1.大作业规则
- 每个任务选题仅供3个小组使用,每个小组最多6人;
- 针对每个具体任务,按照数据预处理、可视化、特征分析、建立模型、训练与测试和分析结果的流程进行和撰写报告;
- 提高模型精度、广泛查阅相关资料并进行不同类别、不同对象、不同算法的对比实验,以便支撑最后的结论;
- 答辩按组进行,现场交一份纸质报告,代码运行正常,提交PPT、报告、源码包。
2.小组选题**
🛒商品购买行为分析
任务要求:
数据集是零售商店中某次促销交易样本数据,商店希望更加了解用户购买行为。通过总结本次促销状况,分析和研究不同用户对不同产品的购买行为来为下一次促销提供相关情报和参考,给出有用的建议。具体内容包括:
1) 年龄、职业、生活年限与消费能力相关性分析
2) 预测不同年龄段的消费能力(金额)
3) 对不同人群进行消费能力分类(划分5个等级)
原始题目来源:kaggle (国外的一个众包比赛网站) - 黑色星期五(网上有大量的数据分析和挖掘代码)
赛题地址:https://www.kaggle.com/sdolezel/black-friday
大作业Gitee地址:https://gitee.com/hutingkai/term-project.git (github上传太慢了,反正git下来是一样的)
拟任务流程:
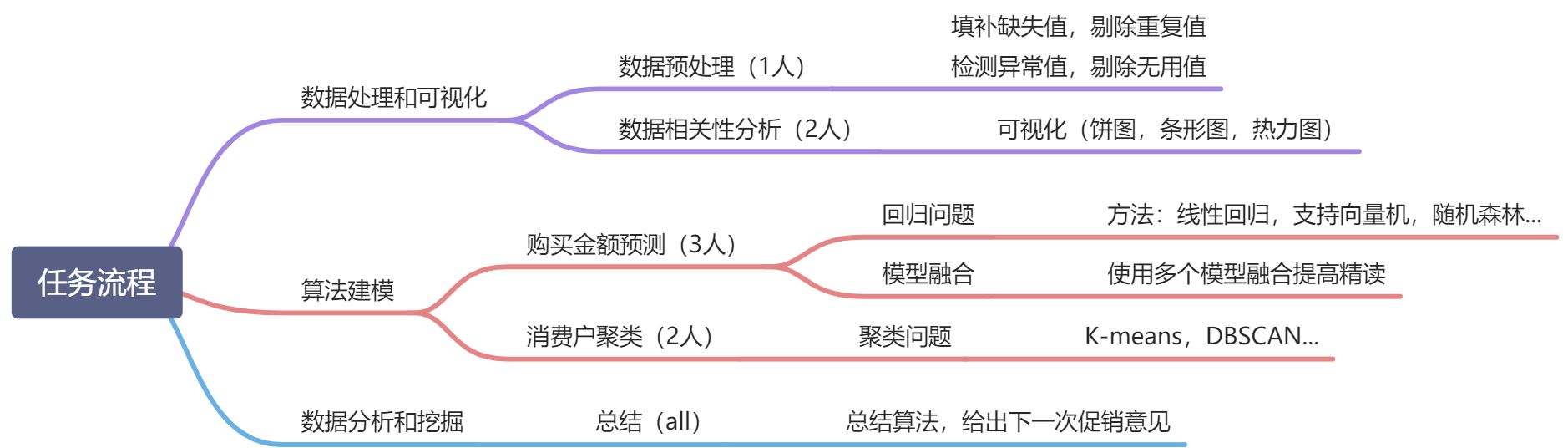
具体细节
数据探索和可视化模块(2)
两部分任务:
1.简单的数据可视化,开一下脑洞挖掘一下原因。比如为什么男性消费用户比女性消费用户多,可能因为促销活动力男性扮演工具人的角色。
2.相关性分析,设计到统计学的知识。稍微难一点,置信度之类的
通过数据探索和可视化分析我们希望能得到以下几个问题的答案:
1.数据集中具有那些特征的用户平均消费能力更强?
- 男性👨vs女性👩
- 已婚vs未婚
- 新居民vs老居民
2.数据集中那些用户群体的规模最大?
3.TOP10热销商品是那些?TOP10的高销售额的商品是那些?其平均售价是多少?有无联系?
4.不同城市的消费主力军是那类用户?
5.年龄、职业、生活年限与消费能力相关性分析
数据预处理模块(2)
三部分任务:
1.清洗:清洗的主要任务在于修复数据。
2.处理:处理的任务设计编码,筛选。
3.特征选择和特征工程:一个字 难
数据划分
https://www.cnblogs.com/xxxxxxxxx/p/10987366.html
数据清洗【Date cleaing】
对数据进行重新审查和校正的过程,目的在于删除重复信息、纠正存在的错误,并提供数据一致性。
数据清洗的难点
数据清理一般针对具体应用场景,因而难以归纳统一的方法和步骤,但是根据数据不同可以给出相应的数据清理方法。
数据清洗方法(Data cleaning method)
1.解决缺失值:最大值、最小值、平均值或者更为复杂的概率估计代替缺失值。
2.去重复值:相等的记录合并为一条记录(既合并/清除)
3.解决错误值:用统计分析的方法识别可能的错误值或者异常值,如偏差分析、识别不遵守分布或者回归方程的值,也可以用简单规则库(常识性规则、业务特定规则等)
检查数据值,或者使用不同属性间的约束、外部的数据来检测和清理数据。
4.解决数据的不一致性:比如数据是类别类型或者次序类型。
!!!删除数据是底线,能不用就不用,删除会损失数据中的信息,特别是样本量特别小的时候。
数据清洗八大场景
1.删除多列
2.更改数据类型
3.将分类变量转换为数字变量
4.检查缺失数据
5.删除列中的字符串
6.输删除列中的空值(Nan)
7.用字符串连接两列(带条件)
8.转换时间戳(从字符串到日期时间格式)
数据处理(Data Processing)
数据处理是对数据进行分析和加工的技术过程。让数据更好的能够拟合好我们的模型,更便于计算,减少计算量,但是具体问题要具体分析。
数据处理方法
1.对数变换
2.标准缩放
3.转换数据类型
4.独热编码
5.标签编码
EDA数据探索分析
懒人报表:分布、热力图
import pandas_profiling as ppfppf.ProfileReport(dataset)
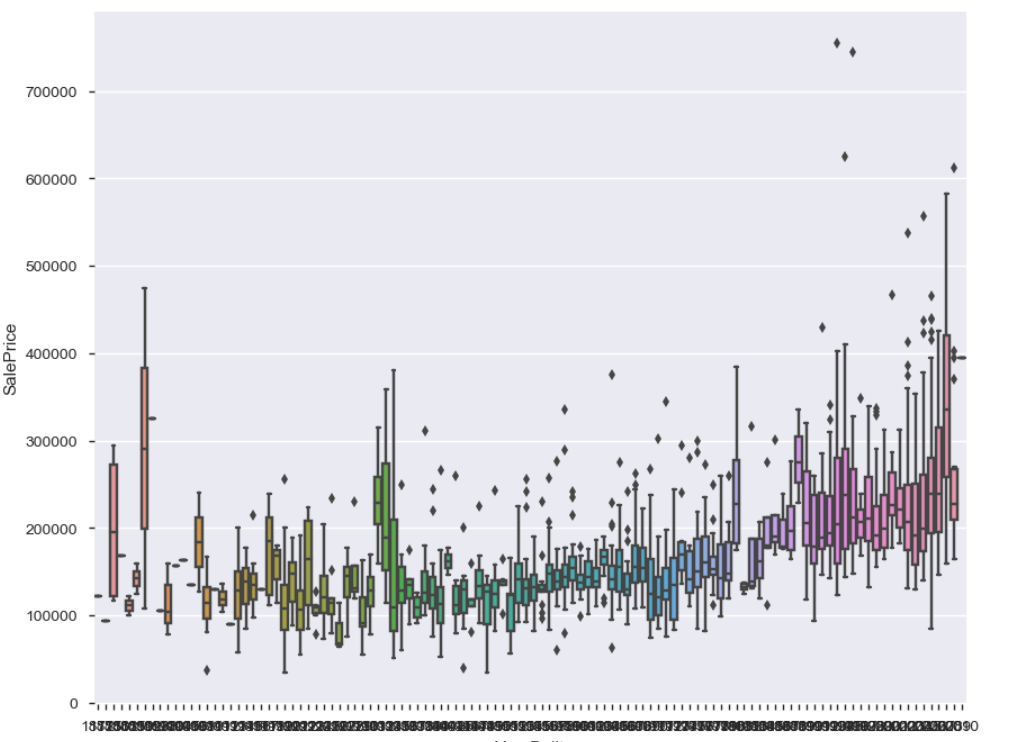
箱型图
查看离群值(异常值)
plt.figure(figsize=(10,8))sns.boxplot(train.YearBuilt, train.SalePrice)##箱型图是看异常值的,离群点
散点图
可以观察是否存在线性关系
plt.figure(figsize=(12,6))plt.scatter(x=train.GrLivArea, y=train.SalePrice)##可以用来观察存在线型的关系plt.xlabel("GrLivArea", fontsize=13)plt.ylabel("SalePrice", fontsize=13)plt.ylim(0,800000)
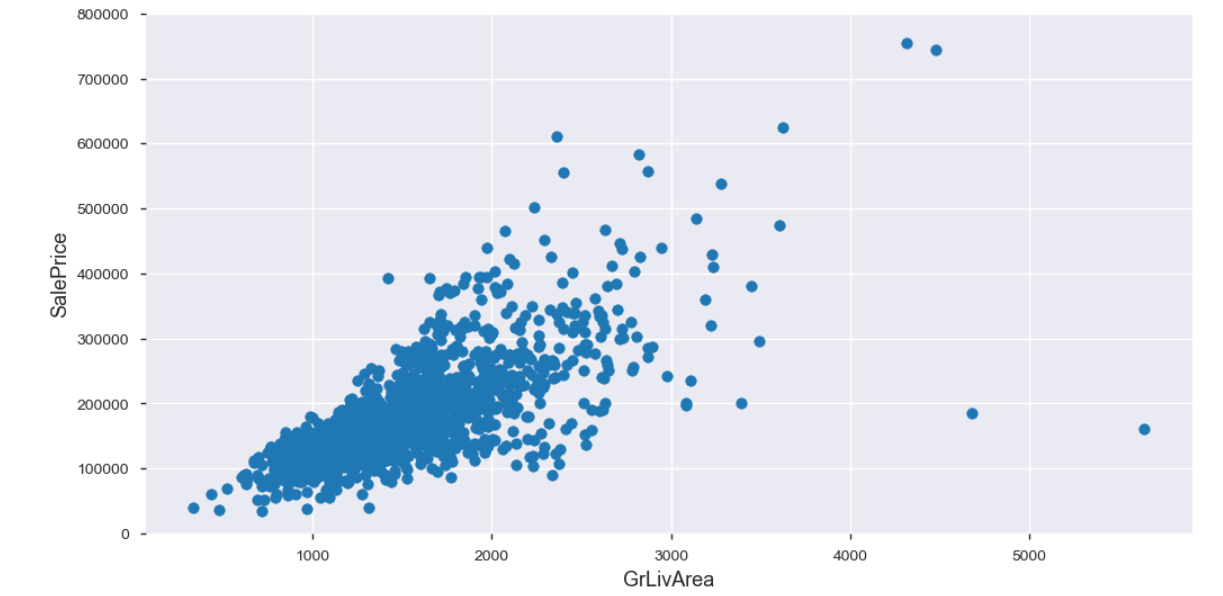
# 找到了离群值和非线性值,当然要删除啦train.drop(train[(train["GrLivArea"]>4000)&(train["SalePrice"]<300000)].index,inplace=True)#pandas 里面的条件索引
预测算法模块(2)
主要任务:
先找多个单模型训练,调参到最优,如线性回归、随机森林回归、决策树回归、XGB
之后做模型集成ensemble learning 收工
评价标准用RMSE,R2
聚类算法模块(2)
主要任务:
把老师上课交的KNN,和DBCSAN用上,比较一下,收工
大作业代码
1.数据探索
2.数据分割
3.数据清洗与处理
4.预测分析
5.聚类

若有收获,就点个赞吧
0 人点赞
