参考文章:https://blog.csdn.net/haoxin963/article/details/83245113
在如今的大部分互联网应用中,缓存的使用方式是: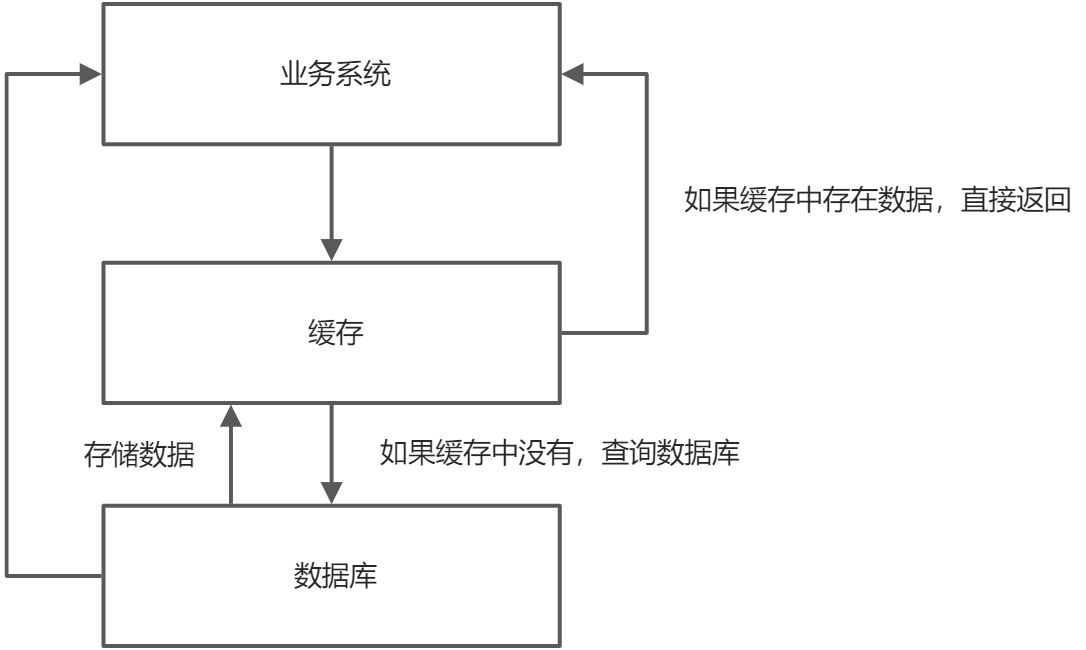
当业务系统处理请求,需要访问数据库获取数据时,先访问缓存,查找缓存中是否有需要的数据
- 如果缓存中存在数据,则直接返回
- 如果缓存中没有数据,则需要访问数据库,查询到数据后返回,并选择是否要保存到缓存中
1. 缓存穿透
1.1 问题描述
要访问的数据在数据库中不存在,当业务系统发起查询操作时,按照传统的步骤,会先访问缓存,而缓存中没有要查询的数据,那么就会直接访问数据库,并且数据库中也不存在要查询的数据,所以之后的每次访问都会绕过缓存直接访问数据库,这就造成了缓存穿透的问题
缓存穿透发生的原因:黑客的恶意攻击,故意使用大量的不存在的数据请求访问服务器,而服务器需要直接访问数据库,数据库支撑不了这样大的请求量而崩溃,进而导致整个服务崩溃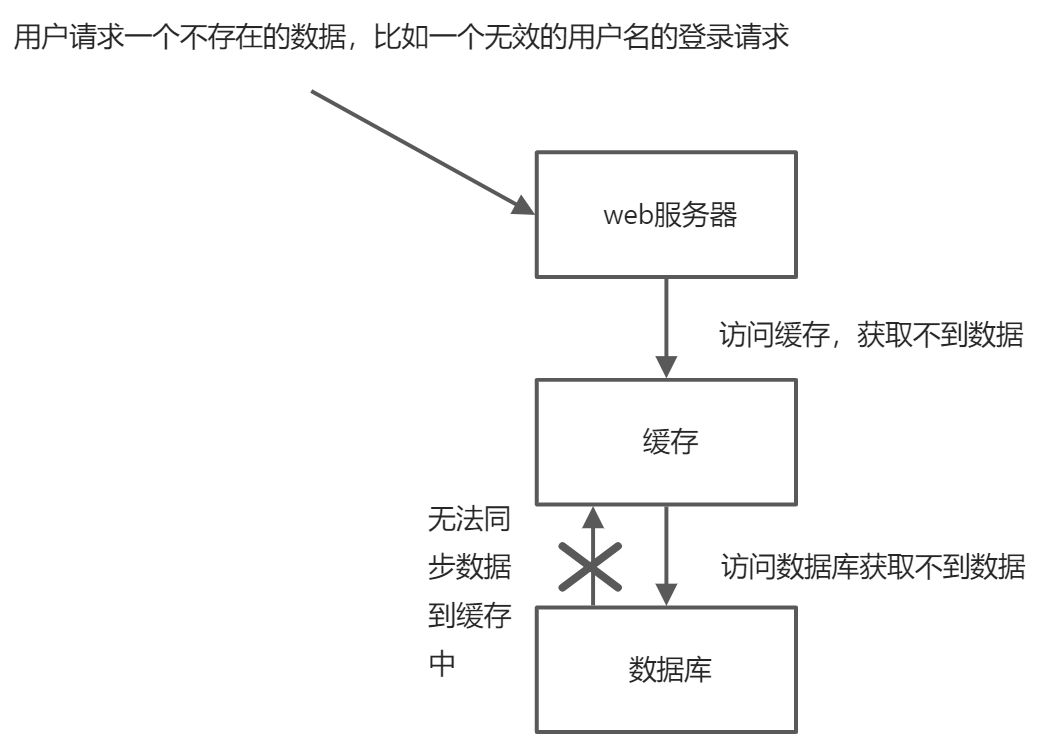
1.2 解决方案
- 一个比较简单的方案就是把这些空数据缓存起来,如果一个查询返回的结果为空,仍然把这个空数据存储到缓存中,那么下次再接收到这样的请求之后,可以直接从缓存中返回空值;为了节省缓存的容量,可以将这些空值的过期时间设置的短一点,比如一两分钟的样子
布隆过滤器,把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。
简单介绍一下布隆过滤器: 布隆过滤器实际上是一个bit 向量或者说 bit 数组:[0,0,0,0,0,0,0,0] 如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1 现在有一个请求是www.baidu.com,缓存baidu的值,假设现在有三个hash函数生成了1,2,3,则布隆过滤器就变为:[1,1,1,0,0,0,0,0] 布隆过滤器判断一个key是否存在的步骤是:
- 按照之前的hash函数计算key的hash值
- 得到值之后判断位数组中的每个位置是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个位置的值不为 1,说明该元素不在布隆过滤器中。
布隆过滤器也会出现误判的情况,比如现在又有一个请求www.bilibili.com,计算出bilibili的hash值也为1,2,3,而恰好这三个位置上的值都为1,布隆过滤器会认为这个值是存在的,而将请求放行
进行实时监控,当发现Redis的命中率开始急速降低,需要排查访问对象和访问的数据,和运维人员配合,可以设置黑名单限制服务
2. 缓存击穿
2.1 问题描述
业务系统所要访问的数据存在于数据库中,但不存在于缓存中(一般来说是因为key过期了),而刚好又有大量的请求要访问这个数据,进而导致这些请求全部压到数据库上,导致数据库崩溃,这就是缓存击穿

2.2 解决方案
- 预先设置热门数据,在Redis高峰访问期到来之前,把一些热门的数据提前存入到缓存中,并且加大这些热门数据key的过期时间,或者设置不过期
- 实时调整,现场监控哪些数据热门,实时调整key的过期时长
- 使用锁,当缓存中的数据失效时,多个请求访问缓存获取不到数据,这时,只有第一个访问缓存的请求可以去访问数据库,即第一个访问缓存的请求给缓存上锁,此时后面到达缓存的其他查询请求将无法查询该字段,从而被阻塞等待;等到第一个线程从数据库获取到数据,并将缓存的值更新之后,其他线程被唤醒,并可以直接从缓存中获得数据
3. 缓存雪崩
3.1 问题描述
在同一时刻,缓存中有大量的key过期,而业务系统的服务又有大量的请求需要获取数据,这时,就有大量的请求直接落到数据库上,可能导致数据库崩溃
这里与缓存击穿的区别在于,缓存击穿是因为一个热点数据的key过期导致大量请求直接落到数据库,而缓存雪崩是大面积的key过期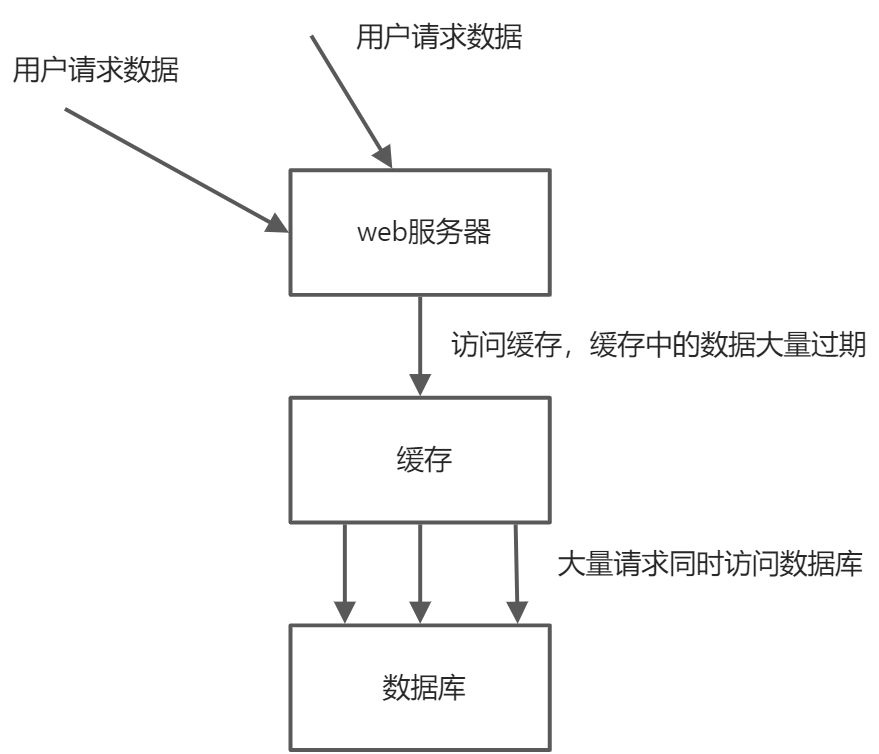
3.2 解决方案
- 使用缓存的集群模式,比如Redis集群,或者使用多级缓存架构,比如nginx缓存 + redis缓存 + 其他缓存
- 针对缓存雪崩出现的原因:同一时刻大量的key过期,将缓存中数据失效的时间错开,在原有缓存失效时间的基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。

若有收获,就点个赞吧
0 人点赞
