索引的”表结构”
类比关系型数据库,新建一张表时,需要先进行表结构设计(字段类型、默认值、是否非空、索引…)。
对于 ES 来说,这种 “表结构” 的概念就叫做 “映射(Mapping)”。
Mapping 类似于数据库中 schema 的概念,主要是对索引的一些设置信息,作用如下:
- 确认索引分片个数,副本分片个数(主分片个数不可更改)
- 7.x 版本默认 主分片 和 副本分片 数目都是1
- 主分片数涉及文档定位具体分片的路由算法,所以被设定成不可更改
- 确认索引的映射模式
- 新写入文档字段与Mapping的同步模式
- 定义索引中字段的信息,如字段名称、字段类型(不可更改)
- Lucene 特性,写入的倒排索引不可更改
- 定义字段倒排索引的设置(分析器、是否索引、是否储存)
参考:Kibana代码演示:Mapping创建索引
问题:索引部分信息无法更改,那有更改的需求咋办?
解答:是无法直接在原索引上进行上述的更改,可以按照新要求的结构,新建一个索引,然后将旧索引的数据,复制过去,这个复制索引数据的操作,叫做 reindex。
ES 数据类型
- 简单类型
- String:
- Text:用作全文检索
- Keyword:用作精确精索
- Date
- Integer / Byte / Long / Floating
- Boolean
- IPv4 & IPv6
- String:
- 复杂类型
- 对象类型(object)
- 嵌套对象类型(nested)
- 特殊类型
- geo_point & geo_shape
- percolator
O2 目前字段类类型选择策略:
- 字符串
- 需要全文分词检索:Text,并指定分词器,一般手动选择 ik_max_word
- 精确搜索:Keyword,默认是索引,如果不需要索引设置 index: false
- 状态值:
- Byte (1-是,0-否)
- Boolean
- 时间
- Long : 统一转成毫秒数存储,避免转化时区问题
- 金额:
- 用 Floating 里面的 scaled_float,弹性因子2位,就是 2 位小数的浮点数
- 对象 / 数组
- 嵌套对象
问题:数组是怎么回事?不是有 对象类型 吗,这个 嵌套类型 是干嘛的?
先说明数组问题: ElasticSearch 没有数组类型,任意的字段都可以包含0个或者多个值,就是说任意的字段,只要写入多个类型相同的值,就自动转成数组存储,开箱即用。 在上述数组的特性之下,对象类型的数组,数组内每个对象在底层都不是分开的,对象间的关系丢失,所以才有嵌套对象。对象仅适用于一对一的关系,当提升成对象数组时,会出现处理结果与预期不合的现象,所以会有嵌套类型来解决对象类型的这种缺陷。
对象数组 vs 嵌套对象数组数据举例:
{"name_object":[{"first" : "John","last" : "Smith"},{"first" : "Alice","last" : "White"}],"name_nested":[{"first" : "John","last" : "Smith"},{"first" : "Alice","last" : "White"}]}
两者在底层的存储结构:
对于 object 数组,ES底层会将其展开扁平的结构,此时 “john” 与 “smith” 的一对一关系丢失,转而变成多对多的关系
{"name_object": {"name_object.first": ["alice","john"],"name_object.last": ["smith","white"]},"name_nested": [{"first": "john","last": "smith"},{"first": "alice","last": "white"}]}
参考:Kibana演示代码:object与nested数组演示
映射模式(Dynamic Mapping)
描述文档可能具有的字段或者属性。如:字段类型、默认值、分析器、是否被索引等。
某个字段的 Mapping 属性不可改,比如某个字段指定类型为 byte,无法更新 Mapping 改成 其他类型。
动态模式
“dynamic” : “true” ,也是默认模式。
创建索引时可以不指定 Mapping,每次添加文档时,ES会对文档的字段类型进行猜测,并将信息动态更新到 Mapping 上。
类型自动识别:
| JSON 类型 | ElasticSearch 类型 |
|---|---|
| 字符串 | - 匹配日期格式,设置成 Date - 匹配数字设置为 float 或者 long,该选项默认关闭 - 设置为 Text,并且增加 keyword 子字段,默认索引字符长度 256 |
| 布尔值 | boolean |
| 浮点数 | float |
| 整数 | long |
| 对象 | Object |
| 数组 | 由第一个非空数值的类型所决定 |
| 空值 | 忽略 |
静态模式
“dynamic” : “false” ,o2现在用的模式。
创建索引时需要指定 Mapping,添加文档时,不存在 Mapping 里面的字段, ES 不会进行猜测然后动态更新到 Mapping里。
参考:Kibana演示代码:静态模式映射演示
严格模式
“dynamic” : “strict”
创建索引时需要指定 Mapping,添加文档时,存在 Mapping 里面没有的字段,会直接添加失败。
参考:Kibana演示代码:严格模式映射演示
问题:三种模式,选哪个?
O2经过一些踩坑经验,从一开始的默认动态模式,转型到现在的静态模式。 对于 ES 里面的数据,大概分为两种,被搜索/聚合的或者用来展示的。 拿商品一样,商品名称 肯定要被搜索的,那它绝对要设置在Mapping里,为这个字段建立倒排索引。但是像 商品标签 这种仅仅只是作为商品搜索的一个展示结果,它并没有被 搜索/聚合 的场景(截止1.5.2版本)
在动态模式下,不需要被搜索/聚合的 商品标签 也会被自动映射到 Mapping中,从而使得 Mapping 冗余,而且还可能出现类型自动识别不精准的场景。 在严格模式下,如果Mapping没有为 商品标签 这个字段设置好Mapping,那插入带有这个字段的商品就会报错,鲁棒性欠缺,而且每有一个新的字段就要重新设置 Mapping 然后 reindex,整体维护成本增大。 在静态模式下,我只需要在 Mapping 中设置需要被 搜索/聚合 的字段即可,新加入的字段既不会被写入 Mapping 造成冗余,也不会出现插入报错。
能够更改 Mapping 的字段类型
- 两种情况
- 新增字段
- Dynamic 设为 true 时,一旦有新增字段的文档写入, Mapping 也同时被更新
- Dynamic 设置为 false,Mapping 不会被更新,新增字段的数据无法被索引,但是信息会出现在 _source 中
- Dynamic 设置成 Strict,文档写入失败
- 对已有字段,一旦已经有数据写入,就不再支持修改字段定义
- Lucene 实现的倒排索引,一旦生成后,就不允许修改
- 如果希望改变字段类型,必须 Reindex API,重建索引
- 新增字段
- 原因
- 如果修改了字段的数据类型,会导致已被索引的字段无法被搜索
- 但是如果是新增的字段,就不会有这样的影响
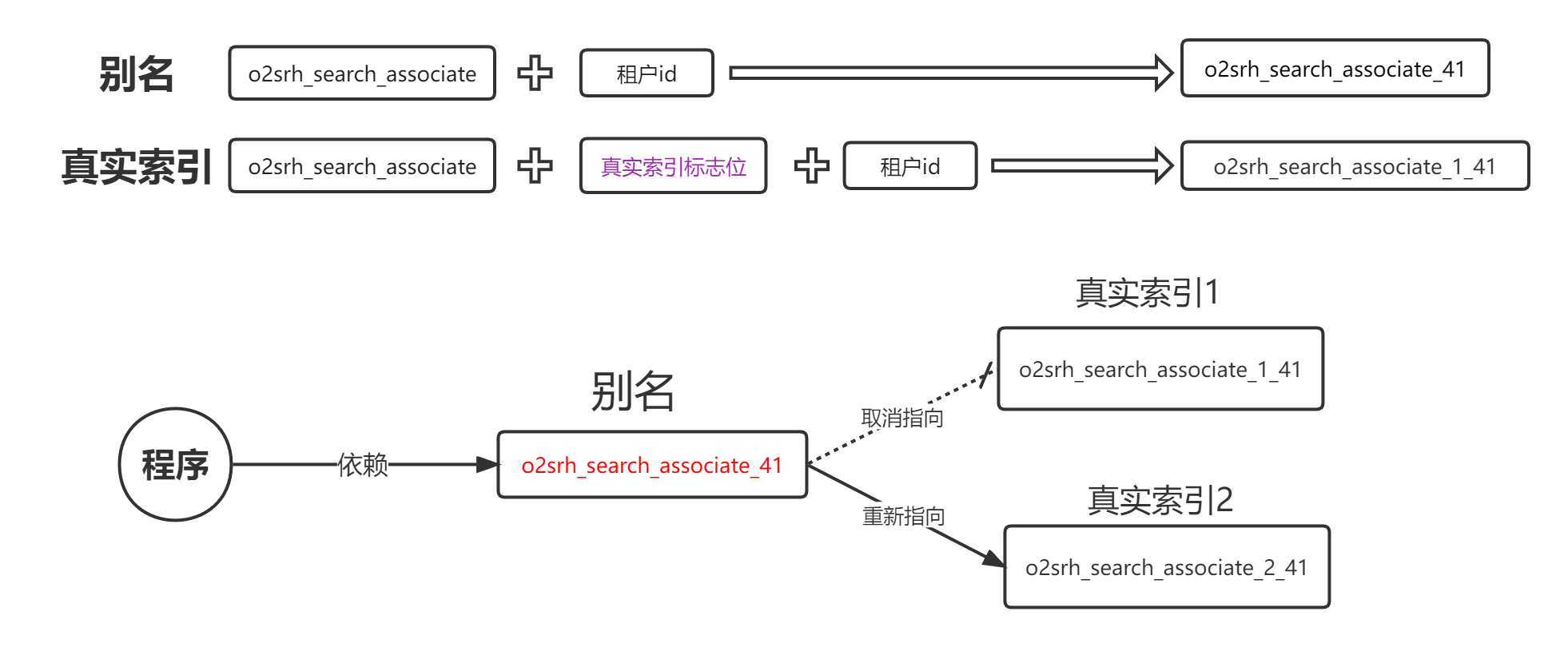
别名机制
别名就是索引的一个代理。
问题引出:
当需要 更改索引 分片数量 / 更改字段属性(类型/分词器),是无法直接更新 Mapping 的,只能创建新的索引,然后将旧索引的数据通过 Reindex 迁移过去。
这里举例索引名称为:test_index
需要新索引生效,有两个方向:
- 不停机方向
- 代码是指向了索引 test_index,我们新建一个符合新需求的索引 test_index_1,然后将 test_index 的索引通过 Reindex 方式迁移到新索引 test_index_1中
- 然后删除 test_index 索引
- 再按照新需求新建索引 test_index,将 test_index_1 的数据通过 Reindex 方式迁移过来。
问题:删除 test_index 索引期间,服务访问该索引会报错,因为找不到该索引,又或者按照动态模式自动建立了一个索引。
- 停机方向
- 代码是指向了索引 test_index,我们新建一个符合新需求的索引 test_index_1,然后将 test_index 的索引通过 Reindex 方式迁移到新索引 test_index_1中
- 修改源码,让其指向 test_index_1,重启服务
问题:需要改变代码,重启服务。
参考:Kibana演示代码:别名
应用 ES 别名实现零停机索引切换:
- 在索引创建时,就使用别名机制。
- 创建索引 test_index_1 ,然后给该索引添加别名 test_index
- 程序中依赖的索引是 test_index
- 当 test_index_1 索引需要重建,就新建索引 test_index_2,然后将数据 Reindex 过去
- 给 test_index_2 添加索引别名 test_index,给 test_index_1 删除别名 test_index
O2的索引管理
入口:中台->O2-搜索管理->搜索配置->索引配置
搜索模块的种子数据,就是整个项目的 4个索引的表结构(截止V1.5.2版本),在环境初始化、多租户初始化,进
行系统 ES 索引的创建。

若有收获,就点个赞吧
0 人点赞
