数据流向图
数据流图(DFD)是结构化系统分析方法的主要表达工具,数据流图,主要是为了说明在一个项目中,数据的处理与流动情况。
语法
数据流
数据流 : 数据流由 一组固定成分的数据 组成 , 表示 数据的流向 ;
数据流命名 : 每个数据流都有一个 命名 , 该命名表达了 该数据流传输 的 数据的含义 ; 如在箭头上标注 “账号信息” , 表示该数据流是传输账号信息 的 , 表示 数据的内容 ;
数据字典 : 数据流箭头上只标明了 “账号信息” , 没有具体的格式内容 , 是只有账号 , 还是有账号/密码/验证码等信息 , 这些数据详细格式 , 都在 数据字典中定义 ;
符号表示 : 数据流 使用 箭头 表示 , 箭头所指的方向 , 代表了数据流向 ;

加工 ( 核心 )
加工 : 描述 “输入数据流” 到 “输出数据流” 之间的变换 , 即 对数据进行了什么样的处理 , 使得 “输入数据流” 变为 “输出数据流” ;
主要操作 : 在程序中的体现是 处理 数据的过程 , 向 “加工” 中输入数据流后 , 将数据进行加工 , 处理 , 变换后 , 产生新的 “输出数据流” ;
符号表示 : 使用 圆形 / 圆角矩形 表示加工 ;

数据存储
数据存储 ( 文件 ) : 表示 暂时存储的数据 , 数据存储的粒度是以 表 为单位 ;
文件名称 : 每个 数据存储 ( 文件 ) 都有 名字 ;
方向 : 流向文件的数据流 表示 向文件内写入内容 , 从文件流出的数据流 表示 从文件读取内容 ;
符号表示 : 使用 双横线 / 半框形矩形 表示
外部实体
外部实体 : 软件系统之外的 人员 / 组织 ;
符号表示 : 矩形 ;
分层说明
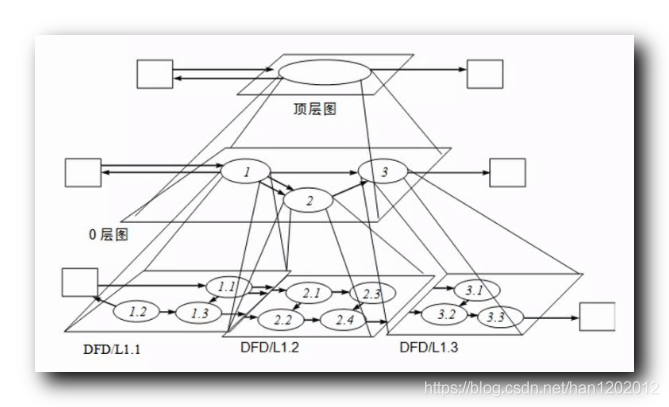
数据流图分层 , 最上层是 顶层数据流图 ,
第二层是 0 层数据流图 ,
最底层是 底层数据流图 ,
“顶层数据流图” 与 “底层数据流图” 之间是若干 中层数据流图 ,
中层数据流图 需要进行编号 , 从 0 开始编号 ;
顶层数据流图
顶层数据流图 : 中间的椭圆 是需要开发的 系统 , 周边的矩形 表示的是 外部实体人或组织 , 外部实体 与 系统 之间 , 有数据传输关系 ;
一个形象的说明是 多个人吃火锅 , 外层周边是人 , 中心位置火锅是系统 ;
顶层数据流图 能够表达的信息是非常有限的 , 其 将整个系统 , 使用一个节点表示 ,
其可以体现出 系统与外界实体之间的交互 ,
但是 系统内部的情况 , 系统内部模块之间的数据交换 是没有体现的 ;
中层数据流图
将 “顶层数据流图” 进行细化 , 细化后的 0 层数据流图 ,
与 顶层数据流图 比较没有变化的部分 : 外部实体 , 外部实体与系统之间的数据流 , 是没有变化的 ;
变化部分 : 有变化的部分是系统内部 , 系统内部进行了细化 , 原来系统是一个节点 , 在 中层数据流图 中 , 会将一个节点 拆分成 多个节点 , 这些节点就是系统中的数据处理部件 , 即 加工 ;
这些数据处理部件 ( 加工 ) 之间会有数据流的交互 ,
底层数据流图
针对每个加工 节点 , 将其拆分 , 绘制其中的更详细的数据流转情况 ;
数据流图 ( DFD ) 分层 , 是从 顶层 -> 中层 -> 底层 , 逐层进行分解 , 这种分解思路 , 与结构化的开发方法 , 是完全匹配的 ;
因此 , 数据流图 是 结构化 开发方法中 , 最常用的工具 ;
绘制数据流图时 , 要保证 上一层数据流图 与 下一层数据流图 保持平衡 , 这就是 数据流图平衡原则 ;
原则
(1):父图-子图平衡原则:
子图可以理解为父图中部分环节的细化。例如我们给出父图: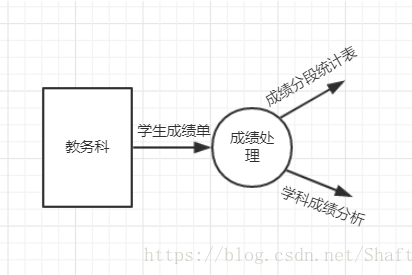
我们想对其中的成绩处理环节进行细化,画成如下数据流图: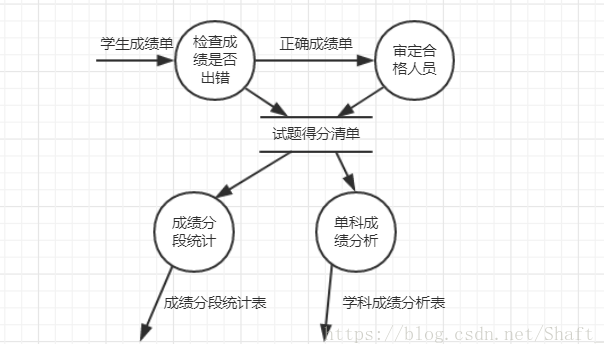
其中一定要保证父图输入输出数据流 = 子图输入输出数据流
(2)数据守恒原则:
所有的输出数据流必须是通过加工的,且通过加工能直接产生。一般情况下要注意一下3个错误:
*1* 外部实体与外部实体间无数据流。*2* 外部实体与数据存储文件无数据流。*3* 数据存储文件间无数据流。
(3)守恒加工原则:
对于同一个加功,其输入与输出的名字必须不同。通常来说要注意一下2点:
*1* 对于每一个加工,都应该有输入、输出。*2* 数据流与加工有关,且必须进过加工。
参考资料
数据流图案例https://blog.csdn.net/baidu_38634017/article/details/88430847
软件工程中的数据流图https://blog.csdn.net/Shaft_/article/details/79727065
ER图
E-R图也称实体-联系图(Entity Relationship Diagram),提供了表示实体类型、属性和联系的方法,用来描述现实世界的概念模型。
语法
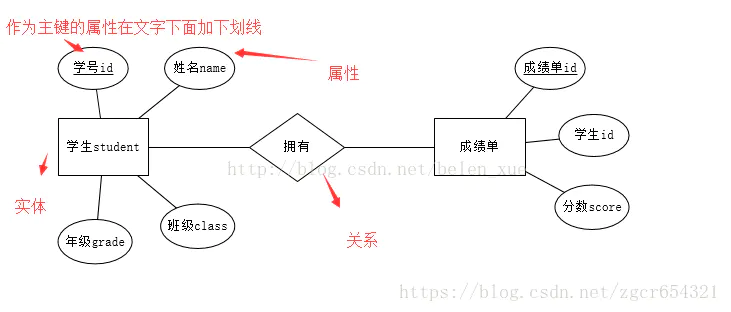
1,实体(entity):
数据模型中的数据对像,每个实体都有自己的实体成员或者说实体对象,例如学生实体包括张三,李四
弱实体
一个实体必须依赖另一个实体存在,那么前者是弱实体,后者是强实体。
弱实体和强实体的联系必然只有1:N或者1:1,这是由于弱实体完全依赖于强实体,强实体不存在,那么弱实体就不存在,所以弱实体是完全参与联系的,因此弱实体与联系之间的联系也是用的双线菱形。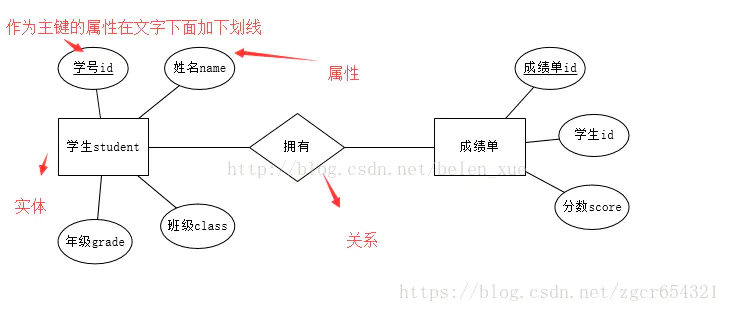
2,属性(attribute):
实体所具有的属性,例如学生具有姓名、学号、年级等属性,用椭圆形表示,属性分为唯一属性( unique attribute)和非唯一属性,唯一属性指的是唯一可用来标识该实体实例或者成员的属性,用下划线表示,一般来讲实体都至少有一个唯一属性。
复合属性(composite attribute)
复合属性是指具有多个属性的组合,例如名字属性,它可以包含姓氏属性和名字属性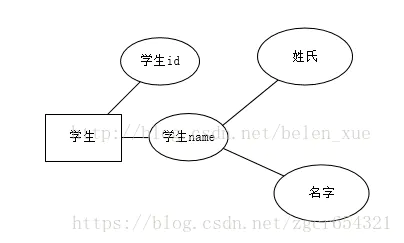
多值属性(multivalued attribute)
一个实体的某个属性可以有多个不同的取值,例如一本书的分类属性,这本书有多个分类,例如科学、医学等,这个分类就是多值属性, 用双线椭圆表示。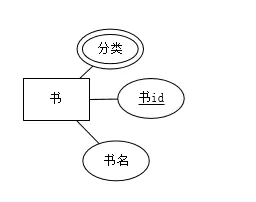
派生属性(derivers attribute)
是非永久性存于数据库的属性。派生属性的值可以从别的属性值或其他数据(如当前日期)派生出来,用虚线椭圆表示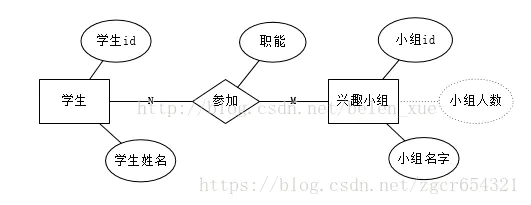
可选属性(optional attribute)
并不是所有的属性都必须有值,有些属性的可以没有值,这就是可选属性,在椭圆的文字后用(O)来表示,如下图的地址就是一个可选属性。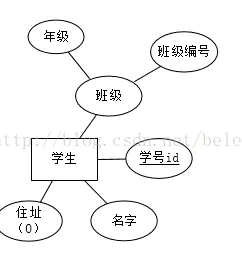
联系属性
联系属于用户表示多个实体之间联系所具有的属性,一般来讲M:N的两个实体的联系具有联系属性,在1:1和1:M的实体联系中联系属性并不必要。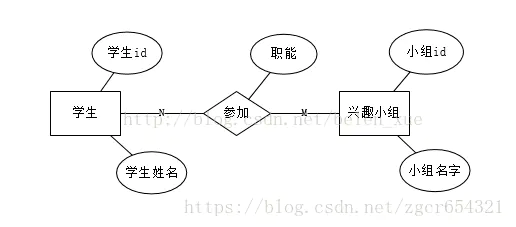
3,关系(relationship):
用来表现数据对象与数据对象之间的联系,例如学生的实体和成绩表的实体之间有一定的联系,每个学生都有自己的成绩表,这就是一种关系,关系用菱形来表示。
关联关系有三种:
(1)1对1(1:1):指对于实体集A与实体集B,A中的每一个实体至多与B中一个实体有关系;反之,在实体集B中的每个实体至多与实体集A中一个实体有关系。
(2)1对多(1:N):1对多关系是指实体集A与实体集B中至少有N(N>0)个实体有关系;并且实体集B中每一个实体至多与实体集A中一个实体有关系。
(3)多对多(M:N):多对多关系是指实体集A中的每一个实体与实体集B中至少有M(M>0)个实体有关系,并且实体集B中的每一个实体与实体集A中的至少N(N>0)个实体有关系。
参考资料
ER图是啥?https://www.cnblogs.com/jpfss/p/11571727.html
数据库ER图基础概念整理https://www.jianshu.com/p/9ff938e3a498

若有收获,就点个赞吧
0 人点赞
