报文格式
所有的HTTP报文都可以分为两类:请求报文(request message)和 响应报文(response message)。请求报文会向Web服务器请求一个动作。响应报文会将请求的结果返回给客户端;请求和响应报文的基本报文结构相同。
请求报文格式
请求报文的格式如下图所示,它主要包含3个部分:起始行(请求行),请求头和请求主体。每个部分结尾要换行,并且请求头与请求主体之间需要用空行隔开。
🔶可以将请求报文格式简写为如下所示:
<method> <url> <version><headers><entity-body>
🔶请求报文示例:**
POST /index.html HTTP/1.1Host: 127.0.0.1Connection: keep-aliveContent-Length: 39Authorization: Basic YWRtaW46YWRtaW4xMjM=Accept: */*hello service!i am a request-message.
响应报文格式
响应报文的格式如下图所示,它与请求报文格式唯一不同在于起始行。
🔶可以将响应报文格式简写为如下所示:
<version> <status> <reason-phrase><headers><entity-body>
🔶响应报文示例:
HTTP/1.1 200 OKContent-type:text/htmlhi~
报文结构
起始行
所有的HTTP报文都以一个起始行作为开始。请求报文的起始行说明了要做些什么;响应报文的起始行说明发生了什么。
(1) 请求行**
请求报文请求服务器对资源进行一些操作。请求报文的起始行,或称为请求行,包含了一个方法和一个请求URL,这个方法描述了服务器应该执行的操作,请求URL描述了要对哪个资源执行这个方法。请求行中还包含HTTP的版本,用来告知服务器,客户端使用的是哪种HTTP。所有这些字段都由空格符分隔。在HTTP/1.0之前,并不要求请求行中包含HTTP版本号。下面是对请求行的简要描述:
- 方法(method):客户端希望服务器对资源执行的动作。是一个单独的词,比如GET、HEAD或POST。
- URL(request-URL):命名了所请求资源,或者URL路径组件的完整URL。如果直接与服务器进行对话,只要URL的路径组件是资源的绝对路径,通常就不会有什么问题——服务器可以假定自己是URL的主机/端口。
- 版本(version):报文所使用的HTTP版本,其格式为:
HTTP/<major>.<minor>其中主要版本号(major)和次要版本号(minor)都是整数。
(2) **响应行**
响应报文承载了状态信息和操作产生的所有结果数据,将其返回给客户端。响应报文的起始行,或称为响应行,包含了响应报文使用的HTTP版本、数字状态码,以及描述操作状态的文本形式的原因短语。所有这些字段都由空格符进行分隔。在HTTP/1.0之前,并不要求在响应中包含响应行。下面是对响应行的简要描述:
- 版本(version):报文所使用的HTTP版本,其格式为:
HTTP/<major>.<minor>其中主要版本号(major)和次要版本号(minor)都是整数。 - 状态码(status-code):这三位数字描述了请求过程中所发生的情况。每个状态码的第一位数字都用于描述状态的一般类别(成功或出错等)。
- 原因短语(reason-phrase):数字状态码的可读版本,包含行终止序列之前的所有文本。本章稍后提供了HTTP规范定义的所有状态码的原因短语示例。原因短语只对人类有意义,因此,比如说,尽管响应行HTTP/1.0200 NOT OK 和 HTTP/1.0200 OK 中原因短语的含义不同,但同样都会被当作成功指示处理。
首部
HTTP首部指请求头和响应头,首部字段向请求和响应报文中添加了一些附加信息。本质上来说,它们只是一些键值对的列表。比如,下面的首部行会向Content-Length首部字段赋值19:
GET /index.html HTTP/1.1Host: 127.0.0.1Content-Length: 19
(1) **首部分类**
HTTP规范定义了几种首部字段。应用程序也可以随意发明自己所用的首部。HTTP首部可以分为以下几类。
- 通用首部:既可以出现在请求报文中,也可以出现在响应报文中。
- 请求首部:提供更多有关请求的信息。
- 响应首部:提供更多有关响应的信息。
- 实体首部:描述主体的长度和内容,或者资源自身。
- 扩展首部:规范中没有定义的新首部。
每个HTTP首部都有一种简单的语法:名字后面跟着冒号 “:”,然后跟上可选的空格,再跟上字段值,最后是一个换行(CRLF)。
(2) 首部延续行
将长的首部行分为多行可以提高可读性,多出来的每行前面至少要有一个空格或制表符(tab)。在下面的例子中,响应报文里包含了一个Server首部,其完整值被划分成了多个延续行。
HTTP/1.0200 OKContent-Type: image/gifContent-Length: 8572Server: Test ServerVersion 1.0
主体部分
HTTP报文的第三部分是可选的实体主体部分。实体的主体是HTTP报文的负荷。就是HTTP要传输的内容。HTTP报文可以承载很多类型的数字数据:文本、JSON文档、XML文档、图片、视频、HTML文档、软件应用程序、信用卡事务、电子邮件等。
HTTP 1.0/1.1/2.0 的区别
HTTP/1.1 相比 HTTP/1.0 性能上的改进:
- 使用 TCP 长连接**的方式改善了 HTTP/1.0 短连接造成的性能开销。在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP/1.1中默认开启长连接keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。HTTP1.0需要使用keep-alive参数来告知服务器端要建立一个长连接。
- 节约带宽:HTTP1.0中存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能。HTTP1.1支持只发送header信息(不带任何body信息),如果服务器认为客户端有权限请求服务器,则返回100,客户端接收到100才开始把请求body发送到服务器;如果返回401,客户端就可以不用发送请求body了节约了带宽。
HTTP/1.1 还是有性能瓶颈:
- 请求 / 响应头部(Header)未经压缩就发送,首部信息越多延迟越大。只能压缩 Body 的部分;
- 发送冗长的首部。每次互相发送相同的首部造成的浪费较多;
- 服务器是按请求的顺序响应的,如果服务器响应慢,会招致客户端一直请求不到数据,也就是队头阻塞;
- 没有请求优先级控制;
- 请求只能从客户端开始,服务器只能被动响应。
HTTP/2.0 相比 HTTP/1.1 性能上的改进:
- 多路复用:HTTP/2 是可以在一个连接中并发多个请求或回应,而不用按照顺序一一对应。移除了 HTTP/1.1 中的串行请求,不需要排队等待,也就不会再出现「队头阻塞」问题,降低了延迟,大幅度提高了连接的利用率。
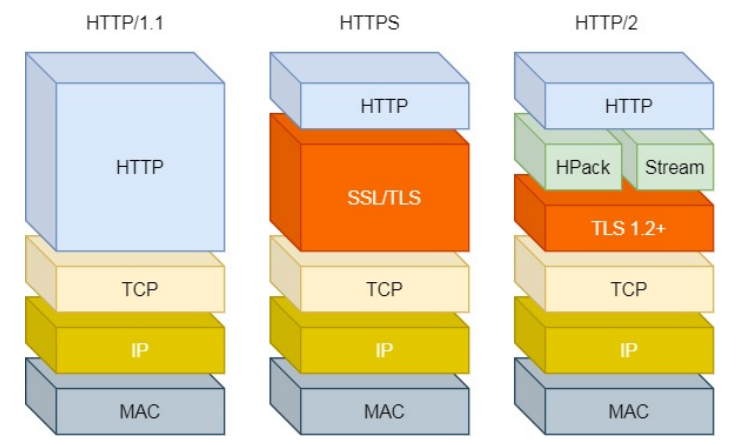
- 数据压缩:HTTP1.1不支持header数据的压缩,HTTP2.0使用HPACK算法对header的数据进行压缩,这样数据体积小了,在网络上传输就会更快。
- 服务器推送:当我们对支持HTTP2.0的web server请求数据的时候,服务器会顺便把一些客户端需要的资源一起推送到客户端,免得客户端再次创建连接发送请求到服务器端获取。这种方式非常合适加载静态资源。服务不再是被动地响应,也可以主动向客户端发送消息。举例来说,在浏览器刚请求 HTML 的时候,就提前把可能会用到的 JS、CSS 文件等静态资源主动发给客户端,减少延时的等待,也就是服务器推送(Server Push,也叫 Cache Push)。
- 二进制格式:HTTP/2 不再像 HTTP/1.1 里的纯文本形式的报文,而是全面采用了二进制格式,头信息和数据体都是二进制,并且统称为帧(frame):头信息帧和数据帧。
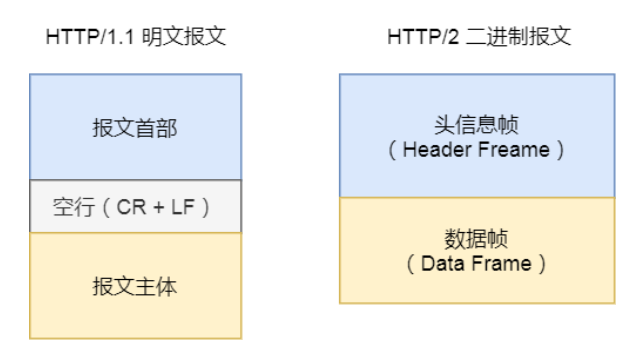
- 数据流:HTTP/2 的数据包不是按顺序发送的,同一个连接里面连续的数据包,可能属于不同的回应。因此,必须要对数据包做标记,指出它属于哪个回应。每个请求或回应的所有数据包,称为一个数据流( Stream )。每个数据流都标记着一个独一无二的编号,其中规定客户端发出的数据流编号为奇数, 服务器发出的数据流编号为偶数客户端还可以指定数据流的优先级。优先级高的请求,服务器就先响应该请求。
客户端识别与cookie机制
Web服务器可能会同时与数千个不同的客户端进行对话。这些服务器通常要记录下它们在与谁交谈,而不会认为所有的请求都来自匿名的客户端。
HTTP最初是一个匿名、无状态的请求/响应协议。服务器处理来自客户端的请求,然后向客户端回送一条响应。Web服务器几乎没有什么信息可以用来判定是哪个用户发送的请求,也无法记录来访用户的请求序列。现代的Web站点希望能够提供个性化的接触。它们希望对连接另一端的用户有更多的了解,并且能在用户浏览页面时对其进行跟踪。
HTTP并不是天生就具有丰富的识别特性的。早期的Web站点设计者们都有自己的用户识别技术。每种技术都有其优势和劣势。下面列出了几种用户识别的解决方案:
- 承载用户身份信息的HTTP首部。
- 客户端IP地址跟踪,通过用户的IP地址对其进行识别。
- 用户登录,用认证方式来识别用户。
- 胖URL,一种在URL中嵌入识别信息的技术。
- cookie,一种功能强大且高效的持久身份识别技术。

若有收获,就点个赞吧
0 人点赞
