es倒排索引
es底层依赖Lucene,而 Lucene 能实现全文搜索主要是因为它实现了倒排索引的查询结构。使用倒排索引
- 通过分词器将每个文档内容域拆分成单独的词(称之为词条或term),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。
比如有一篇文章有三句话
java is the best language
php is the best language
JavaScript is the best language
怎么建立倒排索引,我们提炼出来这三句话里面所有的单词,包括java、php、js is
这些词条组成一个列表,这个列表就是词典。
词典中的每个词条都有一个映射,映射的内容就是在这三句话中,词条出现在哪里了,比如java就对应了他出现在第一句话
is 对应了他在三句话都出现了。
而词典和词典对应词条在文章中出现的位置组合起来就叫倒排表,所有的倒排表加到一起就是倒排文件。
这时候我要查php在这篇文章哪里出现了?我只要在倒排表里面查询php这个词条,就可以很轻易地找到他到底出现在哪句话当中。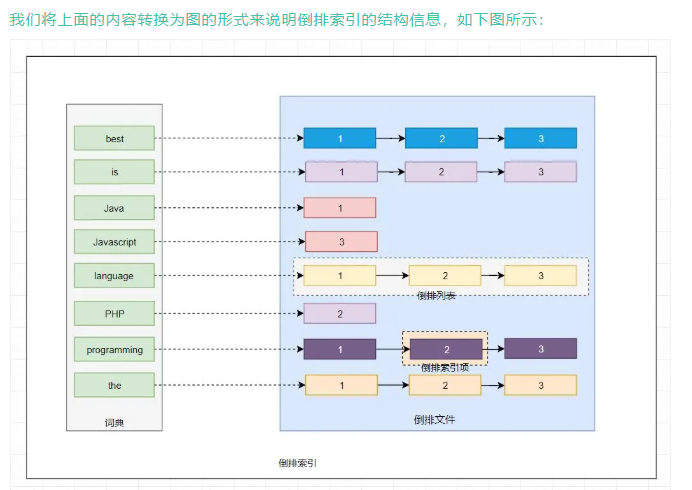
倒排索引主要由两个部分组成:
- 词典:词条term的集合
- 倒排文件:所有单词的倒排表(单词 —-> 文档中出现的位置)
es发现机制
es是一种p2p点对点的分布式系统架构,不是master-slave主从架构的分布式系统。集群中的每个node是直接跟其他节点进行通信的,几乎所有的API操作,比如index,delete,search,等等,都不是说client跟master通信,而是client跟任何一个node进行通信,那个node再将请求转发给对应的node来进行执行。
有两种node:master node,data node。正常情况下,就只有一个master node。master node的责任就是负责维护整个集群的状态信息,如果每次cluster state如果有改变,那么master都会负责将集群状态同步给所有的node。master node负责接收所有的cluster state相关的变化信息,然后将这个改变后的最新的cluster state推动给集群中所有的data node,集群中所有的node都有一份完整的cluster state。
可以提前设置一个节点能不能成为master,如果设置能成为,他就有机会成为master,如果给了他机会他不中用,就只能当date node。
在不同机器上的节点是怎么互相发现组成一个集群的呢?
主要依靠中间的公共节点,一般在配置的时候,会把公共节点的地址配置在普通节点的配置文件中,普通节点进程启动之后就会主动ping公共节点。普通节点只要和集群上的任何一个节点搭上关系,就可以获取整个节点的状态信息,从而联系上master将他拉入集群。
选举master的过程,每次选举的时候,每个节点都把自己所知道的可以成为master的节点按照nodeid字典排序,默认第一个就是自己要选的master节点,如果某个节点的投票数达到一定的值(可以成为master节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。
es为什么会出现脑裂问题
什么是脑裂问题
- 网络问题
- 由于某些节点之间的网络通信出现问题,导致一些节点认为master节点已经挂了,所以有重新选举了新的master节点,从而导致集群信息混乱。
节点负载过大
网络:保证网络可靠
- 针对负载:将master节点与data节点分离,准备几台机器加入集群中,这几台机器只能充当master节点,不可担任存储和搜索的角色,降低master的负载,提高可用性
- 修改集群参数
- 修改ping_timeout:默认值3s,一个节点会认为,如果master节点在3秒之内没有应答,那么这个节点就是死掉了,这时候就会想重新选master,而增加这个值,会增加节点等待响应的时间,从一定程度上会减少误判。
- minimum_master_nodes:最小master节点数量,这个参数表示,一个节点需要看到的具有master节点资格的最小数量,然后才能在集群中做操作。 官方推荐值是(n/2) + 1, n是具有master资格的节点的数量

若有收获,就点个赞吧
0 人点赞
