个步骤。好奇心旺盛的伙伴可以在学习了后续课程后,再来看看这个案例,通过改动模型提升模型的预测能力。
2.2完整代码
import tensorflow as tfimport numpy as npimport sklearn.datasets as datasetsfrom tensorflow import keras#读取数据data = datasets.load_boston() #载入数据集x_data = data.data #特征数据x_labels = data.target #标签数据model = tf.keras.Sequential([keras.layers.Dense(units=1, input_shape=[1])])model.compile(optimizer='sgd', loss='mean_squared_error')model2 = tf.keras.Sequential([tf.keras.layers.Dense(units=1,input_shape=[13])])optimizer = tf.keras.optimizers.SGD(learning_rate=0.000001, momentum=0.0001, nesterov=False)model2.compile(optimizer, loss='mean_squared_error')model2.fit(x_data,x_labels,epochs=300)
3.补充阅读
特征(feature):可以对事物的某些方面的特点进行刻画的数字或者属性。它是所有人工智能系统中非常重要的概念。对于同样的事物我们可以提取出不同的特征,比如上述第一个样例的卧室个数,比如第二个样例的13个不同维度指标,它们都是特征。但高质量的特征对分类器的准确性会起到很大的影响。我们要根据事物本身具备的特点设计出最有效的特征。
特征向量:把一个事物的特征数值组织在一起,可以形成特征向量。比如第二个样例中的13个数,我们把13个特征的数值拼在一条数据中,那么这条数据形成的向量就称为特征向量。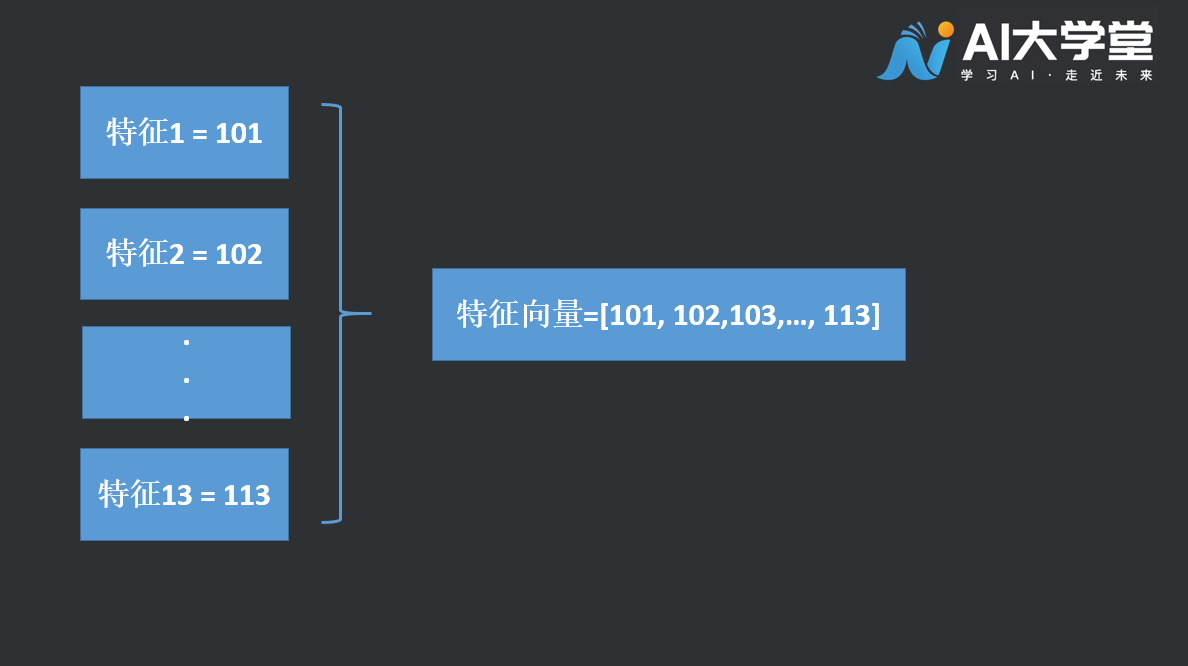
特征点:特征向量化表示后,每一个样本数据均可视为一个特征点。如上图的特征向量即为一个特征点。
特征空间:所有特征点构成的空间称之为特征空间。在第二个样例中,506个样本形成的13维度空间分布,即为房价预测模型的特征空间。
目标:把特征向量在特征空间中进行分类。

若有收获,就点个赞吧
0 人点赞
