- Appendix A: Contributing to Documentation
- A.1. Contributing to Documentation or Other Strings
- A.2. Editing the HBase Website
- A.3. Publishing the HBase Website and Documentation
- A.4. Checking the HBase Website for Broken Links
- A.5. HBase Reference Guide Style Guide and Cheat Sheet
- A.6. Auto-Generated Content
- A.7. Images in the HBase Reference Guide
- A.8. Adding a New Chapter to the HBase Reference Guide
- A.9. Common Documentation Issues
My Name - Linux-amd64-64 -> /home/USER/hadoop/lib/native
- Appendix E: SQL over HBase
- Appendix F: YCSB
- Appendix G: HFile format
- G.1. HBase File Format (version 1)
- G.2. HBase file format with inline blocks (version 2)
- G.2.1. Motivation
- G.2.2. Overview of Version 2
- G.2.3. Unified version 2 block format
- G.2.4. Block index in version 2
- G.2.5. Root block index format in version 2
- G.2.6. Non-root block index format in version 2
- G.2.7. Bloom filters in version 2
- G.2.8. File Info format in versions 1 and 2
- G.2.9. Fixed file trailer format differences between versions 1 and 2
- G.2.10. getShortMidpointKey(an optimization for data index block)
- G.3. HBase File Format with Security Enhancements (version 3)
- Appendix H: Other Information About HBase
- Appendix I: HBase History
- Appendix J: HBase and the Apache Software Foundation
- Appendix K: Apache HBase Orca
- Appendix L: Enabling Dapper-like Tracing in HBase
- 201. Client Modifications
- 202. Tracing from HBase Shell
- Appendix M: 0.95 RPC Specification
- Appendix N: Known Incompatibilities Among HBase Versions
- 203. HBase 2.0 Incompatible Changes
- 203.1. List of Major Changes for HBase 2.0
- 203.2. Coprocessor API changes
- 203.2.5. Miscellaneous
- [−] OnlineRegions.getFromOnlineRegions ( String p1 ) [abstract] : HRegion
- [−] RegionCoprocessorEnvironment.getRegion ( ) [abstract] : HRegion
- [−] RegionCoprocessorHost.postAppend ( Append append, Result result ) : void
- [−] RegionCoprocessorHost.preStoreFileReaderOpen ( FileSystem fs, Path p, FSDataInputStreamWrapper in, long size,CacheConfig cacheConf, Reference r ) : StoreFile.Reader
- 203.2.6. IPC
- 203.2.7. Scheduler changes:
- 203.2.8. Server API changes:
- 203.2.9. Replication and WAL changes:
- [−] classWALKey (8)
- WALEdit.getCompaction ( Cell kv ) [static] : WALProtos.CompactionDescriptor (1)
- WALEdit.getFlushDescriptor ( Cell cell ) [static] : WALProtos.FlushDescriptor (1)
- WALEdit.getRegionEventDescriptor ( Cell cell ) [static] : WALProtos.RegionEventDescriptor (1)
- WALKey.getBuilder ( WALCellCodec.ByteStringCompressor compressor ) : WALProtos.WALKey.Builder 1
- 203.2.10. Deprecated APIs or coprocessor:
- 203.2.11. Admin Interface API changes:
- [−] interface Admin (9)
- [−] Admin.createTableAsync ( HTableDescriptor p1, byte[ ][ ] p2 ) [abstract] : void 1
- [−] Admin.disableTableAsync ( TableName p1 ) [abstract] : void 1
- Admin.enableTableAsync ( TableName p1 ) [abstract] : void 1
- [−] Admin.getCompactionState ( TableName p1 ) [abstract] : AdminProtos.GetRegionInfoResponse.CompactionState 1
- [−] Admin.getCompactionStateForRegion ( byte[ ] p1 ) [abstract] : AdminProtos.GetRegionInfoResponse.CompactionState 1
- 203.2.12. HTableDescriptor and HColumnDescriptor changes
- [−] class HColumnDescriptor (1)
- class HTableDescriptor (3)
- [−] HTableDescriptor.getColumnFamilies ( ) : HColumnDescriptor[ ] (1)
- [−] class HColumnDescriptor (1)
- [−] HTableDescriptor.getCoprocessors ( ) : List (1)
- HTableWrapper changes:
- [−] HTableWrapper.createWrapper ( List openTables, TableName tableName, CoprocessorHost.Environment env, ExecutorService pool ) [static] : HTableInterface 1
- [−] interface Table (4)
- 203.2.13. Deprecated buffer methods in Table (in 1.0.1) and removed in 2.0.0
- 203.2.14. class OperationConflictException (1)
- 203.2.15. class class LockTimeoutException (1)
- 203.2.16. Filter API changes:
- [−] class Filter (2)
- [−] class RegionLoad (1)
- [−] interface AccessControlConstants (3)
- ServerLoad returns long instead of int 1
- [−] ServerLoad.getNumberOfRequests ( ) : int 1
- [−] ServerLoad.getReadRequestsCount ( ) : int 1
- [−] ServerLoad.getTotalNumberOfRequests ( ) : int 1
- [−]ServerLoad.getWriteRequestsCount ( ) : int 1
- [−]class HConstants (6)
- [−]interface Cell 5
- 203.2.17. Region scanner changes:
- 203.2.18. StoreFile changes:
- 203.2.19. Mapreduce changes:
- 203.2.20. ClusterStatus changes:
- 203.2.21. Purge of PBs from API
- 203.2.22. REST changes:
- 203.2.23. PrettyPrinter changes:
- 203.2.24. AccessControlClient changes:
Appendix A: Contributing to Documentation
The Apache HBase project welcomes contributions to all aspects of the project, including the documentation.
In HBase, documentation includes the following areas, and probably some others:
The HBase Reference Guide (this book)
The HBase website
API documentation
Command-line utility output and help text
Web UI strings, explicit help text, context-sensitive strings, and others
Log messages
Comments in source files, configuration files, and others
Localization of any of the above into target languages other than English
No matter which area you want to help out with, the first step is almost always to download (typically by cloning the Git repository) and familiarize yourself with the HBase source code. For information on downloading and building the source, see developer.
A.1. Contributing to Documentation or Other Strings
If you spot an error in a string in a UI, utility, script, log message, or elsewhere, or you think something could be made more clear, or you think text needs to be added where it doesn’t currently exist, the first step is to file a JIRA. Be sure to set the component to Documentation in addition to any other involved components. Most components have one or more default owners, who monitor new issues which come into those queues. Regardless of whether you feel able to fix the bug, you should still file bugs where you see them.
If you want to try your hand at fixing your newly-filed bug, assign it to yourself. You will need to clone the HBase Git repository to your local system and work on the issue there. When you have developed a potential fix, submit it for review. If it addresses the issue and is seen as an improvement, one of the HBase committers will commit it to one or more branches, as appropriate.
Procedure: Suggested Work flow for Submitting Patches
This procedure goes into more detail than Git pros will need, but is included in this appendix so that people unfamiliar with Git can feel confident contributing to HBase while they learn.
If you have not already done so, clone the Git repository locally. You only need to do this once.
Fairly often, pull remote changes into your local repository by using the
git pullcommand, while your tracking branch is checked out.For each issue you work on, create a new branch. One convention that works well for naming the branches is to name a given branch the same as the JIRA it relates to:
$ git checkout -b HBASE-123456
Make your suggested changes on your branch, committing your changes to your local repository often. If you need to switch to working on a different issue, remember to check out the appropriate branch.
When you are ready to submit your patch, first be sure that HBase builds cleanly and behaves as expected in your modified branch.
If you have made documentation changes, be sure the documentation and website builds by running
mvn clean site.If it takes you several days or weeks to implement your fix, or you know that the area of the code you are working in has had a lot of changes lately, make sure you rebase your branch against the remote master and take care of any conflicts before submitting your patch.
$ git checkout HBASE-123456$ git rebase origin/master
- Generate your patch against the remote master. Run the following command from the top level of your git repository (usually called
hbase):$ git format-patch --stdout origin/master > HBASE-123456.patch
The name of the patch should contain the JIRA ID.
Look over the patch file to be sure that you did not change any additional files by accident and that there are no other surprises.
When you are satisfied, attach the patch to the JIRA and click the Patch Available button. A reviewer will review your patch.
If you need to submit a new version of the patch, leave the old one on the JIRA and add a version number to the name of the new patch.
After a change has been committed, there is no need to keep your local branch around.
A.2. Editing the HBase Website
The source for the HBase website is in the HBase source, in the src/site/ directory. Within this directory, source for the individual pages is in the xdocs/ directory, and images referenced in those pages are in the resources/https://hbase.apache.org/images/ directory. This directory also stores images used in the HBase Reference Guide.
The website’s pages are written in an HTML-like XML dialect called xdoc, which has a reference guide at https://maven.apache.org/archives/maven-1.x/plugins/xdoc/reference/xdocs.html. You can edit these files in a plain-text editor, an IDE, or an XML editor such as XML Mind XML Editor (XXE) or Oxygen XML Author.
To preview your changes, build the website using the mvn clean site -DskipTests command. The HTML output resides in the target/site/ directory. When you are satisfied with your changes, follow the procedure in submit doc patch procedure to submit your patch.
A.3. Publishing the HBase Website and Documentation
HBase uses the ASF’s gitpubsub mechanism. A Jenkins job runs the dev-support/jenkins-scripts/generate-hbase-website.sh script, which runs the mvn clean site site:stage against the master branch of the hbase repository and commits the built artifacts to the asf-site branch of the hbase-site repository. When the commit is pushed, the website is redeployed automatically. If the script encounters an error, an email is sent to the developer mailing list. You can run the script manually or examine it to see the steps involved.
A.4. Checking the HBase Website for Broken Links
A Jenkins job runs periodically to check HBase website for broken links, using the dev-support/jenkins-scripts/check-website-links.sh script. This script uses a tool called linklint to check for bad links and create a report. If broken links are found, an email is sent to the developer mailing list. You can run the script manually or examine it to see the steps involved.
A.5. HBase Reference Guide Style Guide and Cheat Sheet
The HBase Reference Guide is written in Asciidoc and built using AsciiDoctor. The following cheat sheet is included for your reference. More nuanced and comprehensive documentation is available at http://asciidoctor.org/docs/user-manual/.
| Element Type | Desired Rendering | How to do it |
|---|---|---|
| A paragraph | a paragraph |
Just type some text with a blank line at the top and bottom.
|
| Add line breaks within a paragraph without adding blank lines | Manual line breaks |
This will break + at the plus sign. Or prefix the whole paragraph with a line containing ‘[%hardbreaks]’
|
| Give a title to anything | Colored italic bold differently-sized text | |
| In-Line Code or commands | monospace |
text
|
| In-line literal content (things to be typed exactly as shown) | bold mono |
typethis
|
| In-line replaceable content (things to substitute with your own values) | bold italic mono |
typesomething
|
| Code blocks with highlighting | monospace, highlighted, preserve space |
[source,java]----myAwesomeCode() {}----
|
| Code block included from a separate file | included just as though it were part of the main file |
[source,ruby]----include\::path/to/app.rb[]----
|
| Include only part of a separate file | Similar to Javadoc |
See http://asciidoctor.org/docs/user-manual/#by-tagged-regions
|
| Filenames, directory names, new terms | italic |
hbase-default.xml
|
| External naked URLs | A link with the URL as link text |
link:http://www.google.com
|
| External URLs with text | A link with arbitrary link text |
link:http://www.google.com[Google]
|
| Create an internal anchor to cross-reference | not rendered |
[[anchor_name]]
|
| Cross-reference an existing anchor using its default title | an internal hyperlink using the element title if available, otherwise using the anchor name |
<<anchor_name>>
|
| Cross-reference an existing anchor using custom text | an internal hyperlink using arbitrary text |
<<anchor_name,Anchor Text>>
|
| A block image | The image with alt text |
image::sunset.jpg[Alt Text]
(put the image in the src/site/resources/images directory)
|
| An inline image | The image with alt text, as part of the text flow |
image:sunset.jpg [Alt Text]
(only one colon)
|
| Link to a remote image | show an image hosted elsewhere |
image::http://inkscape.org/doc/examples/tux.svg[Tux,250,350]
(or image:)
|
| Add dimensions or a URL to the image | depends |
inside the brackets after the alt text, specify width, height and/or link=”http://my_link.com“
|
| A footnote | subscript link which takes you to the footnote |
Some text.footnote:[The footnote text.]
|
| A note or warning with no title | The admonition image followed by the admonition |
NOTE:My note here
WARNING:My warning here
|
| A complex note | The note has a title and/or multiple paragraphs and/or code blocks or lists, etc |
.The Title[NOTE]====Here is the note text. Everything until the second set of four equals signs is part of the note.----some source code----====
|
| Bullet lists | bullet lists |
* list item 1
(see http://asciidoctor.org/docs/user-manual/#unordered-lists)
|
| Numbered lists | numbered list |
. list item 2
(see http://asciidoctor.org/docs/user-manual/#ordered-lists)
|
| Checklists | Checked or unchecked boxes |
Checked:
- [*]
Unchecked:
- [ ]
|
| Multiple levels of lists | bulleted or numbered or combo |
. Numbered (1), at top level* Bullet (2), nested under 1* Bullet (3), nested under 1. Numbered (4), at top level* Bullet (5), nested under 4** Bullet (6), nested under 5- [x] Checked (7), at top level
|
| Labelled lists / variablelists | a list item title or summary followed by content |
Title:: contentTitle::content
|
| Sidebars, quotes, or other blocks of text | a block of text, formatted differently from the default |
Delimited using different delimiters, see http://asciidoctor.org/docs/user-manual/#built-in-blocks-summary. Some of the examples above use delimiters like …., ——,====.
[example]====This is an example block.====[source]----This is a source block.----[note]====This is a note block.====[quote]____This is a quote block.____
If you want to insert literal Asciidoc content that keeps being interpreted, when in doubt, use eight dots as the delimiter at the top and bottom.
|
| Nested Sections | chapter, section, sub-section, etc |
= Book (or chapter if the chapter can be built alone, see the leveloffset info below)== Chapter (or section if the chapter is standalone)=== Section (or subsection, etc)==== Subsection
and so on up to 6 levels (think carefully about going deeper than 4 levels, maybe you can just titled paragraphs or lists instead). Note that you can include a book inside another book by adding the :leveloffset:+1 macro directive directly before your include, and resetting it to 0 directly after. See the book.adoc source for examples, as this is how this guide handles chapters. Don’t do it for prefaces, glossaries, appendixes, or other special types of chapters.
|
| Include one file from another | Content is included as though it were inline |
include::[/path/to/file.adoc]
For plenty of examples. see book.adoc.
|
| A table | a table |
See http://asciidoctor.org/docs/user-manual/#tables. Generally rows are separated by newlines and columns by pipes
|
| Comment out a single line | A line is skipped during rendering |
// This line won’t show up
|
| Comment out a block | A section of the file is skipped during rendering |
////Nothing between the slashes will show up.////
|
| Highlight text for review | text shows up with yellow background |
Test between #hash marks# is highlighted yellow.
|
A.6. Auto-Generated Content
Some parts of the HBase Reference Guide, most notably config.files, are generated automatically, so that this area of the documentation stays in sync with the code. This is done by means of an XSLT transform, which you can examine in the source at src/main/xslt/configuration_to_asciidoc_chapter.xsl. This transforms the hbase-common/src/main/resources/hbase-default.xml file into an Asciidoc output which can be included in the Reference Guide.
Sometimes, it is necessary to add configuration parameters or modify their descriptions. Make the modifications to the source file, and they will be included in the Reference Guide when it is rebuilt.
It is possible that other types of content can and will be automatically generated from HBase source files in the future.
A.7. Images in the HBase Reference Guide
You can include images in the HBase Reference Guide. It is important to include an image title if possible, and alternate text always. This allows screen readers to navigate to the image and also provides alternative text for the image. The following is an example of an image with a title and alternate text. Notice the double colon.
.My Image Titleimage::sunset.jpg[Alt Text]
Here is an example of an inline image with alternate text. Notice the single colon. Inline images cannot have titles. They are generally small images like GUI buttons.
image:sunset.jpg[Alt Text]
When doing a local build, save the image to the src/site/resources/https://hbase.apache.org/images/ directory. When you link to the image, do not include the directory portion of the path. The image will be copied to the appropriate target location during the build of the output.
When you submit a patch which includes adding an image to the HBase Reference Guide, attach the image to the JIRA. If the committer asks where the image should be committed, it should go into the above directory.
A.8. Adding a New Chapter to the HBase Reference Guide
If you want to add a new chapter to the HBase Reference Guide, the easiest way is to copy an existing chapter file, rename it, and change the ID (in double brackets) and title. Chapters are located in the src/main/asciidoc/_chapters/ directory.
Delete the existing content and create the new content. Then open the src/main/asciidoc/book.adoc file, which is the main file for the HBase Reference Guide, and copy an existing include element to include your new chapter in the appropriate location. Be sure to add your new file to your Git repository before creating your patch.
When in doubt, check to see how other files have been included.
A.9. Common Documentation Issues
The following documentation issues come up often. Some of these are preferences, but others can create mysterious build errors or other problems.
Isolate Changes for Easy Diff Review.
Be careful with pretty-printing or re-formatting an entire XML file, even if the formatting has degraded over time. If you need to reformat a file, do that in a separate JIRA where you do not change any content. Be careful because some XML editors do a bulk-reformat when you open a new file, especially if you use GUI mode in the editor.Syntax Highlighting
The HBase Reference Guide usescoderayfor syntax highlighting. To enable syntax highlighting for a given code listing, use the following type of syntax: ``` [source,xml]
My Name
<br />Several syntax types are supported. The most interesting ones for the HBase Reference Guide are `java`, `xml`, `sql`, and `bash`.<a name="20c6731e"></a>## Appendix B: FAQ<a name="2f738f8b"></a>### B.1. GeneralWhen should I use HBase?See [Overview](docs_en_#arch.overview) in the Architecture chapter.Are there other HBase FAQs?See the FAQ that is up on the wiki, [HBase Wiki FAQ](https://wiki.apache.org/hadoop/Hbase/FAQ).Does HBase support SQL?Not really. SQL-ish support for HBase via [Hive](https://hive.apache.org/) is in development, however Hive is based on MapReduce which is not generally suitable for low-latency requests. See the [Data Model](docs_en_#datamodel) section for examples on the HBase client.How can I find examples of NoSQL/HBase?See the link to the BigTable paper in [Other Information About HBase](docs_en_#other.info), as well as the other papers.What is the history of HBase?See [hbase.history](docs_en_#hbase.history).Why are the cells above 10MB not recommended for HBase?Large cells don’t fit well into HBase’s approach to buffering data. First, the large cells bypass the MemStoreLAB when they are written. Then, they cannot be cached in the L2 block cache during read operations. Instead, HBase has to allocate on-heap memory for them each time. This can have a significant impact on the garbage collector within the RegionServer process.<a name="28f671a2"></a>### B.2. UpgradingHow do I upgrade Maven-managed projects from HBase 0.94 to HBase 0.96+?In HBase 0.96, the project moved to a modular structure. Adjust your project’s dependencies to rely upon the `hbase-client` module or another module as appropriate, rather than a single JAR. You can model your Maven dependency after one of the following, depending on your targeted version of HBase. See Section 3.5, “Upgrading from 0.94.x to 0.96.x” or Section 3.3, “Upgrading from 0.96.x to 0.98.x” for more information.Maven Dependency for HBase 0.98
Maven Dependency for HBase 0.96
Maven Dependency for HBase 0.94
<a name="c16b48e3"></a>### B.3. ArchitectureHow does HBase handle Region-RegionServer assignment and locality?See [Regions](docs_en_#regions.arch).<a name="ee8e6fd1"></a>### B.4. ConfigurationHow can I get started with my first cluster?See [Quick Start - Standalone HBase](docs_en_#quickstart).Where can I learn about the rest of the configuration options?See [Apache HBase Configuration](docs_en_#configuration).<a name="a32e8874"></a>### B.5. Schema Design / Data AccessHow should I design my schema in HBase?See [Data Model](docs_en_#datamodel) and [HBase and Schema Design](docs_en_#schema).How can I store (fill in the blank) in HBase?See [Supported Datatypes](docs_en_#supported.datatypes).How can I handle secondary indexes in HBase?See [Secondary Indexes and Alternate Query Paths](docs_en_#secondary.indexes).Can I change a table’s rowkeys?This is a very common question. You can’t. See [Immutability of Rowkeys](docs_en_#changing.rowkeys).What APIs does HBase support?See [Data Model](docs_en_#datamodel), [Client](docs_en_#architecture.client), and [Apache HBase External APIs](docs_en_#external_apis).<a name="c2216059"></a>### B.6. MapReduceHow can I use MapReduce with HBase?See [HBase and MapReduce](docs_en_#mapreduce).<a name="90592d13"></a>### B.7. Performance and TroubleshootingHow can I improve HBase cluster performance?See [Apache HBase Performance Tuning](docs_en_#performance).How can I troubleshoot my HBase cluster?See [Troubleshooting and Debugging Apache HBase](docs_en_#trouble).<a name="ed174166"></a>### B.8. Amazon EC2I am running HBase on Amazon EC2 and…EC2 issues are a special case. See [Amazon EC2](docs_en_#trouble.ec2) and [Amazon EC2](docs_en_#perf.ec2).<a name="a52ec572"></a>### B.9. OperationsHow do I manage my HBase cluster?See [Apache HBase Operational Management](docs_en_#ops_mgt).How do I back up my HBase cluster?See [HBase Backup](docs_en_#ops.backup).<a name="265e33a9"></a>### B.10. HBase in ActionWhere can I find interesting videos and presentations on HBase?See [Other Information About HBase](docs_en_#other.info).<a name="dba4648d"></a>## Appendix C: Access Control MatrixThe following matrix shows the permission set required to perform operations in HBase. Before using the table, read through the information about how to interpret it.Interpreting the ACL Matrix TableThe following conventions are used in the ACL Matrix table:<a name="093733a9"></a>### C.1. ScopesPermissions are evaluated starting at the widest scope and working to the narrowest scope.A scope corresponds to a level of the data model. From broadest to narrowest, the scopes are as follows:Scopes-Global-Namespace (NS)-Table-Column Family (CF)-Column Qualifier (CQ)-CellFor instance, a permission granted at table level dominates any grants done at the Column Family, Column Qualifier, or cell level. The user can do what that grant implies at any location in the table. A permission granted at global scope dominates all: the user is always allowed to take that action everywhere.<a name="6fdc9b7f"></a>### C.2. PermissionsPossible permissions include the following:Permissions-Superuser - a special user that belongs to group "supergroup" and has unlimited access-Admin (A)-Create (C)-Write (W)-Read (R)-Execute (X)For the most part, permissions work in an expected way, with the following caveats:Having Write permission does not imply Read permission.It is possible and sometimes desirable for a user to be able to write data that same user cannot read. One such example is a log-writing process.The hbase:meta table is readable by every user, regardless of the user’s other grants or restrictions.This is a requirement for HBase to function correctly.`CheckAndPut` and `CheckAndDelete` operations will fail if the user does not have both Write and Read permission.`Increment` and `Append` operations do not require Read access.The `superuser`, as the name suggests has permissions to perform all possible operations.And for the operations marked with *, the checks are done in post hook and only subset of results satisfying access checks are returned back to the user.The following table is sorted by the interface that provides each operation. In case the table goes out of date, the unit tests which check for accuracy of permissions can be found in _hbase-server/src/test/java/org/apache/hadoop/hbase/security/access/TestAccessController.java_, and the access controls themselves can be examined in _hbase-server/src/main/java/org/apache/hadoop/hbase/security/access/AccessController.java_.| Interface | Operation | Permissions || --- | --- | --- || Master | createTable | superuser|global(C)|NS(C) || | modifyTable | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) || | deleteTable | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) || | truncateTable | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) || | addColumn | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) || | modifyColumn | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C)|column(A)|column(C) || | deleteColumn | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C)|column(A)|column(C) || | enableTable | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) || | disableTable | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) || | disableAclTable | Not allowed || | move | superuser|global(A)|NS(A)|TableOwner|table(A) || | assign | superuser|global(A)|NS(A)|TableOwner|table(A) || | unassign | superuser|global(A)|NS(A)|TableOwner|table(A) || | regionOffline | superuser|global(A)|NS(A)|TableOwner|table(A) || | balance | superuser|global(A) || | balanceSwitch | superuser|global(A) || | shutdown | superuser|global(A) || | stopMaster | superuser|global(A) || | snapshot | superuser|global(A)|NS(A)|TableOwner|table(A) || | listSnapshot | superuser|global(A)|SnapshotOwner || | cloneSnapshot | superuser|global(A)|(SnapshotOwner & TableName matches) || | restoreSnapshot | superuser|global(A)|SnapshotOwner & (NS(A)|TableOwner|table(A)) || | deleteSnapshot | superuser|global(A)|SnapshotOwner || | createNamespace | superuser|global(A) || | deleteNamespace | superuser|global(A) || | modifyNamespace | superuser|global(A) || | getNamespaceDescriptor | superuser|global(A)|NS(A) || | listNamespaceDescriptors* | superuser|global(A)|NS(A) || | flushTable | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) || | getTableDescriptors* | superuser|global(A)|global(C)|NS(A)|NS(C)|TableOwner|table(A)|table(C) || | getTableNames* | superuser|TableOwner|Any global or table perm || | setUserQuota(global level) | superuser|global(A) || | setUserQuota(namespace level) | superuser|global(A) || | setUserQuota(Table level) | superuser|global(A)|NS(A)|TableOwner|table(A) || | setTableQuota | superuser|global(A)|NS(A)|TableOwner|table(A) || | setNamespaceQuota | superuser|global(A) || | addReplicationPeer | superuser|global(A) || | removeReplicationPeer | superuser|global(A) || | enableReplicationPeer | superuser|global(A) || | disableReplicationPeer | superuser|global(A) || | getReplicationPeerConfig | superuser|global(A) || | updateReplicationPeerConfig | superuser|global(A) || | listReplicationPeers | superuser|global(A) || | getClusterStatus | any user || Region | openRegion | superuser|global(A) || | closeRegion | superuser|global(A) || | flush | superuser|global(A)|global(C)|TableOwner|table(A)|table(C) || | split | superuser|global(A)|TableOwner|TableOwner|table(A) || | compact | superuser|global(A)|global(C)|TableOwner|table(A)|table(C) || | getClosestRowBefore | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) || | getOp | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) || | exists | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) || | put | superuser|global(W)|NS(W)|table(W)|TableOwner|CF(W)|CQ(W) || | delete | superuser|global(W)|NS(W)|table(W)|TableOwner|CF(W)|CQ(W) || | batchMutate | superuser|global(W)|NS(W)|TableOwner|table(W)|CF(W)|CQ(W) || | checkAndPut | superuser|global(RW)|NS(RW)|TableOwner|table(RW)|CF(RW)|CQ(RW) || | checkAndPutAfterRowLock | superuser|global(R)|NS(R)|TableOwner|Table(R)|CF(R)|CQ(R) || | checkAndDelete | superuser|global(RW)|NS(RW)|TableOwner|table(RW)|CF(RW)|CQ(RW) || | checkAndDeleteAfterRowLock | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) || | incrementColumnValue | superuser|global(W)|NS(W)|TableOwner|table(W)|CF(W)|CQ(W) || | append | superuser|global(W)|NS(W)|TableOwner|table(W)|CF(W)|CQ(W) || | appendAfterRowLock | superuser|global(W)|NS(W)|TableOwner|table(W)|CF(W)|CQ(W) || | increment | superuser|global(W)|NS(W)|TableOwner|table(W)|CF(W)|CQ(W) || | incrementAfterRowLock | superuser|global(W)|NS(W)|TableOwner|table(W)|CF(W)|CQ(W) || | scannerOpen | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) || | scannerNext | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) || | scannerClose | superuser|global(R)|NS(R)|TableOwner|table(R)|CF(R)|CQ(R) || | bulkLoadHFile | superuser|global(C)|TableOwner|table(C)|CF(C) || | prepareBulkLoad | superuser|global(C)|TableOwner|table(C)|CF(C) || | cleanupBulkLoad | superuser|global(C)|TableOwner|table(C)|CF(C) || Endpoint | invoke | superuser|global(X)|NS(X)|TableOwner|table(X) || AccessController | grant(global level) | global(A) || | grant(namespace level) | global(A)|NS(A) || | grant(table level) | global(A)|NS(A)|TableOwner|table(A)|CF(A)|CQ(A) || | revoke(global level) | global(A) || | revoke(namespace level) | global(A)|NS(A) || | revoke(table level) | global(A)|NS(A)|TableOwner|table(A)|CF(A)|CQ(A) || | getUserPermissions(global level) | global(A) || | getUserPermissions(namespace level) | global(A)|NS(A) || | getUserPermissions(table level) | global(A)|NS(A)|TableOwner|table(A)|CF(A)|CQ(A) || | hasPermission(table level) | global(A)|SelfUserCheck || RegionServer | stopRegionServer | superuser|global(A) || | mergeRegions | superuser|global(A) || | rollWALWriterRequest | superuser|global(A) || | replicateLogEntries | superuser|global(W) || RSGroup | addRSGroup | superuser|global(A) || | balanceRSGroup | superuser|global(A) || | getRSGroupInfo | superuser|global(A) || | getRSGroupInfoOfTable | superuser|global(A) || | getRSGroupOfServer | superuser|global(A) || | listRSGroups | superuser|global(A) || | moveServers | superuser|global(A) || | moveServersAndTables | superuser|global(A) || | moveTables | superuser|global(A) || | removeRSGroup | superuser|global(A) || > removeServers | superuser|global(A) | |<a name="244e543f"></a>## Appendix D: Compression and Data Block Encoding In HBase> Codecs mentioned in this section are for encoding and decoding data blocks or row keys. For information about replication codecs, see [cluster.replication.preserving.tags](docs_en_#cluster.replication.preserving.tags).Some of the information in this section is pulled from a [discussion](http://search-hadoop.com/m/lL12B1PFVhp1/v=threaded) on the HBase Development mailing list.HBase supports several different compression algorithms which can be enabled on a ColumnFamily. Data block encoding attempts to limit duplication of information in keys, taking advantage of some of the fundamental designs and patterns of HBase, such as sorted row keys and the schema of a given table. Compressors reduce the size of large, opaque byte arrays in cells, and can significantly reduce the storage space needed to store uncompressed data.Compressors and data block encoding can be used together on the same ColumnFamily.Changes Take Effect Upon CompactionIf you change compression or encoding for a ColumnFamily, the changes take effect during compaction.Some codecs take advantage of capabilities built into Java, such as GZip compression. Others rely on native libraries. Native libraries may be available as part of Hadoop, such as LZ4. In this case, HBase only needs access to the appropriate shared library.Other codecs, such as Google Snappy, need to be installed first. Some codecs are licensed in ways that conflict with HBase’s license and cannot be shipped as part of HBase.This section discusses common codecs that are used and tested with HBase. No matter what codec you use, be sure to test that it is installed correctly and is available on all nodes in your cluster. Extra operational steps may be necessary to be sure that codecs are available on newly-deployed nodes. You can use the [compression.test](docs_en_#compression.test) utility to check that a given codec is correctly installed.To configure HBase to use a compressor, see [compressor.install](docs_en_#compressor.install). To enable a compressor for a ColumnFamily, see [changing.compression](docs_en_#changing.compression). To enable data block encoding for a ColumnFamily, see [data.block.encoding.enable](docs_en_#data.block.encoding.enable).Block Compressors-none-Snappy-LZO-LZ4-GZData Block Encoding TypesPrefixOften, keys are very similar. Specifically, keys often share a common prefix and only differ near the end. For instance, one key might be `RowKey:Family:Qualifier0` and the next key might be `RowKey:Family:Qualifier1`.<br />In Prefix encoding, an extra column is added which holds the length of the prefix shared between the current key and the previous key. Assuming the first key here is totally different from the key before, its prefix length is 0.The second key’s prefix length is `23`, since they have the first 23 characters in common.Obviously if the keys tend to have nothing in common, Prefix will not provide much benefit.The following image shows a hypothetical ColumnFamily with no data block encoding.Figure 18. ColumnFamily with No EncodingHere is the same data with prefix data encoding.Figure 19. ColumnFamily with Prefix EncodingDiffDiff encoding expands upon Prefix encoding. Instead of considering the key sequentially as a monolithic series of bytes, each key field is split so that each part of the key can be compressed more efficiently.Two new fields are added: timestamp and type.If the ColumnFamily is the same as the previous row, it is omitted from the current row.If the key length, value length or type are the same as the previous row, the field is omitted.In addition, for increased compression, the timestamp is stored as a Diff from the previous row’s timestamp, rather than being stored in full. Given the two row keys in the Prefix example, and given an exact match on timestamp and the same type, neither the value length, or type needs to be stored for the second row, and the timestamp value for the second row is just 0, rather than a full timestamp.Diff encoding is disabled by default because writing and scanning are slower but more data is cached.This image shows the same ColumnFamily from the previous images, with Diff encoding.Figure 20. ColumnFamily with Diff EncodingFast DiffFast Diff works similar to Diff, but uses a faster implementation. It also adds another field which stores a single bit to track whether the data itself is the same as the previous row. If it is, the data is not stored again.Fast Diff is the recommended codec to use if you have long keys or many columns.The data format is nearly identical to Diff encoding, so there is not an image to illustrate it.Prefix TreePrefix tree encoding was introduced as an experimental feature in HBase 0.96. It provides similar memory savings to the Prefix, Diff, and Fast Diff encoder, but provides faster random access at a cost of slower encoding speed. It was removed in hbase-2.0.0. It was a good idea but little uptake. If interested in reviving this effort, write the hbase dev list.<a name="2adf4673"></a>### D.1. Which Compressor or Data Block Encoder To UseThe compression or codec type to use depends on the characteristics of your data. Choosing the wrong type could cause your data to take more space rather than less, and can have performance implications.In general, you need to weigh your options between smaller size and faster compression/decompression. Following are some general guidelines, expanded from a discussion at [Documenting Guidance on compression and codecs](http://search-hadoop.com/m/lL12B1PFVhp1).-If you have long keys (compared to the values) or many columns, use a prefix encoder. FAST_DIFF is recommended.-If the values are large (and not precompressed, such as images), use a data block compressor.-Use GZIP for _cold data_, which is accessed infrequently. GZIP compression uses more CPU resources than Snappy or LZO, but provides a higher compression ratio.-Use Snappy or LZO for _hot data_, which is accessed frequently. Snappy and LZO use fewer CPU resources than GZIP, but do not provide as high of a compression ratio.-In most cases, enabling Snappy or LZO by default is a good choice, because they have a low performance overhead and provide space savings.-Before Snappy became available by Google in 2011, LZO was the default. Snappy has similar qualities as LZO but has been shown to perform better.<a name="c8bcb98a"></a>### D.2. Making use of Hadoop Native Libraries in HBaseThe Hadoop shared library has a bunch of facility including compression libraries and fast crc’ing — hardware crc’ing if your chipset supports it. To make this facility available to HBase, do the following. HBase/Hadoop will fall back to use alternatives if it cannot find the native library versions — or fail outright if you asking for an explicit compressor and there is no alternative available.First make sure of your Hadoop. Fix this message if you are seeing it starting Hadoop processes:
16/02/09 22:40:24 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
It means is not properly pointing at its native libraries or the native libs were compiled for another platform. Fix this first.Then if you see the following in your HBase logs, you know that HBase was unable to locate the Hadoop native libraries:
2014-08-07 09:26:20,139 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
If the libraries loaded successfully, the WARN message does not show. Usually this means you are good to go but read on.Let’s presume your Hadoop shipped with a native library that suits the platform you are running HBase on. To check if the Hadoop native library is available to HBase, run the following tool (available in Hadoop 2.1 and greater):
$ ./bin/hbase —config ~/conf_hbase org.apache.hadoop.util.NativeLibraryChecker 2014-08-26 13:15:38,717 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable Native library checking: hadoop: false zlib: false snappy: false lz4: false bzip2: false 2014-08-26 13:15:38,863 INFO [main] util.ExitUtil: Exiting with status 1
Above shows that the native hadoop library is not available in HBase context.The above NativeLibraryChecker tool may come back saying all is hunky-dory — i.e. all libs show 'true', that they are available — but follow the below presecription anyways to ensure the native libs are available in HBase context, when it goes to use them.To fix the above, either copy the Hadoop native libraries local or symlink to them if the Hadoop and HBase stalls are adjacent in the filesystem. You could also point at their location by setting the `LD_LIBRARY_PATH` environment variable in your hbase-env.sh.Where the JVM looks to find native libraries is "system dependent" (See `java.lang.System#loadLibrary(name)`). On linux, by default, is going to look in _lib/native/PLATFORM_ where `PLATFORM` is the label for the platform your HBase is installed on. On a local linux machine, it seems to be the concatenation of the java properties `os.name` and `os.arch` followed by whether 32 or 64 bit. HBase on startup prints out all of the java system properties so find the os.name and os.arch in the log. For example:
… 2014-08-06 15:27:22,853 INFO [main] zookeeper.ZooKeeper: Client environment:os.name=Linux 2014-08-06 15:27:22,853 INFO [main] zookeeper.ZooKeeper: Client environment:os.arch=amd64 …
So in this case, the PLATFORM string is `Linux-amd64-64`. Copying the Hadoop native libraries or symlinking at _lib/native/Linux-amd64-64_ will ensure they are found. Rolling restart after you have made this change.Here is an example of how you would set up the symlinks. Let the hadoop and hbase installs be in your home directory. Assume your hadoop native libs are at ~/hadoop/lib/native. Assume you are on a Linux-amd64-64 platform. In this case, you would do the following to link the hadoop native lib so hbase could find them.
… $ mkdir -p ~/hbaseLinux-amd64-64 -> /home/stack/hadoop/lib/native/lib/native/ $ cd ~/hbase/lib/native/ $ ln -s ~/hadoop/lib/native Linux-amd64-64 $ ls -la
Linux-amd64-64 -> /home/USER/hadoop/lib/native
…
If you see PureJavaCrc32C in a stack track or if you see something like the below in a perf trace, then native is not working; you are using the java CRC functions rather than native:
5.02% perf-53601.map [.] Lorg/apache/hadoop/util/PureJavaCrc32C;.update
See [HBASE-11927 Use Native Hadoop Library for HFile checksum (And flip default from CRC32 to CRC32C)](https://issues.apache.org/jira/browse/HBASE-11927), for more on native checksumming support. See in particular the release note for how to check if your hardware to see if your processor has support for hardware CRCs. Or checkout the Apache [Checksums in HBase](https://blogs.apache.org/hbase/entry/saving_cpu_using_native_hadoop) blog post.Here is example of how to point at the Hadoop libs with `LD_LIBRARY_PATH` environment variable:
$ LD_LIBRARY_PATH=~/hadoop-2.5.0-SNAPSHOT/lib/native ./bin/hbase —config ~/conf_hbase org.apache.hadoop.util.NativeLibraryChecker 2014-08-26 13:42:49,332 INFO [main] bzip2.Bzip2Factory: Successfully loaded & initialized native-bzip2 library system-native 2014-08-26 13:42:49,337 INFO [main] zlib.ZlibFactory: Successfully loaded & initialized native-zlib library Native library checking: hadoop: true /home/stack/hadoop-2.5.0-SNAPSHOT/lib/native/libhadoop.so.1.0.0 zlib: true /lib64/libz.so.1 snappy: true /usr/lib64/libsnappy.so.1 lz4: true revision:99 bzip2: true /lib64/libbz2.so.1
Set in _hbase-env.sh_ the LD_LIBRARY_PATH environment variable when starting your HBase.<a name="ac9b7b60"></a>### D.3. Compressor Configuration, Installation, and Use<a name="a91a12c9"></a>#### D.3.1. Configure HBase For CompressorsBefore HBase can use a given compressor, its libraries need to be available. Due to licensing issues, only GZ compression is available to HBase (via native Java libraries) in a default installation. Other compression libraries are available via the shared library bundled with your hadoop. The hadoop native library needs to be findable when HBase starts. SeeCompressor Support On the MasterA new configuration setting was introduced in HBase 0.95, to check the Master to determine which data block encoders are installed and configured on it, and assume that the entire cluster is configured the same. This option, `hbase.master.check.compression`, defaults to `true`. This prevents the situation described in [HBASE-6370](https://issues.apache.org/jira/browse/HBASE-6370), where a table is created or modified to support a codec that a region server does not support, leading to failures that take a long time to occur and are difficult to debug.If `hbase.master.check.compression` is enabled, libraries for all desired compressors need to be installed and configured on the Master, even if the Master does not run a region server.Install GZ Support Via Native LibrariesHBase uses Java’s built-in GZip support unless the native Hadoop libraries are available on the CLASSPATH. The recommended way to add libraries to the CLASSPATH is to set the environment variable `HBASE_LIBRARY_PATH` for the user running HBase. If native libraries are not available and Java’s GZIP is used, `Got brand-new compressor` reports will be present in the logs. See [brand.new.compressor](docs_en_#brand.new.compressor)).Install LZO SupportHBase cannot ship with LZO because of incompatibility between HBase, which uses an Apache Software License (ASL) and LZO, which uses a GPL license. See the [Hadoop-LZO at Twitter](https://github.com/twitter/hadoop-lzo/blob/master/README.md) for information on configuring LZO support for HBase.If you depend upon LZO compression, consider configuring your RegionServers to fail to start if LZO is not available. See [hbase.regionserver.codecs](docs_en_#hbase.regionserver.codecs).Configure LZ4 SupportLZ4 support is bundled with Hadoop. Make sure the hadoop shared library (libhadoop.so) is accessible when you start HBase. After configuring your platform (see [hadoop.native.lib](docs_en_#hadoop.native.lib)), you can make a symbolic link from HBase to the native Hadoop libraries. This assumes the two software installs are colocated. For example, if my 'platform' is Linux-amd64-64:
$ cd $HBASE_HOME $ mkdir lib/native $ ln -s $HADOOP_HOME/lib/native lib/native/Linux-amd64-64
Use the compression tool to check that LZ4 is installed on all nodes. Start up (or restart) HBase. Afterward, you can create and alter tables to enable LZ4 as a compression codec.:
hbase(main):003:0> alter ‘TestTable’, {NAME => ‘info’, COMPRESSION => ‘LZ4’}
Install Snappy SupportHBase does not ship with Snappy support because of licensing issues. You can install Snappy binaries (for instance, by using yum install snappy on CentOS) or build Snappy from source. After installing Snappy, search for the shared library, which will be called _libsnappy.so.X_ where X is a number. If you built from source, copy the shared library to a known location on your system, such as _/opt/snappy/lib/_.In addition to the Snappy library, HBase also needs access to the Hadoop shared library, which will be called something like _libhadoop.so.X.Y_, where X and Y are both numbers. Make note of the location of the Hadoop library, or copy it to the same location as the Snappy library.| |The Snappy and Hadoop libraries need to be available on each node of your cluster. See [compression.test](docs_en_#compression.test) to find out how to test that this is the case.See [hbase.regionserver.codecs](docs_en_#hbase.regionserver.codecs) to configure your RegionServers to fail to start if a given compressor is not available.|Each of these library locations need to be added to the environment variable `HBASE_LIBRARY_PATH` for the operating system user that runs HBase. You need to restart the RegionServer for the changes to take effect.CompressionTestYou can use the CompressionTest tool to verify that your compressor is available to HBase:
$ hbase org.apache.hadoop.hbase.util.CompressionTest hdfs://host/path/to/hbase snappy
Enforce Compression Settings On a RegionServerYou can configure a RegionServer so that it will fail to restart if compression is configured incorrectly, by adding the option hbase.regionserver.codecs to the _hbase-site.xml_, and setting its value to a comma-separated list of codecs that need to be available. For example, if you set this property to `lzo,gz`, the RegionServer would fail to start if both compressors were not available. This would prevent a new server from being added to the cluster without having codecs configured properly.<a name="f7a9c235"></a>#### D.3.2. Enable Compression On a ColumnFamilyTo enable compression for a ColumnFamily, use an `alter` command. You do not need to re-create the table or copy data. If you are changing codecs, be sure the old codec is still available until all the old StoreFiles have been compacted.Enabling Compression on a ColumnFamily of an Existing Table using HBaseShell
hbase> disable ‘test’ hbase> alter ‘test’, {NAME => ‘cf’, COMPRESSION => ‘GZ’} hbase> enable ‘test’
Creating a New Table with Compression On a ColumnFamily
hbase> create ‘test2’, { NAME => ‘cf2’, COMPRESSION => ‘SNAPPY’ }
Verifying a ColumnFamily’s Compression Settings
hbase> describe ‘test’ DESCRIPTION ENABLED ‘test’, {NAME => ‘cf’, DATA_BLOCK_ENCODING => ‘NONE false ‘, BLOOMFILTER => ‘ROW’, REPLICATION_SCOPE => ‘0’, VERSIONS => ‘1’, COMPRESSION => ‘GZ’, MIN_VERSIONS => ‘0’, TTL => ‘FOREVER’, KEEP_DELETED_CELLS => ‘fa lse’, BLOCKSIZE => ‘65536’, IN_MEMORY => ‘false’, B LOCKCACHE => ‘true’} 1 row(s) in 0.1070 seconds
<a name="a858cc51"></a>#### D.3.3. Testing Compression PerformanceHBase includes a tool called LoadTestTool which provides mechanisms to test your compression performance. You must specify either `-write` or `-update-read` as your first parameter, and if you do not specify another parameter, usage advice is printed for each option.LoadTestTool Usage
$ bin/hbase org.apache.hadoop.hbase.util.LoadTestTool -h
usage: bin/hbase org.apache.hadoop.hbase.util.LoadTestTool
Example Usage of LoadTestTool
$ hbase org.apache.hadoop.hbase.util.LoadTestTool -write 1:10:100 -num_keys 1000000 -read 100:30 -num_tables 1 -data_block_encoding NONE -tn load_test_tool_NONE
<a name="0acda8fb"></a>### D.4. Enable Data Block EncodingCodecs are built into HBase so no extra configuration is needed. Codecs are enabled on a table by setting the `DATA_BLOCK_ENCODING` property. Disable the table before altering its DATA_BLOCK_ENCODING setting. Following is an example using HBase Shell:Enable Data Block Encoding On a Table
hbase> disable ‘test’ hbase> alter ‘test’, { NAME => ‘cf’, DATA_BLOCK_ENCODING => ‘FAST_DIFF’ } Updating all regions with the new schema… 0/1 regions updated. 1/1 regions updated. Done. 0 row(s) in 2.2820 seconds hbase> enable ‘test’ 0 row(s) in 0.1580 seconds
Verifying a ColumnFamily’s Data Block Encoding
hbase> describe ‘test’ DESCRIPTION ENABLED ‘test’, {NAME => ‘cf’, DATA_BLOCK_ENCODING => ‘FAST true _DIFF’, BLOOMFILTER => ‘ROW’, REPLICATION_SCOPE => ‘0’, VERSIONS => ‘1’, COMPRESSION => ‘GZ’, MIN_VERS IONS => ‘0’, TTL => ‘FOREVER’, KEEP_DELETED_CELLS =
‘false’, BLOCKSIZE => ‘65536’, IN_MEMORY => ‘fals e’, BLOCKCACHE => ‘true’} 1 row(s) in 0.0650 seconds ```
Appendix E: SQL over HBase
The following projects offer some support for SQL over HBase.
E.1. Apache Phoenix
E.2. Trafodion
Trafodion: Transactional SQL-on-HBase
Appendix F: YCSB
YCSB: The Yahoo! Cloud Serving Benchmark and HBase
TODO: Describe how YCSB is poor for putting up a decent cluster load.
TODO: Describe setup of YCSB for HBase. In particular, presplit your tables before you start a run. See HBASE-4163 Create Split Strategy for YCSB Benchmark for why and a little shell command for how to do it.
Ted Dunning redid YCSB so it’s mavenized and added facility for verifying workloads. See Ted Dunning’s YCSB.
Appendix G: HFile format
This appendix describes the evolution of the HFile format.
G.1. HBase File Format (version 1)
As we will be discussing changes to the HFile format, it is useful to give a short overview of the original (HFile version 1) format.
G.1.1. Overview of Version 1
An HFile in version 1 format is structured as follows:
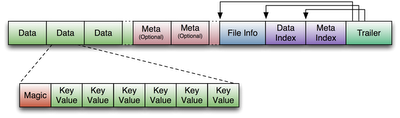 Figure 21. HFile V1 Format
Figure 21. HFile V1 Format
G.1.2. Block index format in version 1
The block index in version 1 is very straightforward. For each entry, it contains:
Offset (long)
Uncompressed size (int)
Key (a serialized byte array written using Bytes.writeByteArray)
Key length as a variable-length integer (VInt)
Key bytes
The number of entries in the block index is stored in the fixed file trailer, and has to be passed in to the method that reads the block index. One of the limitations of the block index in version 1 is that it does not provide the compressed size of a block, which turns out to be necessary for decompression. Therefore, the HFile reader has to infer this compressed size from the offset difference between blocks. We fix this limitation in version 2, where we store on-disk block size instead of uncompressed size, and get uncompressed size from the block header.
G.2. HBase file format with inline blocks (version 2)
Note: this feature was introduced in HBase 0.92
G.2.1. Motivation
We found it necessary to revise the HFile format after encountering high memory usage and slow startup times caused by large Bloom filters and block indexes in the region server. Bloom filters can get as large as 100 MB per HFile, which adds up to 2 GB when aggregated over 20 regions. Block indexes can grow as large as 6 GB in aggregate size over the same set of regions. A region is not considered opened until all of its block index data is loaded. Large Bloom filters produce a different performance problem: the first get request that requires a Bloom filter lookup will incur the latency of loading the entire Bloom filter bit array.
To speed up region server startup we break Bloom filters and block indexes into multiple blocks and write those blocks out as they fill up, which also reduces the HFile writer’s memory footprint. In the Bloom filter case, “filling up a block” means accumulating enough keys to efficiently utilize a fixed-size bit array, and in the block index case we accumulate an “index block” of the desired size. Bloom filter blocks and index blocks (we call these “inline blocks”) become interspersed with data blocks, and as a side effect we can no longer rely on the difference between block offsets to determine data block length, as it was done in version 1.
HFile is a low-level file format by design, and it should not deal with application-specific details such as Bloom filters, which are handled at StoreFile level. Therefore, we call Bloom filter blocks in an HFile “inline” blocks. We also supply HFile with an interface to write those inline blocks.
Another format modification aimed at reducing the region server startup time is to use a contiguous “load-on-open” section that has to be loaded in memory at the time an HFile is being opened. Currently, as an HFile opens, there are separate seek operations to read the trailer, data/meta indexes, and file info. To read the Bloom filter, there are two more seek operations for its “data” and “meta” portions. In version 2, we seek once to read the trailer and seek again to read everything else we need to open the file from a contiguous block.
G.2.2. Overview of Version 2
The version of HBase introducing the above features reads both version 1 and 2 HFiles, but only writes version 2 HFiles. A version 2 HFile is structured as follows:
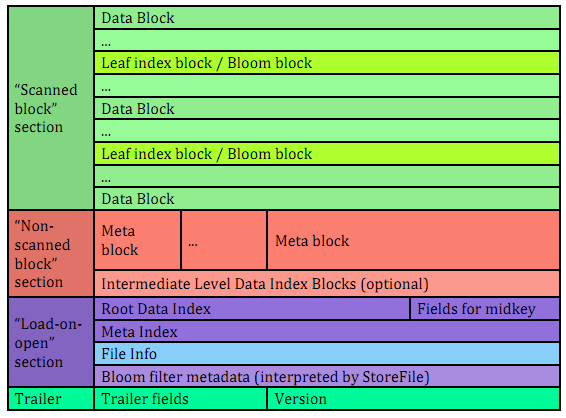 Figure 22. HFile Version 2 Structure
Figure 22. HFile Version 2 Structure
G.2.3. Unified version 2 block format
In the version 2 every block in the data section contains the following fields:
8 bytes: Block type, a sequence of bytes equivalent to version 1’s “magic records”. Supported block types are:
DATA – data blocks
LEAF_INDEX – leaf-level index blocks in a multi-level-block-index
BLOOM_CHUNK – Bloom filter chunks
META – meta blocks (not used for Bloom filters in version 2 anymore)
INTERMEDIATE_INDEX – intermediate-level index blocks in a multi-level blockindex
ROOT_INDEX – root-level index blocks in a multi-level block index
FILE_INFO – the ‘’file info’’ block, a small key-value map of metadata
BLOOM_META – a Bloom filter metadata block in the load-on-open section
TRAILER – a fixed-size file trailer. As opposed to the above, this is not an HFile v2 block but a fixed-size (for each HFile version) data structure
INDEX_V1 – this block type is only used for legacy HFile v1 block
Compressed size of the block’s data, not including the header (int).
Can be used for skipping the current data block when scanning HFile data.Uncompressed size of the block’s data, not including the header (int)
This is equal to the compressed size if the compression algorithm is NONEFile offset of the previous block of the same type (long)
Can be used for seeking to the previous data/index blockCompressed data (or uncompressed data if the compression algorithm is NONE).
The above format of blocks is used in the following HFile sections:
Scanned block section
The section is named so because it contains all data blocks that need to be read when an HFile is scanned sequentially. Also contains Leaf index blocks and Bloom chunk blocks.
Non-scanned block section
This section still contains unified-format v2 blocks but it does not have to be read when doing a sequential scan. This section contains “meta” blocks and intermediate-level index blocks.
We are supporting “meta” blocks in version 2 the same way they were supported in version 1, even though we do not store Bloom filter data in these blocks anymore.
G.2.4. Block index in version 2
There are three types of block indexes in HFile version 2, stored in two different formats (root and non-root):
Data index — version 2 multi-level block index, consisting of:
Version 2 root index, stored in the data block index section of the file
Optionally, version 2 intermediate levels, stored in the non-root format in the data index section of the file. Intermediate levels can only be present if leaf level blocks are present
Optionally, version 2 leaf levels, stored in the non-root format inline with data blocks
Meta index — version 2 root index format only, stored in the meta index section of the file
Bloom index — version 2 root index format only, stored in the ‘’load-on-open’’ section as part of Bloom filter metadata.
G.2.5. Root block index format in version 2
This format applies to:
Root level of the version 2 data index
Entire meta and Bloom indexes in version 2, which are always single-level.
A version 2 root index block is a sequence of entries of the following format, similar to entries of a version 1 block index, but storing on-disk size instead of uncompressed size.
Offset (long)
This offset may point to a data block or to a deeper-level index block.On-disk size (int)
Key (a serialized byte array stored using Bytes.writeByteArray)
Key (VInt)
Key bytes
A single-level version 2 block index consists of just a single root index block. To read a root index block of version 2, one needs to know the number of entries. For the data index and the meta index the number of entries is stored in the trailer, and for the Bloom index it is stored in the compound Bloom filter metadata.
For a multi-level block index we also store the following fields in the root index block in the load-on-open section of the HFile, in addition to the data structure described above:
Middle leaf index block offset
Middle leaf block on-disk size (meaning the leaf index block containing the reference to the ‘’middle’’ data block of the file)
The index of the mid-key (defined below) in the middle leaf-level block.
These additional fields are used to efficiently retrieve the mid-key of the HFile used in HFile splits, which we define as the first key of the block with a zero-based index of (n – 1) / 2, if the total number of blocks in the HFile is n. This definition is consistent with how the mid-key was determined in HFile version 1, and is reasonable in general, because blocks are likely to be the same size on average, but we don’t have any estimates on individual key/value pair sizes.
When writing a version 2 HFile, the total number of data blocks pointed to by every leaf-level index block is kept track of. When we finish writing and the total number of leaf-level blocks is determined, it is clear which leaf-level block contains the mid-key, and the fields listed above are computed. When reading the HFile and the mid-key is requested, we retrieve the middle leaf index block (potentially from the block cache) and get the mid-key value from the appropriate position inside that leaf block.
G.2.6. Non-root block index format in version 2
This format applies to intermediate-level and leaf index blocks of a version 2 multi-level data block index. Every non-root index block is structured as follows.
numEntries: the number of entries (int).
entryOffsets: the “secondary index” of offsets of entries in the block, to facilitate a quick binary search on the key (
numEntries + 1int values). The last value is the total length of all entries in this index block. For example, in a non-root index block with entry sizes 60, 80, 50 the “secondary index” will contain the following int array:{0, 60, 140, 190}.Entries. Each entry contains:
Offset of the block referenced by this entry in the file (long)
On-disk size of the referenced block (int)
Key. The length can be calculated from entryOffsets.
G.2.7. Bloom filters in version 2
In contrast with version 1, in a version 2 HFile Bloom filter metadata is stored in the load-on-open section of the HFile for quick startup.
A compound Bloom filter.
Bloom filter version = 3 (int). There used to be a DynamicByteBloomFilter class that had the Bloom filter version number 2
The total byte size of all compound Bloom filter chunks (long)
Number of hash functions (int)
Type of hash functions (int)
The total key count inserted into the Bloom filter (long)
The maximum total number of keys in the Bloom filter (long)
The number of chunks (int)
Comparator class used for Bloom filter keys, a UTF>8 encoded string stored using Bytes.writeByteArray
Bloom block index in the version 2 root block index format
G.2.8. File Info format in versions 1 and 2
The file info block is a serialized map from byte arrays to byte arrays, with the following keys, among others. StoreFile-level logic adds more keys to this.
| hfile.LASTKEY | The last key of the file (byte array) |
| hfile.AVG_KEY_LEN | The average key length in the file (int) |
| hfile.AVG_VALUE_LEN | The average value length in the file (int) |
In version 2, we did not change the file format, but we moved the file info to the final section of the file, which can be loaded as one block when the HFile is being opened.
Also, we do not store the comparator in the version 2 file info anymore. Instead, we store it in the fixed file trailer. This is because we need to know the comparator at the time of parsing the load-on-open section of the HFile.
G.2.9. Fixed file trailer format differences between versions 1 and 2
The following table shows common and different fields between fixed file trailers in versions 1 and 2. Note that the size of the trailer is different depending on the version, so it is ‘’fixed’’ only within one version. However, the version is always stored as the last four-byte integer in the file.
| Version 1 | Version 2 |
|---|---|
| File info offset (long) | |
| Data index offset (long) | loadOnOpenOffset (long) /The offset of the section that we need to load when opening the file./ |
| Number of data index entries (int) | |
| metaIndexOffset (long) /This field is not being used by the version 1 reader, so we removed it from version 2./ | uncompressedDataIndexSize (long) /The total uncompressed size of the whole data block index, including root-level, intermediate-level, and leaf-level blocks./ |
| Number of meta index entries (int) | |
| Total uncompressed bytes (long) | |
| numEntries (int) | numEntries (long) |
| Compression codec: 0 = LZO, 1 = GZ, 2 = NONE (int) | Compression codec: 0 = LZO, 1 = GZ, 2 = NONE (int) |
| The number of levels in the data block index (int) | |
| firstDataBlockOffset (long) /The offset of the first data block. Used when scanning./ | |
| lastDataBlockEnd (long) /The offset of the first byte after the last key/value data block. We don’t need to go beyond this offset when scanning./ | |
| Version: 1 (int) | Version: 2 (int) |
G.2.10. getShortMidpointKey(an optimization for data index block)
Note: this optimization was introduced in HBase 0.95+
HFiles contain many blocks that contain a range of sorted Cells. Each cell has a key. To save IO when reading Cells, the HFile also has an index that maps a Cell’s start key to the offset of the beginning of a particular block. Prior to this optimization, HBase would use the key of the first cell in each data block as the index key.
In HBASE-7845, we generate a new key that is lexicographically larger than the last key of the previous block and lexicographically equal or smaller than the start key of the current block. While actual keys can potentially be very long, this “fake key” or “virtual key” can be much shorter. For example, if the stop key of previous block is “the quick brown fox”, the start key of current block is “the who”, we could use “the r” as our virtual key in our hfile index.
There are two benefits to this:
having shorter keys reduces the hfile index size, (allowing us to keep more indexes in memory), and
using something closer to the end key of the previous block allows us to avoid a potential extra IO when the target key lives in between the “virtual key” and the key of the first element in the target block.
This optimization (implemented by the getShortMidpointKey method) is inspired by LevelDB’s ByteWiseComparatorImpl::FindShortestSeparator() and FindShortSuccessor().
G.3. HBase File Format with Security Enhancements (version 3)
Note: this feature was introduced in HBase 0.98
G.3.1. Motivation
Version 3 of HFile makes changes needed to ease management of encryption at rest and cell-level metadata (which in turn is needed for cell-level ACLs and cell-level visibility labels). For more information see hbase.encryption.server, hbase.tags, hbase.accesscontrol.configuration, and hbase.visibility.labels.
G.3.2. Overview
The version of HBase introducing the above features reads HFiles in versions 1, 2, and 3 but only writes version 3 HFiles. Version 3 HFiles are structured the same as version 2 HFiles. For more information see hfilev2.overview.
G.3.3. File Info Block in Version 3
Version 3 added two additional pieces of information to the reserved keys in the file info block.
| hfile.MAX_TAGS_LEN | The maximum number of bytes needed to store the serialized tags for any single cell in this hfile (int) |
| hfile.TAGS_COMPRESSED | Does the block encoder for this hfile compress tags? (boolean). Should only be present if hfile.MAX_TAGS_LEN is also present. |
When reading a Version 3 HFile the presence of MAX_TAGS_LEN is used to determine how to deserialize the cells within a data block. Therefore, consumers must read the file’s info block prior to reading any data blocks.
When writing a Version 3 HFile, HBase will always include MAX_TAGS_LEN when flushing the memstore to underlying filesystem.
When compacting extant files, the default writer will omit MAX_TAGS_LEN if all of the files selected do not themselves contain any cells with tags.
See compaction for details on the compaction file selection algorithm.
G.3.4. Data Blocks in Version 3
Within an HFile, HBase cells are stored in data blocks as a sequence of KeyValues (see hfilev1.overview, or Lars George’s excellent introduction to HBase Storage). In version 3, these KeyValue optionally will include a set of 0 or more tags:
| Version 1 & 2, Version 3 without MAX_TAGS_LEN | Version 3 with MAX_TAGS_LEN |
|---|---|
| Key Length (4 bytes) | |
| Value Length (4 bytes) | |
| Key bytes (variable) | |
| Value bytes (variable) | |
| Tags Length (2 bytes) | |
| Tags bytes (variable) |
If the info block for a given HFile contains an entry for MAX_TAGS_LEN each cell will have the length of that cell’s tags included, even if that length is zero. The actual tags are stored as a sequence of tag length (2 bytes), tag type (1 byte), tag bytes (variable). The format an individual tag’s bytes depends on the tag type.
Note that the dependence on the contents of the info block implies that prior to reading any data blocks you must first process a file’s info block. It also implies that prior to writing a data block you must know if the file’s info block will include MAX_TAGS_LEN.
G.3.5. Fixed File Trailer in Version 3
The fixed file trailers written with HFile version 3 are always serialized with protocol buffers. Additionally, it adds an optional field to the version 2 protocol buffer named encryptionkey. If HBase is configured to encrypt HFiles this field will store a data encryption key for this particular HFile, encrypted with the current cluster master key using AES. For more information see [hbase.encryption.server](docs_en#hbase.encryption.server).
Appendix H: Other Information About HBase
H.1. HBase Videos
Introduction to HBase
Introduction to HBase by Todd Lipcon (Chicago Data Summit 2011).
Building Real Time Services at Facebook with HBase by Jonathan Gray (Berlin buzzwords 2011)
The Multiple Uses Of HBase by Jean-Daniel Cryans(Berlin buzzwords 2011).
H.2. HBase Presentations (Slides)
Advanced HBase Schema Design by Lars George (Hadoop World 2011).
Introduction to HBase by Todd Lipcon (Chicago Data Summit 2011).
Getting The Most From Your HBase Install by Ryan Rawson, Jonathan Gray (Hadoop World 2009).
H.3. HBase Papers
BigTable by Google (2006).
HBase and HDFS Locality by Lars George (2010).
No Relation: The Mixed Blessings of Non-Relational Databases by Ian Varley (2009).
H.4. HBase Sites
Cloudera’s HBase Blog has a lot of links to useful HBase information.
CAP Confusion is a relevant entry for background information on distributed storage systems.
HBase RefCard from DZone.
H.5. HBase Books
HBase: The Definitive Guide by Lars George.
H.6. Hadoop Books
Hadoop: The Definitive Guide by Tom White.
Appendix I: HBase History
2006: BigTable paper published by Google.
2006 (end of year): HBase development starts.
2008: HBase becomes Hadoop sub-project.
2010: HBase becomes Apache top-level project.
Appendix J: HBase and the Apache Software Foundation
HBase is a project in the Apache Software Foundation and as such there are responsibilities to the ASF to ensure a healthy project.
J.1. ASF Development Process
See the Apache Development Process page for all sorts of information on how the ASF is structured (e.g., PMC, committers, contributors), to tips on contributing and getting involved, and how open-source works at ASF.
J.2. ASF Board Reporting
Once a quarter, each project in the ASF portfolio submits a report to the ASF board. This is done by the HBase project lead and the committers. See ASF board reporting for more information.
Appendix K: Apache HBase Orca
 Figure 23. Apache HBase Orca, HBase Colors, & Font
Figure 23. Apache HBase Orca, HBase Colors, & Font
An Orca is the Apache HBase mascot. See NOTICES.txt. Our Orca logo we got here: http://www.vectorfree.com/jumping-orca It is licensed Creative Commons Attribution 3.0. See https://creativecommons.org/licenses/by/3.0/us/ We changed the logo by stripping the colored background, inverting it and then rotating it some.
The ‘official’ HBase color is “International Orange (Engineering)”, the color of the Golden Gate bridge in San Francisco and for space suits used by NASA.
Our ‘font’ is Bitsumishi.
Appendix L: Enabling Dapper-like Tracing in HBase
HBase includes facilities for tracing requests using the open source tracing library, Apache HTrace. Setting up tracing is quite simple, however it currently requires some very minor changes to your client code (this requirement may be removed in the future).
Support for this feature using HTrace 3 in HBase was added in HBASE-6449. Starting with HBase 2.0, there was a non-compatible update to HTrace 4 via HBASE-18601. The examples provided in this section will be using HTrace 4 package names, syntax, and conventions. For older examples, please consult previous versions of this guide.
L.1. SpanReceivers
The tracing system works by collecting information in structures called ‘Spans’. It is up to you to choose how you want to receive this information by implementing the SpanReceiver interface, which defines one method:
public void receiveSpan(Span span);
This method serves as a callback whenever a span is completed. HTrace allows you to use as many SpanReceivers as you want so you can easily send trace information to multiple destinations.
Configure what SpanReceivers you’d like to us by putting a comma separated list of the fully-qualified class name of classes implementing SpanReceiver in hbase-site.xml property: hbase.trace.spanreceiver.classes.
HTrace includes a LocalFileSpanReceiver that writes all span information to local files in a JSON-based format. The LocalFileSpanReceiver looks in hbase-site.xml for a hbase.local-file-span-receiver.path property with a value describing the name of the file to which nodes should write their span information.
<property><name>hbase.trace.spanreceiver.classes</name><value>org.apache.htrace.core.LocalFileSpanReceiver</value></property><property><name>hbase.htrace.local-file-span-receiver.path</name><value>/var/log/hbase/htrace.out</value></property>
HTrace also provides ZipkinSpanReceiver which converts spans to Zipkin span format and send them to Zipkin server. In order to use this span receiver, you need to install the jar of htrace-zipkin to your HBase’s classpath on all of the nodes in your cluster.
htrace-zipkin is published to the Maven central repository. You could get the latest version from there or just build it locally (see the HTrace homepage for information on how to do this) and then copy it out to all nodes.
ZipkinSpanReceiver for properties called hbase.htrace.zipkin.collector-hostname and hbase.htrace.zipkin.collector-port in hbase-site.xml with values describing the Zipkin collector server to which span information are sent.
<property><name>hbase.trace.spanreceiver.classes</name><value>org.apache.htrace.core.ZipkinSpanReceiver</value></property><property><name>hbase.htrace.zipkin.collector-hostname</name><value>localhost</value></property><property><name>hbase.htrace.zipkin.collector-port</name><value>9410</value></property>
If you do not want to use the included span receivers, you are encouraged to write your own receiver (take a look at LocalFileSpanReceiver for an example). If you think others would benefit from your receiver, file a JIRA with the HTrace project.
201. Client Modifications
In order to turn on tracing in your client code, you must initialize the module sending spans to receiver once per client process.
private SpanReceiverHost spanReceiverHost;...Configuration conf = HBaseConfiguration.create();SpanReceiverHost spanReceiverHost = SpanReceiverHost.getInstance(conf);
Then you simply start tracing span before requests you think are interesting, and close it when the request is done. For example, if you wanted to trace all of your get operations, you change this:
Configuration config = HBaseConfiguration.create();Connection connection = ConnectionFactory.createConnection(config);Table table = connection.getTable(TableName.valueOf("t1"));Get get = new Get(Bytes.toBytes("r1"));Result res = table.get(get);
into:
TraceScope ts = Trace.startSpan("Gets", Sampler.ALWAYS);try {Table table = connection.getTable(TableName.valueOf("t1"));Get get = new Get(Bytes.toBytes("r1"));Result res = table.get(get);} finally {ts.close();}
If you wanted to trace half of your ‘get’ operations, you would pass in:
new ProbabilitySampler(0.5)
in lieu of Sampler.ALWAYS to Trace.startSpan(). See the HTrace README for more information on Samplers.
202. Tracing from HBase Shell
You can use trace command for tracing requests from HBase Shell. trace 'start' command turns on tracing and trace 'stop' command turns off tracing.
hbase(main):001:0> trace 'start'hbase(main):002:0> put 'test', 'row1', 'f:', 'val1' # traced commandshbase(main):003:0> trace 'stop'
trace 'start' and trace 'stop' always returns boolean value representing if or not there is ongoing tracing. As a result, trace 'stop' returns false on success. trace 'status' just returns if or not tracing is turned on.
hbase(main):001:0> trace 'start'=> truehbase(main):002:0> trace 'status'=> truehbase(main):003:0> trace 'stop'=> falsehbase(main):004:0> trace 'status'=> false
Appendix M: 0.95 RPC Specification
In 0.95, all client/server communication is done with protobuf’ed Messages rather than with Hadoop Writables. Our RPC wire format therefore changes. This document describes the client/server request/response protocol and our new RPC wire-format.
For what RPC is like in 0.94 and previous, see Benoît/Tsuna’s Unofficial Hadoop / HBase RPC protocol documentation. For more background on how we arrived at this spec., see HBase RPC: WIP
M.1. Goals
A wire-format we can evolve
A format that does not require our rewriting server core or radically changing its current architecture (for later).
M.2. TODO
List of problems with currently specified format and where we would like to go in a version2, etc. For example, what would we have to change if anything to move server async or to support streaming/chunking?
Diagram on how it works
A grammar that succinctly describes the wire-format. Currently we have these words and the content of the rpc protobuf idl but a grammar for the back and forth would help with groking rpc. Also, a little state machine on client/server interactions would help with understanding (and ensuring correct implementation).
M.3. RPC
The client will send setup information on connection establish. Thereafter, the client invokes methods against the remote server sending a protobuf Message and receiving a protobuf Message in response. Communication is synchronous. All back and forth is preceded by an int that has the total length of the request/response. Optionally, Cells(KeyValues) can be passed outside of protobufs in follow-behind Cell blocks (because we can’t protobuf megabytes of KeyValues or Cells). These CellBlocks are encoded and optionally compressed.
For more detail on the protobufs involved, see the RPC.proto file in master.
M.3.1. Connection Setup
Client initiates connection.
Client
On connection setup, client sends a preamble followed by a connection header.
<MAGIC 4 byte integer> <1 byte RPC Format Version> <1 byte auth type>
We need the auth method spec. here so the connection header is encoded if auth enabled.
E.g.: HBas0x000x50 — 4 bytes of MAGIC — `HBas’ — plus one-byte of version, 0 in this case, and one byte, 0x50 (SIMPLE). of an auth type.
Has user info, and ``protocol’’, as well as the encoders and compression the client will use sending CellBlocks. CellBlock encoders and compressors are for the life of the connection. CellBlock encoders implement org.apache.hadoop.hbase.codec.Codec. CellBlocks may then also be compressed. Compressors implement org.apache.hadoop.io.compress.CompressionCodec. This protobuf is written using writeDelimited so is prefaced by a pb varint with its serialized length
Server
After client sends preamble and connection header, server does NOT respond if successful connection setup. No response means server is READY to accept requests and to give out response. If the version or authentication in the preamble is not agreeable or the server has trouble parsing the preamble, it will throw a org.apache.hadoop.hbase.ipc.FatalConnectionException explaining the error and will then disconnect. If the client in the connection header — i.e. the protobuf’d Message that comes after the connection preamble — asks for a Service the server does not support or a codec the server does not have, again we throw a FatalConnectionException with explanation.
M.3.2. Request
After a Connection has been set up, client makes requests. Server responds.
A request is made up of a protobuf RequestHeader followed by a protobuf Message parameter. The header includes the method name and optionally, metadata on the optional CellBlock that may be following. The parameter type suits the method being invoked: i.e. if we are doing a getRegionInfo request, the protobuf Message param will be an instance of GetRegionInfoRequest. The response will be a GetRegionInfoResponse. The CellBlock is optionally used ferrying the bulk of the RPC data: i.e. Cells/KeyValues.
Request Parts
The request is prefaced by an int that holds the total length of what follows.
Will have call.id, trace.id, and method name, etc. including optional Metadata on the Cell block IFF one is following. Data is protobuf’d inline in this pb Message or optionally comes in the following CellBlock
If the method being invoked is getRegionInfo, if you study the Service descriptor for the client to regionserver protocol, you will find that the request sends a GetRegionInfoRequest protobuf Message param in this position.
An encoded and optionally compressed Cell block.
M.3.3. Response
Same as Request, it is a protobuf ResponseHeader followed by a protobuf Message response where the Message response type suits the method invoked. Bulk of the data may come in a following CellBlock.
Response Parts
The response is prefaced by an int that holds the total length of what follows.
Will have call.id, etc. Will include exception if failed processing. Optionally includes metadata on optional, IFF there is a CellBlock following.
Return or may be nothing if exception. If the method being invoked is getRegionInfo, if you study the Service descriptor for the client to regionserver protocol, you will find that the response sends a GetRegionInfoResponse protobuf Message param in this position.
An encoded and optionally compressed Cell block.
M.3.4. Exceptions
There are two distinct types. There is the request failed which is encapsulated inside the response header for the response. The connection stays open to receive new requests. The second type, the FatalConnectionException, kills the connection.
Exceptions can carry extra information. See the ExceptionResponse protobuf type. It has a flag to indicate do-no-retry as well as other miscellaneous payload to help improve client responsiveness.
M.3.5. CellBlocks
These are not versioned. Server can do the codec or it cannot. If new version of a codec with say, tighter encoding, then give it a new class name. Codecs will live on the server for all time so old clients can connect.
M.4. Notes
Constraints
In some part, current wire-format — i.e. all requests and responses preceded by a length — has been dictated by current server non-async architecture.
One fat pb request or header+param
We went with pb header followed by pb param making a request and a pb header followed by pb response for now. Doing header+param rather than a single protobuf Message with both header and param content:
Is closer to what we currently have
Having a single fat pb requires extra copying putting the already pb’d param into the body of the fat request pb (and same making result)
We can decide whether to accept the request or not before we read the param; for example, the request might be low priority. As is, we read header+param in one go as server is currently implemented so this is a TODO.
The advantages are minor. If later, fat request has clear advantage, can roll out a v2 later.
M.4.1. RPC Configurations
CellBlock Codecs
To enable a codec other than the default KeyValueCodec, set hbase.client.rpc.codec to the name of the Codec class to use. Codec must implement hbase’s Codec Interface. After connection setup, all passed cellblocks will be sent with this codec. The server will return cellblocks using this same codec as long as the codec is on the servers’ CLASSPATH (else you will get UnsupportedCellCodecException).
To change the default codec, set hbase.client.default.rpc.codec.
To disable cellblocks completely and to go pure protobuf, set the default to the empty String and do not specify a codec in your Configuration. So, set hbase.client.default.rpc.codec to the empty string and do not set hbase.client.rpc.codec. This will cause the client to connect to the server with no codec specified. If a server sees no codec, it will return all responses in pure protobuf. Running pure protobuf all the time will be slower than running with cellblocks.
Compression
Uses hadoop’s compression codecs. To enable compressing of passed CellBlocks, set hbase.client.rpc.compressor to the name of the Compressor to use. Compressor must implement Hadoop’s CompressionCodec Interface. After connection setup, all passed cellblocks will be sent compressed. The server will return cellblocks compressed using this same compressor as long as the compressor is on its CLASSPATH (else you will get UnsupportedCompressionCodecException).
Appendix N: Known Incompatibilities Among HBase Versions
203. HBase 2.0 Incompatible Changes
This appendix describes incompatible changes from earlier versions of HBase against HBase 2.0. This list is not meant to be wholly encompassing of all possible incompatibilities. Instead, this content is intended to give insight into some obvious incompatibilities which most users will face coming from HBase 1.x releases.
203.1. List of Major Changes for HBase 2.0
HBASE-1912- HBCK is a HBase database checking tool for capturing the inconsistency. As an HBase administrator, you should not use HBase version 1.0 hbck tool to check the HBase 2.0 database. Doing so will break the database and throw an exception error.
HBASE-16189 and HBASE-18945- You cannot open the HBase 2.0 hfiles through HBase 1.0 version. If you are an admin or an HBase user who is using HBase version 1.x, you must first do a rolling upgrade to the latest version of HBase 1.x and then upgrade to HBase 2.0.
HBASE-18240 - Changed the ReplicationEndpoint Interface. It also introduces a new hbase-third party 1.0 that packages all the third party utilities, which are expected to run in the hbase cluster.
203.2. Coprocessor API changes
HBASE-16769 - Deprecated PB references from MasterObserver and RegionServerObserver.
HBASE-17312 - [JDK8] Use default method for Observer Coprocessors. The interface classes of BaseMasterAndRegionObserver, BaseMasterObserver, BaseRegionObserver, BaseRegionServerObserver and BaseWALObserver uses JDK8’s ‘default’ keyword to provide empty and no-op implementations.
Interface HTableInterface HBase 2.0 introduces following changes to the methods listed below:
203.2.1. [−] interface CoprocessorEnvironment changes (2)
| Change | Result |
|---|---|
| Abstract method getTable ( TableName ) has been removed. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method getTable ( TableName, ExecutorService ) has been removed. | A client program may be interrupted by NoSuchMethodError exception. |
- Public Audience
The following tables describes the coprocessor changes.
[−] class CoprocessorRpcChannel (1)
| Change | Result |
|---|---|
| This class has become interface. | A client program may be interrupted by IncompatibleClassChangeError or InstantiationError exception depending on the usage of this class. |
Class CoprocessorHost
Classes that were Audience Private but were removed.
| Change | Result |
|---|---|
| Type of field coprocessors has been changed from java.util.SortedSet to org.apache.hadoop.hbase.util.SortedList. | A client program may be interrupted by NoSuchFieldError exception. |
203.2.2. MasterObserver
HBase 2.0 introduces following changes to the MasterObserver interface.
[−] interface MasterObserver (14)
| Change | Result |
|---|---|
| Abstract method voidpostCloneSnapshot ( ObserverContext, HBaseProtos.SnapshotDescription, HTableDescriptor ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method voidpostCreateTable ( ObserverContext, HTableDescriptor, HRegionInfo[ ] ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodErrorexception. |
| Abstract method voidpostDeleteSnapshot (ObserverContext, HBaseProtos.SnapshotDescription ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodErrorexception. |
| Abstract method voidpostGetTableDescriptors ( ObserverContext, List ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodErrorexception. |
| Abstract method voidpostModifyTable ( ObserverContext, TableName, HTableDescriptor ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodErrorexception. |
| Abstract method voidpostRestoreSnapshot ( ObserverContext, HBaseProtos.SnapshotDescription, HTableDescriptor ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodErrorexception. |
| Abstract method voidpostSnapshot ( ObserverContext, HBaseProtos.SnapshotDescription, HTableDescriptor ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodErrorexception. |
| Abstract method voidpreCloneSnapshot ( ObserverContext, HBaseProtos.SnapshotDescription, HTableDescriptor ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodErrorexception. |
| Abstract method voidpreCreateTable ( ObserverContext, HTableDescriptor, HRegionInfo[ ] ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodErrorexception. |
| Abstract method voidpreDeleteSnapshot ( ObserverContext, HBaseProtos.SnapshotDescription ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodErrorexception. |
| Abstract method voidpreGetTableDescriptors ( ObserverContext, List, List ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodErrorexception. |
| Abstract method voidpreModifyTable ( ObserverContext, TableName, HTableDescriptor ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodErrorexception. |
| Abstract method voidpreRestoreSnapshot ( ObserverContext, HBaseProtos.SnapshotDescription, HTableDescriptor ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodErrorexception. |
| Abstract method voidpreSnapshot ( ObserverContext, HBaseProtos.SnapshotDescription, HTableDescriptor ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodErrorexception. |
203.2.3. RegionObserver
HBase 2.0 introduces following changes to the RegionObserver interface.
[−] interface RegionObserver (13)
| Change | Result |
|---|---|
| Abstract method voidpostCloseRegionOperation ( ObserverContext, HRegion.Operation ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method voidpostCompactSelection ( ObserverContext, Store, ImmutableList ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method voidpostCompactSelection ( ObserverContext, Store, ImmutableList, CompactionRequest ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method voidpostGetClosestRowBefore ( ObserverContext, byte[ ], byte[ ], Result ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method DeleteTrackerpostInstantiateDeleteTracker ( ObserverContext, DeleteTracker ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method voidpostSplit ( ObserverContext, HRegion, HRegion ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method voidpostStartRegionOperation ( ObserverContext, HRegion.Operation ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method StoreFile.ReaderpostStoreFileReaderOpen ( ObserverContext, FileSystem, Path, FSDataInputStreamWrapper, long, CacheConfig, Reference, StoreFile.Reader ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method voidpostWALRestore ( ObserverContext, HRegionInfo, HLogKey, WALEdit ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method InternalScannerpreFlushScannerOpen ( ObserverContext, Store, KeyValueScanner, InternalScanner ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method voidpreGetClosestRowBefore ( ObserverContext, byte[ ], byte[ ], Result ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method StoreFile.ReaderpreStoreFileReaderOpen ( ObserverContext, FileSystem, Path, FSDataInputStreamWrapper, long, CacheConfig, Reference, StoreFile.Reader ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method voidpreWALRestore ( ObserverContext, HRegionInfo, HLogKey, WALEdit ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
203.2.4. WALObserver
HBase 2.0 introduces following changes to the WALObserver interface.
[−] interface WALObserver
| Change | Result |
|---|---|
| Abstract method voidpostWALWrite ( ObserverContext, HRegionInfo, HLogKey, WALEdit ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method booleanpreWALWrite ( ObserverContext, HRegionInfo, HLogKey, WALEdit ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
203.2.5. Miscellaneous
HBase 2.0 introduces changes to the following classes:
hbase-server-1.0.0.jar, OnlineRegions.class package org.apache.hadoop.hbase.regionserver
[−] OnlineRegions.getFromOnlineRegions ( String p1 ) [abstract] : HRegion
org/apache/hadoop/hbase/regionserver/OnlineRegions.getFromOnlineRegions:(Ljava/lang/String;)Lorg/apache/hadoop/hbase/regionserver/HRegion;
| Change | Result |
|---|---|
| Return value type has been changed from Region to Region. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
hbase-server-1.0.0.jar, RegionCoprocessorEnvironment.class package org.apache.hadoop.hbase.coprocessor
[−] RegionCoprocessorEnvironment.getRegion ( ) [abstract] : HRegion
org/apache/hadoop/hbase/coprocessor/RegionCoprocessorEnvironment.getRegion:()Lorg/apache/hadoop/hbase/regionserver/HRegion;
| Change | Result |
|---|---|
| Return value type has been changed from org.apache.hadoop.hbase.regionserver.HRegion to org.apache.hadoop.hbase.regionserver.Region. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
hbase-server-1.0.0.jar, RegionCoprocessorHost.class package org.apache.hadoop.hbase.regionserver
[−] RegionCoprocessorHost.postAppend ( Append append, Result result ) : void
org/apache/hadoop/hbase/regionserver/RegionCoprocessorHost.postAppend:(Lorg/apache/hadoop/hbase/client/Append;Lorg/apache/hadoop/hbase/client/Result;)V
| Change | Result |
|---|---|
| Return value type has been changed from void to org.apache.hadoop.hbase.client.Result. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
[−] RegionCoprocessorHost.preStoreFileReaderOpen ( FileSystem fs, Path p, FSDataInputStreamWrapper in, long size,CacheConfig cacheConf, Reference r ) : StoreFile.Reader
org/apache/hadoop/hbase/regionserver/RegionCoprocessorHost.preStoreFileReaderOpen:(Lorg/apache/hadoop/fs/FileSystem;Lorg/apache/hadoop/fs/Path;Lorg/apache/hadoop/hbase/io/FSDataInputStreamWrapper;JLorg/apache/hadoop/hbase/io/hfile/CacheConfig;Lorg/apache/hadoop/hbase/io/Reference;)Lorg/apache/hadoop/hbase/regionserver/StoreFile$Reader;
| Change | Result |
|---|---|
| Return value type has been changed from StoreFile.Reader to StoreFileReader. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
203.2.6. IPC
203.2.7. Scheduler changes:
- Following methods became abstract:
package org.apache.hadoop.hbase.ipc
[−]class RpcScheduler (1)
| Change | Result |
|---|---|
| Abstract method void dispatch ( CallRunner ) has been removed from this class. | A client program may be interrupted by NoSuchMethodError exception. |
hbase-server-1.0.0.jar, RpcScheduler.class package org.apache.hadoop.hbase.ipc
[−] RpcScheduler.dispatch ( CallRunner p1 ) [abstract] : void 1
org/apache/hadoop/hbase/ipc/RpcScheduler.dispatch:(Lorg/apache/hadoop/hbase/ipc/CallRunner;)V
| Change | Result |
|---|---|
| Return value type has been changed from void to boolean. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
- Following abstract methods have been removed:
[−]interface PriorityFunction (2)
| Change | Result |
|---|---|
| Abstract method longgetDeadline ( RPCProtos.RequestHeader, Message ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method int getPriority ( RPCProtos.RequestHeader, Message ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
203.2.8. Server API changes:
[−] class RpcServer (12)
| Change | Result |
|---|---|
| Type of field CurCall has been changed from java.lang.ThreadLocal |
A client program may be interrupted by NoSuchFieldError exception. |
| This class became abstract. | A client program may be interrupted by InstantiationError exception. |
| Abstract method int getNumOpenConnections ( ) has been added to this class. | This class became abstract and a client program may be interrupted by InstantiationError exception. |
| Field callQueueSize of type org.apache.hadoop.hbase.util.Counter has been removed from this class. | A client program may be interrupted by NoSuchFieldError exception. |
| Field connectionList of type java.util.List |
A client program may be interrupted by NoSuchFieldError exception. |
| Field maxIdleTime of type int has been removed from this class. | A client program may be interrupted by NoSuchFieldError exception. |
| Field numConnections of type int has been removed from this class. | A client program may be interrupted by NoSuchFieldError exception. |
| Field port of type int has been removed from this class. | A client program may be interrupted by NoSuchFieldError exception. |
| Field purgeTimeout of type long has been removed from this class. | A client program may be interrupted by NoSuchFieldError exception. |
| Field responder of type RpcServer.Responder has been removed from this class. | A client program may be interrupted by NoSuchFieldError exception. |
| Field socketSendBufferSize of type int has been removed from this class. | A client program may be interrupted by NoSuchFieldError exception. |
| Field thresholdIdleConnections of type int has been removed from this class. | A client program may be interrupted by NoSuchFieldError exception. |
Following abstract method has been removed:
| Change | Result |
|---|---|
| Abstract method Pair |
A client program may be interrupted by NoSuchMethodError exception. |
203.2.9. Replication and WAL changes:
HBASE-18733: WALKey has been purged completely in HBase 2.0. Following are the changes to the WALKey:
[−] classWALKey (8)
| Change | Result |
|---|---|
| Access level of field clusterIds has been changed from protected to private. | A client program may be interrupted by IllegalAccessError exception. |
| Access level of field compressionContext has been changed from protected to private. | A client program may be interrupted by IllegalAccessError exception. |
| Access level of field encodedRegionName has been changed from protected to private. | A client program may be interrupted by IllegalAccessError exception. |
| Access level of field tablename has been changed from protectedto private. | A client program may be interrupted by IllegalAccessError exception. |
| Access level of field writeTime has been changed from protectedto private. | A client program may be interrupted by IllegalAccessError exception. |
Following fields have been removed:
| Change | Result |
|---|---|
| Field LOG of type org.apache.commons.logging.Log has been removed from this class. | A client program may be interrupted by NoSuchFieldError exception. |
| Field VERSION of type WALKey.Version has been removed from this class. | A client program may be interrupted by NoSuchFieldError exception. |
| Field logSeqNum of type long has been removed from this class. | A client program may be interrupted by NoSuchFieldError exception. |
Following are the changes to the WALEdit.class: hbase-server-1.0.0.jar, WALEdit.class package org.apache.hadoop.hbase.regionserver.wal
WALEdit.getCompaction ( Cell kv ) [static] : WALProtos.CompactionDescriptor (1)
org/apache/hadoop/hbase/regionserver/wal/WALEdit.getCompaction:(Lorg/apache/hadoop/hbase/Cell;)Lorg/apache/hadoop/hbase/protobuf/generated/WALProtos$CompactionDescriptor;
| Change | Result |
|---|---|
| Return value type has been changed from org.apache.hadoop.hbase.protobuf.generated.WALProtos.CompactionDescriptor to org.apache.hadoop.hbase.shaded.protobuf.generated.WALProtos.CompactionDescriptor. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
WALEdit.getFlushDescriptor ( Cell cell ) [static] : WALProtos.FlushDescriptor (1)
org/apache/hadoop/hbase/regionserver/wal/WALEdit.getFlushDescriptor:(Lorg/apache/hadoop/hbase/Cell;)Lorg/apache/hadoop/hbase/protobuf/generated/WALProtos$FlushDescriptor;
| Change | Result |
|---|---|
| Return value type has been changed from org.apache.hadoop.hbase.protobuf.generated.WALProtos.FlushDescriptor to org.apache.hadoop.hbase.shaded.protobuf.generated.WALProtos.FlushDescriptor. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
WALEdit.getRegionEventDescriptor ( Cell cell ) [static] : WALProtos.RegionEventDescriptor (1)
org/apache/hadoop/hbase/regionserver/wal/WALEdit.getRegionEventDescriptor:(Lorg/apache/hadoop/hbase/Cell;)Lorg/apache/hadoop/hbase/protobuf/generated/WALProtos$RegionEventDescriptor;
| Change | Result |
|---|---|
| Return value type has been changed from org.apache.hadoop.hbase.protobuf.generated.WALProtos.RegionEventDescriptor to org.apache.hadoop.hbase.shaded.protobuf.generated.WALProtos.RegionEventDescriptor. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
Following is the change to the WALKey.class: package org.apache.hadoop.hbase.wal
WALKey.getBuilder ( WALCellCodec.ByteStringCompressor compressor ) : WALProtos.WALKey.Builder 1
org/apache/hadoop/hbase/wal/WALKey.getBuilder:(Lorg/apache/hadoop/hbase/regionserver/wal/WALCellCodec$ByteStringCompressor;)Lorg/apache/hadoop/hbase/protobuf/generated/WALProtos$WALKey$Builder;
| Change | Result |
|---|---|
| Return value type has been changed from org.apache.hadoop.hbase.protobuf.generated.WALProtos.WALKey.Builder to org.apache.hadoop.hbase.shaded.protobuf.generated.WALProtos.WALKey.Builder. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
203.2.10. Deprecated APIs or coprocessor:
HBASE-16769 - PB references from MasterObserver and RegionServerObserver has been removed.
203.2.11. Admin Interface API changes:
You cannot administer an HBase 2.0 cluster with an HBase 1.0 client that includes RelicationAdmin, ACC, Thrift and REST usage of Admin ops. Methods returning protobufs have been changed to return POJOs instead. pb is not used in the APIs anymore. Returns have changed from void to Future for async methods. HBASE-18106 - Admin.listProcedures and Admin.listLocks were renamed to getProcedures and getLocks. MapReduce makes use of Admin doing following admin.getClusterStatus() to calcluate Splits.
Thrift usage of Admin API: compact(ByteBuffer) createTable(ByteBuffer, List) deleteTable(ByteBuffer) disableTable(ByteBuffer) enableTable(ByteBuffer) getTableNames() majorCompact(ByteBuffer)
REST usage of Admin API: hbase-rest org.apache.hadoop.hbase.rest RootResource getTableList() TableName[] tableNames = servlet.getAdmin().listTableNames(); SchemaResource delete(UriInfo) Admin admin = servlet.getAdmin(); update(TableSchemaModel, boolean, UriInfo) Admin admin = servlet.getAdmin(); StorageClusterStatusResource get(UriInfo) ClusterStatus status = servlet.getAdmin().getClusterStatus(); StorageClusterVersionResource get(UriInfo) model.setVersion(servlet.getAdmin().getClusterStatus().getHBaseVersion()); TableResource exists() return servlet.getAdmin().tableExists(TableName.valueOf(table));
Following are the changes to the Admin interface:
[−] interface Admin (9)
| Change | Result |
|---|---|
| Abstract method createTableAsync ( HTableDescriptor, byte[ ][ ] ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method disableTableAsync ( TableName ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method enableTableAsync ( TableName ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method getCompactionState ( TableName ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method getCompactionStateForRegion ( byte[ ] ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method isSnapshotFinished ( HBaseProtos.SnapshotDescription ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method snapshot ( String, TableName, HBaseProtos.SnapshotDescription.Type ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method snapshot ( HBaseProtos.SnapshotDescription ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method takeSnapshotAsync ( HBaseProtos.SnapshotDescription ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
Following are the changes to the Admin.class: hbase-client-1.0.0.jar, Admin.class package org.apache.hadoop.hbase.client
[−] Admin.createTableAsync ( HTableDescriptor p1, byte[ ][ ] p2 ) [abstract] : void 1
org/apache/hadoop/hbase/client/Admin.createTableAsync:(Lorg/apache/hadoop/hbase/HTableDescriptor;[[B)V
| Change | Result |
|---|---|
| Return value type has been changed from void to java.util.concurrent.Future |
This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
[−] Admin.disableTableAsync ( TableName p1 ) [abstract] : void 1
org/apache/hadoop/hbase/client/Admin.disableTableAsync:(Lorg/apache/hadoop/hbase/TableName;)V
| Change | Result |
|---|---|
| Return value type has been changed from void to java.util.concurrent.Future |
This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
Admin.enableTableAsync ( TableName p1 ) [abstract] : void 1
org/apache/hadoop/hbase/client/Admin.enableTableAsync:(Lorg/apache/hadoop/hbase/TableName;)V
| Change | Result |
|---|---|
| Return value type has been changed from void to java.util.concurrent.Future |
This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
[−] Admin.getCompactionState ( TableName p1 ) [abstract] : AdminProtos.GetRegionInfoResponse.CompactionState 1
org/apache/hadoop/hbase/client/Admin.getCompactionState:(Lorg/apache/hadoop/hbase/TableName;)Lorg/apache/hadoop/hbase/protobuf/generated/AdminProtos$GetRegionInfoResponse$CompactionState;
| Change | Result |
|---|---|
| Return value type has been changed from org.apache.hadoop.hbase.protobuf.generated.AdminProtos.GetRegionInfoResponse.CompactionState to CompactionState. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
[−] Admin.getCompactionStateForRegion ( byte[ ] p1 ) [abstract] : AdminProtos.GetRegionInfoResponse.CompactionState 1
org/apache/hadoop/hbase/client/Admin.getCompactionStateForRegion:([B)Lorg/apache/hadoop/hbase/protobuf/generated/AdminProtos$GetRegionInfoResponse$CompactionState;
| Change | Result |
|---|---|
| Return value type has been changed from org.apache.hadoop.hbase.protobuf.generated.AdminProtos.GetRegionInfoResponse.CompactionState to CompactionState. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
203.2.12. HTableDescriptor and HColumnDescriptor changes
HTableDescriptor and HColumnDescriptor has become interfaces and you can create it through Builders. HCD has become CFD. It no longer implements writable interface. package org.apache.hadoop.hbase
[−] class HColumnDescriptor (1)
| Change | Result |
|---|---|
| Removed super-interface org.apache.hadoop.io.WritableComparable. | A client program may be interrupted by NoSuchMethodError exception. |
HColumnDescriptor in 1.0.0 {code} @InterfaceAudience.Public @InterfaceStability.Evolving public class HColumnDescriptor implements WritableComparable { {code}
HColumnDescriptor in 2.0 {code} @InterfaceAudience.Public @Deprecated // remove it in 3.0 public class HColumnDescriptor implements ColumnFamilyDescriptor, Comparable { {code}
For META_TABLEDESC, the maker method had been deprecated already in HTD in 1.0.0. OWNER_KEY is still in HTD.
class HTableDescriptor (3)
| Change | Result |
|---|---|
| Removed super-interface org.apache.hadoop.io.WritableComparable. | A client program may be interrupted by NoSuchMethodError exception. |
| Field META_TABLEDESC of type HTableDescriptor has been removed from this class. | A client program may be interrupted by NoSuchFieldError exception. |
hbase-client-1.0.0.jar, HTableDescriptor.class package org.apache.hadoop.hbase
[−] HTableDescriptor.getColumnFamilies ( ) : HColumnDescriptor[ ] (1)
org/apache/hadoop/hbase/HTableDescriptor.getColumnFamilies:()[Lorg/apache/hadoop/hbase/HColumnDescriptor;
[−] class HColumnDescriptor (1)
| Change | Result |
|---|---|
| Return value type has been changed from HColumnDescriptor[]to client.ColumnFamilyDescriptor[]. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
[−] HTableDescriptor.getCoprocessors ( ) : List (1)
org/apache/hadoop/hbase/HTableDescriptor.getCoprocessors:()Ljava/util/List;
| Change | Result |
|---|---|
| Return value type has been changed from java.util.List |
This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
- HBASE-12990 MetaScanner is removed and it is replaced by MetaTableAccessor.
HTableWrapper changes:
hbase-server-1.0.0.jar, HTableWrapper.class package org.apache.hadoop.hbase.client
[−] HTableWrapper.createWrapper ( List openTables, TableName tableName, CoprocessorHost.Environment env, ExecutorService pool ) [static] : HTableInterface 1
org/apache/hadoop/hbase/client/HTableWrapper.createWrapper:(Ljava/util/List;Lorg/apache/hadoop/hbase/TableName;Lorg/apache/hadoop/hbase/coprocessor/CoprocessorHost$Environment;Ljava/util/concurrent/ExecutorService;)Lorg/apache/hadoop/hbase/client/HTableInterface;
| Change | Result |
|---|---|
| Return value type has been changed from HTableInterface to Table. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
HBASE-12586: Delete all public HTable constructors and delete ConnectionManager#{delete,get}Connection.
HBASE-9117: Remove HTablePool and all HConnection pooling related APIs.
HBASE-13214: Remove deprecated and unused methods from HTable class Following are the changes to the Table interface:
[−] interface Table (4)
| Change | Result |
|---|---|
| Abstract method batch ( List<?> ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method batchCallback ( List<?>, Batch.Callback )has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method getWriteBufferSize ( ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method setWriteBufferSize ( long ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
203.2.13. Deprecated buffer methods in Table (in 1.0.1) and removed in 2.0.0
HBASE-13298- Clarify if Table.{set|get}WriteBufferSize() is deprecated or not.
LockTimeoutException and OperationConflictException classes have been removed.
203.2.14. class OperationConflictException (1)
| Change | Result |
|---|---|
| This class has been removed. | A client program may be interrupted by NoClassDefFoundErrorexception. |
203.2.15. class class LockTimeoutException (1)
| Change | Result |
|---|---|
| This class has been removed. | A client program may be interrupted by NoClassDefFoundErrorexception. |
203.2.16. Filter API changes:
Following methods have been removed: package org.apache.hadoop.hbase.filter
[−] class Filter (2)
| Change | Result |
|---|---|
| Abstract method getNextKeyHint ( KeyValue ) has been removed from this class. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method transform ( KeyValue ) has been removed from this class. | A client program may be interrupted by NoSuchMethodError exception. |
HBASE-12296 Filters should work with ByteBufferedCell.
HConnection is removed in HBase 2.0.
RegionLoad and ServerLoad internally moved to shaded PB.
[−] class RegionLoad (1)
| Change | Result |
|---|---|
| Type of field regionLoadPB has been changed from protobuf.generated.ClusterStatusProtos.RegionLoad to shaded.protobuf.generated.ClusterStatusProtos.RegionLoad. | A client program may be interrupted by NoSuchFieldError exception. |
- HBASE-15783:AccessControlConstants#OP_ATTRIBUTE_ACL_STRATEGY_CELL_FIRST is not used any more. package org.apache.hadoop.hbase.security.access
[−] interface AccessControlConstants (3)
| Change | Result |
|---|---|
| Field OP_ATTRIBUTE_ACL_STRATEGY of type java.lang.Stringhas been removed from this interface. | A client program may be interrupted by NoSuchFieldError exception. |
| Field OP_ATTRIBUTE_ACL_STRATEGY_CELL_FIRST of type byte[] has been removed from this interface. | A client program may be interrupted by NoSuchFieldError exception. |
| Field OP_ATTRIBUTE_ACL_STRATEGY_DEFAULT of type byte[] has been removed from this interface. | A client program may be interrupted by NoSuchFieldError exception. |
ServerLoad returns long instead of int 1
hbase-client-1.0.0.jar, ServerLoad.class package org.apache.hadoop.hbase
[−] ServerLoad.getNumberOfRequests ( ) : int 1
org/apache/hadoop/hbase/ServerLoad.getNumberOfRequests:()I
| Change | Result |
|---|---|
| Return value type has been changed from int to long. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
[−] ServerLoad.getReadRequestsCount ( ) : int 1
org/apache/hadoop/hbase/ServerLoad.getReadRequestsCount:()I
| Change | Result |
|---|---|
| Return value type has been changed from int to long. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
[−] ServerLoad.getTotalNumberOfRequests ( ) : int 1
org/apache/hadoop/hbase/ServerLoad.getTotalNumberOfRequests:()I
| Change | Result |
|---|---|
| Return value type has been changed from int to long. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
[−]ServerLoad.getWriteRequestsCount ( ) : int 1
org/apache/hadoop/hbase/ServerLoad.getWriteRequestsCount:()I
| Change | Result |
|---|---|
| Return value type has been changed from int to long. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
HBASE-13636 Remove deprecation for HBASE-4072 (Reading of zoo.cfg)
HConstants are removed. HBASE-16040 Remove configuration “hbase.replication”
[−]class HConstants (6)
| Change | Result |
|---|---|
| Field DEFAULT_HBASE_CONFIG_READ_ZOOKEEPER_CONFIG of type boolean has been removed from this class. | A client program may be interrupted by NoSuchFieldError exception. |
| Field HBASE_CONFIG_READ_ZOOKEEPER_CONFIG of type java.lang.String has been removed from this class. | A client program may be interrupted by NoSuchFieldError exception. |
| Field REPLICATION_ENABLE_DEFAULT of type boolean has been removed from this class. | A client program may be interrupted by NoSuchFieldError exception. |
| Field REPLICATION_ENABLE_KEY of type java.lang.String has been removed from this class. | A client program may be interrupted by NoSuchFieldError exception. |
| Field ZOOKEEPER_CONFIG_NAME of type java.lang.String has been removed from this class. | A client program may be interrupted by NoSuchFieldError exception. |
| Field ZOOKEEPER_USEMULTI of type java.lang.String has been removed from this class. | A client program may be interrupted by NoSuchFieldError exception. |
- HBASE-18732: [compat 1-2] HBASE-14047 removed Cell methods without deprecation cycle.
[−]interface Cell 5
| Change | Result |
|---|---|
| Abstract method getFamily ( ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method getMvccVersion ( ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method getQualifier ( ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method getRow ( ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
| Abstract method getValue ( ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
- HBASE-18795:Expose KeyValue.getBuffer() for tests alone. Allows KV#getBuffer in tests only that was deprecated previously.
203.2.17. Region scanner changes:
[−]interface RegionScanner (1)
| Change | Result |
|---|---|
| Abstract method boolean nextRaw ( List, int ) has been removed from this interface. | A client program may be interrupted by NoSuchMethodError exception. |
203.2.18. StoreFile changes:
[−] class StoreFile (1)
| Change | Result |
|---|---|
| This class became interface. | A client program may be interrupted by IncompatibleClassChangeError or InstantiationError exception dependent on the usage of this class. |
203.2.19. Mapreduce changes:
HFile*Format has been removed in HBase 2.0.
203.2.20. ClusterStatus changes:
HBASE-15843: Replace RegionState.getRegionInTransition() Map with a Set hbase-client-1.0.0.jar, ClusterStatus.class package org.apache.hadoop.hbase
[−] ClusterStatus.getRegionsInTransition ( ) : Map 1
org/apache/hadoop/hbase/ClusterStatus.getRegionsInTransition:()Ljava/util/Map;
| Change | Result |
|---|---|
| Return value type has been changed from java.util.Map |
This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
Other changes in ClusterStatus include removal of convert methods that were no longer necessary after purge of PB from API.
203.2.21. Purge of PBs from API
PBs have been deprecated in APIs in HBase 2.0.
[−] HBaseSnapshotException.getSnapshotDescription ( ) : HBaseProtos.SnapshotDescription 1
org/apache/hadoop/hbase/snapshot/HBaseSnapshotException.getSnapshotDescription:()Lorg/apache/hadoop/hbase/protobuf/generated/HBaseProtos$SnapshotDescription;
| Change | Result |
|---|---|
| Return value type has been changed from org.apache.hadoop.hbase.protobuf.generated.HBaseProtos.SnapshotDescription to org.apache.hadoop.hbase.client.SnapshotDescription. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
- HBASE-15609: Remove PB references from Result, DoubleColumnInterpreter and any such public facing class for 2.0. hbase-client-1.0.0.jar, Result.class package org.apache.hadoop.hbase.client
[−] Result.getStats ( ) : ClientProtos.RegionLoadStats 1
org/apache/hadoop/hbase/client/Result.getStats:()Lorg/apache/hadoop/hbase/protobuf/generated/ClientProtos$RegionLoadStats;
| Change | Result |
|---|---|
| Return value type has been changed from org.apache.hadoop.hbase.protobuf.generated.ClientProtos.RegionLoadStats to RegionLoadStats. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
203.2.22. REST changes:
hbase-rest-1.0.0.jar, Client.class package org.apache.hadoop.hbase.rest.client
[−] Client.getHttpClient ( ) : HttpClient 1
org/apache/hadoop/hbase/rest/client/Client.getHttpClient:()Lorg/apache/commons/httpclient/HttpClient
| Change | Result |
|---|---|
| Return value type has been changed from org.apache.commons.httpclient.HttpClient to org.apache.http.client.HttpClient. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
hbase-rest-1.0.0.jar, Response.class package org.apache.hadoop.hbase.rest.client
[−] Response.getHeaders ( ) : Header[ ] 1
org/apache/hadoop/hbase/rest/client/Response.getHeaders:()[Lorg/apache/commons/httpclient/Header;
| Change | Result |
|---|---|
| Return value type has been changed from org.apache.commons.httpclient.Header[] to org.apache.http.Header[]. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
203.2.23. PrettyPrinter changes:
hbase-server-1.0.0.jar, HFilePrettyPrinter.class package org.apache.hadoop.hbase.io.hfile
[−]HFilePrettyPrinter.processFile ( Path file ) : void 1
org/apache/hadoop/hbase/io/hfile/HFilePrettyPrinter.processFile:(Lorg/apache/hadoop/fs/Path;)V
| Change | Result |
|---|---|
| Return value type has been changed from void to int. | This method has been removed because the return type is part of the method signature. A client program may be interrupted by NoSuchMethodError exception. |
203.2.24. AccessControlClient changes:
HBASE-13171 Change AccessControlClient methods to accept connection object to reduce setup time. Parameters have been changed in the following methods:
hbase-client-1.2.7-SNAPSHOT.jar, AccessControlClient.class package org.apache.hadoop.hbase.security.access AccessControlClient.getUserPermissions ( Configuration conf, String tableRegex ) [static] : List DEPRECATED org/apache/hadoop/hbase/security/access/AccessControlClient.getUserPermissions:(Lorg/apache/hadoop/conf/Configuration;Ljava/lang/String;)Ljava/util/List;
AccessControlClient.grant ( Configuration conf, String namespace, String userName, Permission.Action… actions )[static] : void DEPRECATED org/apache/hadoop/hbase/security/access/AccessControlClient.grant:(Lorg/apache/hadoop/conf/Configuration;Ljava/lang/String;Ljava/lang/String;[Lorg/apache/hadoop/hbase/security/access/Permission$Action;)V
AccessControlClient.grant ( Configuration conf, String userName, Permission.Action… actions ) [static] : void DEPRECATED org/apache/hadoop/hbase/security/access/AccessControlClient.grant:(Lorg/apache/hadoop/conf/Configuration;Ljava/lang/String;[Lorg/apache/hadoop/hbase/security/access/Permission$Action;)V
AccessControlClient.grant ( Configuration conf, TableName tableName, String userName, byte[ ] family, byte[ ] qual,Permission.Action… actions ) [static] : void DEPRECATED org/apache/hadoop/hbase/security/access/AccessControlClient.grant:(Lorg/apache/hadoop/conf/Configuration;Lorg/apache/hadoop/hbase/TableName;Ljava/lang/String;[B[B[Lorg/apache/hadoop/hbase/security/access/Permission$Action;)V
AccessControlClient.isAccessControllerRunning ( Configuration conf ) [static] : boolean DEPRECATED org/apache/hadoop/hbase/security/access/AccessControlClient.isAccessControllerRunning:(Lorg/apache/hadoop/conf/Configuration;)Z
AccessControlClient.revoke ( Configuration conf, String namespace, String userName, Permission.Action… actions )[static] : void DEPRECATED org/apache/hadoop/hbase/security/access/AccessControlClient.revoke:(Lorg/apache/hadoop/conf/Configuration;Ljava/lang/String;Ljava/lang/String;[Lorg/apache/hadoop/hbase/security/access/Permission$Action;)V
AccessControlClient.revoke ( Configuration conf, String userName, Permission.Action… actions ) [static] : void DEPRECATED org/apache/hadoop/hbase/security/access/AccessControlClient.revoke:(Lorg/apache/hadoop/conf/Configuration;Ljava/lang/String;[Lorg/apache/hadoop/hbase/security/access/Permission$Action;)V
AccessControlClient.revoke ( Configuration conf, TableName tableName, String username, byte[ ] family, byte[ ] qualifier,Permission.Action… actions ) [static] : void DEPRECATED org/apache/hadoop/hbase/security/access/AccessControlClient.revoke:(Lorg/apache/hadoop/conf/Configuration;Lorg/apache/hadoop/hbase/TableName;Ljava/lang/String;[B[B[Lorg/apache/hadoop/hbase/security/access/Permission$Action;)V
HBASE-18731: [compat 1-2] Mark protected methods of QuotaSettings that touch Protobuf internals as IA.Private

若有收获,就点个赞吧
0 人点赞
