概念简述
Hive: 将SQL转换为MapReduce任务的工具,底层由HDFS来提供数据存储
数仓(Data Warehouse): 面向分析、集成的数据集合。数仓本身不产生数据,存储了大量数据。分析处理用Hive
Hive和RDBMS
Hive采用了类似SQL的查询语句HQL,因此很容易将Hive理解为数据库。
查询语言相似:HQL <==> SQL 高度相似数据规模:Hive存储海量数据;RDBMS只能处理有限的数据集Hive在集群上利用MapReduce计算;RDBMS支持数据规模小执行引擎: (Hive无索引)Hive的引擎是MR/Tez/Spark/Flink,大多数查询时通过Hadoop提供的MapReduce来实现的RDBMS使用自己的引擎:比如NO-SQL数据存储:Hive保存在HDFSRDBMS保存在本地文件系统可扩展性:Hive支持水平扩展RDBMS不友好,最多Oracle理论上100台数据更新:Hive内容读多写少,不建议对数据改写RDBMS数据需要频繁、快速的进行更新
Hive优缺点
Hive优点处理海量数据.底层使用MapReduce系统可以水平扩展.低层基于Hadoop功能可扩展.Hive允许用户自定义函数良好的容错性.某个结点发生故障,HQL依然可以完成统一的元数据管理.元数据:表/字段/字段类型Hive缺点HQL表达能力有限迭代计算无法表达Hive执行效率不高(基于MR的引擎)Hive自动生成的MapReduce作业,不够智能Hive调优困难
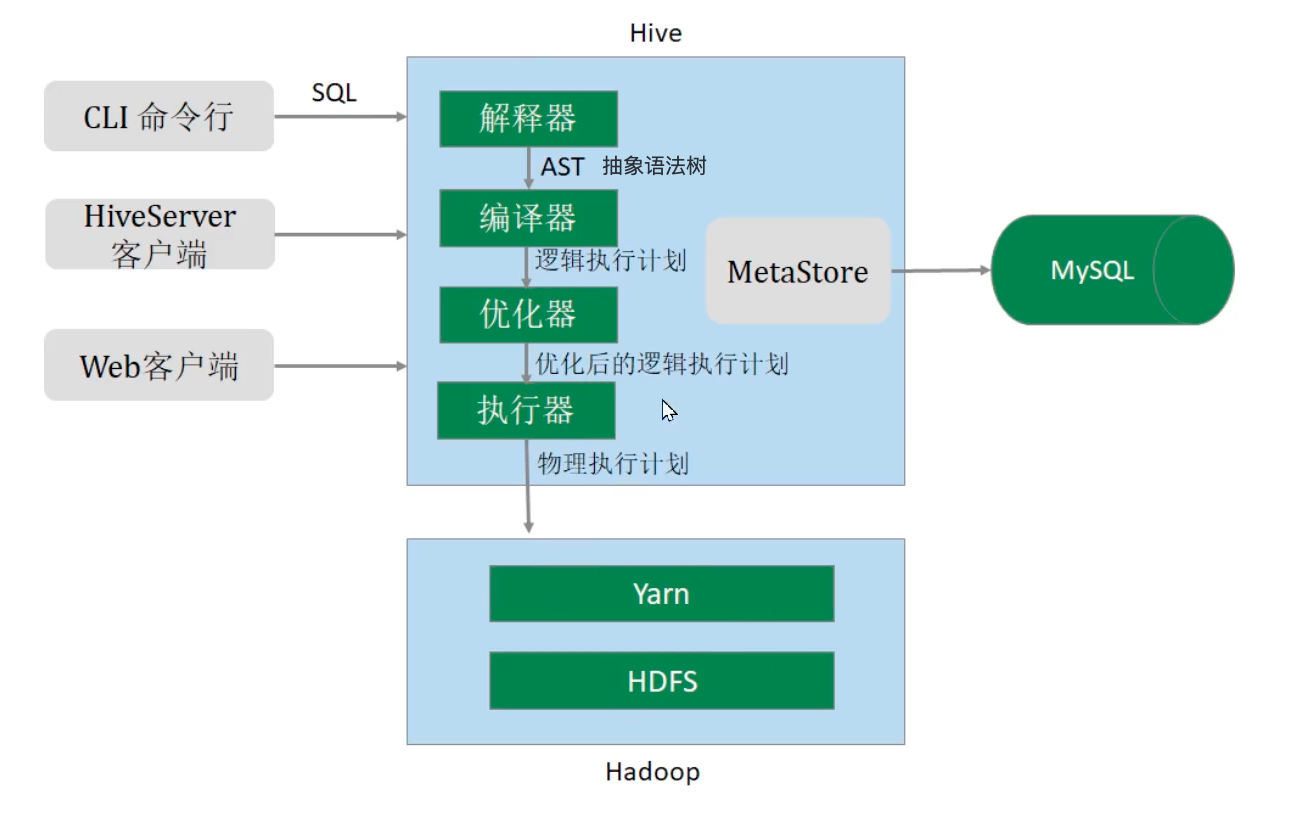
Hive架构

若有收获,就点个赞吧
0 人点赞
