对比关系型数据库
| MySQL | ES |
|---|---|
| Database (数据库) | Index (索引) |
| Table (表) | Type (类型) |
| Row (行) | Document (文档) |
| Column (列) | Fields (字段) |
下图举例为:一个拥有三个节点,有一个索引,该索引有2个主分片,每个主分片有2个副本分片的集群。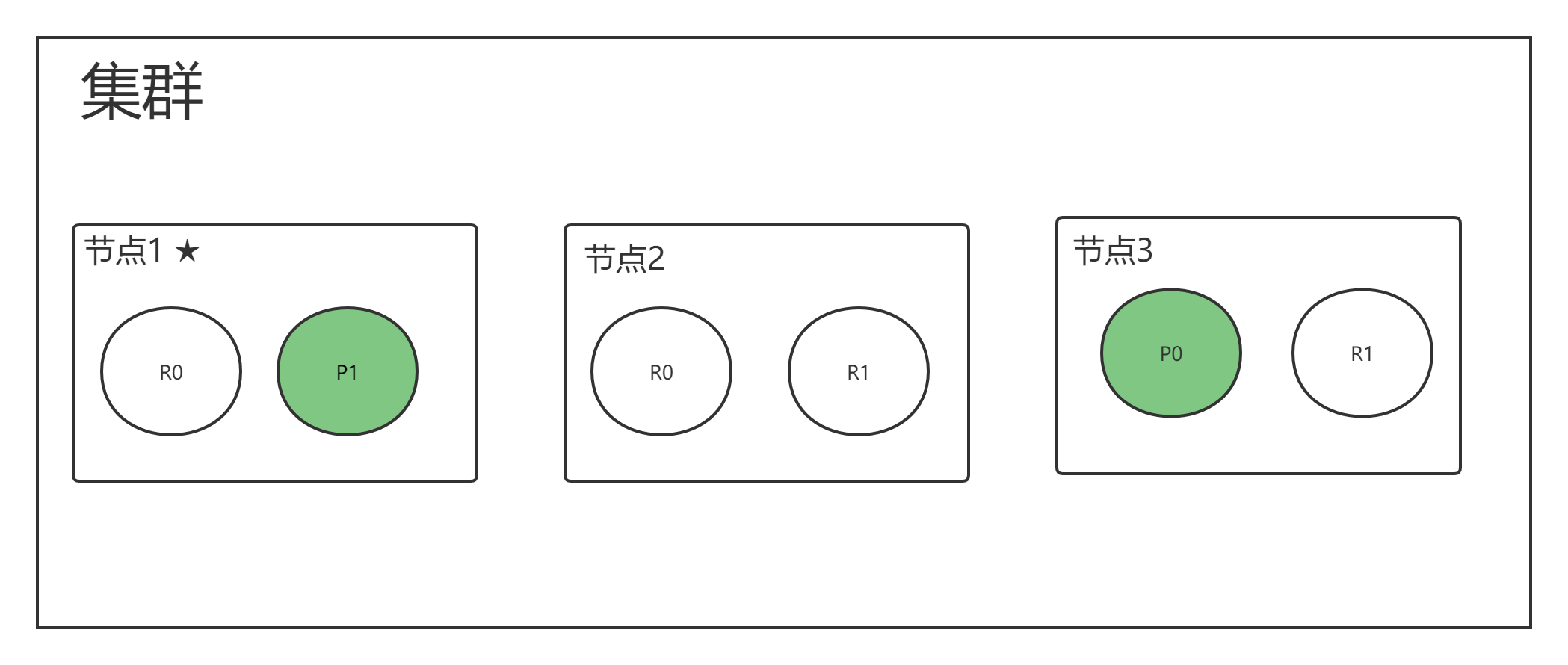
索引(index)
从逻辑上看,索引是一些具有相似结构的文档集合。
索引实际上是指向一个或者多个物理 分片 的 逻辑命名空间 。我们的文档被存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交互。
分片(shard)
将索引划分成多分,是索引的物理实现,每一份就是一个分片。
每个分片又是一个 Lucene引擎,具有全部的搜索能力。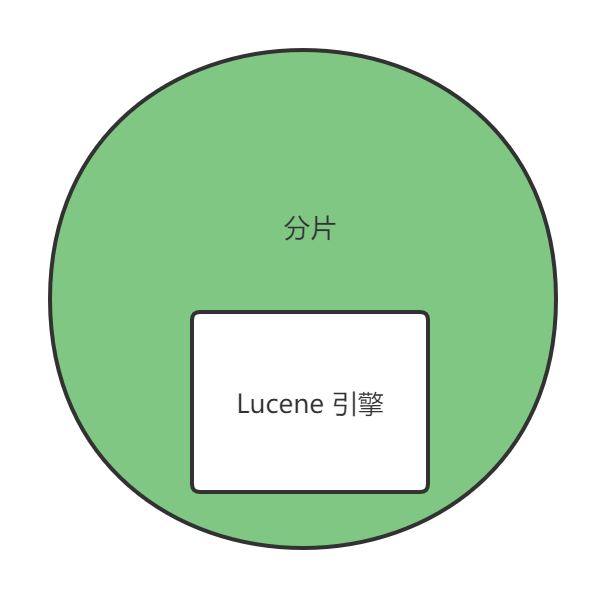
一个分片是一个底层的工作单元,仅保存了全部数据中的一部分,同时一个分片也是一个 Lucene 的实例,也就是一个分片就是一个完整的搜索引擎。
Elasticsearch 是利用分片将数据分发到集群内各处的。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。 当你的集群规模扩大或者缩小时, Elasticsearch 会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里。
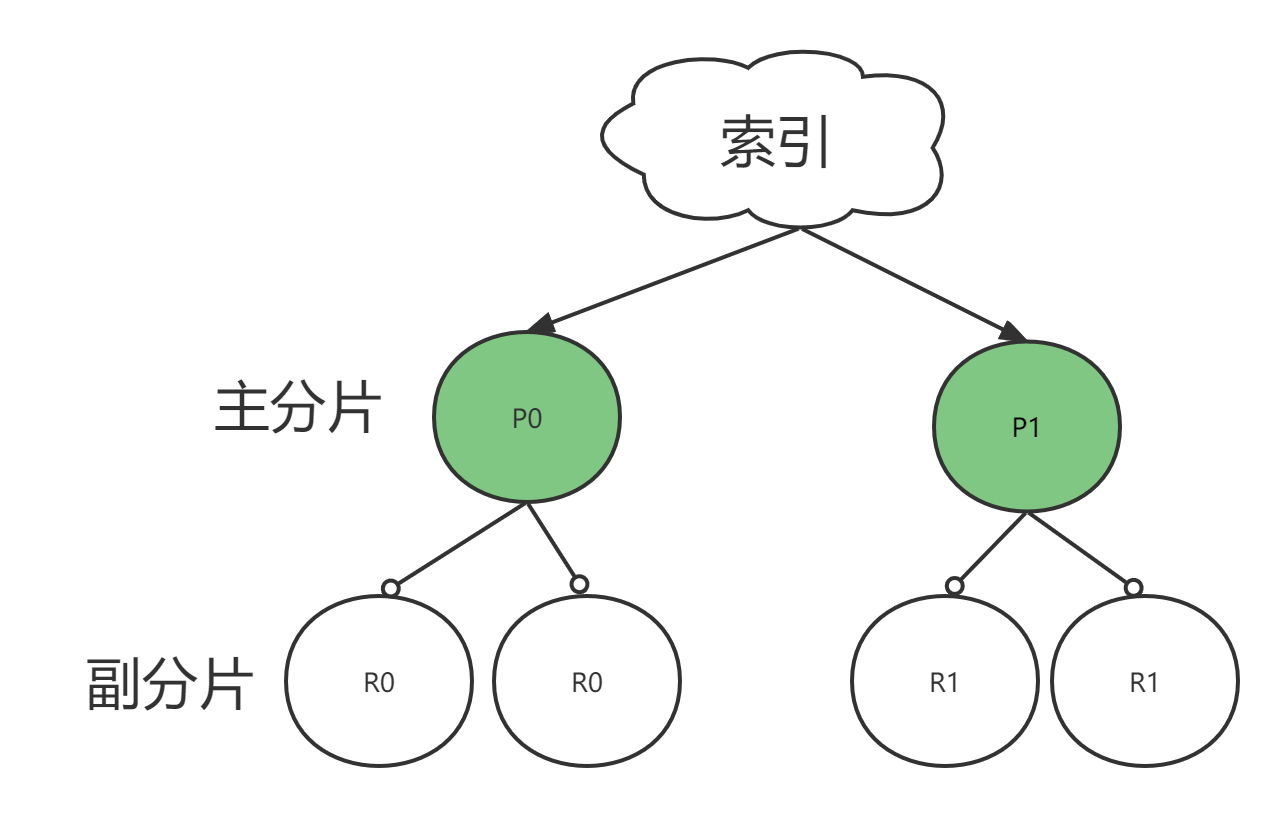
一个 Lucene 索引 在 ES 被称为 分片。 一个 ES 索引是 分片 的集合。
当 ES 在索引中搜索的时候,它发送查询到每一个属于索引的分片(Lucene 索引),然后合并每个分片的结果到一个全局的结果集。
一个分片可以是 主 分片或者 副本 分片。
主分片(Primary Shard)
- 可执行文档的读、写操作
- 用以解决数据水平扩展的问题。通过主分片,可以将数据分布到集群内的所有节点之上
- 索引内任意一个文档都归属于一个主分片
- 主分片的数目决定着索引能够保存的最大数据量(理论最大能够存储 Integer.MAX_VALUE - 128)
- 创建索引时默认为 1,也可指定数量,但后续不可修改数量,涉及路由算法
- 7.0 默认为1
副本分片(Replicas shard)
- 可执行读文档操作
- 一个主分片的复制。应用于 故障转移 和 提高搜索性能。
- 在对应主分片失败的情况下,提供了高可用。这也是 主分片 不与 副分片 在同一节点运行的原因。
- 扩展 搜索量/吞吐量,因为搜索可以在所有 副本 上进行。
- 创建索引时默认为 1,后续可修改数量,
- 增加副本数,还可以在一定成都的上提高服务的可用性(读取的吞吐)
- 7.0 默认为0
注意:同一个分片的主分片、副本分片不会分配在同一个节点
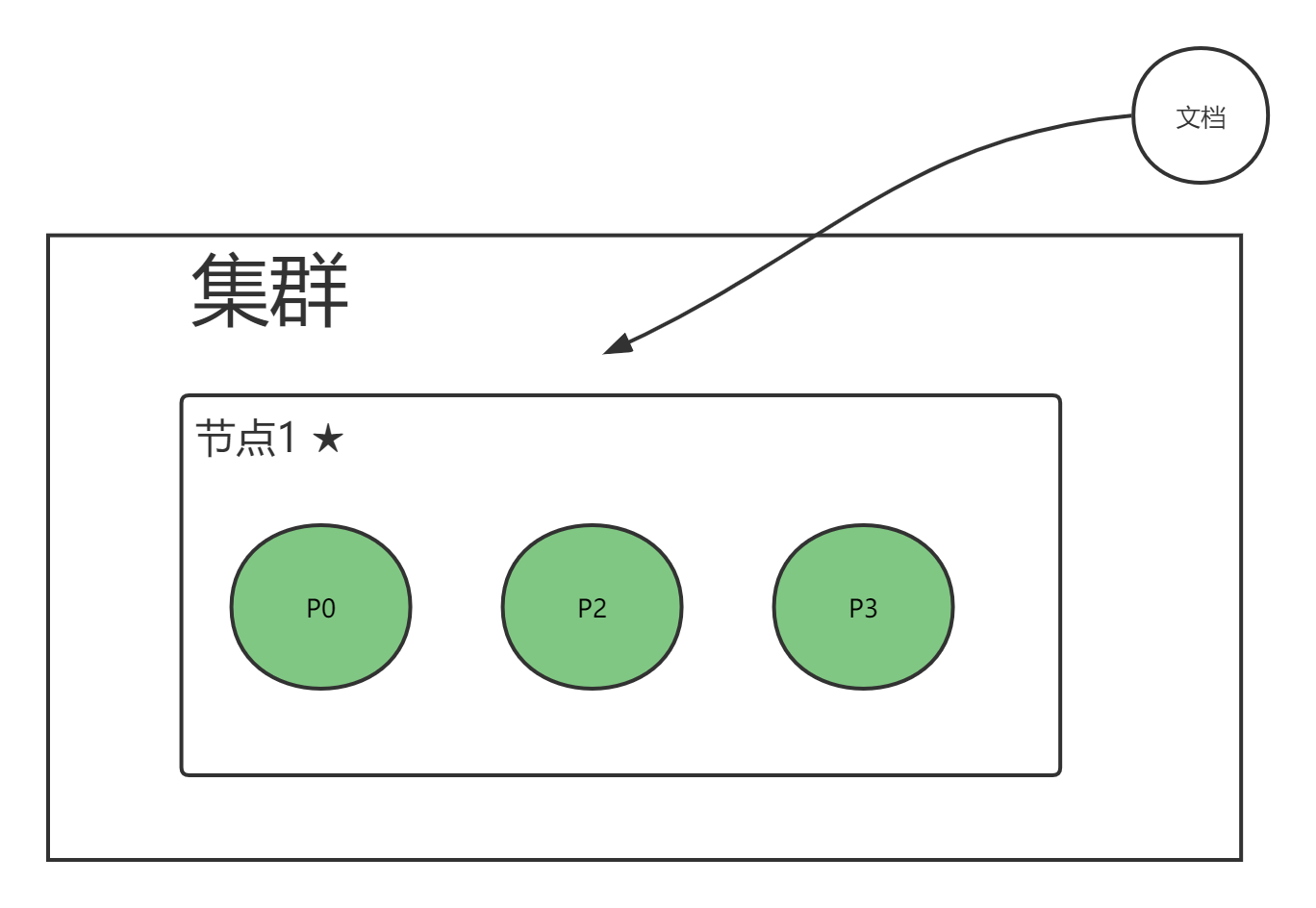
上图中,如果节点1挂了,R0无法起到替换 P1 的作用,所以同一个分片的主副分片不会放在一个节点,上图主要是做解释作用,真正情况节点1只有 P1, R0属于未分配的分配,此时集群状态是 yellow
上图中,节点1 挂了,节点2的 R0里提升成 主节点,起到了高可用的作用。
路由计算
当一个索引具有多个分片时,我怎么才能知道我操作的文档,具体在哪个分片上呢?
路由算法就是解决这个问题的!
算法公式:
shard = hash(_routing) % number_of_primary_shards
得出的结果就是 [0, number_of_primary_shards-1] 之间的数
- Hash 算法确保文档均匀分散到分片中
- 默认的 _routing 值是文档 id
- 可以自定制定 routing数值,例如用相同国家的商品,都分配到指定的 shard
设置 Index Settings 后, Primary数 不能随意更改的根本原因。
routing是一个可变值,默认是文档 _id,也可以设置成一个自定义值
- number_of_primary_shards 主分数,这也说明为什么在创建索引时要确认主分片数量,而且还不能更改。因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了
类型(type)
索引的类型,是逻辑上的 分类/分区。通常会为具有一组共同字段的文档定义一个类型。
索引 关联上 数据,中间不应该增加概念。
- 5.X 支持多种 type
- 6.X 只能支持一种 type
- 7.X 默认不再支持自定义 type。(默认类型:_doc)
文档(document)
索引里的一条数据。
可以是任意的 JSON 格式。
将文档写入 ES 的过程叫做 索引(Indexing)
域(field)
相当于是数据表的字段,对文档数据根据不同属性进行分类标识。
节点(node)
一个运行中的 ES 实例,包含着分片。
节点是一个 ElasticSearch 的实例
- 本质上就是一个 Java进程
- 一台机器上可以运行多个 ElasticSearch 进程,但是生产环境一般建议一台机器上只运行一个 ElasticSearch 实例
- 每一个节点都有名字,通过配置文件配置,或者启动的时候 -E node.name=node1 指定
- 每一个节点在启动之后,会分配一个 UID,保存在 data 目录下
节点能力:
- 我们可以发送请求到集群中的任一节点。
- 每个节点都有能力处理任意请求。
- 每个节点都知道集群中任一文档位置,所以可以直接将请求转发到需要的节点上。
- 接收请求的节点叫做 协调节点 (coordinating node)
- 当发送请求的时候, 为了扩展负载,更好的做法是轮询集群中所有的节点。
集群节点特征:
- 所有节点共同承担数据和负载的压力
- 当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据
- 当你的集群规模扩大或者缩小时, Elasticsearch 会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里。
主节点特征:
- 负责管理集群范围内的所有变更,例如索引、节点的变动(新增、删除)。
- 不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈
- 任何节点都可以成为主节点
作为用户,我们可以将请求发送到 集群中的任何节点 ,包括主节点。 每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的。
Master-eligible nodes 和 Master Node
- 每个节点启动后,默认就是一个 Master eligible 节点
- 可以设置 node.master: false 禁止
- Master-eligible节点可以参加选主流程,成为 Master 节点
- 当第一个节点启动时候,它会将自己选举成 Master 节点
- 每个节点上都保存了集群的状态,只有 Master 节点才能修改集群的状态信息
- 集群状态(Cluster State),维护了一个集群中,必要的信息
- 所有的节点信息
- 所有的索引和其相关的 Mapping 与 Setting 信息
- 分片的路由信息
- 任意节点都能修改,会导致数据的不一致性
- 集群状态(Cluster State),维护了一个集群中,必要的信息
Data Node & Corrdinating Node
- Data Node 数据节点
- 可以保存数据的节点,负责保存分片数据。在数据扩展上起到了至关重要的作用
- Coordinating Node 协调节点
- 负责接受 Client 的请求,将请求分发到合适的节点,最终把结果汇集到一起
- 每个节点默认都起到了 Coordinating Node 的职责
集群(cluster)
一个 或 多个 拥有相同 cluster.name 的节点。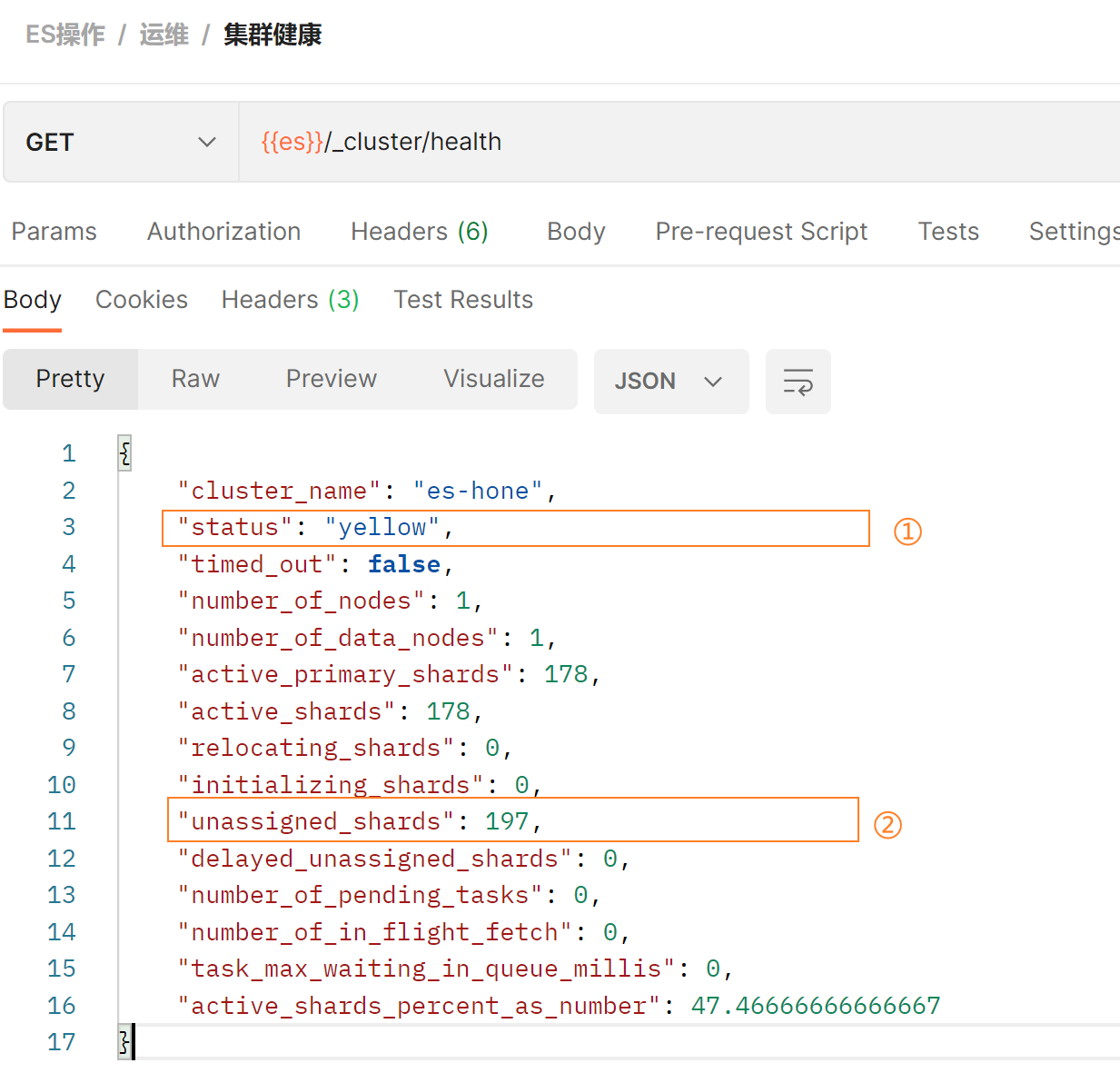
集群状态:
- Green: 健康状态,所有主副分片都可用
- Yellow:亚健康,所有主分片可用,部分副本分片不可用
- Red:不健康状态,部分主分片不可用
上图只有一个节点,197个副本分片unassigned没有分配到,在同一个节点上既保存原始数据又保存副本是没有意义的,因为一旦失去了那个节点,我们也将丢失该节点上的所有副本数据。
倒排索引(Inverted Index)
使全文检索快速的结构。
{"id": 1001,"content": "I love ShangHai"},{"id": 1002,"content": "I hava a plan"}
正排索引(forward index):
| id | content |
|---|---|
| 1001 | I love ShangHai |
| 1002 | I hava a plan |
字段类型是 Text 需要分词 的倒排索引(inverted index):
| Term | 1001 | 1002 |
|---|---|---|
| i | √ | √ |
| love | √ | |
| shanghai | √ | |
| hava | √ | |
| plan | √ |
字段类型是 KeyWord 不分词的倒排索引:
| Term | 1001 | 1002 |
|---|---|---|
| I love ShangHai | √ | |
| I hava a plan | √ |
搜索: I love
| Term | 1001 | 1002 |
|---|---|---|
| i | √ | √ |
| love | √ | |
| Total | 2 | 1 |
分析
分析(analysis)是文档被发送并加入倒排索引之前,ElasticSearch 让每个被分析字段经过一系列得处理步骤
写入的分析
搜索的分析
相关性
搜索的关键词与倒排索引内容的类似程度

若有收获,就点个赞吧
0 人点赞
