那话话不多说 我们就开始今天的一个学习之旅吧
嗯 其实对于图游走类算法来说呢
它的一个目标就是我们要学习出图中每一个节点的低维表示
也就是这个node embeddings
然后再得到这个node embeddings 之后呢
就可以利用这些低维表示来进行接下来的下游任务
也就是节点分类之类的
那这也是为什么同学们在做我们的作业一的时候发现啊
我们在运行地啊 两个命令
第一个是training 啊training
我训练我们的地 我模型第二个就是把我们的定位模型用到呃链接预测零
station 那里我们就分为了两个步步骤
那呃为什么这个低维表示可以用来做下游任务呢
是因为我们利用了啊这样的一个图 有种类算法
来使得我们这个学习到的embedding 可以
嗯 学习到节点跟它的一个邻居的关系
然后更好的表示图结构与图特征的信息
那要怎么得到这个not
embedding
同学们就要继续听下去了
系统声音调大
呃 其实在第一节课的时候嗯
我有简单的提到图游走类算法的一个模式
那在这里我们进行一个简单的回顾
比如说对于这样的一张图
我们要在图上做游走的过程 那怎么游走呢
那怎么游走呢 我们可以简单的看一下这个动图
呃 这是一个非常粗糙的动图 大家不要嫌弃
呃 通过这个动图呢
相信大家已经比较清楚图有种类算法的一个本质了
那我们最开始呢就是在图
图上进行多次的游走
游走之后得到多条的一个游走序列
然后得到这个序列之后呢 再通过图表示学习
然后学习到节点 利用节点之间的关系
来学习节点的低维表示
然后再得到这些表示之后呢 再用它们来做下游任务
嗯 那我有点好奇 大家在看到这个节点序列的时候
可不可以联想到自然语言处理当中的什么概念 也就是
n l p 当中的什么概念呢
好 给大家一个提示
看我们的节点是不是可以看作n lp 当中的词
然后节点序列可以联想成啊n l p 当中的句子呢
嗯 那接下来我们就要引入n l p 领域当中的一个算法
Word2vec
好 注意前方即将迎来新内容 Word2vec
呃 奇怪 为什么我明明在讲图学习
现在却要讲n lp领域的内容呢
那就是因为我有种类算法
他在最开始的时候参考的就是nlp领域当中的这个Word2vec 的模型 呃
因此呢我们在这里需要先简单的介绍一下Word2vec
嗯 为了让大家对我举办的思想有一个初步的认识啊
这里我先举一个苹果的例子
比如说呃我单单的给出苹果这个词 而没有其他的信息
那可能对于不了解苹果的同学来说
这个词的词义是模糊的 嗯
因为这个苹果它可能指可以吃的
然后也有可能指啊大家的手机啊 电脑之类的这个苹果
但是如果我给出啊很多关于苹果的句子呢
可以看到 我这里给出了很多这个关于苹果的句子
比如说苹果营养价值很高 富含矿物质和维生素
啊 比如说所有的水果里我最爱吃苹果了等等
那通过这些多个句子的上下文
大家应该知道我所要展示的这个苹果它的词义是一种水果
一种食物等等 那通过这个例子
大家可以大概的得出一个结论啊 词的语义由其上下文来决定
那Word2vec其实就是利用了这样的一个思想
那它是怎么做的呢
接下来呢我们就来看一下Word2vec
是怎么建模这种上下文的语义关系的
那在Word2vec 当中呢 他其实提出了两种模型结构
用于学习词向量
分别是c 报和skip gram
那因为我们的图有种类算法
呃 用到的更多是skip gram 模型
因此呢我们这里就只介绍一下啊skip gram 模型
那skip gram目的很简单
就是希望我们可以给定中心词
然后预测中心词它对应的一个上下文
啊 什么是中心词呢 比如说我们给定了p p t上面这个句子
那我们就假设neighbors 是中心词
同时我们设置我们的
窗口大小是三
比如说啊这个这个窗口大小表示的就是呃左右两中心词
左右两边的这个上下文的词数
因此呢呃我们的center word
就是neighbors 那它对应的这个contextword
就是啊uniformly from the 还有 of the last
还有这六个词
呃 下面我们看一下skip gram的一个模型结构
那这个嗯模型架构图我们可以看到 它分为了三三层吧
第一层就是一个输入层 那输入层就是
中心词的一个one-hot的表示 一个one-hot的向量
呃 当one-hot对应的值为一的时候
那这就是你啊中心词所在的一个完好的向量了
那在经过中间的这一层
中间的这一层呢就是一个投影层
它其实也对应了我们单词的一个一维的向量
那最后一呃最后一层就是我们的输出层了
哦 我们在通过输出层呢呃就是一个soft max 层
在soft max层来预测我们的对应的这个上下文的词啊
那这里我要补充的一点是呢 我们使用这个skip gram
模型的本质 并不是为了说要多么准确的在最后一层
预测出啊我们的这个context word
我们是想要得到模型训练完毕的这个副产物
那这个副产物是什么
就是我们呃中间这个hidden layer
呃 这个层呃这个参数
也就是这个w
那我们这样就简略的讲完了这个skip gram
模型 那对于它怎么实现的
我们到作业里面会大家可以看一下我们的代码
那接下来就讲一讲Word2vec
在最后一层的输出层 它所用到的一个优化的方法
最后一层刚刚我们讲了是一个soft max 分类层
那大家都学过 呃 有一定深度学习基础的
应该都知道soft max 是用来干什么的吧
嗯那这里我就简单的举一个例子
假设呢我们给定了这个中心词orange 然后我们要预测
嗯 我们要预测它的一个上下文中的词 也就是juice
那呃在这里我们看到juice 它对应的概率是最高的是零点六
那我们要预测它嗯是我们的这个上下文字
其实我们除了要预测得到句子的概率
同时呢我们也要把整个词表当中
啊其他所有词的单所有单词的概率都预测一遍
那这样这样子的话呢 我们这个计算词表的嗯
概率是呃非常多的
嗯 这个时候我们可以看到
其实我们这个计算量也是非常大的
那这里被我的这个呃头像挡住的地方 就是计算量大四个字了
那因此呢作者就提出了嗯负采样的方法进行一个优化
因为说softmax 的计算量太大了
不采样的思想理解起来也比较简单
那我这里就非常通俗易懂的让大家来看一下它是什么意思
首先我们将中心词对应的那个上下文词作为正样本
比如说对于这个中心词来说
juice 就是它的正样本那
嗯 同时呢我们选取一定数量的负样本 比如说p p t
上我展示了三个副样本 alien happy 还有zero
那确定好了正负样本之后呢
我们就不再需要计算所有词的概率了
而只需要对这几个样本进行一个分类 那怎么分类呢
我们把这样本它的一个lable标签设置为一
然后把负样本的标签设置为零
那这个时候我们就通过把soft max
修改成了多个的Multiple sigmoid
函数是一个二分类的函数 把这个
呃 softmax 层修改成了多个的sigmoid层
那这个时候呢呃我们就只需要计算四个概率了
那接下来呢呃继续刚才的内容
那我们看到我们的softmax层就变成了多个sigmoid的层
从而减少了计算量啊
那到这里呢 我准备的一个整体架构就比较清清晰了 呃
在我们所讲解的这个Word2vec 算法当中呢
其实有针对性的选择了一些内容来讲
嗯 比如说我们这节课 我们就只把Word2vec
当做skip gram加负采样 那就构成了我们的Word2vec
那在skip gram模型训练完毕之后呢
就可以获取需要的这个词表示了
那讲完了 Word2vec到最后呢
我们接下来看一下它是怎么应用到这个图嵌入领域的
那在前面我们讲Word2vec 思想的时候说过
呃 词的语义由其上下文来决定
那么我们可能会联想啊
在图中节点是不是也会受到邻居的影响呢
这里我们举一个社交网络当中的例子
呃 中国有一句古话 近朱者赤 近墨者黑啊
也就是说在我们这样的一个社交圈子当中呢
周遭的环境对我们 对我们来说是会有一定的影响的
那嗯其实也表现为图中的节点会受到我们这个邻居的影响
呃 甚至呢我们可以用呃邻居来表示我们当前的这个中心节点 嗯
比如说嗯更加嗯举更加例具体的例子
比如我们在家庭环境当中啊
我们就会受到父母的影响嗯
在学校环境下也会受到老师和同学的影响
那呃这种情况也不单单存在于这个社交网络 然后 这个范围内
那其他的很多图啊 网络啊都会有这样的一个这样的一个规律
也就是图中的节点通常会受到邻居的影响
那这也是为什么我们可以把Word2vec 这个算法呃迁移到这个图嵌入领域
两者其实是有相通之处的之处的
那因此呢接下来我们就讲一讲第一个图 有种类算法DeepWalk
好 下面我们要讲一下DeepWalk了
所有种类算法的一个鼻祖就是DeepWalk模型
那它是一个将我们的这个n l p领域的思想运用到图嵌入领域的模型
前面我们讲到呢图中的节点
我们可以把它映射成我们n l p当中的一个单词
然后我们也可以把啊游走得到的这个结点序列
当成n l p 当中的句子
那我们可以看一下
就是对于这个n lp 来说
我们是不是呃有非常多的语料可可以直接让我们获得这些句子了呢
也就是说n lp的句子是可以直接获取的
那对于图我们要怎么得到这个节点序列呢
那在DeepWalk当中呢 他提出提出来我们要用random walk
一个一个游走方式
那这里我们简单的看一看这个例子 在呃random 当中呢
我们的具体过程就是比如说从某个节点出发 然后
随机的往下走 那我们游走的每一步呢都是与和这个点相邻的节点
继续往下走 然后再从中随机的选择一条到达某一个节点
在啊重复这个过程
直到我们呃到达了 最大的一个游走长度
或者说再也无法走下去
那在走走了多趟之后呢
就得到了这个嗯多个的游走序列
这个时候这些序列其实就可以类比
我们刚刚提到的这个n l p 当中的句子
那随机游走的本质其实就是一个可以回头的d f s
为什么说它可以回头呢 我们可以看一下这个a b a 的例子
那因为这是一个啊无向图 然后我们从a
出发任意的选择下一条往下走
我们走到了b
那b 的话它也有两条边走
那我们也可以回到有可能回到a 的这个节点
那因此说我们就说DeepWalk是一个
可以回头的d f s
那如果我们把呃一般的随机游走表示成公式的话呢
我们可以得到这个式子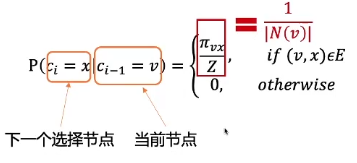
那对于这个式子来说呢
v 点就是我们当前的这个节点
然后哦
d f s 就是深度优先搜索
是数据结构当中的一个概念哦
然后c i 减1就这个是我们当前的节点
然后c i等于x 呢就是我们下一个要有呃要选择的节点
呃 呃这边呢
这个时候呢呃如果我们v x 之间有边相连的话
那它就加入到我们可以被选择的一个候选集里面
那对于DeepWalk来说
对于DeepWalk来说呃
我们的被选择的呃概率是等概率的
那这个时候呃对应的这个概率公式就等于大n v 的呃绝对值分之一
那这里的大n
就表示v 的一个邻居节点大n v 然后加一个绝对值的符号
那这就表示啊它所具有的这个邻居节点的一个个数
那这就是我们的这个呃random walk 一个公式的表示
等概率的话怎么选 那你就可以随机非常随机的选择啦
嗯 然后呢 那在DeepWalk当中呢
我们就针对这个图中的每个节点进行多次的采样
然后得到这些节点序列之后呢
就可以套用这个Word2vec 模型的
那这个大Z
其实是一个归一化后的概率分布啊
原始的概率分布就是这个
那比啊比如说等概率的前提下
我们每每一个节点都有一个一被选中的一的概率
那对这个概率进行归一化那
嗯 大概其实就对应到了我们的这个呃大nv
这个这个绝对值了
嗯 那到这里的话 我们的这个DeepWalk模型就整体架构就讲解完毕了
可以看到呢我们和Word2vec 的一个区别就在于
我们需要在图中先进行一个随机游走的过程
然后呢就可以继续套用之前的这个skip gram模型
以及这个负采样的模型
那在这里我可能还要提一下的就是
呃大部分的图游走在算法
它都是针对针对我们这个游走部分做一个呃创新和改动的
并且呢在他呃他在后续的时候呢
训练方式都和Word2vec 一致
也就是说 对于图游走的算法
我们可以更多的关注游走的这一块
那这里我们再来一个再提一个啊互动问题吧
就是呃DeepWalk的话
也就是说在图中我们要怎么选择负样本呢
啊 图游走是可以用于图分类的
我们在图游走之后
然后通过这个skip gram 模型来训练 训练
得到了多个节点的embedding
再利用这个节点embedding 来做图图的一个节点分类
嗯
没错 就是随机采样 嗯
因为我们的图通常是非常巨大的
那这个时候只要在这个图里面随机的选择样本就可以了
那通常呢啊
啊 频出现频率高的节点被选中的这个概率也比较大
那我们别看这个DeepWalk
虽然它的这个呃可以再讲一下刚才那个概率吗
嗯 这个概率其实是一个等概率的方式
就是你的每一个每一个邻居节点它都有被选中的可能
而且它被选中的这个
可能是 而且他被选中的可能是啊相同的好
我们继续接下来的
那可能听完这个DeepWalk讲解的同学会发现呢呃
底部会有一个比较大的缺点
就是呃他忽略了这个图 其实是一个复杂的结构
那前面我们也有讲到呃DeepWalk 在选择随机游走的这个
下一个节点的时候
它的这个方式是一个均匀随机采样的
然后非常的简单直接
那同时呢嗯他的一个游走过程其实就是一个深度优先搜索的过程
然后那刚有同学问深度优先搜索是什么那
我觉得你还是要去补一下数据结构的知识
那深度优先搜索呢其实是只关注到呃图的一个结构相似性
我们可以再看一下下面的这张图啊
蓝色的箭头呢它的含义就代表了我们是一个d f s 的过程那
大家可以看到它其实就是对图的一个全局的结构进行一个搜索
那其实除了深深度优先搜索以外呢
同学们应该还还可以想到一个
宽度优先搜索的概念
那可以看到红色的这箭头就是宽度优先搜索
那宽度优先搜索它更倾倾向于获取图的一个局部相似性
毫无疑问呢 如果我们可以同时结合两种啊模式的话
就可以更加全面的就对我们的这个图结构进行探索和学习了
那接下来我们就要讲一下这个node2vec 模型
呃 前面前面我刚讲第一步的时候有讲这个公式 那这里我们
再详细的讲一下吧 就是对于一般的这个随机游走公式来说呢
呃我们可以表达成这样的一个式子
其中啊v节点就是当前的节点
然后接下来我们要确定他下一个游走的节点 也就是x
那我们就需要和呃我们当前节点有边的这个节点
在其中进行一个选择
要满足某一个概率分布
那对于这样的一个公分分布呢
它其实是一个归一化之后的一个转转移概率分布
大Z呢其实是一个归一化的分子
那 就是一个原始的概率分布
就是一个原始的概率分布
比如说我们在DeepWalk当中呢
这个 其实就是等于一了
其实就是等于一了
然后这个大Z其实就是我们这个啊 邻居节点的个数
当前节节点的邻居节点的个数
那呃node2vec 他说他要修改这样的一个公式
那显然呢他就需要修改我们的这个原始的概率分布了
也就是这个
那在呃真的讲解这个node2vec 算法之前呢
我们我们先来定义三个前提
那大家要看一下我们这个图
盯紧了不要啊 走神了
其中呢v 点就是我们当前正在访问的节点啊
可以看到它是一个红色的节点啊
红色的字体的一个节点
嗯 然后呢 我们看一下
t节点t节点是黑色的字体节点
它表示上一个访问的节点
也就是说我们是先访问了t节点
然后下面我们正在访问v节点
然后呢呃是x 一x 二和x 三三个绿色的节点
那他们表示呃节点v 它未访问的这个邻居节点
那大家要记住这三个概念
我们后续会用这个概念来计算node2vec 提出的这个概率分布
呃 这个呢是node2vec 的一个公式 那首先我们看一下
右边这个 表示什么
表示什么 表示啊一个边的权值边的权重
表示啊一个边的权值边的权重
也就是说啊它在计算它的一个原始概率的时候呢
把我们这个边的权值也考虑进去了
那这也是DeepWalk没有做到的一点
DeepWalk 它没有考虑到边的全值全值
下面我们再看一下这个阿尔法公式的一个概念
那阿尔法公式是等于这样的 三种情况
我们先不来看
呃 我们先来了解一下这个 代表什么样的含义
代表什么样的含义 表示我们当前这个节点v 它的一个一阶邻居
表示我们当前这个节点v 它的一个一阶邻居
到我们节点t的距离
那我们就放到这个图里面来理解一下
对于这个节点t 它到我们自身的距离 那就是
零了显然就是零
那对于 节点来说
节点来说
它与我们的节点t有边相连 那 显然就是1了
显然就是1了
对于这个节点来说
那嗯对于 和
和 节点呢 他们都需要经过v
节点呢 他们都需要经过v
才能到达t节点
那显然呢他们的呃这个距离就是2了
那阿尔法公式呢就是针对这样的三种情况
三种距离情况给他们分别赋赋值赋值我们的这个概率
比如说对于这个呃上一个访问过的节点节点 t 
等于零的时候 那访问概率是p 分之一
对于这个 等于1也就是节点x 一的情况下呢
等于1也就是节点x 一的情况下呢
访问概率是一
对于剩下的两个x 二x 三节点当中呢 我们的访问概率就是q
分之一了
那大家可能会感到疑惑
就是呃为什么呃阿尔法公式里面的这个p
q 它是怎么确定的呢 然后
嗯 他们其实是算法当中的超参数
然后我们就是利用这两个参数来调整呃
我们的一个游走的程度
那我们下面就来具体的探讨一下这三呃这三种情况下
我们会偏向于啊深度优先搜索还是广度优先搜索
就来探讨一下他们的三种情况
比如说 嗯
当我们的 等于零的时候呢
等于零的时候呢
我们其实是在重新访问上一个访问过的节点
可以看到它的访问概率是p 分之一
嗯 那这个p 分之一呢就决定了我们是否要go back
是否要回到上一个节点 当我们的p 非常小的时候
p分之一就会非常大
非常大的话 显然我们访问这个节点t的概率也很大
那这个时候就啊有很大的概率可以go back
接下来我们再来看一下另外的两个情况
嗯 假如我们以这个一的原始概率访问了我们的x 一节点
那这个时候我们是
呃 访问过了t 之后呢 再访问了v 节点 再访问这个x1
节点
那可以看到这个过程其实非常类似于一个宽度优先搜索的过程
呃 当我们以q 分之一的原始概率分别啊
可能随机访问了x 二和x 三节点的时候呢那
那这个时候就很像一个深度优先搜索的过程了
我们先访问了t 再访问v 再访问x 二点
大家可以看到 我们其实是利用这个呃参数q 超参数q
来控制我们的这个呃宽度 优先搜索还是呃深度优先搜索
当我们的q 比较大或者说非常大的时候呢
嗯这里的访问概率其实是零了 那相对的我们的
算法就会更加倾向于走b f s 或者嗯go back
那嗯在b f s 和b f s 之间呢
它就更倾向于回到我们的这个宽度优先搜索
那当q 非常小的时候呢 那啊这个值可能会非常大
那这个时候我们就会倾向于走d f s
那这个地方大大家有没有听清楚呢
最后我们再来看一下 当我们的p 等于q 等于一的时候呢
我们的这个原始概率 就等于
就等于 了那
了那
也就是说我们现这个原始概率分布就等于我们的边的权值
那边的权值越大的话 它就有可能啊被选中的概率也就越大了
那到这里我们就把Node2vec的这个bias random walk讲完了
嗯 那他后面的模型部分呢也和我们的deepwalk一样了
就是嗯在skip gram
把我们的通过biased random walk
获得的多个游走训练
输入到我们的这个skip gram模型进行一个训练
训练完之后获得节点embedding
然后再用于下游任务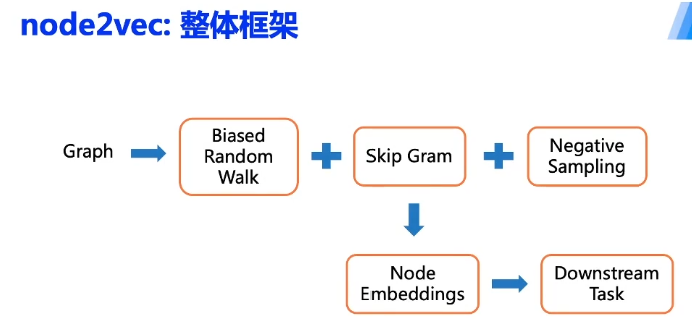

若有收获,就点个赞吧
0 人点赞
