題目
使用Heart Failure Prediction Dataset做分類實驗,要使用多種分類方法。
繳交報告,說明使用方法,細節,結果,分析等。
資料: https://www.kaggle.com/fedesoriano/heart-failure-prediction
| 年齡 | 性別 | 胸痛類型 | 靜息血壓 | 血清膽固醇 | 空腹血糖 | 靜息心電圖結果 | 達到的最大心率 | 運動誘發的心絞痛 | 抑鬱症測量的數值 | 運動ST段的坡度 | 心臟病 |
|---|---|---|---|---|---|---|---|---|---|---|---|
- Age:患者年齡[年]
- Sex:患者的性別[M:男,F:女]
- ChestPainType:胸痛類型 [TA:典型心絞痛,ATA:非典型心絞痛,NAP:非心絞痛,ASY:無症狀]
- RestingBP:靜息血壓 [mm Hg]
- Cholesterol:血清膽固醇 [mm/dl]
- FastingBS:空腹血糖 [1:如果 FastingBS > 120 mg/dl,0:否則]
- RestingECG:靜息心電圖結果 [正常:正常,ST:有 ST-T 波異常(T 波倒置和/或 ST 抬高或壓低 > 0.05 mV),LVH:根據埃斯蒂斯標準顯示可能或明確的左心室肥大]
- MaxHR:達到的最大心率 [60 到 202 之間的數值]
- ExerciseAngina:運動誘發的心絞痛 [Y:是,N:否]
- Oldpeak:oldpeak = ST [抑鬱症測量的數值]
- ST_Slope:運動ST段的坡度[Up:向上傾斜,Flat:平坦,Down:向下傾斜]
- HeartDisease:輸出類[1:心髒病,0:正常]
機器學習的七個步驟
- 收集資料(Gathering data )
- 準備數據(Preparing that data)
- 選擇模型(Choosing a model)
- 訓練機器(Training)
- 評估分析(Evaluation)
- 調整參數(Hyperparameter tuning)
- 預測推論(Prediction)
問題定義
Classification
監督式學習中預測的Y如果是不連續的值(項目種類),則是分類(classification)。例如:是否退租?是否回購?是否換手機?喜歡什麼顏色?…等。
Regression
監督式學習中預測的Y如果是連續的值,則是迴歸(Regression)。例如:預測房屋價格、預測股價、預測體重、預測購買機率…等。
🧀問題類型:分類
🧀可使用方法
【機器學習懶人包】從數據分析到模型整合,各種好用的演算法全都整理給你啦!
- K-近鄰演算法(K-NN)
K-NN 演算法是一種最簡單的分類演算法,透過識別被分成若干類的數據點,以預測新樣本點的分類。K-NN 是一種非參數的演算法,是「懶惰學習」的著名代表,它根據相似性(如,距離函數)對新數據進行分類。
- 支持向量機(SVM)
支持向量機既可用於迴歸也可用於分類。它基於定義決策邊界的決策平面。決策平面(超平面)可將一組屬於不同類的對象分開。
- 樸素貝氏(樸素貝葉斯)
樸素貝氏分類器建立在貝氏定理的基礎上,基於特徵之間互相獨立的假設(假定類中存在一個與任何其他特徵無關的特徵)。即使這些特徵相互依賴,或者依賴於其他特徵的存在,樸素貝氏演算法都認為這些特徵都是獨立的。這樣的假設過於理想,樸素貝氏因此而得名。
- 決策樹分類
決策樹以樹狀結構建構分類或迴歸模型。它透過將數據集不斷分拆成更小的子集,來使決策樹不斷生長,最終長成具有決策節點(包括根節點和內部節點)和葉節點的樹。最初的決策樹演算法,採用了 Iterative Dichotomiser 3(ID3)演算法來確定分裂節點的順序。
- 隨機森林分類器
隨機森林分類器是一種基於裝袋(bagging)的整合演算法,即自舉助聚合法(bootstrap aggregation)。整合演算法結合了多個相同或不同類型的演算法,來對對象進行分類(例如,SVM 的整合,基於樸素貝氏的整合或基於決策樹的整合)。
- 邏輯回歸
它為邏輯回歸分析(Logistic Regression, LR),是分類和預測演算法中的一種。採用的是監督學習的方式,通過分析歷史數據特徵來對未來事件發生的概率進行預測。
🧀評估方式
混淆矩陣
混淆矩陣是一張表,這張表透過對比已知分類結果的測試數據的預測值,和真值表來描述衡量分類器的性能。在二分類的情況下,混淆矩陣是展示預測值和真實值四種不同結果組合的表。
ROC曲線和AUC面積(?)
實作
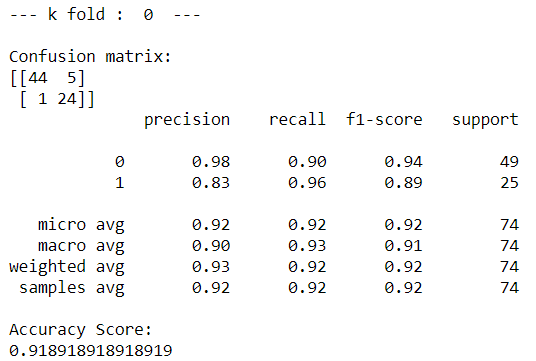
classification_report 的指標分析
classification_report(y_test,y_pred)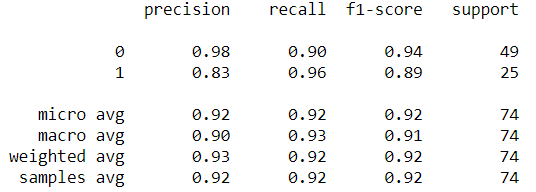
在這個報告中:
- y_test 爲樣本真實標籤,y_pred 爲樣本預測標籤;
- precision:精度=正確預測的個數(TP)/被預測正確的個數(TP+FP);也就是模型預測的結果中有多少是預測正確的
- recall:召回率=正確預測的個數(TP)/預測個數(TP+FN);也就是某個類別測試集中的總量,有多少樣本預測正確了;
- f1-score:F1 = 2精度召回率/(精度+召回率)
- support:當前行的類別在測試數據中的樣本總量
- micro avg:計算所有數據下的指標值,假設全部數據 5 個樣本中有 3 個預測正確,所以 micro avg 爲 3/5=0.6
- macro avg:每個類別評估指標未加權的平均值,比如準確率的 macro avg,(0.50+0.00+1.00)/3=0.5
- weighted avg:加權平均,就是測試集中樣本量大的,我認爲它更重要,給他設置的權重大點;比如第一個值的計算方法,(0.501 + 0.01 + 1.0*3)/5 = 0.70
K-近鄰演算法(K-NN)
- kNN算法中的超参数:k、weights、P;
SVM
linear:线性核函数(linear kernel)
polynomial:多项式核函数(ploynomial kernel)
RBF:径向基核函数(radical basis function)
sigmoid: 神经元的非线性作用函数核函数(Sigmoid tanh)
precomputed :用户自定义核函数
RBF內核參數
使用徑向基函數(RBF) 核訓練 SVM 時,必須考慮兩個參數:C和gamma。C所有 SVM 內核共有的參數,在訓練示例的錯誤分類與決策表面的簡單性之間進行權衡。低C使決策表面平滑,而高C旨在正確分類所有訓練示例。 gamma定義單個訓練示例的影響有多大。越大gamma,其他示例必須受到影響。
的正確選擇C和gamma是對SVM的性能至關重要。一是建議使用GridSearchCV與 C和gamma間隔成倍天南地北地選擇良好的價值觀。
第二個圖是作為C和函數的分類器交叉驗證準確度的熱圖gamma。在這個例子中,我們探索了一個相對較大的網格以進行說明。在實踐中,對數網格來自 10−3 到 103通常就足夠了。如果最佳參數位於網格的邊界上,則可以在後續搜索中沿該方向擴展。

若有收获,就点个赞吧
0 人点赞
