聚类算法是比较典型的无监督机器学习算法。聚类系列算法的目的是知识发现,寻找样本点之间的相互关系,从而找到某种规律。
聚类算法最初的算法是K-Means算法。K-Means算法是一种简单的模型,它的步骤是先确定要将样本点分成几簇,然后随机初始化这些簇的中心。选定簇中心后,我们开始计算其他每个样本点到这些簇中心的距离,需要提到的是,计算距离的指标有很多,诸如曼哈顿距离,欧氏距离,余弦距离等等。在这里我们经常采用欧式距离。某个样本点若离哪个簇中心最近,这个点就属于哪个簇。在划分完以后,我们会形成k个簇。但这不是终点,由于一开始的簇中心是随机设定,其不一定真正在簇的中心,因此我们需要计算簇内部样本点到簇中心的距离的平均值,然后根据这个平均值选定新的簇中心。选定新的簇中心后,继续求取其余样本点到这些簇中心的距离,根据距离再次调节。就这样一层层迭代,直到上一个簇中心与下一个簇中心之间距离极小,小于某个阈值时,迭代结束。
K-Means的模型比较简单,且实现容易。但缺点也同样明显,其受初始簇中心的分布影响较大,对离群值很敏感,对于一些特殊的分布结果不好。我们后续会介绍更多K-Means的变式,这些变式可以弥补K-Means的不足。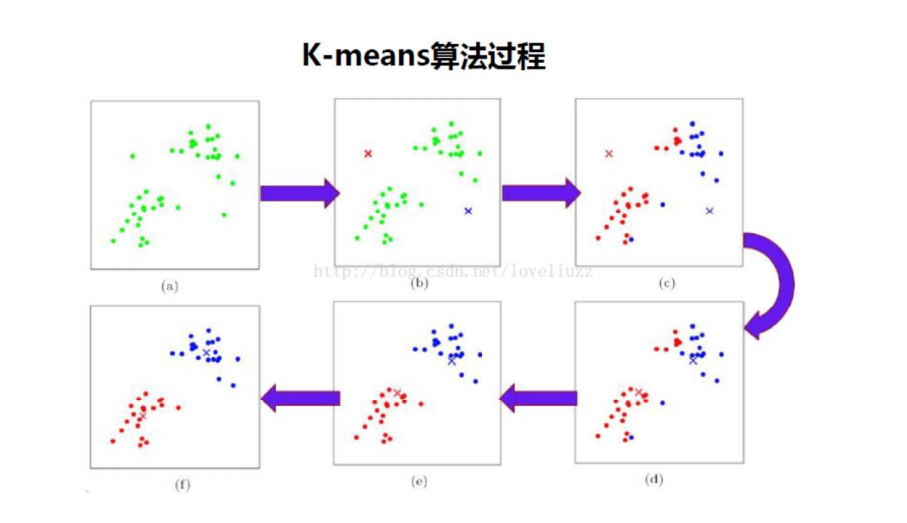

若有收获,就点个赞吧
0 人点赞
