语料说明
数据语料用处:文本分类、信息抽取、舆情分析、应急管理
语料表1字段说明:【标签、标题、发布时间、新闻链接】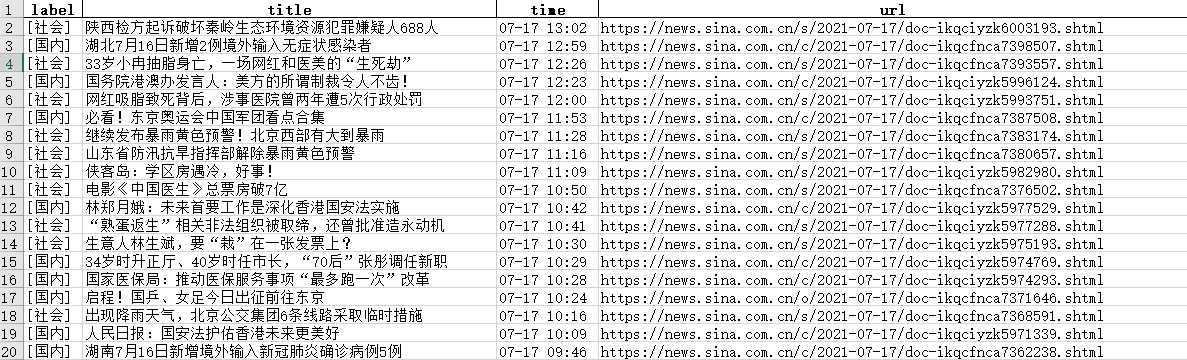
语料表2字段说明:【标题、作者、发布时间、正文、图片路径】
爬虫源码安装和解析
爬虫实现工具:selenium、requests、BeautifulSoup
爬虫流程构建:实现定时一次爬取,可自由选择是否二次爬取。(为了防止重复爬取,应该有个去重判断处理,还没有写;另外还应该有针对主题的三次爬取)
爬虫源码
函数的参数都给出了具体说明,以及函数的输入输出说明
- 导入依赖
import osimport randomimport pickleimport datetimeimport requestsimport pandas as pdimport timefrom tqdm import tqdmfrom bs4 import BeautifulSoupfrom gne import GeneralNewsExtractorfrom selenium import webdriverfrom selenium.webdriver.chrome.options import Optionsimport syssys.setrecursionlimit(10000)
SinaNewsExtractor Sina滚动新闻提取器
- SinaNewsExtractor
def SinaNewsExtractor(url=None,page_nums=50,stop_time_limit=3,verbose=1,withSave=False):"""url:爬取链接,具有既定格式 https://news.sina.com.cn/roll/#pageid=153&lid=2970&k=&num=50&page={}page_nums:爬取滚动新闻的页码数,可取值范围为[1,50]的整数,默认为50(最大值)stop_time_limit:为防止爬虫封锁IP,采用时停策略进行缓冲,可控制时停的上界,输入为一个整数,默认为3verbose:控制爬取可视化打印的标志位,0表示不显示,1表示html打印,2表示详细打印,默认为1withSave:是否保存输出到当前文件夹下,默认False函数输入:url函数输出:具有新闻信息的pandas表格、由bs4组成的html列表"""day_html = []df = pd.DataFrame([],columns=["label","title","time","url"])url = "https://news.sina.com.cn/roll/#pageid=153&lid=2970&k=&num=50&page={}"chrome_options = Options()chrome_options.add_argument('--headless')driver = webdriver.Chrome("chromedriver.exe",chrome_options=chrome_options) # 启动driverdriver.implicitly_wait(60)# 获取html,主要耗时for page in range(1,page_nums+1):driver.get(url.format(page))driver.refresh()soup = BeautifulSoup(driver.page_source,"lxml")frame = soup.find("div",attrs={"class":"d_list_txt","id":"d_list"})day_html.append(frame)time.sleep(random.randint(1,stop_time_limit))if verbose != 0:print(page,url.format(page),len(day_html))# 提取新闻信息,超快for html in day_html:for li in html.find_all("li"):url = li.a["href"]label = li.span.texttitle = li.a.textpublic = li.find("span",attrs={"class":"c_time"}).textdf.loc[len(df)] = [label,title,public,url]if verbose ==2:print("{}\t{}\t{}".format(df.shape[0],public,title))# 关闭driver,防止后台进程残留driver.quit()# 开启保存if withSave:if os.path.isdir("dataDaliy") is False:os.makedirs('dataDaliy')if os.path.isdir("pklDaliy") is False:os.makedirs('pklDaliy')curr = datetime.datetime.now()curr_pkl = "pklDaliy/{}_{}_{}_{}_{}news.pkl".format(curr.year,curr.month,curr.day,curr.hour,curr.minute)curr_excel = "dataDaliy/{}_{}_{}_{}_{}news.xlsx".format(curr.year,curr.month,curr.day,curr.hour,curr.minute)pickle.dump(day_html,open(curr_pkl,"wb"))df.to_excel(curr_excel,index=False)return df,day_html
SingleNewsExtractor 单条新闻详细信息提取
- SingleNewsExtractor
def SingleNewsExtractor(url,verbose=False):"""url:新闻链接verbose:是否开启打印,默认为False"""extractor = GeneralNewsExtractor()user_agent_pc = [# 谷歌'Mozilla/5.0.html (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.html.2171.71 Safari/537.36','Mozilla/5.0.html (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.html.1271.64 Safari/537.11','Mozilla/5.0.html (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.html.648.133 Safari/534.16',# 火狐'Mozilla/5.0.html (Windows NT 6.1; WOW64; rv:34.0.html) Gecko/20100101 Firefox/34.0.html','Mozilla/5.0.html (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',# opera'Mozilla/5.0.html (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.html.2171.95 Safari/537.36 OPR/26.0.html.1656.60',# qq浏览器'Mozilla/5.0.html (compatible; MSIE 9.0.html; Windows NT 6.1; WOW64; Trident/5.0.html; SLCC2; .NET CLR 2.0.html.50727; .NET CLR 3.5.30729; .NET CLR 3.0.html.30729; Media Center PC 6.0.html; .NET4.0C; .NET4.0E; QQBrowser/7.0.html.3698.400)',# 搜狗浏览器'Mozilla/5.0.html (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.html.963.84 Safari/535.11 SE 2.X MetaSr 1.0.html',# 360浏览器'Mozilla/5.0.html (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.html.1599.101 Safari/537.36','Mozilla/5.0.html (Windows NT 6.1; WOW64; Trident/7.0.html; rv:11.0.html) like Gecko',# uc浏览器'Mozilla/5.0.html (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.html.2125.122 UBrowser/4.0.html.3214.0.html Safari/537.36',]user_agent = {'User-Agent':random.choice(user_agent_pc)}rep = requests.get(url, headers=user_agent)source = rep.content.decode("utf-8",errors='ignore')result = extractor.extract(source)if verbose:print(result)return result
FileNewsExtractor 文档级别新闻详细信息提取
- FileNewsExtractor
def FileNewsExtractor(csv_file,save_file,verbose=False):"""csv_file:csv路径save_file:保存文件路径verbose:是否开启打印,默认为False函数输入:csv文件路径(必须有url)、提取新闻的文件保存路径函数输出:具有详细新闻信息的pandas表"""news = pd.DataFrame([],columns=['title', 'author', 'publish_time', 'content', 'images'])data = pd.read_excel(csv_file)for idx,news_url in tqdm(enumerate(data["url"]),total=len(data["url"])):news_infos = SingleNewsExtractor(news_url,verbose=verbose)news.loc[idx] = news_infosif idx % 3 and idx != 0:time.sleep(random.randint(1,3))news.to_excel(save_file,index=False)return news
main 主程序
# 测试主程序def test(c1 = False ,c2 = False):# 测试1if c1:url = "https://news.sina.com.cn/roll/#pageid=153&lid=2970&k=&num=50&page={}"df,day_html = SinaNewsExtractor(url=url,page_nums=50,stop_time_limit=5,verbose=1,withSave=True)# 测试 2if c2:FileNewsExtractor("dataDaliy/2021_7_17_9_26news.xlsx","detailed_news.xlsx")if __name__ == '__main__':test(c1=False,c2=False)
完整代码
import osimport randomimport pickleimport datetimeimport requestsimport pandas as pdimport timefrom tqdm import tqdmfrom bs4 import BeautifulSoupfrom gne import GeneralNewsExtractorfrom selenium import webdriverfrom selenium.webdriver.chrome.options import Optionsimport syssys.setrecursionlimit(10000)def SinaNewsExtractor(url=None,page_nums=50,stop_time_limit=3,verbose=1,withSave=False):"""url:爬取链接,具有既定格式 https://news.sina.com.cn/roll/#pageid=153&lid=2970&k=&num=50&page={}page_nums:爬取滚动新闻的页码数,可取值范围为[1,50]的整数,默认为50(最大值)stop_time_limit:为防止爬虫封锁IP,采用时停策略进行缓冲,可控制时停的上界,输入为一个整数,默认为3verbose:控制爬取可视化打印的标志位,0表示不显示,1表示html打印,2表示详细打印,默认为1withSave:是否保存输出到当前文件夹下,默认False函数输入:url函数输出:具有新闻信息的pandas表格、由bs4组成的html列表"""day_html = []df = pd.DataFrame([],columns=["label","title","time","url"])url = "https://news.sina.com.cn/roll/#pageid=153&lid=2970&k=&num=50&page={}"chrome_options = Options()chrome_options.add_argument('--headless')driver = webdriver.Chrome("chromedriver.exe",chrome_options=chrome_options) # 启动driverdriver.implicitly_wait(60)# 获取html,主要耗时for page in range(1,page_nums+1):driver.get(url.format(page))driver.refresh()soup = BeautifulSoup(driver.page_source,"lxml")frame = soup.find("div",attrs={"class":"d_list_txt","id":"d_list"})day_html.append(frame)time.sleep(random.randint(1,stop_time_limit))if verbose != 0:print(page,url.format(page),len(day_html))# 提取新闻信息,超快for html in day_html:for li in html.find_all("li"):url = li.a["href"]label = li.span.texttitle = li.a.textpublic = li.find("span",attrs={"class":"c_time"}).textdf.loc[len(df)] = [label,title,public,url]if verbose ==2:print("{}\t{}\t{}".format(df.shape[0],public,title))# 关闭driver,防止后台进程残留driver.quit()# 开启保存if withSave:if os.path.isdir("dataDaliy") is False:os.makedirs('dataDaliy')if os.path.isdir("pklDaliy") is False:os.makedirs('pklDaliy')curr = datetime.datetime.now()curr_pkl = "pklDaliy/{}_{}_{}_{}_{}news.pkl".format(curr.year,curr.month,curr.day,curr.hour,curr.minute)curr_excel = "dataDaliy/{}_{}_{}_{}_{}news.xlsx".format(curr.year,curr.month,curr.day,curr.hour,curr.minute)pickle.dump(day_html,open(curr_pkl,"wb"))df.to_excel(curr_excel,index=False)return df,day_htmldef SingleNewsExtractor(url,verbose=False):"""url:新闻链接verbose:是否开启打印,默认为False"""extractor = GeneralNewsExtractor()user_agent_pc = [# 谷歌'Mozilla/5.0.html (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.html.2171.71 Safari/537.36','Mozilla/5.0.html (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.html.1271.64 Safari/537.11','Mozilla/5.0.html (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.html.648.133 Safari/534.16',# 火狐'Mozilla/5.0.html (Windows NT 6.1; WOW64; rv:34.0.html) Gecko/20100101 Firefox/34.0.html','Mozilla/5.0.html (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',# opera'Mozilla/5.0.html (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.html.2171.95 Safari/537.36 OPR/26.0.html.1656.60',# qq浏览器'Mozilla/5.0.html (compatible; MSIE 9.0.html; Windows NT 6.1; WOW64; Trident/5.0.html; SLCC2; .NET CLR 2.0.html.50727; .NET CLR 3.5.30729; .NET CLR 3.0.html.30729; Media Center PC 6.0.html; .NET4.0C; .NET4.0E; QQBrowser/7.0.html.3698.400)',# 搜狗浏览器'Mozilla/5.0.html (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.html.963.84 Safari/535.11 SE 2.X MetaSr 1.0.html',# 360浏览器'Mozilla/5.0.html (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.html.1599.101 Safari/537.36','Mozilla/5.0.html (Windows NT 6.1; WOW64; Trident/7.0.html; rv:11.0.html) like Gecko',# uc浏览器'Mozilla/5.0.html (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.html.2125.122 UBrowser/4.0.html.3214.0.html Safari/537.36',]user_agent = {'User-Agent':random.choice(user_agent_pc)}rep = requests.get(url, headers=user_agent)source = rep.content.decode("utf-8",errors='ignore')result = extractor.extract(source)if verbose:print(result)return resultdef FileNewsExtractor(csv_file,save_file,verbose=False):"""csv_file:csv路径save_file:保存文件路径verbose:是否开启打印,默认为False函数输入:csv文件路径(必须有url)、提取新闻的文件保存路径函数输出:具有详细新闻信息的pandas表"""news = pd.DataFrame([],columns=['title', 'author', 'publish_time', 'content', 'images'])data = pd.read_excel(csv_file)for idx,news_url in tqdm(enumerate(data["url"]),total=len(data["url"])):news_infos = SingleNewsExtractor(news_url,verbose=verbose)news.loc[idx] = news_infosif idx % 3 and idx != 0:time.sleep(random.randint(1,3))news.to_excel(save_file,index=False)return news# 测试主程序def test(c1 = False ,c2 = False):# 测试1if c1:url = "https://news.sina.com.cn/roll/#pageid=153&lid=2970&k=&num=50&page={}"df,day_html = SinaNewsExtractor(url=url,page_nums=50,stop_time_limit=5,verbose=1,withSave=True)# 测试 2if c2:FileNewsExtractor("dataDaliy/2021_7_17_9_26news.xlsx","detailed_news.xlsx")if __name__ == '__main__':test(c1=False,c2=False)
c1、c2都是布尔类型,相当于开关,使用True来开启。
表1全都存储在dataDaliy文件夹中
表2是自定义路径存储
同时也会保存表1的html字段到pklDaliy文件夹中
已实现的应用
突发事件新闻抽取及分类【待写】
- 基于规则触发


若有收获,就点个赞吧
0 人点赞
