- 应用层测试
- 应用层对数据的逻辑处理
- 数据库层测试
- 对每一层数据进行校验。包括(数据表结构、字段类型边界、数据一致性校验、数据完整性校验、数据正确性校验、数据转换逻辑校验)
前期更加关注:
数据的完整性(是否缺失数据)和正确性(数据抽烟检查每个字段是否正确)
数据量有问题、数据字段缺失、数据转换逻辑有问题(提供完整的表映射文档、表结构、自测sql)
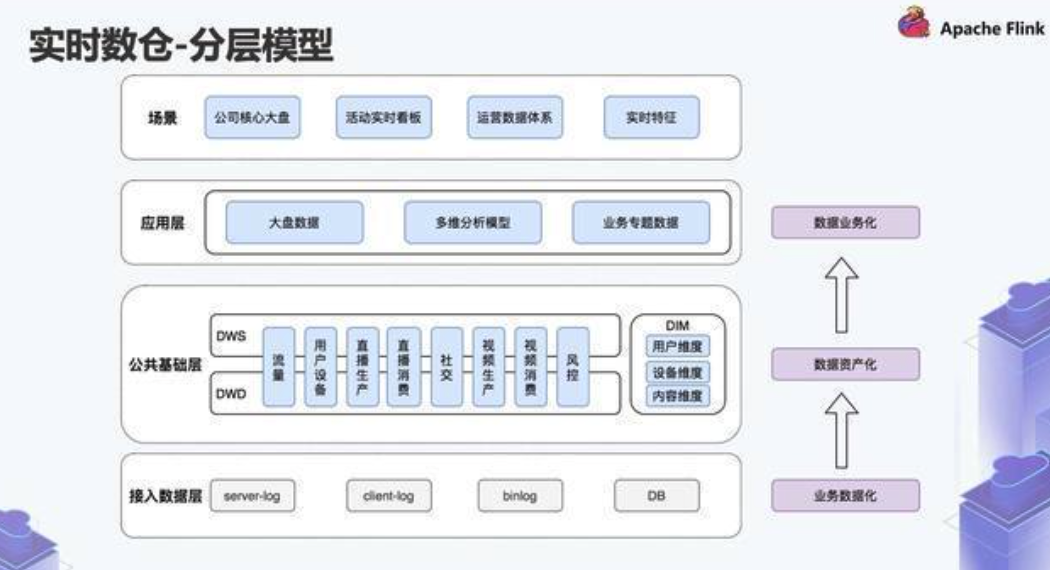
数据分层
- 清晰数据结构:每个数据分层都有自己的作用域,能够方便定位和理解
- 数据血缘追踪:业务表来源很多,快速定位到问题,并理清楚危害范围
- 减少重复开发:规范数据分层,开发中间层数据,减少重复计算
- 复制问题简化:将复杂任务分解成多个步骤完成,每一层只处理单一的步骤
- 屏蔽异常数据:定位、记录原始数据的异常、屏蔽业务的影响,没必要每改一次业务从新接入一次数据
实时数仓的应用场景
- 实时OLAP分析
- 实时数据看板
- 实时业务监控
- 实时数据接口服务

实时数仓和离线数仓的区别:
- 离线数仓:数据存储方式单一都在Hive表上,APP应用层在数仓内部
- 实时数仓:数据存储方式很多,不存在APP应用层。比如,明细数据或者汇总数据一般存放在Kafka,维度信息需要使用Hbase、mysql或其他KV数据库
ODS贴源层建设
数据源:binlog日志,public日志、埋点日志,消息队列
ODS层数据源主要包括两种:
- 离线采集时,自动产生的Kafka topic
- 自己采集同步到 kafka topic,
DWD明细层建设
数据来源于ODS层
- 通过 Stream SQL 完成 ETL 工作,对binlog日志进行简单的数据清理、处理数据漂移和数据乱序,可能对多个ODS表进行 Stream Join
- 对流量日志做通用的 ETL 处理和数据过滤,完成非结构化数据的结构化处理和数据分流
该层的数据除了存储在消息队列 Kafka 中,通常也会把数据实时 写入 Druid 数据库中,供查询明细数据和作为简单汇总数据的加工数据源。
DIM维度层建设
基于维度建模理念,建立整个业务过程的一致性维度,降低数据计算口径和算法不统一风险
数据来源:
- Flink程序实时处理ODS数据得到
- 通过离线任务出仓得到
DIM层数据主要使用 MySQL、Hbase、kv三种存储引擎。
- 维度数据比较少使用 MySQL
- 单条数据少,查询QPS比较高的,使用KV存储
- 对数据量大,维度变化不是特别敏感的使用HBase存储
DWM中间层建设
DWM层对DWD层明细数据按照常用维度进行初步汇总
- 对共性指标加工,对个性指标复用拉齐(比如PV,UV等共性指标在DWM进行统一计算,确保指标口径是统一在一个固定的模型中完成;个性指标需要确认唯一时间字段,并尽可能与其他指标在时间维度上拉齐,比如异常订单量需要与交易域指标在事件时间上拉齐)
- 多维主题汇总
- 衍生维度的加工。顺风车券相关的汇总 指标加工中我们使用 Hbase 的版本机制来构建一个衍生维度的拉链表
APP应用层
把实时汇总数据写入应用系统的数据库中:
用于实时数据接口服务的 Hbase 数据库
用于实时数据产品的 mysql 和 redis 数据库
实时指标的目标:
- 离线实时指标整体数据差异在 1% 以内
- 数据延迟:SLA标准是活动期间所有核心报表场景数据延迟不能超过5分钟
- 稳定性:作业重启后,指标曲线是正常的
实时指标的难点:
- 数据量大,QPS峰值高
- 组件依赖复杂
- 链路复杂
元数据
- 技术元数据
- 存储元数据:表、字段、分区等信息
- 运行元数据:大数据平台上所有的运行信息:类似Hive Job日志,包括作业类型、实例名称、输入输出、SQL、运行参数、执行时间、执行引擎、占用资源
- 数据同步、计算任务、任务调度等信息:数据同步的输入输入表和字段,以及同步任务本身节点信息;任务调度主要有任务的依赖类型、依赖关系、调度周期
- 业务元数据
- 业务指标
- 业务代码
- 业务术语
- 管理元数据
- 数据所有者
- 数据治理定责
- 数据安全等级
flume 分布式日志收集系统
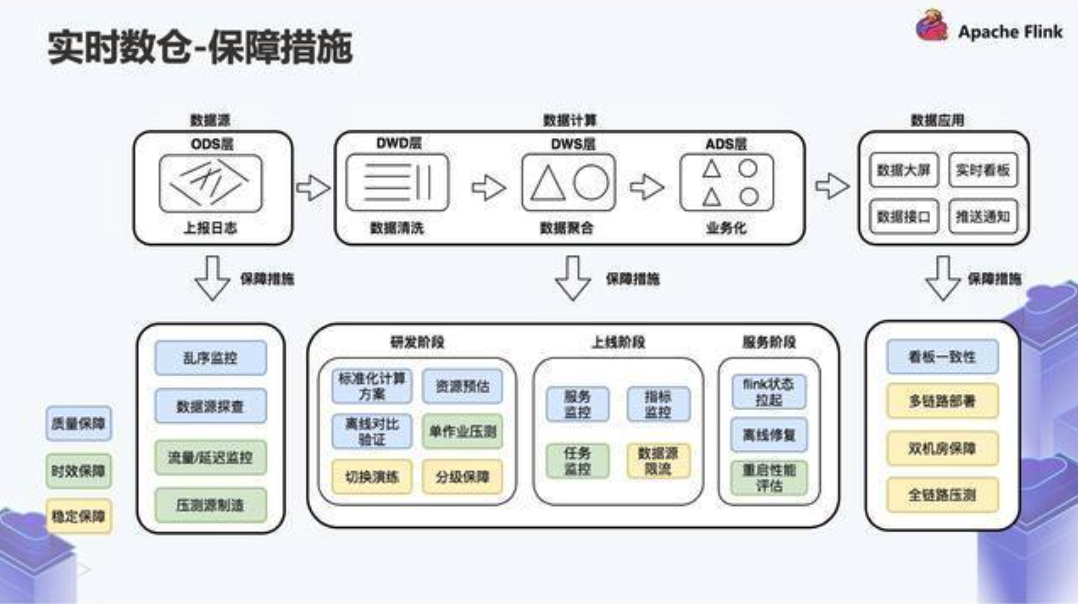
数据质量
- 数据完整性测试
- 数据量少
- 数据是否重复
- 数据是否主键唯一
- 数据量确认
- 总条数是否缺失
- 日期是否缺失、存在空值
- 业务关键字是否缺失
- 数据规模不确定
- 历史数据条数的波动进行对比观察
- 数据量少
- 数据一致性测试
- 数据记录规范一致
- 数据逻辑一致
- 多节点数据一致
- 数据准确性测试
- 数值检查
- 数值是否在常规范围
- 数值是否在业务返回
- 数值分布是否异常
- 时间维度对比
- 空间维度对比
- 上下游数据对比
- 与系统内数据对比
- 与系统外数据对比
- 数值检查
- 数据及时性测试
- 数据约束检查
- 检查数据类型、数据长度、索引和主键是否符合要求
- 需要覆盖所有数据类型,对不支持的类型要做异常处理
- 要检查约束是否符合预期
- 数据存储检查
- 评估是否需要以压缩文件形式存储
- Hive 表类型选择是否合理
- 代码中读写的文件目录是否正确
- SQL文件检查
- SQL规范检查
- 命名规范
- 不能用Select *
- 多用中间表
- 少用子查询,子查询嵌套不能超过3层
- 禁止使用drop/create table方式生成中间表,统一使用 insert overwrite table 写入
- “脏”数据处理
- 所有 key 过滤掉 Null / null ,过滤掉 key is not null
- 时间格式 ‘脏数据’
- join 操作
- 先过滤,再进行 join 操作
- 小表放在 join 左边
- 少用 distinct 操作,因为 distinct 比较消耗资源
- SQL语法检查
- 不同表的加载方式,insert into 和 insert overwrite
- union 和 union all 正确使用
- 合理使用 order by 、sort by、group by
- SQL规范检查
- 数据处理逻辑验证
- 数据处理过程是否符合业务逻辑
- 对异常值、脏数据、极值、特殊值(0,负值)处理是否符合预期
- 字段类型和实际数据是否一致,主键构造是否合理
- 去重记录,是否按照去重规则进行去重处理
- 数据的输入和输出是否符合规定的格式
- Shell脚本测试
- 脚本中 jar 包引入是否正确
- 验证脚本中 Mapper文件、Reducer文件、MapReduce依赖文件和 MapReduce 输入/输出文件的路径是否正确。MapReduce 运行配置参数是否合理
- 验证脚本执行是否正确,过程中的日志输出是否符合预期
- 调度任务测试
- 任务是否支持重跑
- 依赖的父任务是否配置合理
- 任务依赖层次是否合理
- 任务是否在规定时间内完成

若有收获,就点个赞吧
0 人点赞
