1、基础介绍
1.1 注释

单行注释
在使用#(井号)时,#位于注释行的开头,#后面有一个空格,接着是注释的内容。
# 这是单行注释print("hello")
多行注释
多行注释用三个单引号 ‘’’ 或者三个双引号 “”” 将注释括起来,例如:
单引号(‘’’)
'''这是多行注释,用三个单引号这是多行注释,用三个单引号这是多行注释,用三个单引号'''print("Hello!")
双引号(”””)
"""这是多行注释,用三个双引号这是多行注释,用三个双引号这是多行注释,用三个双引号"""print("Hello, World!")
注意:
python解释器遇到 #号注释时,会自动跳过。
而遇到‘’’引号注释,是会加载到内存中的。
因为,引号注释的本质是定义了一串字符串
只不过这个字符串没有被使用而已。
1.2 算数运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 | 10 + 20 = 30 |
| - | 减 | 10 - 20 = -10 |
| * | 乘 | 10 * 20 = 200 |
| / | 除 | 10 / 20 = 0.5 |
| // | 取整除 | 返回除法的整数部分(商) 9 // 2 输出结果 4 |
| % | 取余数 | 返回除法的余数 9 % 2 = 1 |
| ** | 幂 | 又称次方、乘方,2 ** 3 = 8 |
在 Python 中 * 运算符还可以用于字符串,计算结果就是字符串重复指定次数的结果
- 优先级
- 先乘除后加减
- 同级运算符是 从左至右 计算
- 可以使用
()调整计算的优先级 | 运算符 | 描述 | | —- | —- | | | 幂 (最高优先级) | | / % // | 乘、除、取余数、取整除 | | + - | 加法、减法 | | >> << | 右移,左移运算符 | | & | 位 ‘AND’ | | ^ | | 位运算符 | | <= < > >= | 比较运算符 | | <> == != | 等于运算符 | | = %= /= //= -= += = = | 赋值运算符 | | is is not | 身份运算符 | | in not in | 成员运算符 | | and or not | 逻辑运算符 |
1.3 变量及类型
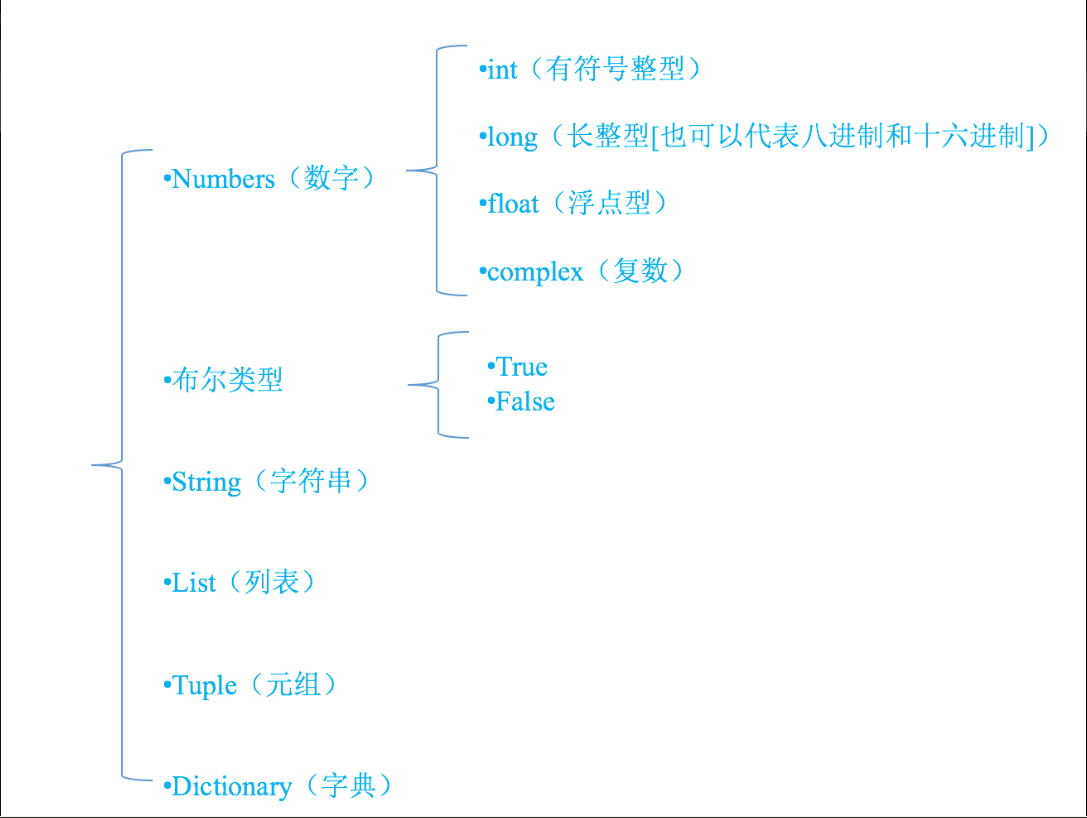
Python有五个标准的数据类型:
- Numbers(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Dictionary(字典)
可以使用type(变量的名字),来查看变量的类型
| 函数 | 说明 |
|---|---|
| print(x) | 将 x 输出到控制台 |
| type(x) | 查看 x 的变量类型 |
| int(x) | 将 x 转换为一个整数 |
| float(x) | 将 x 转换到一个浮点数 |
% 被称为 格式化操作符,专门用于处理字符串中的格式
| 格式化字符 | 含义 |
|---|---|
| %s | 字符串 |
| %d | 有符号十进制整数,%06d表示输出的整数显示位数,不足的地方使用 0补全 |
| %f | 浮点数,%.2f表示小数点后只显示两位 |
| %% | 输出 % |
1.4 编码解码
编码(encode)与解码(decode)
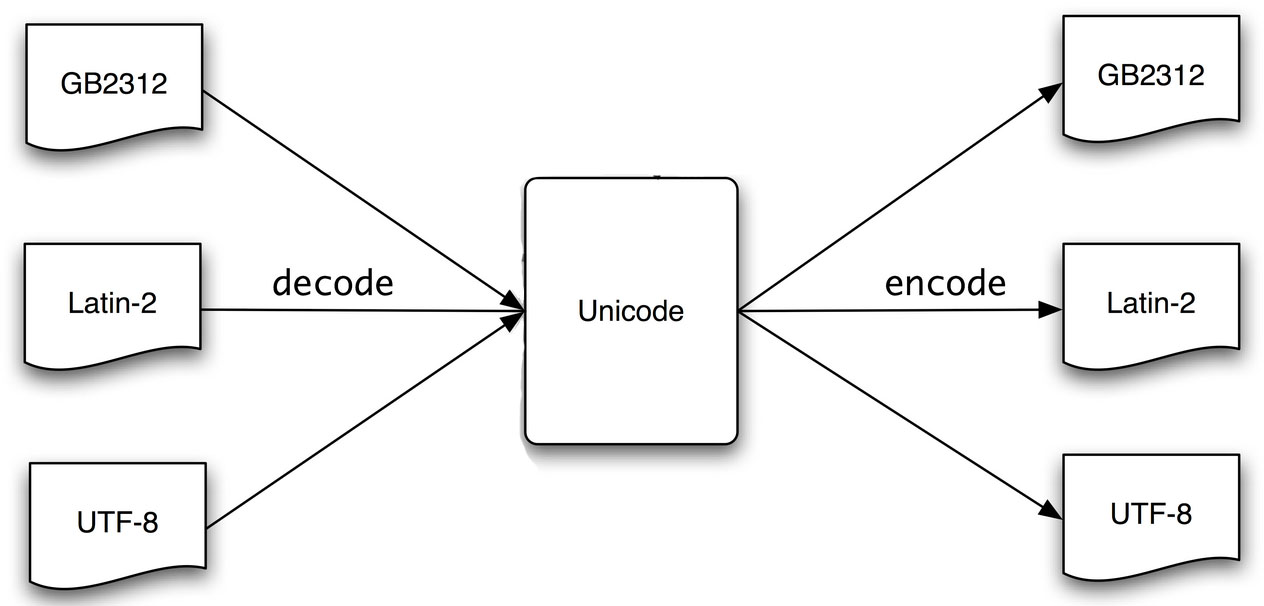
- encode()
encode()方法为str对象的方法,用于将字符串转换为二进制数据(即bytes),也称为“编码”,其语法格式如下:
strdef encode(self,encoding: str = ...,errors: str = ...) -> bytes

在使用encode()方法时,不会修改原字符串,如果需要修改原字符串,需要对其进行重新赋值。
- decode()
decode()方法为bytes对象的方法,用于将二进制数据转换为字符串,即将使用encode()方法转换的结果再转换为字符串,也称为“解码”
bytesdef decode(self,encoding: str = ...,errors: str = ...) -> str

在设置解码采用的字符编码时,需要与编码时采用的字符编码一致。
字符在计算机的内存中统一是以Unicode编码的。只有在字符要被写进文件、存进硬盘或者从服务器发送至客户端(例如网页前端的代码)时会变成utf-8。但其实我比较关心怎么把这些字符以Unicode的字节形式表现出来,露出它在内存中的庐山正面目的。这里有个照妖镜:xxxx.encode/decode('unicode-escape')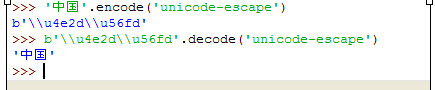
b’\u4e2d’还是b’\u4e2d,一个斜杠貌似没影响。同时可以 发现在shell窗口中,直接输 ‘\u4e2d’和输入b ‘\u4e2d’.decode(‘unicode-escape’)是相同的,都会打印出汉字‘中’, 反而是 ‘\u4e2d’.decode(‘unicode-escape’)会报错。说明 说明Python3不仅支持Unicode,而且一个‘\uxxxx’格式的 Unicode字符 可被辨识且被等价于str类型。
如果我们知道一个Unicode字节码,怎么变成UTF-8的字节码呢。懂了以上这些,现在我们就有思路了,先decode,再encode。代码如下:xxx.decode('unicode-escape').encode()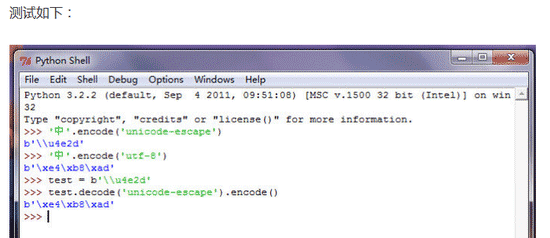
2、控制语句
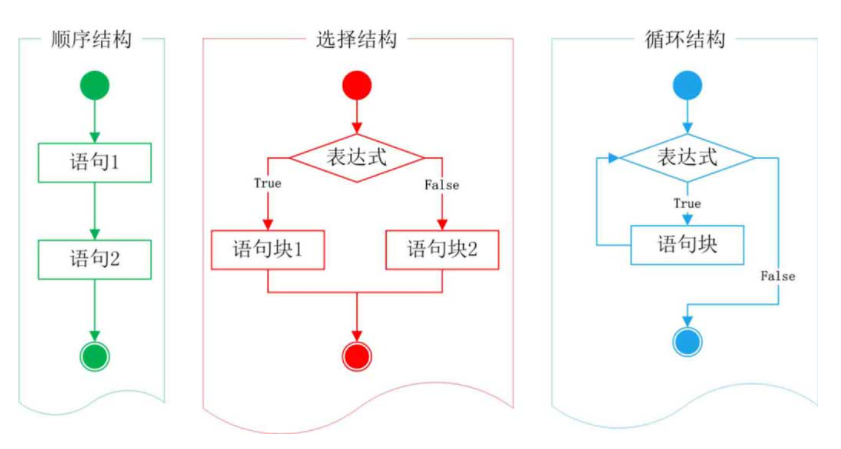
2.1 if
2.1.1 格式
if 判断条件1:执行语句1……elif 判断条件2:执行语句2……elif 判断条件3:执行语句3……else:执行语句4……
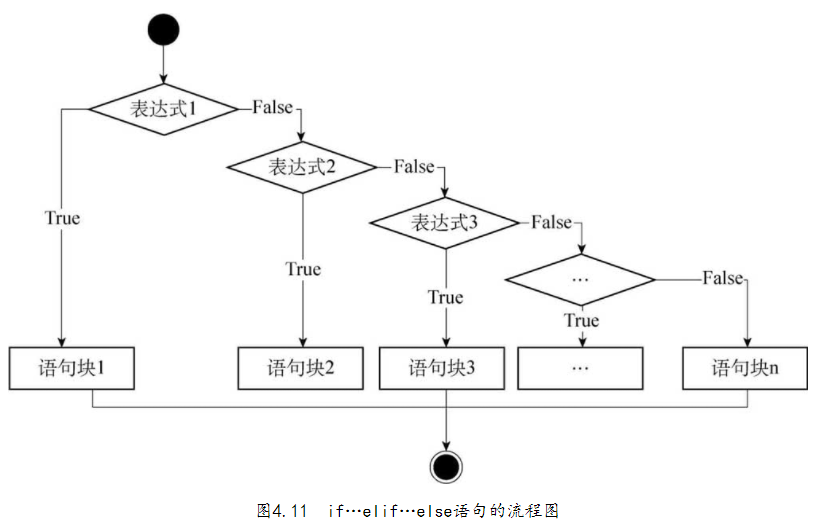
if和elif都需要判断表达式的真假,而else则不需要判断;另外,elif和else都必须跟if一起使用,不能单独使用。
2.1.2 三元表达式
为真时的结果 if 判定条件 else 为假时的结果
示例:
In [0]: # name = "a"...: name = "b"...: ret = "java" if name == "a" else "python"...: print(ret)...:python
2.1.3 变量的真假
空元组、空列表、空字典、空字符串、数字0,None都是False
其他皆为True
2.1.4 判断变量的类型
在实际写程序中,经常要对变量类型进行判断,可以使用type()或者isinstance()``方法判断:
a = 1b = [1, 2, 3, 4]c = (1, 2, 3, 4)d = {'a': 1, 'b': 2, 'c': 3}e = "abc"print(type(a)) # <class 'int'>print(type(b)) # <class 'list'>print(type(c)) # <class 'tuple'>print(type(d)) # <class 'dict'>print(type(e)) # <class 'str'>print(isinstance(a, int)) # Trueprint(isinstance(b, list)) # Trueprint(isinstance(c, tuple)) # Trueprint(isinstance(d, dict)) # Trueprint(isinstance(e, str)) # True
2.2 while
while循环是通过一个条件来控制是否要继续反复执行循环体中的语句。
格式:
while 判断条件:执行语句…
示例:
i = 0while i<5:print("当前是第%d次执行循环"%(i+1))print("i=%d"%i)i+=1
2.3 for
for循环可以遍历任何序列的项目,如一个列表或者一个字符串等。
但是,for循环是一种迭代循环机制,而while循环是条件循环。
迭代:即重复相同的逻辑操作,每次操作都是在上一次的结果上进行的。
格式
for 临时变量 in 可迭代对象:循环满足条件时执行的代码else:循环不满足条件时执行的代码
可迭代对象:基本类型有字符串、列表、元组、字典、文件等
(具体查看<迭代器>)
示例1:
In [10]: for i in range(5):...: ... print(i)...: # range()函数。它会生成数列[0,1,2,3,4]01234
示例2:
In [18]: for i, value in enumerate(['A', 'B', 'C']):...: print(i, value)...:(0, 'A')(1, 'B')(2, 'C')"""Python内置的enumerate函数可以把一个list变成索引-元素对,这样就可以在for循环中同时迭代索引和元素本身"""
2.4 break
- break的作用:用来结束整个循环
- 只能用在循环中,除此以外不能单独使用
- 在嵌套循环中,只对最近的一层循环起作用
- break语句一般会结合if语句进行搭配使用,表示在某种条件下跳出循环。
demo:
In [1]: name = 'yuque'...:...: for x in name:...: print('----')...: if x == 'q':...: break...: print(x)...:----y----u----
2.5 continue
- continue的作用:用来结束本次循环,紧接着执行下一次的循环
- 只能用在循环中,除此以外不能单独使用
- 在嵌套循环中,只对最近的一层循环起作用
demo:
In [2]: name = 'yuque'...:...: for x in name:...: print('----')...: if x == 'q':...: continue...: print(x)...:----y----u--------u----e
2.6 else
当循环没有遇到continue或break,是正常的i完成了循环条件退出的情况时,再执行else中的代码
for i in range(10):pass#break,打开注释时,则不执行else中的语句else:print("yuque")>>>"yuque"
- 使用continue语句直接跳到循环的下一次迭代。
- 使用break完全中止循环。
3、数据类型
3.1 字符串
3.1.1 值
In [57]: var1 = 'Hello yuque!'...: var2 = "Python string"...:# 通过下标访问字符串对应的值In [58]: print("var1[0]:{}".format(var1[0]))var1[0]:HIn [59]: print("var2[1:3]:{}".format(var1[1:6]))var2[1:3]:ello
3.1.2 转义字符
在需要在字符中使用特殊字符时,python用反斜杠()转义字符。如下表:
| 转义字符 | 描述 |
|---|---|
| \(在行尾时) | 续行符 |
| \\ | 反斜杠符号 |
| \‘ | 单引号 |
| \“ | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,yy代表的字符,例如:\o12代表换行 |
| \xyy | 十六进制数,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
3.1.3 字符串运算符
下表实例变量 a 值为字符串 “Hello”,b 变量值为 “Python”:
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | >>>a + b’HelloPython’ |
| * | 重复输出字符串 | >>>a * 2’HelloHello’ |
| [] | 通过索引获取字符串中字符 | >>>a[1]’e’ |
| [ : ] | 截取字符串中的一部分 | >>>a[1:4]’ell’ |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | >>>”H” in aTrue |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | >>>”M” not in aTrue |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母”r”(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | >>>print r’\n’\n>>> print R’\n’\n |
| % | 格式字符串 | [ |
](https://www.yuque.com/yuanliang/yuanzi/og4if9) |
3.1.4 三引号
允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符:
errHTML = '''<HTML><HEAD><TITLE>Friends CGI Demo</TITLE></HEAD><BODY><H3>ERROR</H3><B>%s</B><P><FORM><INPUT TYPE=button VALUE=BackONCLICK="window.history.back()"></FORM></BODY></HTML>'''cursor.execute('''CREATE TABLE users (login VARCHAR(8),uid INTEGER,prid INTEGER)''')
3.1.5 Unicode 字符串
Python 中定义一个 Unicode 字符串和定义一个普通字符串一样简单:
In [60]: u'Hello yuque !'Out[60]: u'Hello yuque !'
引号前小写的”u”表示这里创建的是一个 Unicode 字符串。如果你想加入一个特殊字符,可以使用 Python 的 Unicode-Escape 编码。如下例所示:
In [61]: u'Hello\u0020yuque !'Out[61]: u'Hello yuque !'
3.1.6 format函数
#通过位置print '{0},{1}'.format('yuque',20)print '{},{}'.format('yueque',20)print '{1},{0},{1}'.format('yuque',20)#通过关键字参数print '{name},{age}'.format(age=18,name='yuque')class Person:def __init__(self,name,age):self.name = nameself.age = agedef __str__(self):return 'This guy is {self.name},is {self.age} old'.format(self=self)print str(Person('yuque',18))#通过映射 lista_list = ['yuque',20,'china']print 'my name is {0[0]},from {0[2]},age is {0[1]}'.format(a_list)#my name is yuque,from china,age is 20#通过映射 dictb_dict = {'name':'yuque','age':20,'province':'zhejiang'}print 'my name is {name}, age is {age},from {province}'.format(**b_dict)#my name is yuque, age is 20,from zhejiang#填充与对齐print '{:>8}'.format('189')# 189print '{:0>8}'.format('189')#00000189print '{:a>8}'.format('189')#aaaaa189#精度与类型f#保留两位小数print '{:.2f}'.format(321.33345)#321.33#用来做金额的千位分隔符print '{:,}'.format(1234567890)#1,234,567,890#其他类型 主要就是进制了,b、d、o、x分别是二进制、十进制、八进制、十六进制。print '{:b}'.format(18) #二进制 10010print '{:d}'.format(18) #十进制 18print '{:o}'.format(18) #八进制 22print '{:x}'.format(18) #十六进制12
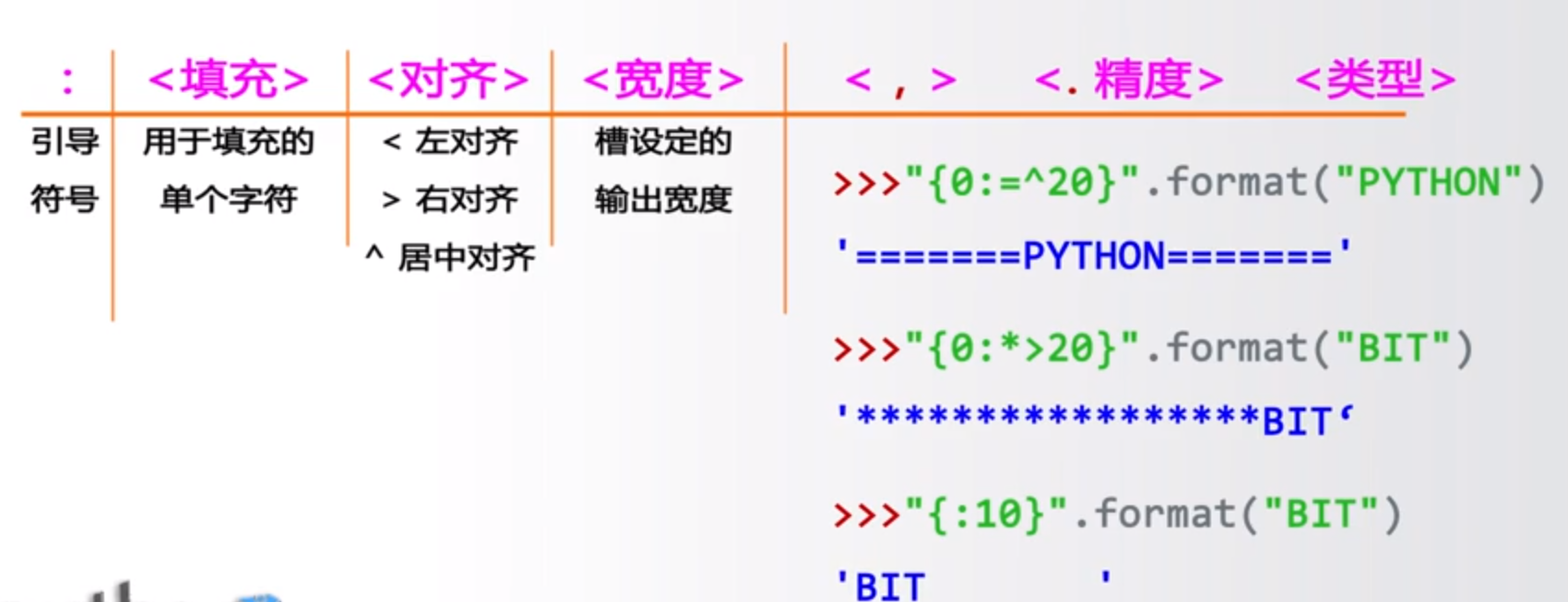

3.1.7 字符串的常见操作
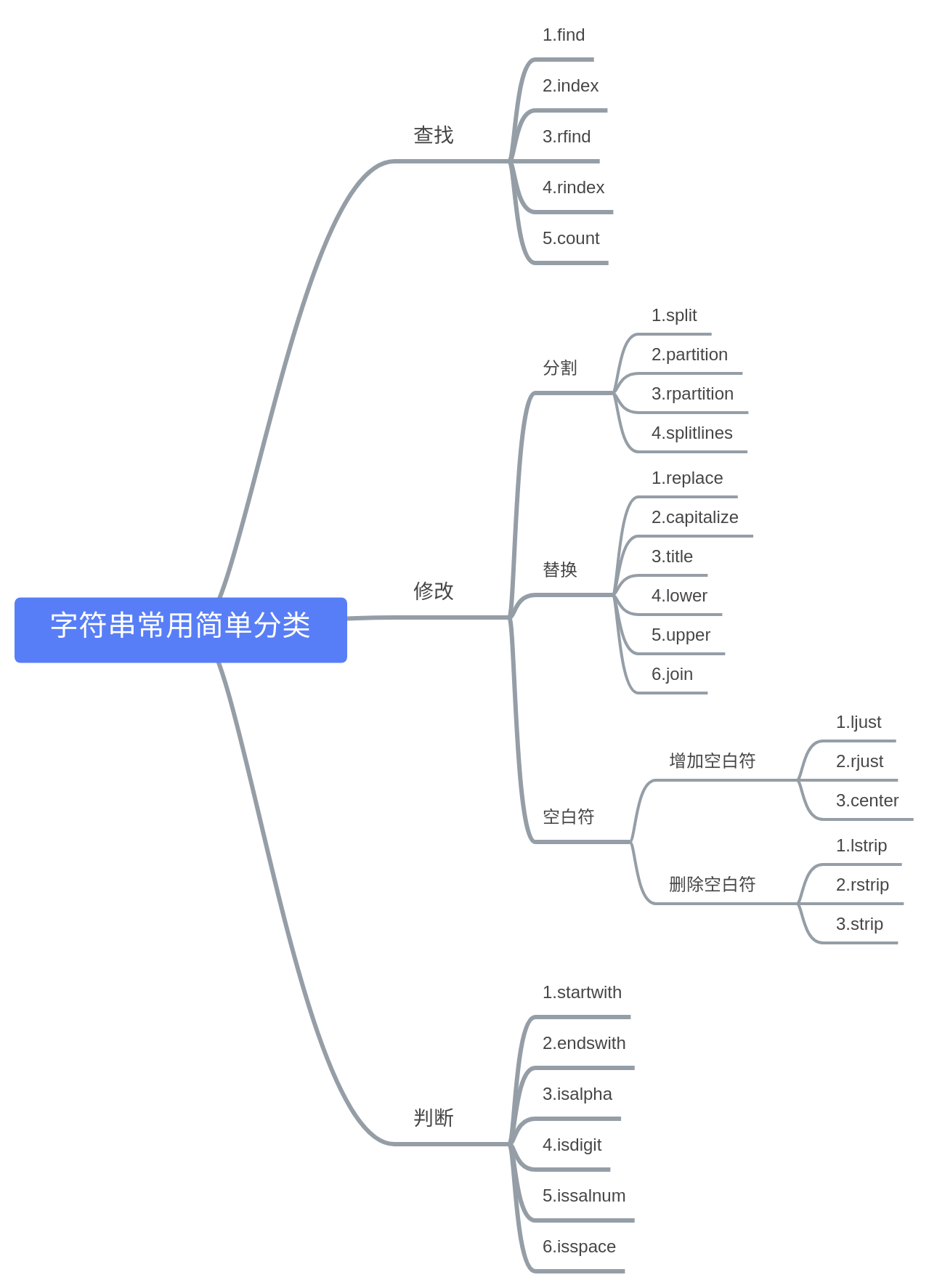 这些方法实现了string模块的大部分方法,如下表所示列出了目前字符串内建支持的方法,所有的方法都包含了对Unicode的支持,有一些甚至是专门用于Unicode的。
这些方法实现了string模块的大部分方法,如下表所示列出了目前字符串内建支持的方法,所有的方法都包含了对Unicode的支持,有一些甚至是专门用于Unicode的。
| 方法 | 描述 |
|---|---|
| string.capitalize() | 把字符串的第一个字符大写 |
| string.center(width) | 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
| string.count(str, beg=0, end=len(string)) | 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| string.decode(encoding=’UTF-8’, errors=’strict’) | 以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除非 errors 指 定 的 是 ‘ignore’ 或 者’replace’ |
| string.encode(encoding=’UTF-8’, errors=’strict’) | 以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是’ignore’或者’replace’ |
| string.endswith(obj, beg=0, end=len(string)) | 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
| string.expandtabs(tabsize=8) | 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 |
| string.find(str, beg=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
| string.format() | 格式化字符串 |
| string.index(str, beg=0, end=len(string)) | 跟find()方法一样,只不过如果str不在 string中会报一个异常. |
| string.isalnum() | 如果 string 至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
| string.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True, 否则返回 False |
| string.isdecimal() | 如果 string 只包含十进制数字则返回 True 否则返回 False. |
| string.isdigit() | 如果 string 只包含数字则返回 True 否则返回 False. |
| string.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| string.isnumeric() | 如果 string 中只包含数字字符,则返回 True,否则返回 False |
| string.isspace() | 如果 string 中只包含空格,则返回 True,否则返回 False. |
| string.istitle() | 如果 string 是标题化的(见 title())则返回 True,否则返回 False |
| string.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| string.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
| string.lower() | 转换 string 中所有大写字符为小写. |
| string.lstrip() | 截掉 string 左边的空格 |
| string.maketrans(intab, outtab]) | maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| max(str) | 返回字符串 str 中最大的字母。 |
| min(str) | 返回字符串 str 中最小的字母。 |
| string.partition(str) | 有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. |
| string.replace(str1, str2, num=string.count(str1)) | 把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
| string.rfind(str, beg=0,end=len(string) ) | 类似于 find()函数,不过是从右边开始查找. |
| string.rindex( str, beg=0,end=len(string)) | 类似于 index(),不过是从右边开始. |
| string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
| string.rpartition(str) | 类似于 partition()函数,不过是从右边开始查找 |
| string.rstrip() | 删除 string 字符串末尾的空格. |
| string.split(str=””, num=string.count(str)) | 以 str 为分隔符切片 string,如果 num有指定值,则仅分隔 num 个子字符串 |
| string.splitlines([keepends]) | 按照行(‘\r’, ‘\r\n’, \n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| string.startswith(obj, beg=0,end=len(string)) | 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. |
| string.strip([obj]) | 在 string 上执行 lstrip()和 rstrip() |
| string.swapcase() | 翻转 string 中的大小写 |
| string.title() | 返回”标题化”的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| string.translate(str, del=””) | 根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 del 参数中 |
| string.upper() | 转换 string 中的小写字母为大写 |
| string.zfill(width) | 返回长度为 width 的字符串,原字符串 string 右对齐,前面填充0 |
3.2 列表
3.2.1 格式
list是一种有序的集合,可以随时添加和删除其中的元素。
列表中的每个元素都分配一个数字 - 它的位置,或索引,第一个索引是0,第二个索引是1,依此类推。
list1 = ['physics', 'chemistry', 1997, 2000]list2 = [1, 2, 3, 4, 5 ]list3 = ["a", "b", "c", "d"]print("list1[0]: {}".format(list1[0])) # 访问print("list2[1:5]: {}".format(list2[1:5])) # 截取print("list3: {}".format(list3.append("e"))) # 使用append()添加元素
以上实例输出结果:
list1[0]: physicslist2[1:5]: [2, 3, 4, 5]list3: ["a", "b", "c", "d", "e"]
3.2.2 操作符
列表对 + 和 的操作符与字符串相似。+ 号用于组合列表, 号用于重复列表。
如下所示:
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 计算元素个数 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 连接 |
| [‘Hi!’] * 4 | [‘Hi!’, ‘Hi!’, ‘Hi!’, ‘Hi!’] | 复制 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| [1, 2, 3, 4, 5, 6][:3] | [1,2,3] | 切片 |
| for x in [1, 2, 3]: print x, | 1 2 3 | 迭代 |
3.2.3 常见操作
 常用方法:
常用方法:
| 方法 | 描述 |
|---|---|
| len(list) | 列表元素个数 |
| max(list) | 返回列表元素最大值 |
| min(list) | 返回列表元素最小值 |
| list(seq) | 将元组转换为列表 |
| list.append(obj) | 在列表末尾添加新的对象 |
| list.count(obj) | 统计某个元素在列表中出现的次数 |
| list.extend(seq) | 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| list.index(obj) | 从列表中找出某个值第一个匹配项的索引位置 |
| list.insert(index, obj) | 将对象插入列表 |
| list.pop([index=-1]) | 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| list.remove(obj) | 移除列表中某个值的第一个匹配项 |
| list.reverse() | 反向列表中元素 |
| list.sort(cmp=None, key=None, reverse=False) | 对原列表进行排序 |
3.2.4 列表遍历
#!/usr/bin/env python# -*- coding: utf-8 -*-if __name__ == '__main__':list = ['html', 'js', 'css', 'python']# 方法1print '遍历列表方法1:'for i in list:print ("序号:%s 值:%s" % (list.index(i) + 1, i))print '\n遍历列表方法2:'# 方法2for i in range(len(list)):print ("序号:%s 值:%s" % (i + 1, list[i]))# 方法3print '\n遍历列表方法3:'for i, val in enumerate(list):print ("序号:%s 值:%s" % (i + 1, val))# 方法4print '\n遍历列表方法4 (设置遍历开始初始位置,只改变了起始序号):'for i, val in enumerate(list, 2):print ("序号:%s 值:%s" % (i + 1, val))
3.3 元组
3.3.1 格式
Python的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
tup1 = ('physics', 'chemistry', 1997, 2000)tup2 = (1, 2, 3, 4, 5 )tup3 = "a", "b", "c", "d"# 创建空元组tup1 = ()# 元组中只包含一个元素时,需要在元素后面添加逗号tup1 = (50,)# 元组与字符串类似,下标索引从0开始,可以进行截取,组合等
默认的集合类型
所有的多对象的,逗号分隔的,没有明确用符号定义的,比如说像用方括号表示列表和用 圆括号表示元组一样,
等等这些集合默认的类型都是元组
下面是一个简单的示例:
In [14]: 'abc', -4.24e93, 18+6.6j, 'xyz'Out[14]: ('abc', -4.24e+93, (18+6.6j), 'xyz') # 默认是元组类型输出In [15]: x, y = 1, 2In [16]: x, yOut[16]: (1, 2) #默认是元组类型输出In [17]: [x,y]Out[17]: [1, 2] #明确了是[]则输出为列表
所有函数返回的多对象(不包括有符号封装的)都是元组类型。
注意,有符号封装的多对 象集合其实是返回的一个单一的容器对象,
比如:
def foo1():return obj1, obj2, obj3# 默认的作为一个包含 3 个对象的元组类型def foo2():return [obj1, obj2, obj3]# 返回一个单一对象,一个包含 3 个对象的列表def foo3():return (obj1, obj2, obj3)# 返回一个跟 foo1()相同的对象,唯一不同的是这里的元组是显式定义的
3.3.2 修改/删除
- 不可修改
python中不允许修改元组的数据,包括不能删除其中的元素
In [18]: tup = ('physics', 'chemistry', 1997, 2000)In [19]: tupOut[19]: ('physics', 'chemistry', 1997, 2000)In [20]: tup[0] = "123" # 改变元组中的值,则报错
以上实例修改元组后,会有异常信息,输出如下所示:
---------------------------------------------------------------------------NameError Traceback (most recent call last)<ipython-input-22-d8914e7dceb3> in <module>()----> 1 tup[0] = "123"NameError: name 'tup' is not defined
- “可变的”元组 ```python In [25]: t = (‘a’, ‘b’, [‘A’, ‘B’])
In [26]: t[2][0],t[2][1] = “X”,”Y”
In [27]: t Out[27]: (‘a’, ‘b’, [‘X’, ‘Y’])
tuple定义的时候有3个元素,分别是`'a'`,`'b'`和一个list。不是说tuple一旦定义后就不可变了吗?怎么后来又变了?别急,先看看定义的时候tuple包含的3个元素:<br /><br />当我们把list的元素`'A'`和`'B'`修改为`'X'`和`'Y'`后,tuple变为:<br />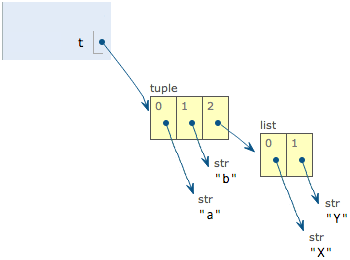表面上看,tuple的元素确实变了,但其实变的不是tuple的元素,而是list的元素。tuple一开始指向的list并没有改成别的list,所以,tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向`'a'`,就不能改成指向`'b'`,指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的!理解了“指向不变”后,要创建一个内容也不变的tuple怎么做?那就必须保证tuple的每一个元素本身也不能变.---<a name="nktYL"></a>### 3.3.3 元组运算符与字符串一样,元组之间可以使用 + 号和 * 号进行运算。这就意味着他们可以组合和复制,<br />运算后会生成一个新的元组| **Python 表达式** | **结果** | **描述** || --- | --- | --- || len((1, 2, 3)) | 3 | 计算元素个数 || (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接 || ('Hi!',) * 4 | ('Hi!', 'Hi!', 'Hi!', 'Hi!') | 复制 || (1,2,3,4,5,6)[:3] | (1,2,3) | 切片 || 3 in (1, 2, 3) | True | 元素是否存在 || for x in (1, 2, 3): print x, | 1 2 3 | 迭代 |---<a name="vhY0V"></a>### 3.3.4 元组的内置函数Python元组包含了以下内置函数| 方法 | 描述 || --- | --- || cmp(tuple1, tuple2) | 比较两个元组元素。 || len(tuple) | 计算元组元素个数。 || max(tuple) | 返回元组中元素最大值。 || min(tuple) | 返回元组中元素最小值。 || tuple(seq) | 将列表转换为元组。 || tuple.count(obj) | 统计某个元素在元组中出现的次数 || tuple.index(obj) | 从元组中找出某个值第一个匹配项的索引位置 |<a name="zk9Yc"></a>## 3.4 字典<a name="btSNW"></a>### 3.4.1 格式字典是另一种可变容器模型,且可存储任意类型对象。<br />字典的每个键值 key=>value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:```pythond = {key1 : value1, key2 : value2 }
键一般是唯一的,如果重复最后的一个键值对会替换前面的,值不需要唯一。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组(类型是否可变相关内容请点击这查看)
In [5]: dict = {} # 定义一个空字典In [6]: dict["name"] = "yuque" # 往字典中添加一对键值对In [7]: dict["name"] # 访问字典的key为"name"值Out[7]: 'yuque'In [8]: dict["url"] # 访问不存在的key值时,会报错---------------------------------------------------------------------------KeyError Traceback (most recent call last)<ipython-input-8-b730ac192bae> in <module>()----> 1 dict["url"]KeyError: 'url'--------------------------------------------------------------------------In [10]: dict["url"] = "https://www.baidu.com/" # 增加一个urlIn [11]: dict["url"] = "https://www.yuque.com/" # 已经存在的key,会将之前的value替换In [12]: dict # 打印字典Out[12]: {'name': 'yuque', 'url': 'https://www.yuque.com/'}In [13]: dict[[user]] = 1000 # 使用列表来当key,程序报错---------------------------------------------------------------------------NameError Traceback (most recent call last)<ipython-input-13-fea8cd6bd74b> in <module>()----> 1 dict[[user]] = 1000NameError: name 'user' is not defined
3.4.2 常见操作
2.1字典的增删改查

2.2 其他常见操作
| dict = {“name”:”yuque”, “url”:”https://www.yuque.com/"} | |||
|---|---|---|---|
| 方法 | 表达式 | 返回值 | 描述 |
| len() | len(dict) | 2 | 测量字典中,键值对的个数 |
| keys | dict.keys | [“name”,”url”] | 返回一个包含字典所有KEY的列表 |
| values | dict.values | [“yuque”, “https://www.yuque.com/“] | 返回一个包含字典所有value的列表 |
| items | dict.items | [(“name”,”yuque”),(“url”,”https://www.yuque.com/“)] | 返回一个包含所有(键,值)元祖的列表 |
| has_key | dict.has_key(“name”) | True | dict.has_key(key)如果key在字典中, 返回True,否则返回False |
注意:字典本身是没有下标索引的,所以字典本身是不支持切片的。
若要想要使用切片,先调用keys(),values(),items()方法,返回了列表格式才可。
In [14]: dict = {"name":"yuque", "url":"https://www.yuque.com/"}In [15]: dict[1:]---------------------------------------------------------------------------TypeError Traceback (most recent call last)<ipython-input-15-ae38b271cd00> in <module>()----> 1 dict[1:]TypeError: unhashable type
3.5 集合
3.5.1 格式
集合(set)是一个无序不重复元素的序列。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
创建格式:
parame = {value01,value02,...}或者set(value)
3.5.2 基本操作
2.1 添加元素 add
语法格式如下:s.add(x)
将元素 x 添加到集合 s 中,如果元素已存在,则不进行任何操作。
In [1]: thisset = set(("Google", "Runoob", "Taobao"))In [2]: thisset.add("Facebook")In [3]: print(thisset)Out[3]: {'Facebook', 'Google', 'Runoob', 'Taobao'}
还有一个方法,也可以添加元素,且参数可以是列表,元组,字典等,语法格式如下:s.update(x)
x 可以有多个,用逗号分开。
In [4]: thisset = set(("Google", "Runoob", "Taobao"))In [5]: thisset.update({1,3})In [6]: print(thisset)Out[6]: {1, 3, 'Google', 'Runoob', 'Taobao'}In [7]: thisset.update([1,4],[5,6])In [8]: print(thisset)Out[8]: {1, 3, 4, 5, 6, 'Google', 'Runoob', 'Taobao'}
2.2 移除元素 remove
语法格式如下:s.remove(x)
将元素 x 添加到集合 s 中移除,如果元素不存在,则会发生错误.
In [9]: thisset = set(("Google", "Runoob", "Taobao"))In [10]: thisset.remove("Taobao")In [11]: print(thisset)set(['Google', 'Runoob'])In [12]: thisset.remove("Facebook") # 不存在会发生错误---------------------------------------------------------------------------KeyError Traceback (most recent call last)<ipython-input-12-53a786b3179c> in <module>()----> 1 thisset.remove("Facebook")KeyError: 'Facebook'
此外还有一个方法也是移除集合中的元素,且如果元素不存在,不会发生错误。格式如下所示:s.discard(x)
In [13]: thisset = set(("Google", "Runoob", "Taobao"))In [14]: thisset.discard("Facebook") # 不存在不会发生错误In [15]: print(thisset)set(['Google', 'Taobao', 'Runoob'])
我们也可以设置随机删除集合中的一个元素,语法格式如下:s.pop()
In [16]: thisset = set(("Google", "Runoob", "Taobao", "Facebook"))In [17]: thisset.pop()Out[17]: 'Facebook'In [18]: print(thisset)set(['Google', 'Taobao', 'Runoob'])
2.3 集合个数 len
语法格式如下:len(s)
计算集合 s 元素个数。
In [19]: thisset = set(("Google", "Runoob", "Taobao"))In [20]: len(thisset)Out[20]: 3
2.4 清空集合 clear
语法格式如下:s.clear()
清空集合 s。
In [21]: thisset = set(("Google", "Runoob", "Taobao"))In [22]: thisset.clear()In [23]: print(thisset)set([])
2.5 是否存在
语法格式如下:x in s
判断元素 s 是否在集合 x 中存在,存在返回 True,不存在返回 False。
In [24]: thisset = set(("Google", "Runoob", "Taobao"))In [25]: "Runoob" in thissetOut[25]: TrueIn [26]: "Facebook" in thissetOut[26]: False
3.5.3 集合的运算
In [27]: s_a ={1,2,3,4,5,6}In [28]: s_b = {4,5,6,7,8,9}# 并集 ,两种写法,结果是一样的In [29]: print(s_a | s_b)set([1, 2, 3, 4, 5, 6, 7, 8, 9])In [30]: print(s_a.union(s_b))set([1, 2, 3, 4, 5, 6, 7, 8, 9])# 交集In [31]: print(s_a & s_b)set([4, 5, 6])In [32]: print(s_a.intersection(s_b))set([4, 5, 6])# 差集 A -(A&B)In [33]: print(s_a - s_b)set([1, 2, 3])In [34]: print(s_a.difference(s_b))set([1, 2, 3])# 对称差 (A|B)-(A&B)In [35]: print(s_a ^ s_b)set([1, 2, 3, 7, 8, 9])In [36]: print(s_a.symmetric_difference(s_b))set([1, 2, 3, 7, 8, 9])

若有收获,就点个赞吧
0 人点赞
