由于K-Means聚类受初始值和离群值的影响较大,我们开发出了不少有关K-Means聚类算法的变式。
K-Mediods算法在选取簇中心时是根据各个样本点距离簇中心的中位数来选取的,因此K-Mediods具有一定的抗噪性,几乎不受离群值的影响,但其还是不能减弱初始值的影响。
二分K-Means算法是对K-Means的一个修正。由于初始值的影响,聚类情况很有可能不理想。我们常常通过计算整个簇中样本点与簇中心的MSE来对簇中心的位置进行迭代与修正,整体的聚类损失就是k个类的MSE之和。由于某些簇中心之间的距离过近,每个簇中的MSE都很小,这时候我们可以选择合并具有这样特点的簇。某些簇中心之间的距离很远,簇中的MSE很大,这时候我们可以选择切分含有样本量较多的簇,令簇的MSE变小。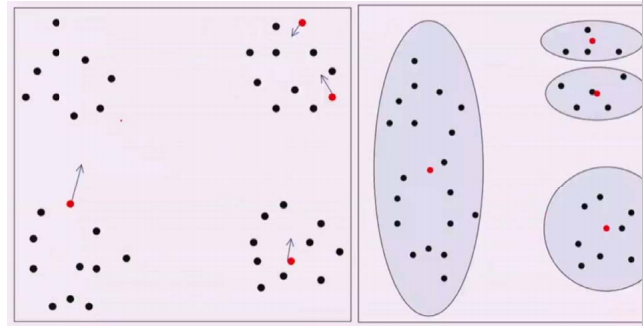
由于选定合适的初始值对于后续的聚类有着及其重要的作用,因此我们常采用K-Means++算法来减弱初始值的影响。K-Means++算法会先随机选定一个初始值作为一个簇中心,然后计算每个样本到这个初始值之间的距离,然后将距离转化为概率,通俗来讲就是,距离更大的样本具有更高的概率被选中作为另一个簇中心,而距离小的样本被选中作为另一个簇中心的概率不大。这种方法可以有效地控制每个簇的MSE值,使得每个簇分的比较均匀,很大程度上削弱了初始值对结果的影响,因此K-Means++算法是比较重要的算法。
K-Means算法中有两个相当重要的指标,一个指标是MSE损失函数,另一个是簇数k。下面来一一介绍。
MSE损失函数的形式如下。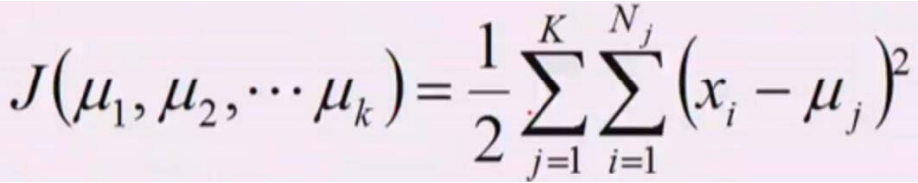 K-Means的理论基础是假定数据点符合同方差的高斯分布模型。在这个式子中,j代表着簇别数,i代表着j簇别中的第i个样本。我们可以通过最大似然函数来得到K-Means的迭代方法。由于这个损失函数是一个非凸函数(因为高斯模型是正态分布模型),因此我们往往得到的是局部最优解,而不是全局最优解。
K-Means的理论基础是假定数据点符合同方差的高斯分布模型。在这个式子中,j代表着簇别数,i代表着j簇别中的第i个样本。我们可以通过最大似然函数来得到K-Means的迭代方法。由于这个损失函数是一个非凸函数(因为高斯模型是正态分布模型),因此我们往往得到的是局部最优解,而不是全局最优解。
下面再来说说k值,选取的k值对于迭代结果的影响很大。K=1时,MSE为0,K=N(N是总样本数)时,MSE与原数据集的方差一样。我们通常选择一开始下降快的。
最后来说说Canopy聚类,Canopy聚类的特点是一次出结果,可以得知,Canopy的聚类结果一定不会很准确,因此Canopy聚类往往与K-Means聚类结合使用,Canopy聚类最大的优点就是必定可以聚类出k值,也就是说假设我们一开始不知道如何选定一个k值,Canopy就可以帮我们进行划分,选定k值,接着我们可以用K-Means算法继续迭代。如下所示,假设样本集合D集非空,我们在D集中选择一个d中心点作为簇中心, 然后计算D中除d外的样本点与d的距离,我们要设定两个超参数T1和T2(T1>T2)。那些距离小于T2的样本点属于d簇,不能做其他簇的中心,那些距离大于T2小于T1的样本点属于中心点d簇中的样本,但它可以做其他簇的中心。距离大于T1的样本中的一个一定会成为其他簇的中心。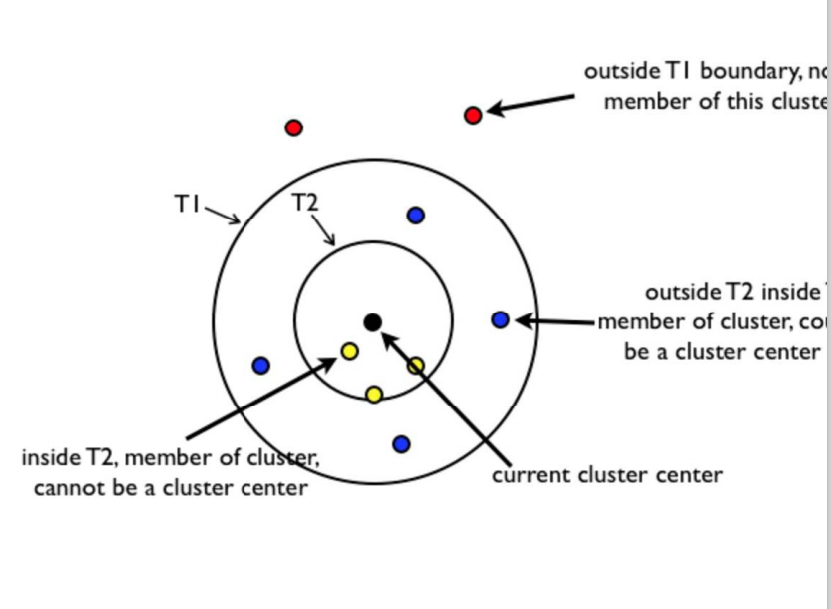

若有收获,就点个赞吧
0 人点赞
