大促的瞬间激增的流量对软件系统的挑战是非常大的,这也在系统的稳定性、可用性、性能上提出了更高的要求,系统的稳定性和高性能同时也是业务品牌和用户体验的重要保障。
大促压测是一个多方配合的过程,特别是研发、测试、PE等同学。压测既是为了保证业务峰值下系统的稳定性同时也是探测系统性能的好机会。
压测其实一个需要做很多工作的过程,分别是业务梳理->架构梳理->流量预估和目标预设->场景建模->压测环境准备->压测策略准备->压测执行->压测数据收集->产出压测分析报告->性能瓶颈分析->性能优化->再次压测。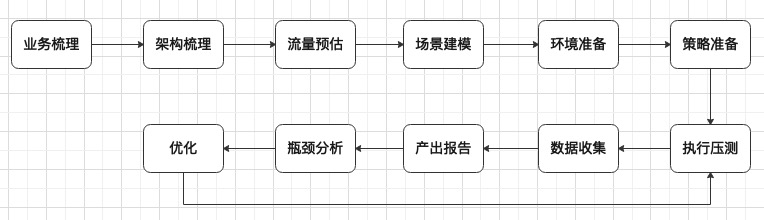
业务梳理
根据大促的业务特性和用户操作路径梳理出哪些需要承受峰值流量、哪些承载了基础业务、哪些是核心业务,这里用下图举个例子,每个系统作用不同需要结合实际情况来梳理产出核心业务图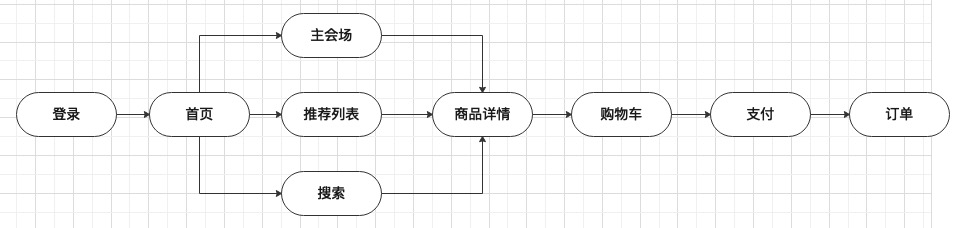
架构梳理
根据上面的业务梳理我们还要进行架构梳理,对我们的整个系统所有应用进行梳理,了解哪些应用会面临大促的压力,哪些与大促无关;哪些是核心应用,哪些是非核心应用。理清这些应用之间的关联关系,有哪些上下游依赖,哪些需要重点保障,哪些是可以降级的。
这个过程要理出整体的业务架构大图(可分成在线离线),包含各个应用,上下游依赖,中间件,所在的网络环境,带宽使用量,负载均衡设备,数据库,在线数据采集、订阅,离线数据处理等所有环节;只有把整个架构都搞清楚了,才能针对性的进行风险评估、容量规划、预案准备等。
把架构理出来后很大程度上我就知道当一个压测流量进入系统的时候它的具体流向是怎么样的,会影响哪些系统,是不是存在流量放大等等。
流量预估和目标预设
流量的预估既要根据数据同时也要结合经验。比如通过监控系统来确定日常的平均qps和峰值qps,高峰时段的流量占比等,然后再根据往届的流量数据情况结合运营在引流上的数据进行预估。
我个人针对一般性的大促功能都采用5~10倍日常,1.5倍上次大促的方式来初步预估。为了考虑极端情况下的稳定性,我一般都是预设10%的时间内承受了90%的流量。当然每个场景和功能都不一样,还是要根据实际情况来预估。
流量预估完成之后我要明确期望达到的QPS以及机器数量。
这个预估也要多和运营同学进行沟通,毕竟每次大促的力度是不一样的。同时和有经验的研发、测试同学进行沟通,既不要过分的扩大也不要预估不足。
场景建模
通过上面的业务梳理之后我在场景建模阶段还要把具体的用户操作具体化,这里依然是使用3W模型,即什么人在什么时候做什么事情,比如用户在晚上8点秒杀iphone11。确定这样一个操作之后,我们要结合梳理出的架构来分析压测涉及到哪些API,这些API之间的压测量级是什么样的或者有什么样的比例关系等。业务模型的构造准确度,直接影响了压测结果的可参考性。淘宝大促用的全部都是RPS模式压测,即从服务端角度出发每个API之间是漏斗比例关系。
压测环境准备
压测模型主要划分为三类:线下压测、线上引流压测、线上全链路压测。
这里引用网上文章《性能优化之集中常见压测模型及优缺点》中的图,如侵权请联系删除。
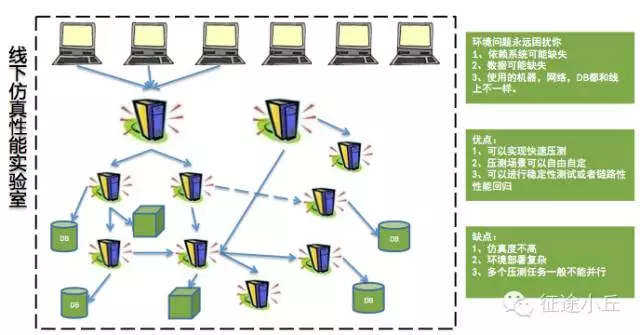
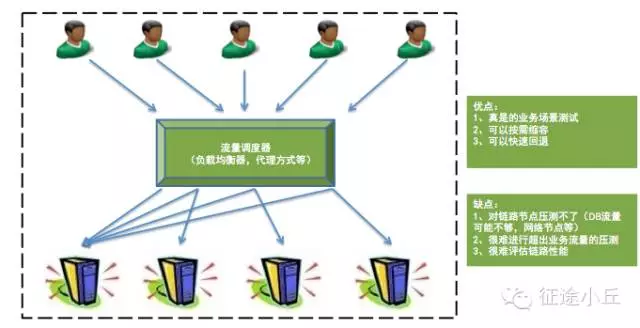
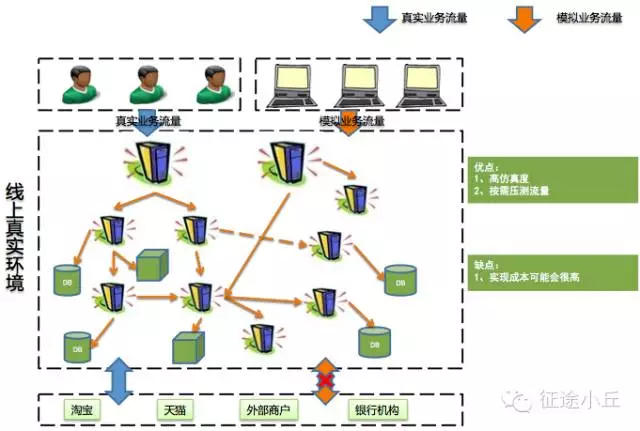
一般单应用的压测一般现在预发环境进行链路串通和验证,然后在晚上进行全链路压测,阿里内部其实有非常完善的全链路压测工具进行支撑。在压测工具的选择上,我们也可以看看外部开源工具的特性,作比较之后再决定。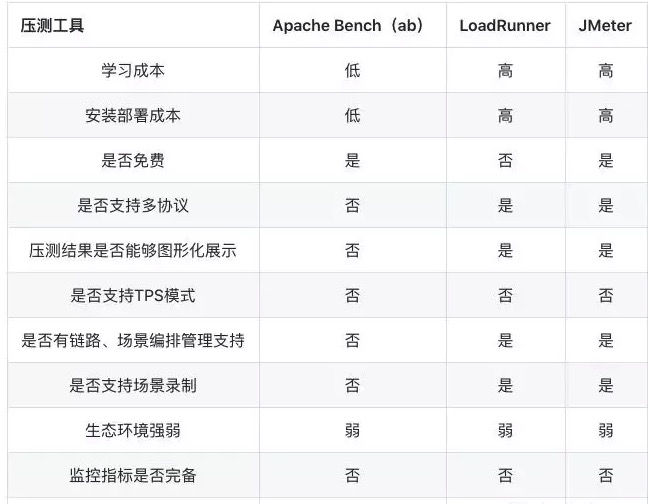
根据不同的压测模型,我们需要准备不同的类型的数据,比如线上全链路压测阿里内部也有工具进行真实业务流量引流,而模拟业务流量则需要造测试数据,这就需要各方进行配合。
压测策略准备
压测策略其实就是关于压到多少的问题,我自己的经历来看主要是以下几种:
- 峰值脉冲
即完全模拟0点大促目标峰值流量,进行大促态压测,观察系统表现。 - 系统摸高
取消限流降级保护功能,抬高当前压测值(前提是当前的目标压测值已经达到,则可以进行摸高测试),观察系统的极限值是多少。可进行多轮提升压力值压测,直到系统出现异常为止。 - 限流降级验证
顾名思义,即验证限流降级保护功能是否正常。 - 破坏性测试
验证预案的有效性,类似于容灾演练时的预案执行演练。即为持续保持大促态压测,并验证预案的有效性,观察执行预案之后对系统的影响。 并发测试
模拟客户端请求,在单位时间内(S)同时发起一定量的请求,验证系统是否具有并发性的问题。
当然还有很多其他的策略,需要实际的业务场景来进行选择,比如秒杀场景就不可避免的要多进行并发测试。注意这里的策略选择不是单一的,也不是一次性的而是多策略配合和多轮反复验证的。因此就需要产出明确的压测计划,方便各方保持节奏一致。
压测执行
在进行压测执行前一般都会进行压测方案的评审和沟通,各方达成一致之后再进行压测。同时在正式进行压测之前,我们还需要做好系统的预热和登录准备(如果有)。
预热是为了该缓存的数据提前缓存好,达到大促缓存态的状态,也更好地实现我们缓存的目的。当然也可以通过先一轮、低量级的全链路压测,来提前预热系统提前缓存住需要缓存的数据。
在进行完预热和链路验证之后,按照之前定好的压测策略和计划进行压测,在压测的过程中同时要注意当前的压测对用户的影响是不是可以接受的。
压测数据收集
通过监控系统和压测系统获取系统的各项指标,主要是核心链路上的系统表现和监控数据
产出压测报告
测试同学把压测方案和压测数据形成报告,并给出可能存在的性能瓶颈。
性能瓶颈分析
在分析定位问题时,因涉及的系统较多、子业务系统的形态不一,需要具体问题具体分析。可以自上而下,也可以自下而上,你对整个系统了解的越深定位就会越快。
性能优化
这又是一个很大的话题,大部分是集中在降低相应时间上,具体的调优要根据性能瓶颈的具体表现来分析调优。
再次压测
优化完成之后再次压测直到达成压测目标。
小感悟
阿里在压测的基础建设上我觉得是非常不错的,不管是线下还是线上引流、全链路压测,甚至是白天的全链路压测都已经做得相对完善,这得益于多年来双十一的挑战沉淀下来的。
阿里的压测更多是由测试同学进行主导,然后研发、PE等进行配合,但是系统的瓶颈在哪里,性能大概有多少其实研发自己是最清楚的,因此也需要研发自己多去和测试同学进行沟通。

若有收获,就点个赞吧
0 人点赞
