- 79. Overview
- 80. Terminology
- 81. Planning
- 82. First-time configuration steps
- 83. Backup and Restore commands
- 84. Administration of Backup Images
- 85. Configuration keys
- 86. Best Practices
- 87. Scenario: Safeguarding Application Datasets on Amazon S3
- 88. Security of Backup Data
- 89. Technical Details of Incremental Backup and Restore
- 90. A Warning on File System Growth
- 91. Capacity Planning
- 92. Limitations of the Backup and Restore Utility
79. Overview
Backup and restore is a standard operation provided by many databases. An effective backup and restore strategy helps ensure that users can recover data in case of unexpected failures. The HBase backup and restore feature helps ensure that enterprises using HBase as a canonical data repository can recover from catastrophic failures. Another important feature is the ability to restore the database to a particular point-in-time, commonly referred to as a snapshot.
The HBase backup and restore feature provides the ability to create full backups and incremental backups on tables in an HBase cluster. The full backup is the foundation on which incremental backups are applied to build iterative snapshots. Incremental backups can be run on a schedule to capture changes over time, for example by using a Cron task. Incremental backups are more cost-effective than full backups because they only capture the changes since the last backup and they also enable administrators to restore the database to any prior incremental backup. Furthermore, the utilities also enable table-level data backup-and-recovery if you do not want to restore the entire dataset of the backup.
The backup and restore feature supplements the HBase Replication feature. While HBase replication is ideal for creating “hot” copies of the data (where the replicated data is immediately available for query), the backup and restore feature is ideal for creating “cold” copies of data (where a manual step must be taken to restore the system). Previously, users only had the ability to create full backups via the ExportSnapshot functionality. The incremental backup implementation is the novel improvement over the previous “art” provided by ExportSnapshot.
The backup and restore feature uses DistCp to transfer files between clusters . HADOOP-15850 fixes a bug where CopyCommitter#concatFileChunks unconditionally tried to concatenate the files being DistCp’ed to target cluster (though the files are independent) . Without the fix from HADOOP-15850 , the transfer would fail. So the backup and restore feature need hadoop version as below
2.7.x
2.8.x
2.9.2+
2.10.0+
3.0.4+
3.1.2+
3.2.0+
3.3.0+
80. Terminology
The backup and restore feature introduces new terminology which can be used to understand how control flows through the system.
A backup: A logical unit of data and metadata which can restore a table to its state at a specific point in time.
Full backup: a type of backup which wholly encapsulates the contents of the table at a point in time.
Incremental backup: a type of backup which contains the changes in a table since a full backup.
Backup set: A user-defined name which references one or more tables over which a backup can be executed.
Backup ID: A unique names which identifies one backup from the rest, e.g.
backupId_1467823988425
81. Planning
There are some common strategies which can be used to implement backup and restore in your environment. The following section shows how these strategies are implemented and identifies potential tradeoffs with each.
This backup and restore tools has not been tested on Transparent Data Encryption (TDE) enabled HDFS clusters. This is related to the open issue HBASE-16178.
81.1. Backup within a cluster
This strategy stores the backups on the same cluster as where the backup was taken. This approach is only appropriate for testing as it does not provide any additional safety on top of what the software itself already provides.
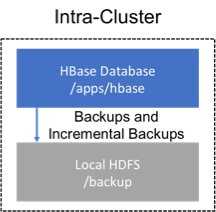 Figure 4. Intra-Cluster Backup
Figure 4. Intra-Cluster Backup
81.2. Backup using a dedicated cluster
This strategy provides greater fault tolerance and provides a path towards disaster recovery. In this setting, you will store the backup on a separate HDFS cluster by supplying the backup destination cluster’s HDFS URL to the backup utility. You should consider backing up to a different physical location, such as a different data center.
Typically, a backup-dedicated HDFS cluster uses a more economical hardware profile to save money.
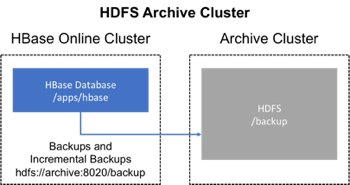 Figure 5. Dedicated HDFS Cluster Backup
Figure 5. Dedicated HDFS Cluster Backup
81.3. Backup to the Cloud or a storage vendor appliance
Another approach to safeguarding HBase incremental backups is to store the data on provisioned, secure servers that belong to third-party vendors and that are located off-site. The vendor can be a public cloud provider or a storage vendor who uses a Hadoop-compatible file system, such as S3 and other HDFS-compatible destinations.
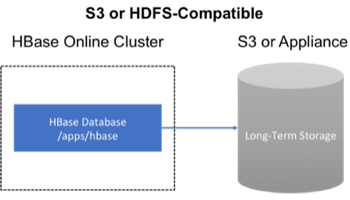 Figure 6. Backup to Cloud or Vendor Storage Solutions
Figure 6. Backup to Cloud or Vendor Storage Solutions
The HBase backup utility does not support backup to multiple destinations. A workaround is to manually create copies of the backup files from HDFS or S3.
82. First-time configuration steps
This section contains the necessary configuration changes that must be made in order to use the backup and restore feature. As this feature makes significant use of YARN’s MapReduce framework to parallelize these I/O heavy operations, configuration changes extend outside of just hbase-site.xml.
82.1. Allow the “hbase” system user in YARN
The YARN container-executor.cfg configuration file must have the following property setting: allowed.system.users=hbase. No spaces are allowed in entries of this configuration file.
Skipping this step will result in runtime errors when executing the first backup tasks.
Example of a valid container-executor.cfg file for backup and restore:
yarn.nodemanager.log-dirs=/var/log/hadoop/mapredyarn.nodemanager.linux-container-executor.group=yarnbanned.users=hdfs,yarn,mapred,binallowed.system.users=hbasemin.user.id=500
82.2. HBase specific changes
Add the following properties to hbase-site.xml and restart HBase if it is already running.
The “,…” is an ellipsis meant to imply that this is a comma-separated list of values, not literal text which should be added to hbase-site.xml.
<property><name>hbase.backup.enable</name><value>true</value></property><property><name>hbase.master.logcleaner.plugins</name><value>org.apache.hadoop.hbase.backup.master.BackupLogCleaner,...</value></property><property><name>hbase.procedure.master.classes</name><value>org.apache.hadoop.hbase.backup.master.LogRollMasterProcedureManager,...</value></property><property><name>hbase.procedure.regionserver.classes</name><value>org.apache.hadoop.hbase.backup.regionserver.LogRollRegionServerProcedureManager,...</value></property><property><name>hbase.coprocessor.region.classes</name><value>org.apache.hadoop.hbase.backup.BackupObserver,...</value></property><property><name>hbase.master.hfilecleaner.plugins</name><value>org.apache.hadoop.hbase.backup.BackupHFileCleaner,...</value></property>
83. Backup and Restore commands
This covers the command-line utilities that administrators would run to create, restore, and merge backups. Tools to inspect details on specific backup sessions is covered in the next section, Administration of Backup Images.
Run the command hbase backup help <command> to access the online help that provides basic information about a command and its options. The below information is captured in this help message for each command.
83.1. Creating a Backup Image
| |
For HBase clusters also using Apache Phoenix: include the SQL system catalog tables in the backup. In the event that you need to restore the HBase backup, access to the system catalog tables enable you to resume Phoenix interoperability with the restored data.
|
The first step in running the backup and restore utilities is to perform a full backup and to store the data in a separate image from the source. At a minimum, you must do this to get a baseline before you can rely on incremental backups.
Run the following command as HBase superuser:
hbase backup create <type> <backup_path>
After the command finishes running, the console prints a SUCCESS or FAILURE status message. The SUCCESS message includes a backup ID. The backup ID is the Unix time (also known as Epoch time) that the HBase master received the backup request from the client.
| |
Record the backup ID that appears at the end of a successful backup. In case the source cluster fails and you need to recover the dataset with a restore operation, having the backup ID readily available can save time.
|
83.1.1. Positional Command-Line Arguments
type
The type of backup to execute: full or incremental. As a reminder, an incremental backup requires a full backup to already exist.
backup_path
The backup_path argument specifies the full filesystem URI of where to store the backup image. Valid prefixes are hdfs:, webhdfs:, s3a: or other compatible Hadoop File System implementations.
83.1.2. Named Command-Line Arguments
-t
A comma-separated list of tables to back up. If no tables are specified, all tables are backed up. No regular-expression or wildcard support is present; all table names must be explicitly listed. See Backup Sets for more information about peforming operations on collections of tables. Mutually exclusive with the -s option; one of these named options are required.
-s
Identify tables to backup based on a backup set. See Using Backup Sets for the purpose and usage of backup sets. Mutually exclusive with the -t option.
-w
(Optional) Specifies the number of parallel workers to copy data to backup destination. Backups are currently executed by MapReduce jobs so this value corresponds to the number of Mappers that will be spawned by the job.
-b
(Optional) Specifies the bandwidth of each worker in MB per second.
-d
(Optional) Enables “DEBUG” mode which prints additional logging about the backup creation.
-q
(Optional) Allows specification of the name of a YARN queue which the MapReduce job to create the backup should be executed in. This option is useful to prevent backup tasks from stealing resources away from other MapReduce jobs of high importance.
83.1.3. Example usage
$ hbase backup create full hdfs://host5:8020/data/backup -t SALES2,SALES3 -w 3
This command creates a full backup image of two tables, SALES2 and SALES3, in the HDFS instance who NameNode is host5:8020 in the path /data/backup. The -w option specifies that no more than three parallel works complete the operation.
83.2. Restoring a Backup Image
Run the following command as an HBase superuser. You can only restore a backup on a running HBase cluster because the data must be redistributed the RegionServers for the operation to complete successfully.
hbase restore <backup_path> <backup_id>
83.2.1. Positional Command-Line Arguments
backup_path
The backup_path argument specifies the full filesystem URI of where to store the backup image. Valid prefixes are hdfs:, webhdfs:, s3a: or other compatible Hadoop File System implementations.
backup_id
The backup ID that uniquely identifies the backup image to be restored.
83.2.2. Named Command-Line Arguments
-t
A comma-separated list of tables to restore. See Backup Sets for more information about peforming operations on collections of tables. Mutually exclusive with the -s option; one of these named options are required.
-s
Identify tables to backup based on a backup set. See Using Backup Sets for the purpose and usage of backup sets. Mutually exclusive with the -t option.
-q
(Optional) Allows specification of the name of a YARN queue which the MapReduce job to create the backup should be executed in. This option is useful to prevent backup tasks from stealing resources away from other MapReduce jobs of high importance.
-c
(Optional) Perform a dry-run of the restore. The actions are checked, but not executed.
-m
(Optional) A comma-separated list of tables to restore into. If this option is not provided, the original table name is used. When this option is provided, there must be an equal number of entries provided in the -t option.
-o
(Optional) Overwrites the target table for the restore if the table already exists.
83.2.3. Example of Usage
hbase restore /tmp/backup_incremental backupId_1467823988425 -t mytable1,mytable2
This command restores two tables of an incremental backup image. In this example: • /tmp/backup_incremental is the path to the directory containing the backup image. • backupId_1467823988425 is the backup ID. • mytable1 and mytable2 are the names of tables in the backup image to be restored.
83.3. Merging Incremental Backup Images
This command can be used to merge two or more incremental backup images into a single incremental backup image. This can be used to consolidate multiple, small incremental backup images into a single larger incremental backup image. This command could be used to merge hourly incremental backups into a daily incremental backup image, or daily incremental backups into a weekly incremental backup.
$ hbase backup merge <backup_ids>
83.3.1. Positional Command-Line Arguments
backup_ids
A comma-separated list of incremental backup image IDs that are to be combined into a single image.
83.3.2. Named Command-Line Arguments
None.
83.3.3. Example usage
$ hbase backup merge backupId_1467823988425,backupId_1467827588425
83.4. Using Backup Sets
Backup sets can ease the administration of HBase data backups and restores by reducing the amount of repetitive input of table names. You can group tables into a named backup set with the hbase backup set add command. You can then use the -set option to invoke the name of a backup set in the hbase backup create or hbase restore rather than list individually every table in the group. You can have multiple backup sets.
Note the differentiation between the
hbase backup set addcommand and the -set option. Thehbase backup set addcommand must be run before using the-setoption in a different command because backup sets must be named and defined before using backup sets as a shortcut.
If you run the hbase backup set add command and specify a backup set name that does not yet exist on your system, a new set is created. If you run the command with the name of an existing backup set name, then the tables that you specify are added to the set.
In this command, the backup set name is case-sensitive.
The metadata of backup sets are stored within HBase. If you do not have access to the original HBase cluster with the backup set metadata, then you must specify individual table names to restore the data.
To create a backup set, run the following command as the HBase superuser:
$ hbase backup set <subcommand> <backup_set_name> <tables>
83.4.1. Backup Set Subcommands
The following list details subcommands of the hbase backup set command.
You must enter one (and no more than one) of the following subcommands after hbase backup set to complete an operation. Also, the backup set name is case-sensitive in the command-line utility.
add
Adds table[s] to a backup set. Specify a backup_set_name value after this argument to create a backup set.
remove
Removes tables from the set. Specify the tables to remove in the tables argument.
list
Lists all backup sets.
describe
Displays a description of a backup set. The information includes whether the set has full or incremental backups, start and end times of the backups, and a list of the tables in the set. This subcommand must precede a valid value for the backup_set_name value.
delete
Deletes a backup set. Enter the value for the backup_set_name option directly after the hbase backup set delete command.
83.4.2. Positional Command-Line Arguments
backup_set_name
Use to assign or invoke a backup set name. The backup set name must contain only printable characters and cannot have any spaces.
tables
List of tables (or a single table) to include in the backup set. Enter the table names as a comma-separated list. If no tables are specified, all tables are included in the set.
Maintain a log or other record of the case-sensitive backup set names and the corresponding tables in each set on a separate or remote cluster, backup strategy. This information can help you in case of failure on the primary cluster.
83.4.3. Example of Usage
$ hbase backup set add Q1Data TEAM3,TEAM_4
Depending on the environment, this command results in one of the following actions:
If the
Q1Databackup set does not exist, a backup set containing tablesTEAM_3andTEAM_4is created.If the
Q1Databackup set exists already, the tablesTEAM_3andTEAM_4are added to theQ1Databackup set.
84. Administration of Backup Images
The hbase backup command has several subcommands that help with administering backup images as they accumulate. Most production environments require recurring backups, so it is necessary to have utilities to help manage the data of the backup repository. Some subcommands enable you to find information that can help identify backups that are relevant in a search for particular data. You can also delete backup images.
The following list details each hbase backup subcommand that can help administer backups. Run the full command-subcommand line as the HBase superuser.
84.1. Managing Backup Progress
You can monitor a running backup in another terminal session by running the hbase backup progress command and specifying the backup ID as an argument.
For example, run the following command as hbase superuser to view the progress of a backup
$ hbase backup progress <backup_id>
84.1.1. Positional Command-Line Arguments
backup_id
Specifies the backup that you want to monitor by seeing the progress information. The backupId is case-sensitive.
84.1.2. Named Command-Line Arguments
None.
84.1.3. Example usage
hbase backup progress backupId_1467823988425
84.2. Managing Backup History
This command displays a log of backup sessions. The information for each session includes backup ID, type (full or incremental), the tables in the backup, status, and start and end time. Specify the number of backup sessions to display with the optional -n argument.
$ hbase backup history <backup_id>
84.2.1. Positional Command-Line Arguments
backup_id
Specifies the backup that you want to monitor by seeing the progress information. The backupId is case-sensitive.
84.2.2. Named Command-Line Arguments
-n
(Optional) The maximum number of backup records (Default: 10).
-p
The full filesystem URI of where backup images are stored.
-s
The name of the backup set to obtain history for. Mutually exclusive with the -t option.
-t
The name of table to obtain history for. Mutually exclusive with the -s option.
84.2.3. Example usage
$ hbase backup history$ hbase backup history -n 20$ hbase backup history -t WebIndexRecords
84.3. Describing a Backup Image
This command can be used to obtain information about a specific backup image.
$ hbase backup describe <backup_id>
84.3.1. Positional Command-Line Arguments
backup_id
The ID of the backup image to describe.
84.3.2. Named Command-Line Arguments
None.
84.3.3. Example usage
$ hbase backup describe backupId_1467823988425
84.4. Deleting a Backup Image
This command can be used to delete a backup image which is no longer needed.
$ hbase backup delete <backup_id>
84.4.1. Positional Command-Line Arguments
backup_id
The ID to the backup image which should be deleted.
84.4.2. Named Command-Line Arguments
None.
84.4.3. Example usage
$ hbase backup delete backupId_1467823988425
84.5. Backup Repair Command
This command attempts to correct any inconsistencies in persisted backup metadata which exists as the result of software errors or unhandled failure scenarios. While the backup implementation tries to correct all errors on its own, this tool may be necessary in the cases where the system cannot automatically recover on its own.
$ hbase backup repair
84.5.1. Positional Command-Line Arguments
None.
84.6. Named Command-Line Arguments
None.
84.6.1. Example usage
$ hbase backup repair
85. Configuration keys
The backup and restore feature includes both required and optional configuration keys.
85.1. Required properties
hbase.backup.enable: Controls whether or not the feature is enabled (Default: false). Set this value to true.
hbase.master.logcleaner.plugins: A comma-separated list of classes invoked when cleaning logs in the HBase Master. Set this value to org.apache.hadoop.hbase.backup.master.BackupLogCleaner or append it to the current value.
hbase.procedure.master.classes: A comma-separated list of classes invoked with the Procedure framework in the Master. Set this value to org.apache.hadoop.hbase.backup.master.LogRollMasterProcedureManager or append it to the current value.
hbase.procedure.regionserver.classes: A comma-separated list of classes invoked with the Procedure framework in the RegionServer. Set this value to org.apache.hadoop.hbase.backup.regionserver.LogRollRegionServerProcedureManager or append it to the current value.
hbase.coprocessor.region.classes: A comma-separated list of RegionObservers deployed on tables. Set this value to org.apache.hadoop.hbase.backup.BackupObserver or append it to the current value.
hbase.master.hfilecleaner.plugins: A comma-separated list of HFileCleaners deployed on the Master. Set this value to org.apache.hadoop.hbase.backup.BackupHFileCleaner or append it to the current value.
85.2. Optional properties
hbase.backup.system.ttl: The time-to-live in seconds of data in the hbase:backup tables (default: forever). This property is only relevant prior to the creation of the hbase:backup table. Use the alter command in the HBase shell to modify the TTL when this table already exists. See the below section for more details on the impact of this configuration property.
hbase.backup.attempts.max: The number of attempts to perform when taking hbase table snapshots (default: 10).
hbase.backup.attempts.pause.ms: The amount of time to wait between failed snapshot attempts in milliseconds (default: 10000).
hbase.backup.logroll.timeout.millis: The amount of time (in milliseconds) to wait for RegionServers to execute a WAL rolling in the Master’s procedure framework (default: 30000).
86. Best Practices
86.1. Formulate a restore strategy and test it.
Before you rely on a backup and restore strategy for your production environment, identify how backups must be performed, and more importantly, how restores must be performed. Test the plan to ensure that it is workable. At a minimum, store backup data from a production cluster on a different cluster or server. To further safeguard the data, use a backup location that is at a different physical location.
If you have a unrecoverable loss of data on your primary production cluster as a result of computer system issues, you may be able to restore the data from a different cluster or server at the same site. However, a disaster that destroys the whole site renders locally stored backups useless. Consider storing the backup data and necessary resources (both computing capacity and operator expertise) to restore the data at a site sufficiently remote from the production site. In the case of a catastrophe at the whole primary site (fire, earthquake, etc.), the remote backup site can be very valuable.
86.2. Secure a full backup image first.
As a baseline, you must complete a full backup of HBase data at least once before you can rely on incremental backups. The full backup should be stored outside of the source cluster. To ensure complete dataset recovery, you must run the restore utility with the option to restore baseline full backup. The full backup is the foundation of your dataset. Incremental backup data is applied on top of the full backup during the restore operation to return you to the point in time when backup was last taken.
86.3. Define and use backup sets for groups of tables that are logical subsets of the entire dataset.
You can group tables into an object called a backup set. A backup set can save time when you have a particular group of tables that you expect to repeatedly back up or restore.
When you create a backup set, you type table names to include in the group. The backup set includes not only groups of related tables, but also retains the HBase backup metadata. Afterwards, you can invoke the backup set name to indicate what tables apply to the command execution instead of entering all the table names individually.
86.4. Document the backup and restore strategy, and ideally log information about each backup.
Document the whole process so that the knowledge base can transfer to new administrators after employee turnover. As an extra safety precaution, also log the calendar date, time, and other relevant details about the data of each backup. This metadata can potentially help locate a particular dataset in case of source cluster failure or primary site disaster. Maintain duplicate copies of all documentation: one copy at the production cluster site and another at the backup location or wherever it can be accessed by an administrator remotely from the production cluster.
87. Scenario: Safeguarding Application Datasets on Amazon S3
This scenario describes how a hypothetical retail business uses backups to safeguard application data and then restore the dataset after failure.
The HBase administration team uses backup sets to store data from a group of tables that have interrelated information for an application called green. In this example, one table contains transaction records and the other contains customer details. The two tables need to be backed up and be recoverable as a group.
The admin team also wants to ensure daily backups occur automatically.
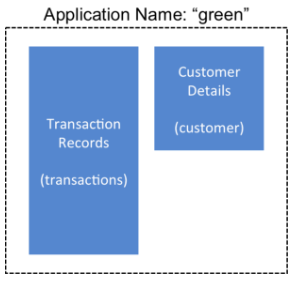 Figure 7. Tables Composing The Backup Set
Figure 7. Tables Composing The Backup Set
The following is an outline of the steps and examples of commands that are used to backup the data for the green application and to recover the data later. All commands are run when logged in as HBase superuser.
- A backup set called green_set is created as an alias for both the transactions table and the customer table. The backup set can be used for all operations to avoid typing each table name. The backup set name is case-sensitive and should be formed with only printable characters and without spaces.
$ hbase backup set add green_set transactions$ hbase backup set add green_set customer
- The first backup of green_set data must be a full backup. The following command example shows how credentials are passed to Amazon S3 and specifies the file system with the s3a: prefix.
$ ACCESS_KEY=ABCDEFGHIJKLMNOPQRST$ SECRET_KEY=123456789abcdefghijklmnopqrstuvwxyzABCD$ sudo -u hbase hbase backup create full\s3a://$ACCESS_KEY:SECRET_KEY@prodhbasebackups/backups -s green_set
- Incremental backups should be run according to a schedule that ensures essential data recovery in the event of a catastrophe. At this retail company, the HBase admin team decides that automated daily backups secures the data sufficiently. The team decides that they can implement this by modifying an existing Cron job that is defined in
/etc/crontab. Consequently, IT modifies the Cron job by adding the following line:@daily hbase hbase backup create incremental s3a://$ACCESS_KEY:$SECRET_KEY@prodhbasebackups/backups -s green_set
- A catastrophic IT incident disables the production cluster that the green application uses. An HBase system administrator of the backup cluster must restore the green_set dataset to the point in time closest to the recovery objective.
If the administrator of the backup HBase cluster has the backup ID with relevant details in accessible records, the following search with the
hdfs dfs -lscommand and manually scanning the backup ID list can be bypassed. Consider continuously maintaining and protecting a detailed log of backup IDs outside the production cluster in your environment.
The HBase administrator runs the following command on the directory where backups are stored to print the list of successful backup IDs on the console:
`hdfs dfs -ls -t /prodhbasebackups/backups`
- The admin scans the list to see which backup was created at a date and time closest to the recovery objective. To do this, the admin converts the calendar timestamp of the recovery point in time to Unix time because backup IDs are uniquely identified with Unix time. The backup IDs are listed in reverse chronological order, meaning the most recent successful backup appears first.
The admin notices that the following line in the command output corresponds with the green_set backup that needs to be restored:/prodhbasebackups/backups/backup_1467823988425`
- The admin restores green_set invoking the backup ID and the -overwrite option. The -overwrite option truncates all existing data in the destination and populates the tables with data from the backup dataset. Without this flag, the backup data is appended to the existing data in the destination. In this case, the admin decides to overwrite the data because it is corrupted.
$ sudo -u hbase hbase restore -s green_set \s3a://$ACCESS_KEY:$SECRET_KEY@prodhbasebackups/backups backup_1467823988425 \ -overwrite
88. Security of Backup Data
With this feature which makes copying data to remote locations, it’s important to take a moment to clearly state the procedural concerns that exist around data security. Like the HBase replication feature, backup and restore provides the constructs to automatically copy data from within a corporate boundary to some system outside of that boundary. It is imperative when storing sensitive data that with backup and restore, much less any feature which extracts data from HBase, the locations to which data is being sent has undergone a security audit to ensure that only authenticated users are allowed to access that data.
For example, with the above example of backing up data to S3, it is of the utmost importance that the proper permissions are assigned to the S3 bucket to ensure that only a minimum set of authorized users are allowed to access this data. Because the data is no longer being accessed via HBase, and its authentication and authorization controls, we must ensure that the filesystem storing that data is providing a comparable level of security. This is a manual step which users must implement on their own.
89. Technical Details of Incremental Backup and Restore
HBase incremental backups enable more efficient capture of HBase table images than previous attempts at serial backup and restore solutions, such as those that only used HBase Export and Import APIs. Incremental backups use Write Ahead Logs (WALs) to capture the data changes since the previous backup was created. A WAL roll (create new WALs) is executed across all RegionServers to track the WALs that need to be in the backup.
After the incremental backup image is created, the source backup files usually are on same node as the data source. A process similar to the DistCp (distributed copy) tool is used to move the source backup files to the target file systems. When a table restore operation starts, a two-step process is initiated. First, the full backup is restored from the full backup image. Second, all WAL files from incremental backups between the last full backup and the incremental backup being restored are converted to HFiles, which the HBase Bulk Load utility automatically imports as restored data in the table.
You can only restore on a live HBase cluster because the data must be redistributed to complete the restore operation successfully.
90. A Warning on File System Growth
As a reminder, incremental backups are implemented via retaining the write-ahead logs which HBase primarily uses for data durability. Thus, to ensure that all data needing to be included in a backup is still available in the system, the HBase backup and restore feature retains all write-ahead logs since the last backup until the next incremental backup is executed.
Like HBase Snapshots, this can have an expectedly large impact on the HDFS usage of HBase for high volume tables. Take care in enabling and using the backup and restore feature, specifically with a mind to removing backup sessions when they are not actively being used.
The only automated, upper-bound on retained write-ahead logs for backup and restore is based on the TTL of the hbase:backup system table which, as of the time this document is written, is infinite (backup table entries are never automatically deleted). This requires that administrators perform backups on a schedule whose frequency is relative to the amount of available space on HDFS (e.g. less available HDFS space requires more aggressive backup merges and deletions). As a reminder, the TTL can be altered on the hbase:backup table using the alter command in the HBase shell. Modifying the configuration property hbase.backup.system.ttl in hbase-site.xml after the system table exists has no effect.
91. Capacity Planning
When designing a distributed system deployment, it is critical that some basic mathmatical rigor is executed to ensure sufficient computational capacity is available given the data and software requirements of the system. For this feature, the availability of network capacity is the largest bottleneck when estimating the performance of some implementation of backup and restore. The second most costly function is the speed at which data can be read/written.
91.1. Full Backups
To estimate the duration of a full backup, we have to understand the general actions which are invoked:
Write-ahead log roll on each RegionServer: ones to tens of seconds per RegionServer in parallel. Relative to the load on each RegionServer.
Take an HBase snapshot of the table(s): tens of seconds. Relative to the number of regions and files that comprise the table.
Export the snapshot to the destination: see below. Relative to the size of the data and the network bandwidth to the destination.
To approximate how long the final step will take, we have to make some assumptions on hardware. Be aware that these will not be accurate for your system — these are numbers that your or your administrator know for your system. Let’s say the speed of reading data from HDFS on a single node is capped at 80MB/s (across all Mappers that run on that host), a modern network interface controller (NIC) supports 10Gb/s, the top-of-rack switch can handle 40Gb/s, and the WAN between your clusters is 10Gb/s. This means that you can only ship data to your remote at a speed of 1.25GB/s — meaning that 16 nodes (1.25 * 1024 / 80 = 16) participating in the ExportSnapshot should be able to fully saturate the link between clusters. With more nodes in the cluster, we can still saturate the network but at a lesser impact on any one node which helps ensure local SLAs are made. If the size of the snapshot is 10TB, this would full backup would take in the ballpark of 2.5 hours (10 * 1024 / 1.25 / (60 * 60) = 2.23hrs)
As a general statement, it is very likely that the WAN bandwidth between your local cluster and the remote storage is the largest bottleneck to the speed of a full backup.
When the concern is restricting the computational impact of backups to a “production system”, the above formulas can be reused with the optional command-line arguments to hbase backup create: -b, -w, -q. The -b option defines the bandwidth at which each worker (Mapper) would write data. The -w argument limits the number of workers that would be spawned in the DistCp job. The -q allows the user to specify a YARN queue which can limit the specific nodes where the workers will be spawned — this can quarantine the backup workers performing the copy to a set of non-critical nodes. Relating the -b and -w options to our earlier equations: -b would be used to restrict each node from reading data at the full 80MB/s and -w is used to limit the job from spawning 16 worker tasks.
91.2. Incremental Backup
Like we did for full backups, we have to understand the incremental backup process to approximate its runtime and cost.
Identify new write-ahead logs since last full or incremental backup: negligible. Apriori knowledge from the backup system table(s).
Read, filter, and write “minimized” HFiles equivalent to the WALs: dominated by the speed of writing data. Relative to write speed of HDFS.
DistCp the HFiles to the destination: see above.
For the second step, the dominating cost of this operation would be the re-writing the data (under the assumption that a majority of the data in the WAL is preserved). In this case, we can assume an aggregate write speed of 30MB/s per node. Continuing our 16-node cluster example, this would require approximately 15 minutes to perform this step for 50GB of data (50 * 1024 / 60 / 60 = 14.2). The amount of time to start the DistCp MapReduce job would likely dominate the actual time taken to copy the data (50 / 1.25 = 40 seconds) and can be ignored.
92. Limitations of the Backup and Restore Utility
Serial backup operations
Backup operations cannot be run concurrently. An operation includes actions like create, delete, restore, and merge. Only one active backup session is supported. HBASE-16391 will introduce multiple-backup sessions support.
No means to cancel backups
Both backup and restore operations cannot be canceled. (HBASE-15997, HBASE-15998). The workaround to cancel a backup would be to kill the client-side backup command (control-C), ensure all relevant MapReduce jobs have exited, and then run the hbase backup repair command to ensure the system backup metadata is consistent.
Backups can only be saved to a single location
Copying backup information to multiple locations is an exercise left to the user. HBASE-15476 will introduce the ability to specify multiple-backup destinations intrinsically.
HBase superuser access is required
Only an HBase superuser (e.g. hbase) is allowed to perform backup/restore, can pose a problem for shared HBase installations. Current mitigations would require coordination with system administrators to build and deploy a backup and restore strategy (HBASE-14138).
Backup restoration is an online operation
To perform a restore from a backup, it requires that the HBase cluster is online as a caveat of the current implementation (HBASE-16573).
Some operations may fail and require re-run
The HBase backup feature is primarily client driven. While there is the standard HBase retry logic built into the HBase Connection, persistent errors in executing operations may propagate back to the client (e.g. snapshot failure due to region splits). The backup implementation should be moved from client-side into the ProcedureV2 framework in the future which would provide additional robustness around transient/retryable failures. The hbase backup repair command is meant to correct states which the system cannot automatically detect and recover from.
Avoidance of declaration of public API
While the Java API to interact with this feature exists and its implementation is separated from an interface, insufficient rigor has been applied to determine if it is exactly what we intend to ship to users. As such, it is marked as for a Private audience with the expectation that, as users begin to try the feature, there will be modifications that would necessitate breaking compatibility (HBASE-17517).
Lack of global metrics for backup and restore
Individual backup and restore operations contain metrics about the amount of work the operation included, but there is no centralized location (e.g. the Master UI) which present information for consumption (HBASE-16565).

若有收获,就点个赞吧
0 人点赞
