什么是无锁编程
无锁变成并不是“不用锁来编写多线程程序”。无锁仅仅是代码的一种性质,并不是无锁编程的全部内容。
一般来说,如果无锁编程满足下面条件,就可以认为是无锁的,如果不满足,那么就不是无锁的。
通过上图,我我们发现“无锁(lock-free)”这个词中的“锁(lock)”并不是指代码中的“锁(mutex)”,而是指的是能够通过某种方式“阻塞(locking up)”整个程序的可能性。这个可能性可能来源于经典的“死锁(deadlock)”,也可能由于很糟糕的内存调度顺序使得程序停滞不前(这可能变成一些恶意攻击者的突破口)。这听起来挺搞笑的,但是由于持有锁(mutex)的线程的调用顺序是任意的,因此最坏的情况是可能发生的,纵使有些时候,理论计算告诉我们“最坏情况”是一个不可能事件(概率为0),但是从概念上来说,只要“可能发生”阻塞,那么这个程序就不是无锁的。
没有人指望一个很大的工程是完全无锁的,通常来说,我们希望这个工程中某一个访问了公有内存的代码片段是无锁的。举一个例子,我们可能希望拥有一个“无锁队列”,这个无锁队列支持若干无锁的操作,诸如 push , pop , isEmpty 等等操作。
无锁编程的技巧
当你尝试去实现一个无阻塞的无锁程序,这会引出一系列技巧,比如:原子操作(atomic operations),内存屏障(memory barriers), ABA问题等。从这里开始,问题就变得棘手起来。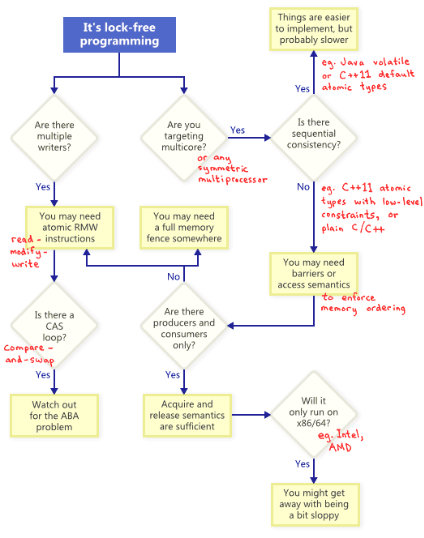
原子的“读-修改-写”操作
原子操作的定义为一系列可以访问内存,并且不可分割的操作。没有任何线程可以观测到进行了一半的原子操作。在现代的处理器中,很多的操作都是原子的,比如:基础数据类型的“对齐读取(aligned reads)”和“对齐写(aligned writes)”通常是原子的。
更近一步,我们有了 读-修改-写(Read-modify-write) (RMW)操作,这个操作使我们可以原子化更复杂的操作,特别的,当有多个写线程时,这个操作非常有用。原因在于,当多个线程试图去读-修改-写一个内存区域时,他们会自动被排成不想交的一列,并依次执行。
正如流程图中所说,RMW十分重要,即使是在只有一个处理器的系统中。如果没有了原子性,一个线程可能被中断打断,并导致一些潜在的问题
“比较并交换”循环
最常讨论的RMW操作是 比较并交换(compare-and-swap) (CAS)。在Win32里面,CAS通过一系列intrinsics函数实现的,比如 _InterlockedCompareExchange 。通常情况下,我们在循环中使用CAS操作来尝试提交一些操作。具体来说,我们首先拷贝一些公有变量到局部变量中,并进行一些操作来改动局部变量的值,最后,将这些改动借助CAS操作提交至公有可见。
void LockFreeQueue::push(Node* newHead){for (;;){// Copy a shared variable (m_Head) to a local.Node* oldHead = m_Head;// Do some speculative work, not yet visible to other threads.newHead->next = oldHead;// Next, attempt to publish our changes to the shared variable.// If the shared variable hasn't changed, the CAS succeeds and we return.// Otherwise, repeat.if (_InterlockedCompareExchange(&m_Head, newHead, oldHead) == oldHead)return;}}
顺序一致性
顺序一致性(Sequential Consistency)意味着所有的线程都有共同的对于内存访问操作的顺序的判定。这个判定的内存访问操作的顺序恰好等同于在源代码中的内存访问定义的顺序。在线性一致性模型中,一些内存顺序有关的问题不会发生。
一个非常简单(但是显然不可能在实际中使用的)解决内存一致性的方式是禁用编译器优化,并且强制所有的线程在同一个处理器上面运行。这样,即使存在着线程的切换,处理器将永远无法发现自己的内存顺序出现了问题。
内存顺序
正如流程图中所述,当你在多核计算机上运行无锁程序,且你的程序并没有保证内存顺序一致性的时候,你需要思考如何避免内存乱序的发生。
在线代的处理器结构中,这些试图矫正内存顺序的方法可以分为两类分别是矫正 编译器导致的内存乱序(compiler reordering)和 处理器导致的内存乱序(processor reordering) 具体而言有如下方式:
- 一系列轻量级的同步以及屏障指令,这些我将在之后讨论
- 一系列内存屏障的指令,我在之前已经展示过
- 一些内存顺序的指令,提供了acquire和release语义
Acquire语义防止该语句后的语句内存乱序,而Release语义防止了该语句之前语句的错排,这些语义特别适合用于处理“生产者/消费者”关联的线程关系,一个线程生产并广播消息,而另一个线程接收消息,这些我也将在之后的文章中详述。
不同处理器有不同的内存模型
不同的处理器有不同的内存模型,在内存重拍的问题上,不同的CPU以来的规则是依赖于硬件的,比如PowerPC和ARM处理器可以修改内存写的执行顺序,而Inter和AMD的x86/64处理器则不行。因此,古老的处理器有更加弱的内存模型(relaxed memory model).
通过C++11,我们可以调用一些固有的模板来无视掉这些由于平台导致的问题。不过我认为程序员们需要知道不同平台的区别。其中比较重要的一点事,在x86/64的处理器层面,所有的读(load)操作都自带了acquire语义,而所有的写(store)操作都自带了release语义,至少对于非SSE指令集和非并行储存的内存模型而言是这样的。从结果上来看,一些在x86/64上运行正常的程序在其他处理器上崩溃就不是一件很奇怪的事情了。
如果你对于处理器如何将内存操作重排感兴趣的话,我推荐你阅读Is Parallel Programming Hard的附录C。并且时刻警醒内存重排有时候是来自于编译器而非处理器。
在这篇文章中,我们有过多的提及无锁编程的一些实际代码编写上的策略,比如什么时候我们应该用无锁编程,我们应该做到什么程度,以及验证你程序有效性的必要性。

若有收获,就点个赞吧
0 人点赞
