服务器端开发要做的事情
- 实现网站的业务逻辑
- 数据的增删改查
为什么选择node
- 使用js语法开发后端应用
- 生态系统活跃,有大量的开源库可以使用
- 一些公司要求前端工程师掌握node开发
- 前端开发工具大多基于node
初识Node.js
node是基于chrome v8引擎的javascript代码运行环境
其实就是一个软件,这个软件可以运行javascript代码,我们就称它为JavaScript代码运行环境
既然是一个软件,那么我想要去使用它,就必须要先去安装一下这个软件
还有就是,基于node.js和第三方工具electron可以开发桌面应用程序
在浏览器的js运行环境中,有一个顶级对象window对象
但是node.js中不存在window对象
但是node.js中有一个类似于window对象的东西,就是Globals对象
Node运行环境搭建
安装
去官网下载安装包
目前node有两个主要的版本:
一个是10.13.0 LTS; LTS = Long Term Support 长期支持 稳定版。
一个是11.1.0 Current Current 拥有最新特性 实验版
下载稳定版进行安装即可
安装完成后,打开命令行工具,去验证一下是否安装成功。
在命令行输入 node -v 查看当前node的安装版本,如果可以正常返回值,就代表安装成功了
JavaScript本质上是什么?
是一门编程语言
浏览器的内核包括?
1、DOM渲染引擎 2、js解析器,js运行在浏览器张的内核的js引擎内部
是否js只能在浏览器中运行?
不是的,所有的js环境中都可以运行 比如在命令行窗口中输入node,就进入到js执行环境了,在这个环境中可以执行js语法的代码
实现动态网站的技术
Java,asp,.net ,node.js ,python
只有输入完node进入的那个环境才是repl环境吗? 是的
命令行窗口的运行环境,我们称之为REPL运行环境, read-eval-print-loop 也就是 读取代码-执行-打印结果-循环 这个过程
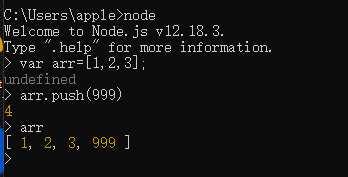
在REPL环境中,有一个特性 —> _表示最后一次的执行结果
直接输入一个算术表达式,可以正常输出这个表达式的计算结果 第二次运算的时候,可以用 _ 直接代替上一个表达式的运算结果,参与到新的运算中去
如下图:
那么输入 node可以进入到REPL环境中,那怎么退出这个环境呢?
.exit
REPL环境可以可以执行js代码,那么自然也就可以执行js文件,在js代码比较多的时候,我们把代码放在一个js文件中,然后在命令行窗口输入 node 文件名 就可以运行了
全局对象、全局成员
node有一个全局对象,就是globals对象,等同于浏览器中的window对象,在用的时候可以省略。
全局成员都是直接隶属于globals全局对象就是不需要引用就可以直接使用的对象。
需要注意的是全局对象Globals区别于global关键字。nodejs全局对象分为以下几类:
1、为模块包装使用的全局对象
(1)exports
(2)module
(3)require
(4)filename:当前文件名称
(5)dirname:当前文件目录
2、process对象
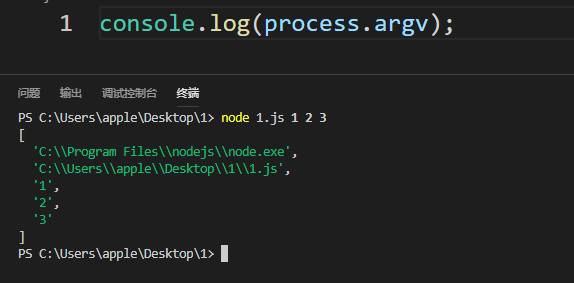
process.argv**
argv是一个数组,默认情况下,前两项数据分别是:Node.js环境的路径,当前执行的js文件的全路径 从第三个参数开始,表示命令行参数
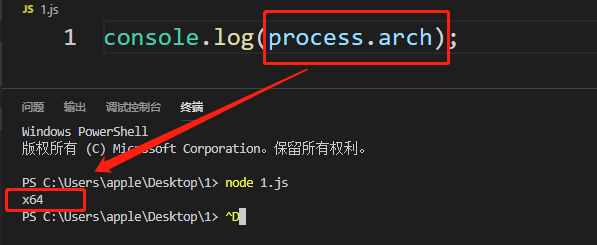
process.arch**
打印当前系统的架构(64位或32位)
3、控制台Console模块
4、EventLoop相关api
(1)setImmediate
(2)setInterval
(3)setTimeout
(4)相关clear
5、Buffer对象
6、global
global用于扩展变量和方法。
Node快速入门
JavaScript由三部分组成:
ECMAScript 是这门语言的核心,规则了这门语言的语法规则
DOM 浏览器这个运行环境,为js提供的API
BOM 浏览器这个运行环境,为js提供的API
Node是由
ECMAScript 是这门语言的核心
Node环境提供的一些附加的API组成的
Node.js基础语法
所有ECMAScript语法在Node环境中都可以用
JavaScript要运行代码的话,是引入到html页面中进行运行
node中没有html页面,所以要执行代码的话,要借助命令行工具
先新建一个js文件,写上node代码,然后打开命令行工具(命令行目录必须和工作目录处于同一个文件夹啊),然后在命令行中输入 node 文件名 ,回车,就可以运行当前文件了
Node.js模块化开发
JavaScript开发的两大弊端
1、文件依赖关系不明确
JavaScript文件的依赖关系是由文件引入的先后顺序决定的。
2、命名冲突
在一个js文件中命名了一个变量,之后又引入了其他的js文件,并且这个新文件中也有这个变量,那么后边的变量就会把前边的变量给覆盖了。文件与文件之间是全开放的状态
前端标准的模块化规范:
1、AMD - require.js
2、CMD - seajs(国产的,阿里巴巴的)
服务器端的模块化规范
1、CommonJs - Node.js
前端标准与后端标准的模块化的区别:
主要是文件加载的不同
1、前端模块化加载js文件的时候,需要从服务器经过网络传输到浏览器端,代码才能执行 2、在服务器端,加载文件的时候,只需要从磁盘加载到内存就可以了 所以说服务端的加载一般是同步的。前端的加载一般是异步的(因为传输过程需要时间)
文件与文件之间是一种半封闭的状态,在当前文件中有哪些代码我希望其他文件能够访问到,那么我就把这一部分代码给开放出去。不开放的那部分代码,其他文件是访问不到的。
软件中的模块化开发
一个功能就是一个模块,多个模块可以组成完整的应用,抽离一个模块不会影响其他功能的运行。
node.js中模块化开发的规范
- node.js规定一个JavaScript文件就是一个模块,模块内部定义的变量和函数在默认情况下外部是无法得到的。
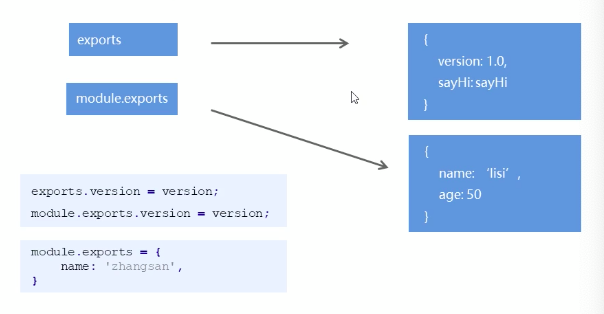
- 在实际开发中,肯定会出现一个文件需要依赖另一个文件的情况,那么,模块内部可以使用exports对象进行成员导出(模块内部定义的变量或者函数,想要在模块外部被访问到,那么我们可以把它进行导出),再使用require方法导入其他模块。
怎么导出呢?实际上就是把这个函数变成exports的属性值就可以了。
在b中使用require方法进行导入。require方法有一个返回值,返回值就是导入的那个模块的exports对象
Node.js中模块成员导出的方式
1、exports和require
//a.jsconst add = (n1, n2) => {return n1 + n2;}exports.add = add;// exports是一个对象,需要导出东西的话,就把要导出的东西当作exports对象的属性值就可以了// 第一个add是exports的属性值,第二个add是我们定义的add方法
const a = require("./a");//导入模块时,后缀可以省略// require是有返回值的,所以我定义了一个变量去接收它的返回值。// 它的返回值其实就是exports对象console.log(a);//这里的a就是a.js中的add方法,也就是exports对象的add属性的属性值console.log(a.add(23,5)); //所以如果想要调用add,直接以对象的形式进行调用
系统模块
什么是系统模块?
Node运行环境提供的API,因为这些API都是以模块化的方式进行开发的,所以我们又称node运行环境提供的API为系统模块
node运行环境提供了很多系统模块,在每一个系统模块当中,它提供的都是具有相关性的功能。
比如说文件操作系统模块,提供了读取文件,写入文件,创建文件夹等模块
系统模块fs 文件操作
f:file, s:system系统 文件操作系统
我们要操作哪个模块,就要引入一下这个模块。系统模块也不例外。
所以在用系统模块的时候,我们要先引入一下这个模块
const fs = require('fs');//require('fs')中的fs,指的就是fs系统模块//const fs中的fs,就是fs系统模块中的module.exports的返回值//这个操作暴露了一些与文件操作相关的API
读取文件内容
fs.reaFile('文件路径/文件名称',['文件编码'],callback)
//a.jsconst add = (n1, n2) => {return n1 + n2;}// exports.add = add;// exports是一个对象,需要导出东西的话,就把要导出的东西当作exports对象的属性值就可以了// 第一个add是exports的属性值,第二个add是我们定义的add方法// module.exports也是对象类型,我们只需要把模块成员作为module.exports对象的属性值就可以了。module.exports.add = add;// exports对象和module.exports对象都可以导出成员,那么二者有什么关系呢?// exports是module.exports的别名(地址引用关系),导出对象最终以module.exports为准// 默认情况下,他俩指向的是同一块内存空间,所以默认情况下,这两种写法是等价的。如下// module.exports.add = add;// exports.add = add;// 但是如果exports对象和module.exports对象指向的不是同一个对象时,以module.exports对象为准,// 比如我们强制改变了module.exports对象指向// exports.add = add;//module.exports = {// name:"zhangsan"// }// 这个时候二者指向的东西就不一样了,那么最终的导出结果,就是module.exports对象里边的东西咯
const a = require("./a");//导入模块时,后缀可以省略// require是有返回值的,所以我定义了一个变量去接收它的返回值。// 它的返回值其实就是exports对象console.log(a);//这里的a就是a.js中的add方法,也就是exports对象的add属性的属性值console.log(a.add(23,5)); //所以如果想要调用add,直接以对象的形式进行调用
// const a = require('./1');// console.log(a.sum(12, 3))// require里边的fs 指的是node提供的fs系统模块,fs是文件操作系统const fs = require('fs');// fs模块有一些相关的API,我们可以直接调用// 客户端向服务器端请求浏览index.html的时候,// 服务器端要先在自己的硬盘当中找到index.html,并读取出文件的内容,再将文件内容返回给客户端// 这个过程就是由fs.readFile来完成的// fs.readFile('文件路径/文件名称',['文件编码'],callback);// 记住,以后在官方文档中看到某个参数是用[]包起来的,说明它是一个可选参数// 实际上是硬盘在读取内容,读取内容这个过程需要时间,// 所以我们不能通过这个API的返回值直接拿到内容// 所以在这个地方我们需要定义一个函数,当文件内容读取完成后,硬盘会通知这个API说内容读取完了,我可以调用你的回调函数了// 然后在调用回调函数的时候,把读取到的内容通过函数的参数的形式传递过来了// 所以第三个参数callback 的作用,就是为了拿到读取的结果// callback的第一个参数是err,第二个参数是doc// 为什么第一个参数是err呢// 因为读取的时候可能会出错,如果出错了就把信息存在err中,err是一个对象,里边包含着错误信息。如果err的值为空,说明读取成功了// 第二个参数是doc,它里边是文件读取的结果// node.js中的所有API,它们的回调函数第一个参数都是err,所以我们也称node.js为错误优先的回调函数// 读取文件内容// fs.readFile('./1.js', 'utf-8', (err, doc) => {// if (err == null) {// console.log(doc);// }// })// 写入文件内容// 应用场景:比如在网站的运行当中,要监控网站的运行情况。// 例如在网站的运行过程中是否报错的情况,// 那程序员也不能一直盯着电脑看啊,所以我们希望当程序运行报错的时候,我们把错误信息写入错误日志当中// 程序员上班的时候,只需要查看错误日志就可以直接查看网站有没有报过错了// 语法// fs.writeFile('文件路径/文件名称', '数据', callback);// 如果文件路径中不存在这个文件名称,系统会自动帮我们创建一个出来// 写入内容这个过程可能会成功,也可能会失败,所以写入内容的结果就是这个成功或者失败,也就是函数的第一个参数err// const content = '<h3>111233</h3>';// fs.writeFile('./1.txt', content, err => {// if (err != null) {// console.log(err);// return;// }// console.log('写入成功');// })// 系统模块path 路径操作// 主要是针对硬盘的路径进行操作// 路径拼接API// 为什么会有路径拼接这种操作呢// 1、不同操作系统的路径分隔符不统一// 路径分隔符是啥,就是文件夹与文件夹之间的分隔符// /public/uploads// window中是 \ / 都可以// Linux中是只有/才可以// 为什么要考虑Linux呢,因为Linux系统通常作为我们的网站服务器,我们的项目以后很可能要运行在Linux下// Path2D.join('路径','路径',...)// const path = require('path');// let finalPath = path.join('localhost', '1.html', '3');// console.log(finalPath);// 相对路径 绝对路径// Node.js开发时,一般用的都是绝对路径// 大多数情况下使用绝对路径,因为相对路径有时候相对的是命令行工具的当前工作目录// 在读取文件或者设置文件路径时都会选择绝对路径// 使用__dirname获取当前文件所在的绝对路径// 用绝对路径还是相对路径,要取决于这个相对路径 相对的是否是当前的文件// 但是大多情况下,相对路径相对的都不是当前文件,而是命令行窗口所在的文件目录// 所以需要用path.join方法 将当前文件的绝对路径 和你想要读取的文件拼接在一起 形成一个完整的路径再去读取// require方法中也有路径,它的路径本身就是相对于当前文件的,所以在用require方法的时候是可以写相对路径的
Node第三方模块
别人写好的,具有特定功能的,我们能直接使用的模块即第三方模块,由于第三方模块通常是有多个文件组成并且被放置在一个文件夹中,所以又名包 所以 包—第三方模块
第三方模块有两种存在形式:
以js文件的形式存在,提供实现项目具体功能的API接口
以命令行工具形式存在,辅助项目开发
获取第三方模块
第三方模块都是非官方的模块,是由千千万万的开发者提供的。 比如张三写了一个很厉害的模块,很多人都想去使用它,但是很多人都不认识张三,无法得到这个模块。 所以就需要一个平台来存储这些模块,于是npmjs.com就诞生了,它是第三方模块的存储和分发仓库。在这个网站中存储了非常多的模块
那我们怎么使用这个网站上的包呢?
npmjs.com提供了一个命令行工具npm
npm(node package manager)node的第三方模块管理工具
node安装好的时候,就已经集成了npm了
第三方模块npm
npm在使用过程中,只要没有看到红色的报错就没问题,出现warn也问题不大 npm详细使用写在另一篇笔记中了
一、下载 npm install 模块名称
模块下载到哪了?默认情况下是下载到了当前命令行窗口所在的文件夹的位置中。 执行完这句代码后,文件夹中会自动生成一个Nodemodules包,第三方模块就存在这个文件夹里边。
二、卸载某个模块 npm uninstall package 模块名称
三、npm安装中的本地安装和全局安装
本地安装 将模块下载到当前的项目当中,供当前的项目使用
全局安装 将模块安装到一个公共的目录当中,所有的项目都可以使用这个模块
一般我们将命令行工具进行全局安装;库文件进行本地安装
npm install 模块名 -g, 全局安装npm install 模块名 --save-dev安装依赖到开发环境
npm install 模块名 --save安装依赖到生产环境
第三方模块nrm
npm下载地址切换工具
npm默认的下载地址在国外,我们在国内下载的速度慢。目前国内有人将国内的服务器与国外的服务器进行同步,我们可以直接访问国内服务器进行安装。
那么怎么切换到国内安装的地址呢
1.使用npm install nrm -g 下载它(全局安装)
2.查询可用下载地址列表nrm ls
3.切换npm下载地址 ,再使用 nrm use 下载地址名称 就可以了
第三方模块nodemon
nodemon是一个命令行工具,用来辅助项目开发
在node.js中,每次修改文件后都要在命令行工具中重新执行该文件,非常繁琐
使用步骤:
1、使用npm install nodemon -g 先安装
2、以后在执行node server.js的时候,用nodemon server.js来代替
第三方模块Gulp
基于node平台开发你前端构建工具 将机械化操作编写成任务,想要执行机械化操作时执行一个命令行命令任务就能自动执行了
一、Gulp能做什么
1.项目上线的时候,对html css js文件压缩合并
2.语法转换(es6 less)
3.公共文件抽离
4.修改文件浏览器自动刷新
我感觉这个功能有点类似于webpack
二、Gulp的使用
1.使用npm install gulp 下载gulp文件
2.在项目根目录下建立gulpfile.js文件
3.重构项目的文件夹结构
src目录放置源代码文件 dist目录放置构建后的文件
4.在gulpfile.js文件中编写任务
5.在命令行工具中执行gulp任务

若有收获,就点个赞吧
0 人点赞
