对于jedis和redisTemplate等工具包没有封装的命令该如何使用?
一、Pipelin模式介绍
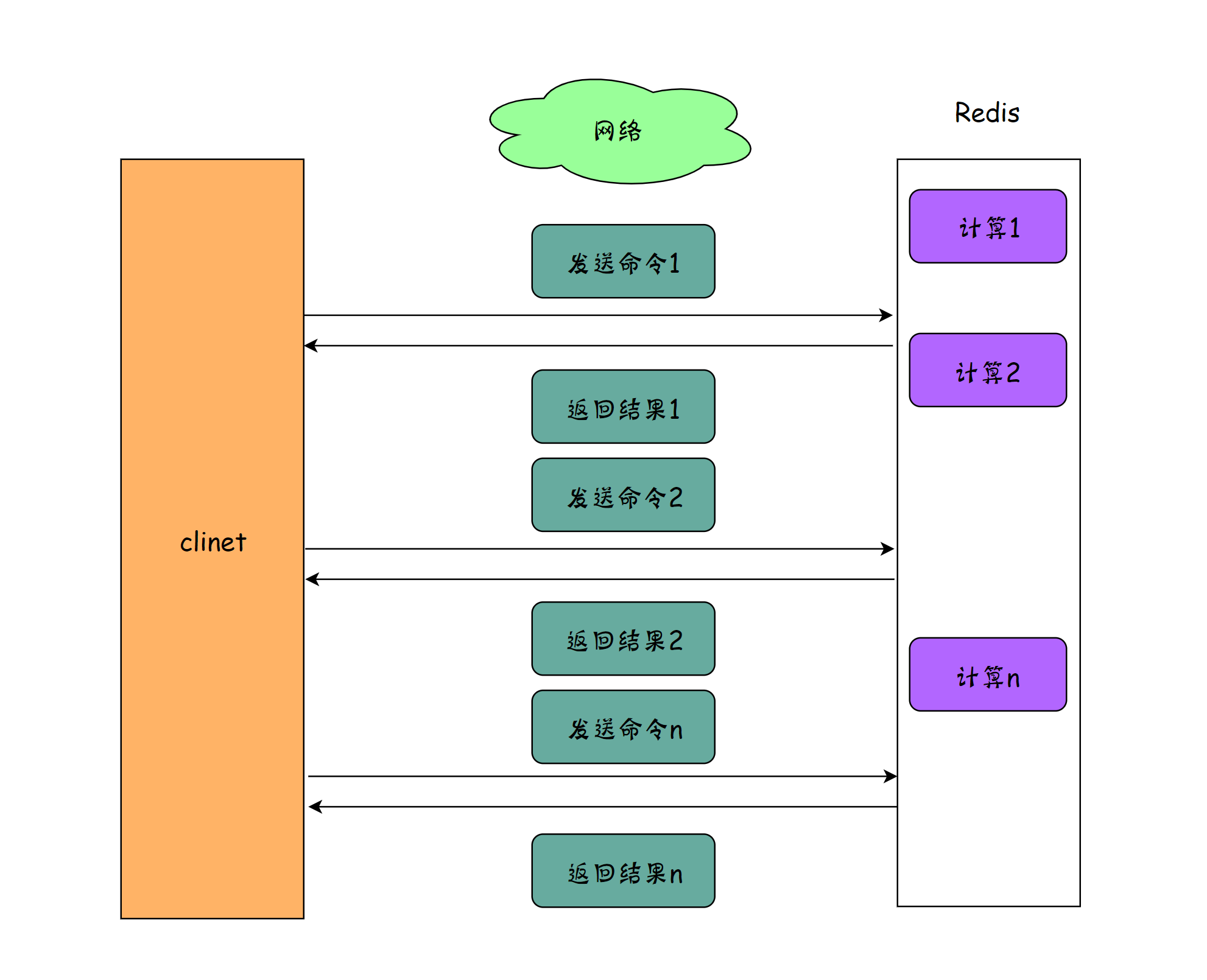
1、Redis的通常使用方式
大多数情况下,都会通过请求-相应机制去操作Redis。使用这种模式的步骤为
- 获得jedis实例
- 发送Redis命令
- 由于Redis是单线程的,所以处理完上一个指令之后才会进行执行该命令。
2、Pipeline模式
然而使用Pipeline 模式,客户端可以一次性的发送多个命令,无需等待服务端返回。这样就大大的减少了网络往返时间,提高了系统性能。
pipeline是多条命令的组合,使用PIPELINE 可以解决网络开销的问题,原理也非常简单,流程如下, 将多个指令打包后,一次性提交到Redis, 网络通信只有一次。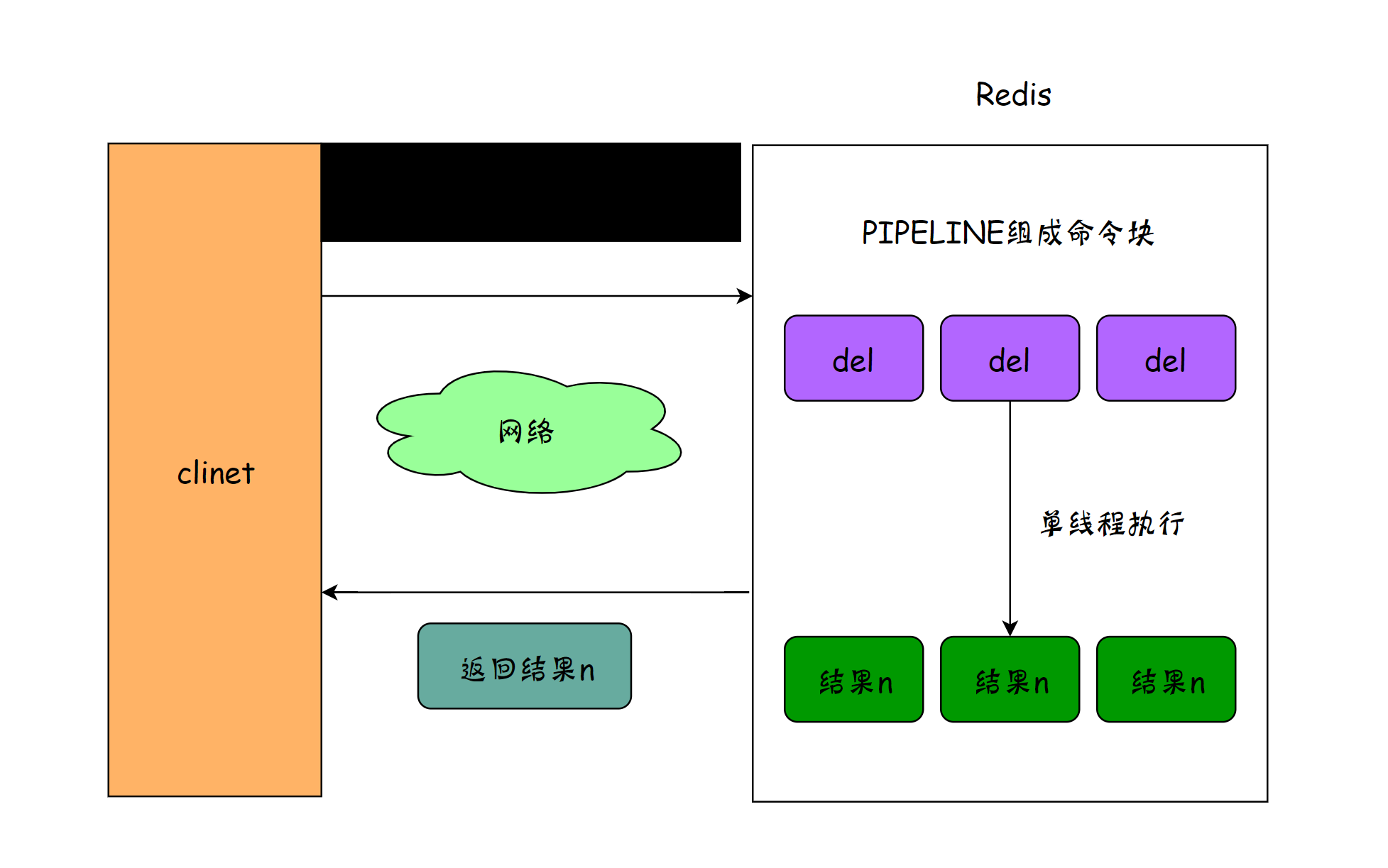
3、性能对比
| 网络 | 延迟 | 非Pipeline | Pipeline |
|---|---|---|---|
| 本机 | 1300 | 1414 | 114 |
| 内网服务器 | 1222ms | 15321ms | 310ms |
| 异地机房 | 90910ms | 92000ms | 1090ms |
可以看到,Redis的延迟主要出现在网络请求的IO次数上,因此在使用Redis的时候,尽量减少网络IO次数,通过pipeline的方式将多个指令封装在一个命令里执行。
二、Redis事务
Redis的简单事务是将一组需要一起执行的命令放到multi和exec两个命令之间,其中multi代表事务开始,exec代表事务结束
1、事务命令
- multi:事务开始
- exec:提交事务
- watch:事务监控
WATCH命令可以监控一个或多个键,一旦其中有一个键被修改(或删除),之后的事务就不会执行。监控一直持续到
discard:停止事务
在执行exec之前执行该命令,提交事务会失败,执行的命令会进行回滚
127.0.0.1:6379> multi //开始事务OK127.0.0.1:6379> sadd tt 1 //业务操作QUEUED127.0.0.1:6379> DISCARD //停止事务OK127.0.0.1:6379> exec //提交事务(error) ERR EXEC without MULTI //报不存在事务异常127.0.0.1:6379> get tt //获取不到对象(nil)127.0.0.1:6379>
2、事务异常
Redis支持事务,但他属于弱事务,中间的一些异常可能会导致事务失效。
往期面试题:001期~180期汇总
1、命令错误,语法不正确,导致事务不能正常结束
127.0.0.1:6379> multi //开始事务OK127.0.0.1:6379> set aa 123 //业务操作QUEUED127.0.0.1:6379> sett bb 124 //命令错误(error) ERR unknown command 'sett'127.0.0.1:6379> exec(error) EXECABORT Transaction discarded because of previous errors. //提交事务异常127.0.0.1:6379> get aa //查询不到数据(nil)127.0.0.1:6379>
2、运行错误,语法正确,但类型错误,事务可以正常结束
127.0.0.1:6379> multiOK127.0.0.1:6379> set t 1 //业务操作1QUEUED127.0.0.1:6379> sadd t 1 //业务操作2QUEUED127.0.0.1:6379> set t 2 //业务操作3QUEUED127.0.0.1:6379> exec1) OK2) (error) WRONGTYPE Operation against a key holding the wrong kind of value //类型异常3) OK127.0.0.1:6379> get t //可以获取到t"2"127.0.0.1:6379>
三、Redis发布与订阅
Redis提供了“发布、订阅”模式的消息机制,其中消息订阅者与发布者不直接通信,发布者向指定的频道(channel)发布消息,订阅该频道的每个客户端都可以接收到消息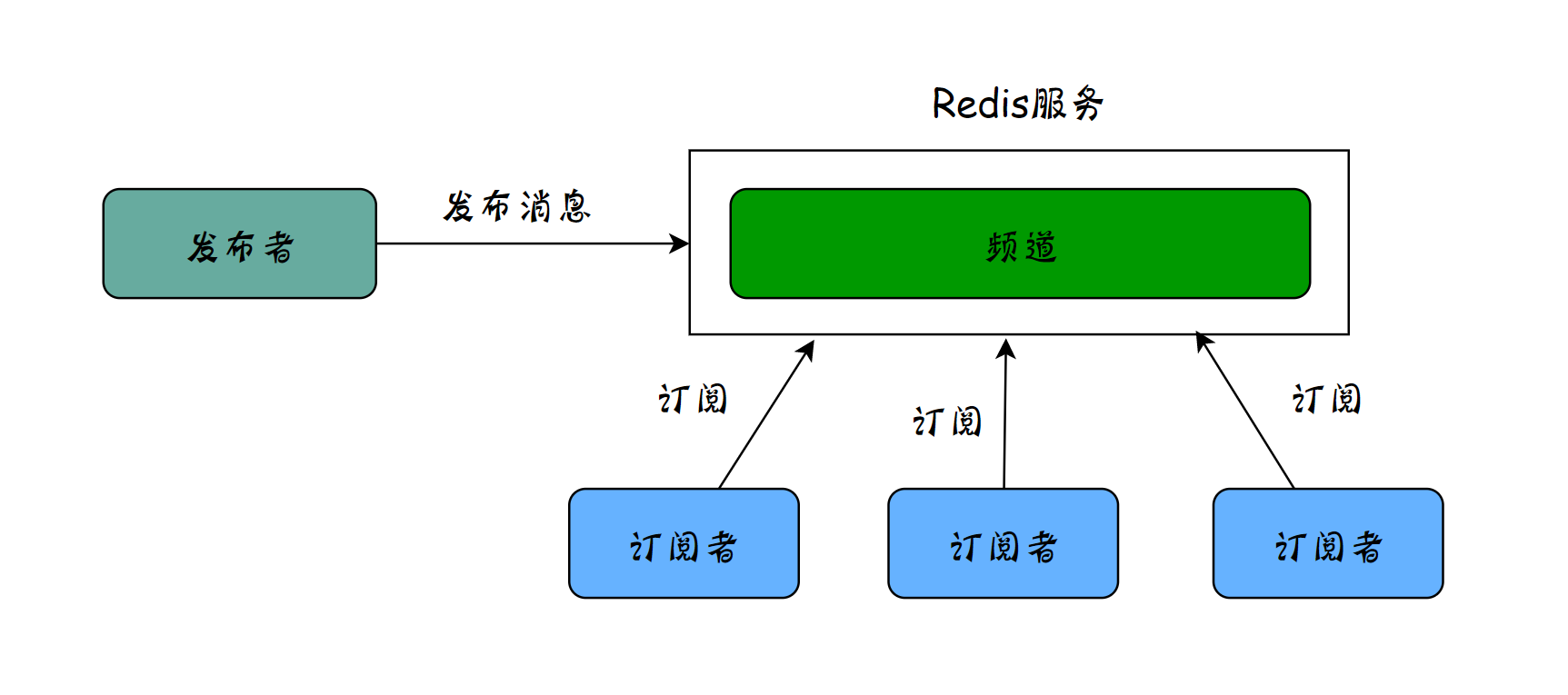
1、Redis发布订阅常用命令
| 命令 | 含义 |
|---|---|
| publish channel | 发布消息 |
| subscribe channel | 订阅消息 |
| pubsub numsub channel | 查看订阅数 |
| unsubscribe channel | 取消订阅 |
| psubscribe ch* | 按模式订阅和取消订阅 |
2、应用场景
Redis主要提供发布消息、订阅频道、取消订阅以及按照模式订阅和取消订阅,和很多专业的消息队列(kafka rabbitmq),Redis的发布订阅显得很lower, 比如无法实现消息规程和回溯, 但就是简单,如果能满足应用场景,用这个也可以
- 订阅号、公众号、微博关注、邮件订阅系统等
- 即使通信系统
- 群聊部落系统(微信群)
四、键的迁移
键迁移大家可能用的不是很多,因为一般都是使用Redis主从同步。不过对于做数据统计分析使用的时候,可能会使用到,比如用户标签。为了避免key批量删除导致的Redis雪崩,一般都是通过一个计算使用的Redis和一个最终业务使用的Redis,通过将计算时用的Redis里的键值通过迁移的方式一个一个的更新到业务Redis中,使其对业务冲击最小化。1、move
move指令将Redis一个库中的数据迁移到另外一个库中。
如果key在目标数据库中已存在,那么什么也不会发生。这种模式不建议在生产环境使用,在同一个reids里可以玩move key db //reids有16个库, 编号为0-15set name DK; move name 5 //迁移到第6个库elect 5 ;//数据库切换到第6个库,get name 可以取到james1
2、dump
Redis DUMP 命令用于将key给序列化 ,并返回被序列化的值。用于导入到其他服务中
一般通过dump命令导出,使用restore命令导入。
1.在A服务器上
2.在B服务器上set name james;dump name; // 得到"\x00\x05james\b\x001\x82;f\"DhJ"
restore name 0 "\x00\x05james\b\x001\x82;f\"DhJ" //0代表没有过期时间get name //返回james
3、migrate
migrate用于在Redis实例间进行数据迁移,实际上migrate命令是将dump、restore、del三个命令进行组合,从而简化了操作流程。
往期面试题:001期~180期汇总
migrate命令具有原子性,从Redis 3.0.6版本后已经支持迁移多个键的功能。migrate命令的数据传输直接在源Redis和目标Redis上完成,目标Redis完成restore后会发送OK给源Redis。
| migrate | 192.168.42.112 | 6379 | name | 0 | 1000 | copy | replace |
|---|---|---|---|---|---|---|---|
| 指令 | 要迁移的目标IP | 端口 | 迁移键值 | 目标库 | 超时时间 | 迁移后不删除原键 | 不管目标库是不存在test键都迁移成功 |
比如:把111上的name键值迁移到112上的Redis
192.168.42.111:6379> migrate 192.168.42.112 6379 name 0 1000 copy
五、自定义命令封装
当使用jedis或者jdbctemplate时,想执行键迁移的指令的时候,发现根本没有封装相关指令,这个时候该怎么办呢?除了框架帮封装的方法外,自己也可以通过反射的方式进行命令的封装,主要步骤如下
- 建立
Connection链接,使用Connection连接Redis - 通过反射获取
Connection中的sendCommand方法(protected Connection sendCommand(Command cmd, String... args))。 - 调用
connection的sendCommand方法,第二个参数为执行的命令(比如set,get,client等),第三个参数为命令的参数。可以看到ProtocolCommand这个枚举对象包含了Redis的所有指令,即所有的指令都可以通过这个对象获取到。并封装执行 - 执行
invoke方法,并且按照Redis的指令封装参数 - 获取Redis的命令执行结果 ```java import redis.clients.jedis.Connection; import redis.clients.jedis.Protocol;
import java.io.IOException; import java.lang.reflect.InvocationTargetException; import java.lang.reflect.Method;
/**
- @Auther: Fcant
- @Date: 2020/10/11 23:17
@Description: */ public class RedisKeyMove {
public static void main(String[] args) throws IOException {
//1.使用Connection连接Redistry (Connection connection = new Connection("10.1.253.188", 6379)) {// 2. 通过反射获取Connection中的sendCommand方法(protected Connection sendCommand(Command cmd, String... args))。Method method = Connection.class.getDeclaredMethod("sendCommand", Protocol.Command.class, String[].class);method.setAccessible(true); // 设置可以访问private和protected方法// 3. 调用connection的sendCommand方法,第二个参数为执行的命令(比如set,get,client等),第三个参数为命令的参数。// 3.1 该命令最终对应redis中为: set test-key test-valuemethod.invoke(connection, Protocol.Command.MIGRATE,new String[] {"10.1.253.69", "6379", "name", "0", "1000", "copy"});// 4.获取Redis的命令执行结果System.out.println(connection.getBulkReply());} catch (NoSuchMethodException e) {e.printStackTrace();} catch (IllegalAccessException e) {e.printStackTrace();} catch (InvocationTargetException e) {e.printStackTrace();}
六、键全量遍历
1、keys
| 指令 | 含义 | | —- | —- | |
keys *| 返回所有的键,匹配任意字符多个字符 | | `keys y| 以y结尾的键 | |keys ne| 以n开头以e结尾,返回name | |keys n?me| ?问号代表只匹配—个字符返回name,全局匹配 | |keys n?m| 返回name | |keys [j,l]*| 返回以j,l开头的所有键keys [j]ames全量匹配james` |
考虑到是单线程,使用改命令会阻塞线程, 在生产环境不建议使用,键多可能会阻塞。
2、渐进式遍历 scan
1,初始化数据
mset n1 1 n2 2 n3 3 n4 4 n5 5 n6 6 n7 7 n8 8 n9 9 n10 10 n11 11 n12 12 n13 13
2,遍历匹配
scan 0 match n* count 5 匹配以n开头的键,最大是取5条,第一次scan 0开始
第二次从游标4096开始取20个以n开头的键,相当于一页一页的取当最后返回0时,键被取完。
3、scan 和keys对比
- 通过游标分布进行的,不会阻塞线程;
- 提供 limit 参数,可以控制每次返回结果的最大条数,limit 不准,返回的结果可多可少;
- 同 keys 一样,Scan也提供模式匹配功能;
- 服务器不需要为游标保存状态,游标的唯一状态就是 scan 返回给客户端的游标整数;
- scan返回的结果可能会有重复,需要客户端去重复;
- scan遍历的过程中如果有数据修改,改动后的数据能不能遍历到是不确定的;
- 单次返回的结果是空的并不意味着遍历结束,而要看返回的游标值是否为零;
4、其他遍历命令
SCAN 命令用于迭代当前数据库中的数据库键。
SSCAN 命令用于迭代集合键中的元素。
HSCAN 命令用于迭代哈希键中的键值对。
ZSCAN 命令用于迭代有序集合中的元素(包括元素成员和元素分值)。
用法和scan一样

若有收获,就点个赞吧
0 人点赞
