MySQL驱动程序安装:
我们使用Django来操作MySQL,实际上底层还是通过Python来操作的。因此我们想要用Django来操作MySQL,首先还是需要安装一个驱动程序。在Python3中,驱动程序有多种选择。比如有pymysql以及mysqlclient等。这里我们就使用mysqlclient来操作。mysqlclient安装非常简单。只需要通过pip install mysqlclient即可安装。
常见MySQL驱动介绍:
MySQL-python:也就是MySQLdb。是对C语言操作MySQL数据库的一个简单封装。遵循了Python DB API v2。但是只支持Python2,目前还不支持Python3。mysqlclient:是MySQL-python的另外一个分支。支持Python3并且修复了一些bug。pymysql:纯Python实现的一个驱动。因为是纯Python编写的,因此执行效率不如MySQL-python。并且也因为是纯Python编写的,因此可以和Python代码无缝衔接。MySQL Connector/Python:MySQL官方推出的使用纯Python连接MySQL的驱动。因为是纯Python开发的。效率不高。操作数据库
Django配置连接数据库:
在操作数据库之前,首先先要连接数据库。这里我们以配置
MySQL为例来讲解。Django连接数据库,不需要单独的创建一个连接对象。只需要在settings.py文件中做好数据库相关的配置就可以了。示例代码如下:DATABASES = {'default': {# 数据库引擎(是mysql还是oracle等)'ENGINE': 'django.db.backends.mysql',# 数据库的名字'NAME': 'dfz',# 连接mysql数据库的用户名'USER': 'root',# 连接mysql数据库的密码'PASSWORD': 'root',# mysql数据库的主机地址'HOST': '127.0.0.1',# mysql数据库的端口号'PORT': '3306',}}
在Django中操作数据库:
在
Django中操作数据库有两种方式。第一种方式就是使用原生sql语句操作,第二种就是使用ORM模型来操作。这节课首先来讲下第一种。
在Django中使用原生sql语句操作其实就是使用python db api的接口来操作。如果你的mysql驱动使用的是pymysql,那么你就是使用pymysql来操作的,只不过Django将数据库连接的这一部分封装好了,我们只要在settings.py中配置好了数据库连接信息后直接使用Django封装好的接口就可以操作了。示例代码如下:# 使用django封装好的connection对象,会自动读取settings.py中数据库的配置信息from django.db import connection# 获取游标对象cursor = connection.cursor()# 拿到游标对象后执行sql语句cursor.execute("select * from book")# 获取所有的数据rows = cursor.fetchall()# 遍历查询到的数据for row in rows:print(row)
以上的
execute以及fetchall方法都是Python DB API规范中定义好的。任何使用Python来操作MySQL的驱动程序都应该遵循这个规范。所以不管是使用pymysql或者是mysqlclient或者是mysqldb,他们的接口都是一样的。更多规范请参考:https://www.python.org/dev/peps/pep-0249/。Python DB API下规范下cursor对象常用接口:
description:如果cursor执行了查询的sql代码。那么读取cursor.description属性的时候,将返回一个列表,这个列表中装的是元组,元组中装的分别是(name,type_code,display_size,internal_size,precision,scale,null_ok),其中name代表的是查找出来的数据的字段名称,其他参数暂时用处不大。rowcount:代表的是在执行了sql语句后受影响的行数。close:关闭游标。关闭游标以后就再也不能使用了,否则会抛出异常。execute(sql[,parameters]):执行某个sql语句。如果在执行sql语句的时候还需要传递参数,那么可以传给parameters参数。示例代码如下:cursor.execute("select * from article where id=%s",(1,))
fetchone:在执行了查询操作以后,获取第一条数据。fetchmany(size):在执行查询操作以后,获取多条数据。具体是多少条要看传的size参数。如果不传size参数,那么默认是获取第一条数据。fetchall:获取所有满足sql语句的数据。
模型常用属性
常用字段:
在Django中,定义了一些Field来与数据库表中的字段类型来进行映射。以下将介绍那些常用的字段类型。
AutoField:
映射到数据库中是int类型,可以有自动增长的特性。一般不需要使用这个类型,如果不指定主键,那么模型会自动的生成一个叫做id的自动增长的主键。如果你想指定一个其他名字的并且具有自动增长的主键,使用AutoField也是可以的。
BigAutoField:
64位的整形,类似于AutoField,只不过是产生的数据的范围是从1-9223372036854775807。
BooleanField:
在模型层面接收的是True/False。在数据库层面是tinyint类型。如果没有指定默认值,默认值是None。
CharField:
在数据库层面是varchar类型。在Python层面就是普通的字符串。这个类型在使用的时候必须要指定最大的长度,也即必须要传递max_length这个关键字参数进去。
DateField:
日期类型。在Python中是datetime.date类型,可以记录年月日。在映射到数据库中也是date类型。使用这个Field可以传递以下几个参数:
auto_now:在每次这个数据保存的时候,都使用当前的时间。比如作为一个记录修改日期的字段,可以将这个属性设置为True。auto_now_add:在每次数据第一次被添加进去的时候,都使用当前的时间。比如作为一个记录第一次入库的字段,可以将这个属性设置为True。DateTimeField:
日期时间类型,类似于DateField。不仅仅可以存储日期,还可以存储时间。映射到数据库中是datetime类型。这个Field也可以使用auto_now和auto_now_add两个属性。TimeField:
时间类型。在数据库中是time类型。在Python中是datetime.time类型。EmailField:
类似于CharField。在数据库底层也是一个varchar类型。最大长度是254个字符。FileField:
用来存储文件的。这个请参考后面的文件上传章节部分。ImageField:
用来存储图片文件的。这个请参考后面的图片上传章节部分。FloatField:
浮点类型。映射到数据库中是float类型。IntegerField:
整形。值的区间是-2147483648——2147483647。BigIntegerField:
大整形。值的区间是-9223372036854775808——9223372036854775807。PositiveIntegerField:
正整形。值的区间是0——2147483647。SmallIntegerField:
小整形。值的区间是-32768——32767。PositiveSmallIntegerField:
正小整形。值的区间是0——32767。TextField:
大量的文本类型。映射到数据库中是longtext类型。UUIDField:
只能存储uuid格式的字符串。uuid是一个32位的全球唯一的字符串,一般用来作为主键。URLField:
类似于CharField,只不过只能用来存储url格式的字符串。并且默认的max_length是200。
Field的常用参数:
null:
如果设置为True,Django将会在映射表的时候指定是否为空。默认是为False。在使用字符串相关的Field(CharField/TextField)的时候,官方推荐尽量不要使用这个参数,也就是保持默认值False。因为Django在处理字符串相关的Field的时候,即使这个Field的null=False,如果你没有给这个Field传递任何值,那么Django也会使用一个空的字符串""来作为默认值存储进去。因此如果再使用null=True,Django会产生两种空值的情形(NULL或者空字符串)。如果想要在表单验证的时候允许这个字符串为空,那么建议使用blank=True。如果你的Field是BooleanField,那么对应的可空的字段则为NullBooleanField。
blank:
标识这个字段在表单验证的时候是否可以为空。默认是False。
这个和null是有区别的,null是一个纯数据库级别的。而blank是表单验证级别的。
db_column:
这个字段在数据库中的名字。如果没有设置这个参数,那么将会使用模型中属性的名字。
default:
默认值。可以为一个值,或者是一个函数,但是不支持lambda表达式。并且不支持列表/字典/集合等可变的数据结构。
primary_key:
unique:
在表中这个字段的值是否唯一。一般是设置手机号码/邮箱等。
更多Field参数请参考官方文档:https://docs.djangoproject.com/zh-hans/2.0/ref/models/fields/
模型中Meta配置:
对于一些模型级别的配置。我们可以在模型中定义一个类,叫做Meta。然后在这个类中添加一些类属性来控制模型的作用。比如我们想要在数据库映射的时候使用自己指定的表名,而不是使用模型的名称。那么我们可以在Meta类中添加一个db_table的属性。示例代码如下:
class Book(models.Model):name = models.CharField(max_length=20,null=False)desc = models.CharField(max_length=100,name='description',db_column="description1")class Meta:db_table = 'book_model'
db_table:
这个模型映射到数据库中的表名。如果没有指定这个参数,那么在映射的时候将会使用模型名来作为默认的表名。
ordering:
设置在提取数据的排序方式。后面章节会讲到如何查找数据。比如我想在查找数据的时候根据添加的时间排序,那么示例代码如下:
class Book(models.Model):name = models.CharField(max_length=20,null=False)desc = models.CharField(max_length=100,name='description',db_column="description1")pub_date = models.DateTimeField(auto_now_add=True)class Meta:db_table = 'book_model'ordering = ['pub_date']
外键和表关系
外键:
在MySQL中,表有两种引擎,一种是InnoDB,另外一种是myisam。如果使用的是InnoDB引擎,是支持外键约束的。外键的存在使得ORM框架在处理表关系的时候异常的强大。因此这里我们首先来介绍下外键在Django中的使用。
类定义为class ForeignKey(to,on_delete,**options)。第一个参数是引用的是哪个模型,第二个参数是在使用外键引用的模型数据被删除了,这个字段该如何处理,比如有CASCADE、SET_NULL等。这里以一个实际案例来说明。比如有一个User和一个Article两个模型。一个User可以发表多篇文章,一个Article只能有一个Author,并且通过外键进行引用。那么相关的示例代码如下:
class User(models.Model):username = models.CharField(max_length=20)password = models.CharField(max_length=100)class Article(models.Model):title = models.CharField(max_length=100)content = models.TextField()author = models.ForeignKey("User",on_delete=models.CASCADE)
以上使用ForeignKey来定义模型之间的关系。即在article的实例中可以通过author属性来操作对应的User模型。这样使用起来非常的方便。示例代码如下:
article = Article(title='abc',content='123')author = User(username='张三',password='111111')article.author = authorarticle.save()# 修改article.author上的值article.author.username = '李四'article.save()
为什么使用了ForeignKey后,就能通过author访问到对应的user对象呢。因此在底层,Django为Article表添加了一个属性名_id的字段(比如author的字段名称是author_id),这个字段是一个外键,记录着对应的作者的主键。以后通过article.author访问的时候,实际上是先通过author_id找到对应的数据,然后再提取User表中的这条数据,形成一个模型。
如果想要引用另外一个app的模型,那么应该在传递to参数的时候,使用app.model_name进行指定。以上例为例,如果User和Article不是在同一个app中,那么在引用的时候的示例代码如下:
# User模型在user这个app中class User(models.Model):username = models.CharField(max_length=20)password = models.CharField(max_length=100)# Article模型在article这个app中class Article(models.Model):title = models.CharField(max_length=100)content = models.TextField()author = models.ForeignKey("user.User",on_delete=models.CASCADE)
如果模型的外键引用的是本身自己这个模型,那么to参数可以为'self',或者是这个模型的名字。在论坛开发中,一般评论都可以进行二级评论,即可以针对另外一个评论进行评论,那么在定义模型的时候就需要使用外键来引用自身。示例代码如下:
class Comment(models.Model):content = models.TextField()origin_comment = models.ForeignKey('self',on_delete=models.CASCADE,null=True)# 或者# origin_comment = models.ForeignKey('Comment',on_delete=models.CASCADE,null=True)
外键删除操作:
如果一个模型使用了外键。那么在对方那个模型被删掉后,该进行什么样的操作。可以通过on_delete来指定。可以指定的类型如下:
CASCADE:级联操作。如果外键对应的那条数据被删除了,那么这条数据也会被删除。PROTECT:受保护。即只要这条数据引用了外键的那条数据,那么就不能删除外键的那条数据。SET_NULL:设置为空。如果外键的那条数据被删除了,那么在本条数据上就将这个字段设置为空。如果设置这个选项,前提是要指定这个字段可以为空。SET_DEFAULT:设置默认值。如果外键的那条数据被删除了,那么本条数据上就将这个字段设置为默认值。如果设置这个选项,前提是要指定这个字段一个默认值。SET():如果外键的那条数据被删除了。那么将会获取SET函数中的值来作为这个外键的值。SET函数可以接收一个可以调用的对象(比如函数或者方法),如果是可以调用的对象,那么会将这个对象调用后的结果作为值返回回去。DO_NOTHING:不采取任何行为。一切全看数据库级别的约束。
以上这些选项只是Django级别的,数据级别依旧是RESTRICT!
表关系:
表之间的关系都是通过外键来进行关联的。而表之间的关系,无非就是三种关系:一对一、一对多(多对一)、多对多等。以下将讨论一下三种关系的应用场景及其实现方式。
一对多:
- 应用场景:比如文章和作者之间的关系。一个文章只能由一个作者编写,但是一个作者可以写多篇文章。文章和作者之间的关系就是典型的多对一的关系。
实现方式:一对多或者多对一,都是通过
ForeignKey来实现的。还是以文章和作者的案例进行讲解。class User(models.Model):username = models.CharField(max_length=20)password = models.CharField(max_length=100)class Article(models.Model):title = models.CharField(max_length=100)content = models.TextField()author = models.ForeignKey("User",on_delete=models.CASCADE)
那么以后在给
Article对象指定author,就可以使用以下代码来完成:article = Article(title='abc',content='123')author = User(username='zhiliao',password='111111')# 要先保存到数据库中author.save()article.author = authorarticle.save()
并且以后如果想要获取某个用户下所有的文章,可以通过
article_set来实现。示例代码如下:user = User.objects.first()# 获取第一个用户写的所有文章articles = user.article_set.all()for article in articles:print(article)
一对一:
应用场景:比如一个用户表和一个用户信息表。在实际网站中,可能需要保存用户的许多信息,但是有些信息是不经常用的。如果把所有信息都存放到一张表中可能会影响查询效率,因此可以把用户的一些不常用的信息存放到另外一张表中我们叫做
UserExtension。但是用户表User和用户信息表UserExtension就是典型的一对一了。实现方式:
Django为一对一提供了一个专门的Field叫做OneToOneField来实现一对一操作。示例代码如下:class User(models.Model):username = models.CharField(max_length=20)password = models.CharField(max_length=100)class UserExtension(models.Model):birthday = models.DateTimeField(null=True)school = models.CharField(blank=True,max_length=50)user = models.OneToOneField("User", on_delete=models.CASCADE)
在
UserExtension模型上增加了一个一对一的关系映射。其实底层是在UserExtension这个表上增加了一个user_id,来和user表进行关联,并且这个外键数据在表中必须是唯一的,来保证一对一。多对多:
应用场景:比如文章和标签的关系。一篇文章可以有多个标签,一个标签可以被多个文章所引用。因此标签和文章的关系是典型的多对多的关系。
实现方式:
Django为这种多对多的实现提供了专门的Field。叫做ManyToManyField。还是拿文章和标签为例进行讲解。示例代码如下:class Article(models.Model):title = models.CharField(max_length=100)content = models.TextField()tags = models.ManyToManyField("Tag",related_name="articles")class Tag(models.Model):name = models.CharField(max_length=50)
在数据库层面,实际上
Django是为这种多对多的关系建立了一个中间表。这个中间表分别定义了两个外键,引用到article和tag两张表的主键。
related_name和related_query_name:
related_name:
还是以User和Article为例来进行说明。如果一个article想要访问对应的作者,那么可以通过author来进行访问。但是如果有一个user对象,想要通过这个user对象获取所有的文章,该如何做呢?这时候可以通过user.article_set来访问,这个名字的规律是模型名字小写_set。示例代码如下:
user = User.objects.get(name='张三')user.article_set.all()
如果不想使用模型名字小写_set的方式,想要使用其他的名字,那么可以在定义模型的时候指定related_name。示例代码如下:
class Article(models.Model):title = models.CharField(max_length=100)content = models.TextField()# 传递related_name参数,以后在方向引用的时候使用articles进行访问author = models.ForeignKey("User",on_delete=models.SET_NULL,null=True,related_name='articles')
以后在方向引用的时候。使用articles可以访问到这个作者的文章模型。示例代码如下:
user = User.objects.get(name='张三')user.articles.all()
如果不想使用反向引用,那么可以指定related_name='+'。示例代码如下:
class Article(models.Model):title = models.CharField(max_length=100)content = models.TextField()# 传递related_name参数,以后在方向引用的时候使用articles进行访问author = models.ForeignKey("User",on_delete=models.SET_NULL,null=True,related_name='+')
以后将不能通过user.article_set来访问文章模型了。
related_query_name:
在查找数据的时候,可以使用filter进行过滤。使用filter过滤的时候,不仅仅可以指定本模型上的某个属性要满足什么条件,还可以指定相关联的模型满足什么属性。比如现在想要获取写过标题为abc的所有用户,那么可以这样写:
users = User.objects.filter(article__title='abc')
如果你设置了related_name为articles,因为反转的过滤器的名字将使用related_name的名字,那么上例代码将改成如下:
users = User.objects.filter(articles__title='abc')
可以通过related_query_name将查询的反转名字修改成其他的名字。比如article。示例代码如下:
class Article(models.Model):title = models.CharField(max_length=100)content = models.TextField()# 传递related_name参数,以后在方向引用的时候使用articles进行访问author = models.ForeignKey("User",on_delete=models.SET_NULL,null=True,related_name='articles',related_query_name='article')
那么在做反向过滤查找的时候就可以使用以下代码:
users = User.objects.filter(article__title='abc')
模型的操作:
在ORM框架中,所有模型相关的操作,比如添加/删除等。其实都是映射到数据库中一条数据的操作。因此模型操作也就是数据库表中数据的操作。
添加一个模型到数据库中:
添加模型到数据库中。首先需要创建一个模型。创建模型的方式很简单,就跟创建普通的Python对象是一摸一样的。在创建完模型之后,需要调用模型的save方法,这样Django会自动的将这个模型转换成sql语句,然后存储到数据库中。示例代码如下:
class Book(models.Model):name = models.CharField(max_length=20,null=False)desc = models.CharField(max_length=100,name='description',db_column="description1")pub_date = models.DateTimeField(auto_now_add=True)book = Book(name='三国演义',desc='三国英雄!')book.save()
查找数据:
查找所有数据:
要查找Book这个模型对应的表下的所有数据。那么示例代码如下:
books = Book.objects.all()
数据过滤:
在查找数据的时候,有时候需要对一些数据进行过滤。那么这时候需要调用objects的filter方法。实例代码如下:
books = Book.objects.filter(name='三国演义')> [<Book:三国演义>]# 多个条件books = Book.objects.filter(name='三国演义',desc='test')
获取单个对象:
使用filter返回的是所有满足条件的结果集。有时候如果只需要返回第一个满足条件的对象。那么可以使用get方法。示例代码如下:
book = Book.objects.get(name='三国演义')> <Book:三国演义>
当然,如果没有找到满足条件的对象,那么就会抛出一个异常。而filter在没有找到满足条件的数据的时候,是返回一个空的列表。
数据排序:
在之前的例子中,数据都是无序的。如果你想在查找数据的时候使用某个字段来进行排序,那么可以使用order_by方法来实现。示例代码如下:
books = Book.objects.order_by("pub_date")
以上代码在提取所有书籍的数据的时候,将会使用pub_date从小到大进行排序。如果想要进行倒序排序,那么可以在pub_date前面加一个负号。实例代码如下:
books = Book.objects.order_by("-pub_date")
修改数据:
在查找到数据后,便可以进行修改了。修改的方式非常简单,只需要将查找出来的对象的某个属性进行修改,然后再调用这个对象的save方法便可以进行修改。示例代码如下:
from datetime import datetimebook = Book.objects.get(name='三国演义')book.pub_date = datetime.now()book.save()
删除数据:
在查找到数据后,便可以进行删除了。删除数据非常简单,只需要调用这个对象的delete方法即可。实例代码如下:
book = Book.objects.get(name='三国演义')book.delete()
查询操作
查找是数据库操作中一个非常重要的技术。查询一般就是使用filter、exclude以及get三个方法来实现。我们可以在调用这些方法的时候传递不同的参数来实现查询需求。在ORM层面,这些查询条件都是使用field+__+condition的方式来使用的。以下将那些常用的查询条件来一一解释。
查询条件
exact:
使用精确的=进行查找。如果提供的是一个None,那么在SQL层面就是被解释为NULL。示例代码如下:
article = Article.objects.get(id__exact=14)article = Article.objects.get(id__exact=None)
以上的两个查找在翻译为SQL语句为如下:
select ... from article where id=14;select ... from article where id IS NULL;
iexact:
使用like进行查找。示例代码如下:
article = Article.objects.filter(title__iexact='hello world')
那么以上的查询就等价于以下的SQL语句:
select ... from article where title like 'hello world';
注意上面这个sql语句,因为在MySQL中,没有一个叫做ilike的。所以exact和iexact的区别实际上就是LIKE和=的区别,在大部分collation=utf8_general_ci情况下都是一样的(collation是用来对字符串比较的)。
contains:
大小写敏感,判断某个字段是否包含了某个数据。示例代码如下:
articles = Article.objects.filter(title__contains='hello')
在翻译成SQL语句为如下:
select ... where title like binary '%hello%';
要注意的是,在使用contains的时候,翻译成的sql语句左右两边是有百分号的,意味着使用的是模糊查询。而exact翻译成sql语句左右两边是没有百分号的,意味着使用的是精确的查询。
icontains:
大小写不敏感的匹配查询。示例代码如下:
articles = Article.objects.filter(title__icontains='hello')
在翻译成SQL语句为如下:
select ... where title like '%hello%';
in:
提取那些给定的field的值是否在给定的容器中。容器可以为list、tuple或者任何一个可以迭代的对象,包括QuerySet对象。示例代码如下:
articles = Article.objects.filter(id__in=[1,2,3])
以上代码在翻译成SQL语句为如下:
select ... where id in (1,3,4)
当然也可以传递一个QuerySet对象进去。示例代码如下:
inner_qs = Article.objects.filter(title__contains='hello')categories = Category.objects.filter(article__in=inner_qs)
以上代码的意思是获取那些文章标题包含hello的所有分类。
将翻译成以下SQL语句,示例代码如下:
select ...from category where article.id in (select id from article where title like '%hello%');
gt:
某个field的值要大于给定的值。示例代码如下:
articles = Article.objects.filter(id__gt=4)
以上代码的意思是将所有id大于4的文章全部都找出来。
将翻译成以下SQL语句:
select ... where id > 4;
gte:
lt:
lte:
startswith:
判断某个字段的值是否是以某个值开始的。大小写敏感。示例代码如下:
articles = Article.objects.filter(title__startswith='hello')
以上代码的意思是提取所有标题以hello字符串开头的文章。
将翻译成以下SQL语句:
select ... where title like 'hello%'
istartswith:
endswith:
判断某个字段的值是否以某个值结束。大小写敏感。示例代码如下:
articles = Article.objects.filter(title__endswith='world')
以上代码的意思是提取所有标题以world结尾的文章。
将翻译成以下SQL语句:
select ... where title like '%world';
iendswith:
range:
判断某个field的值是否在给定的区间中。示例代码如下:
from django.utils.timezone import make_awarefrom datetime import datetimestart_date = make_aware(datetime(year=2018,month=1,day=1))end_date = make_aware(datetime(year=2018,month=3,day=29,hour=16))articles = Article.objects.filter(pub_date__range=(start_date,end_date))
以上代码的意思是提取所有发布时间在2018/1/1到2018/12/12之间的文章。
将翻译成以下的SQL语句:
select ... from article where pub_time between '2018-01-01' and '2018-12-12'。
需要注意的是,以上提取数据,不会包含最后一个值。也就是不会包含2018/12/12的文章。
而且另外一个重点,因为我们在settings.py中指定了USE_TZ=True,并且设置了TIME_ZONE='Asia/Shanghai',因此我们在提取数据的时候要使用django.utils.timezone.make_aware先将datetime.datetime从navie时间转换为aware时间。make_aware会将指定的时间转换为TIME_ZONE中指定的时区的时间。
date:
针对某些date或者datetime类型的字段。可以指定date的范围。并且这个时间过滤,还可以使用链式调用。示例代码如下:
articles = Article.objects.filter(pub_date__date=date(2018,3,29))
以上代码的意思是查找时间为2018/3/29这一天发表的所有文章。
将翻译成以下的sql语句:
select ... WHERE DATE(CONVERT_TZ(`front_article`.`pub_date`, 'UTC', 'Asia/Shanghai')) = 2018-03-29
注意,因为默认情况下MySQL的表中是没有存储时区相关的信息的。因此我们需要下载一些时区表的文件,然后添加到Mysql的配置路径中。如果你用的是windows操作系统。那么在[http://dev.mysql.com/downloads/timezones.html](http://dev.mysql.com/downloads/timezones.html)下载timezone_2018d_posix.zip - POSIX standard。然后将下载下来的所有文件拷贝到C:\ProgramData\MySQL\MySQL Server 5.7\Data\mysql中,如果提示文件名重复,那么选择覆盖即可。
如果用的是linux或者mac系统,那么在命令行中执行以下命令:mysql_tzinfo_to_sql /usr/share/zoneinfo | mysql -D mysql -u root -p,然后输入密码,从系统中加载时区文件更新到mysql中。
year:
根据年份进行查找。示例代码如下:
articles = Article.objects.filter(pub_date__year=2018)articles = Article.objects.filter(pub_date__year__gte=2017)
以上的代码在翻译成SQL语句为如下:
select ... where pub_date between '2018-01-01' and '2018-12-31';select ... where pub_date >= '2017-01-01';
month:
day:
week_day:
Django 1.11新增的查找方式。同year,根据星期几进行查找。1表示星期天,7表示星期六,2-6代表的是星期一到星期五。
time:
根据时间进行查找。示例代码如下:
articles = Article.objects.filter(pub_date__time=datetime.time(12,12,12));
以上的代码是获取每一天中12点12分12秒发表的所有文章。
更多的关于时间的过滤,请参考Django官方文档:[https://docs.djangoproject.com/en/2.0/ref/models/querysets/#range](https://docs.djangoproject.com/en/2.0/ref/models/querysets/#range)。
isnull:
根据值是否为空进行查找。示例代码如下:
articles = Article.objects.filter(pub_date__isnull=False)
以上的代码的意思是获取所有发布日期不为空的文章。
将来翻译成SQL语句如下:
select ... where pub_date is not null;
regex和iregex:
大小写敏感和大小写不敏感的正则表达式。示例代码如下:
articles = Article.objects.filter(title__regex=r'^hello')
以上代码的意思是提取所有标题以hello字符串开头的文章。
将翻译成以下的SQL语句:
select ... where title regexp binary '^hello';
根据关联的表进行查询:
假如现在有两个ORM模型,一个是Article,一个是Category。代码如下:
class Category(models.Model):"""文章分类表"""name = models.CharField(max_length=100)class Article(models.Model):"""文章表"""title = models.CharField(max_length=100,null=True)category = models.ForeignKey("Category",on_delete=models.CASCADE)
比如想要获取文章标题中包含”hello”的所有的分类。那么可以通过以下代码来实现:
categories = Category.object.filter(article__title__contains("hello"))
聚合函数:
如果你用原生SQL,则可以使用聚合函数来提取数据。比如提取某个商品销售的数量,那么可以使用Count,如果想要知道商品销售的平均价格,那么可以使用Avg。
聚合函数是通过aggregate方法来实现的。在讲解这些聚合函数的用法的时候,都是基于以下的模型对象来实现的。
from django.db import modelsclass Author(models.Model):"""作者模型"""name = models.CharField(max_length=100)age = models.IntegerField()email = models.EmailField()class Meta:db_table = 'author'class Publisher(models.Model):"""出版社模型"""name = models.CharField(max_length=300)class Meta:db_table = 'publisher'class Book(models.Model):"""图书模型"""name = models.CharField(max_length=300)pages = models.IntegerField()price = models.FloatField()rating = models.FloatField()author = models.ForeignKey(Author,on_delete=models.CASCADE)publisher = models.ForeignKey(Publisher, on_delete=models.CASCADE)class Meta:db_table = 'book'class BookOrder(models.Model):"""图书订单模型"""book = models.ForeignKey("Book",on_delete=models.CASCADE)price = models.FloatField()class Meta:db_table = 'book_order'
Avg:求平均值。比如想要获取所有图书的价格平均值。那么可以使用以下代码实现。from django.db.models import Avgresult = Book.objects.aggregate(Avg('price'))print(result)
以上的打印结果是:
{"price__avg":23.0}
其中
price__avg的结构是根据field__avg规则构成的。如果想要修改默认的名字,那么可以将Avg赋值给一个关键字参数。示例代码如下:from django.db.models import Avgresult = Book.objects.aggregate(my_avg=Avg('price'))print(result)
那么以上的结果打印为:
{"my_avg":23}
Count:获取指定的对象的个数。示例代码如下:from django.db.models import Countresult = Book.objects.aggregate(book_num=Count('id'))
以上的
result将返回Book表中总共有多少本图书。Count类中,还有另外一个参数叫做distinct,默认是等于False,如果是等于True,那么将去掉那些重复的值。比如要获取作者表中所有的不重复的邮箱总共有多少个,那么可以通过以下代码来实现:from djang.db.models import Countresult = Author.objects.aggregate(count=Count('email',distinct=True))
Max和Min:获取指定对象的最大值和最小值。比如想要获取Author表中,最大的年龄和最小的年龄分别是多少。那么可以通过以下代码来实现:from django.db.models import Max,Minresult = Author.objects.aggregate(Max('age'),Min('age'))
如果最大的年龄是88,最小的年龄是18。那么以上的result将为:
{"age__max":88,"age__min":18}
Sum:求指定对象的总和。比如要求图书的销售总额。那么可以使用以下代码实现:from djang.db.models import Sumresult = Book.objects.annotate(total=Sum("bookstore__price")).values("name","total")
以上的代码
annotate的意思是给Book表在查询的时候添加一个字段叫做total,这个字段的数据来源是从BookStore模型的price的总和而来。values方法是只提取name和total两个字段的值。
更多的聚合函数请参考官方文档:https://docs.djangoproject.com/en/2.0/ref/models/querysets/#aggregation-functions
aggregate和annotate的区别:
aggregate:返回使用聚合函数后的字段和值。annotate:在原来模型字段的基础之上添加一个使用了聚合函数的字段,并且在使用聚合函数的时候,会使用当前这个模型的主键进行分组(group by)。
比如以上Sum的例子,如果使用的是annotate,那么将在每条图书的数据上都添加一个字段叫做total,计算这本书的销售总额。
而如果使用的是aggregate,那么将求所有图书的销售总额。
F表达式和Q表达式:
F表达式:
F表达式是用来优化ORM操作数据库的。比如我们要将公司所有员工的薪水都增加1000元,如果按照正常的流程,应该是先从数据库中提取所有的员工工资到Python内存中,然后使用Python代码在员工工资的基础之上增加1000元,最后再保存到数据库中。这里面涉及的流程就是,首先从数据库中提取数据到Python内存中,然后在Python内存中做完运算,之后再保存到数据库中。示例代码如下:employees = Employee.objects.all()for employee in employees:employee.salary += 1000employee.save()
而我们的
F表达式就可以优化这个流程,他可以不需要先把数据从数据库中提取出来,计算完成后再保存回去,他可以直接执行SQL语句,就将员工的工资增加1000元。示例代码如下:from djang.db.models import FEmployee.object.update(salary=F("salary")+1000)
F表达式并不会马上从数据库中获取数据,而是在生成SQL语句的时候,动态的获取传给F表达式的值。
比如如果想要获取作者中,name和email相同的作者数据。如果不使用F表达式,那么需要使用以下代码来完成:authors = Author.objects.all()for author in authors:if author.name == author.email:print(author)
如果使用
F表达式,那么一行代码就可以搞定。示例代码如下:from django.db.models import Fauthors = Author.objects.filter(name=F("email"))
Q表达式:
如果想要实现所有价格高于100元,并且评分达到9.0以上评分的图书。那么可以通过以下代码来实现:
books = Book.objects.filter(price__gte=100,rating__gte=9)
以上这个案例是一个并集查询,可以简单的通过传递多个条件进去来实现。
但是如果想要实现一些复杂的查询语句,比如要查询所有价格低于10元,或者是评分低于9分的图书。那就没有办法通过传递多个条件进去实现了。这时候就需要使用Q表达式来实现了。示例代码如下:from django.db.models import Qbooks = Book.objects.filter(Q(price__lte=10) | Q(rating__lte=9))
以上是进行或运算,当然还可以进行其他的运算,比如有
&和~(非)等。一些用Q表达式的例子如下:from django.db.models import Q# 获取id等于3的图书books = Book.objects.filter(Q(id=3))# 获取id等于3,或者名字中包含文字"记"的图书books = Book.objects.filter(Q(id=3)|Q(name__contains("记")))# 获取价格大于100,并且书名中包含"记"的图书books = Book.objects.filter(Q(price__gte=100)&Q(name__contains("记")))# 获取书名包含“记”,但是id不等于3的图书books = Book.objects.filter(Q(name__contains='记') & ~Q(id=3))
QuerySet API:
我们通常做查询操作的时候,都是通过
模型名字.objects的方式进行操作。其实模型名字.objects是一个django.db.models.manager.Manager对象,而Manager这个类是一个“空壳”的类,他本身是没有任何的属性和方法的。他的方法全部都是通过Python动态添加的方式,从QuerySet类中拷贝过来的。示例图如下: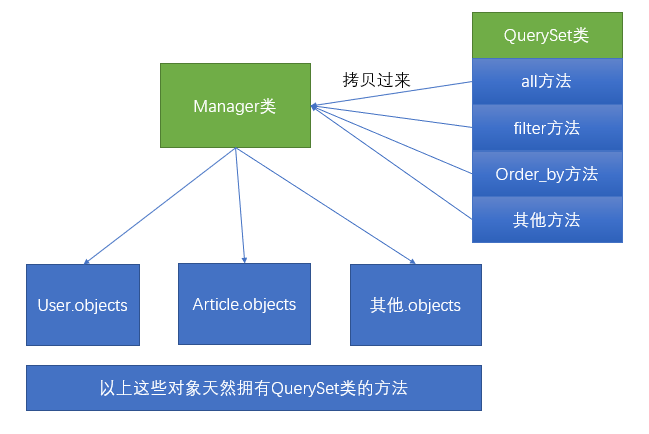
所以我们如果想要学习ORM模型的查找操作,必须首先要学会QuerySet上的一些API的使用。返回新的QuerySet的方法:
在使用
QuerySet进行查找操作的时候,可以提供多种操作。比如过滤完后还要根据某个字段进行排序,那么这一系列的操作我们可以通过一个非常流畅的链式调用的方式进行。比如要从文章表中获取标题为123,并且提取后要将结果根据发布的时间进行排序,那么可以使用以下方式来完成:articles = Article.objects.filter(title='123').order_by('create_time')
可以看到
order_by方法是直接在filter执行后调用的。这说明filter返回的对象是一个拥有order_by方法的对象。而这个对象正是一个新的QuerySet对象。因此可以使用order_by方法。
那么以下将介绍在那些会返回新的QuerySet对象的方法。filter:将满足条件的数据提取出来,返回一个新的QuerySet。具体的filter可以提供什么条件查询。请见查询操作章节。exclude:排除满足条件的数据,返回一个新的QuerySet。示例代码如下:Article.objects.exclude(title__contains='hello')
以上代码的意思是提取那些标题不包含
hello的图书。annotate:给QuerySet中的每个对象都添加一个使用查询表达式(聚合函数、F表达式、Q表达式、Func表达式等)的新字段。示例代码如下:articles = Article.objects.annotate(author_name=F("author__name"))
以上代码将在每个对象中都添加一个
author__name的字段,用来显示这个文章的作者的年龄。order_by:指定将查询的结果根据某个字段进行排序。如果要倒叙排序,那么可以在这个字段的前面加一个负号。示例代码如下:# 根据创建的时间正序排序articles = Article.objects.order_by("create_time")# 根据创建的时间倒序排序articles = Article.objects.order_by("-create_time")# 根据作者的名字进行排序articles = Article.objects.order_by("author__name")# 首先根据创建的时间进行排序,如果时间相同,则根据作者的名字进行排序articles = Article.objects.order_by("create_time",'author__name')
一定要注意的一点是,多个
order_by,会把前面排序的规则给打乱,而使用后面的排序方式。比如以下代码:articles = Article.objects.order_by("create_time").order_by("author__name")
他会根据作者的名字进行排序,而不是使用文章的创建时间。
values:用来指定在提取数据出来,需要提取哪些字段。默认情况下会把表中所有的字段全部都提取出来,可以使用values来进行指定,并且使用了values方法后,提取出的QuerySet中的数据类型不是模型,而是在values方法中指定的字段和值形成的字典:articles = Article.objects.values("title",'content')for article in articles:print(article)
以上打印出来的
article是类似于{"title":"abc","content":"xxx"}的形式。
如果在values中没有传递任何参数,那么将会返回这个恶模型中所有的属性。values_list:类似于values。只不过返回的QuerySet中,存储的不是字典,而是元组。示例代码如下:articles = Article.objects.values_list("id","title")print(articles)
那么在打印
articles后,结果为<QuerySet [(1,'abc'),(2,'xxx'),...]>等。
如果在values_list中只有一个字段。那么你可以传递flat=True来将结果扁平化。示例代码如下:articles1 = Article.objects.values_list("title")>> <QuerySet [("abc",),("xxx",),...]>articles2 = Article.objects.values_list("title",flat=True)>> <QuerySet ["abc",'xxx',...]>
all:获取这个ORM模型的QuerySet对象。select_related:在提取某个模型的数据的同时,也提前将相关联的数据提取出来。比如提取文章数据,可以使用select_related将author信息提取出来,以后再次使用article.author的时候就不需要再次去访问数据库了。可以减少数据库查询的次数。示例代码如下:article = Article.objects.get(pk=1)>> article.author # 重新执行一次查询语句article = Article.objects.select_related("author").get(pk=2)>> article.author # 不需要重新执行查询语句了
selected_related只能用在一对多或者一对一中,不能用在多对多或者多对一中。比如可以提前获取文章的作者,但是不能通过作者获取这个作者的文章,或者是通过某篇文章获取这个文章所有的标签。prefetch_related:这个方法和select_related非常的类似,就是在访问多个表中的数据的时候,减少查询的次数。这个方法是为了解决多对一和多对多的关系的查询问题。比如要获取标题中带有hello字符串的文章以及他的所有标签,示例代码如下:from django.db import connectionarticles = Article.objects.prefetch_related("tag_set").filter(title__contains='hello')print(articles.query) # 通过这条命令查看在底层的SQL语句for article in articles:print("title:",article.title)print(article.tag_set.all())# 通过以下代码可以看出以上代码执行的sql语句for sql in connection.queries:print(sql)
但是如果在使用
article.tag_set的时候,如果又创建了一个新的QuerySet那么会把之前的SQL优化给破坏掉。比如以下代码:tags = Tag.obejcts.prefetch_related("articles")for tag in tags:articles = tag.articles.filter(title__contains='hello') #因为filter方法会重新生成一个QuerySet,因此会破坏掉之前的sql优化# 通过以下代码,我们可以看到在使用了filter的,他的sql查询会更多,而没有使用filter的,只有两次sql查询for sql in connection.queries:print(sql)
那如果确实是想要在查询的时候指定过滤条件该如何做呢,这时候我们可以使用
django.db.models.Prefetch来实现,Prefetch这个可以提前定义好queryset。示例代码如下:tags = Tag.objects.prefetch_related(Prefetch("articles",queryset=Article.objects.filter(title__contains='hello'))).all()for tag in tags:articles = tag.articles.all()for article in articles:print(article)for sql in connection.queries:print('='*30)print(sql)
因为使用了
Prefetch,即使在查询文章的时候使用了filter,也只会发生两次查询操作。defer:在一些表中,可能存在很多的字段,但是一些字段的数据量可能是比较庞大的,而此时你又不需要,比如我们在获取文章列表的时候,文章的内容我们是不需要的,因此这时候我们就可以使用defer来过滤掉一些字段。这个字段跟values有点类似,只不过defer返回的不是字典,而是模型。示例代码如下:articles = list(Article.objects.defer("title"))for sql in connection.queries:print('='*30)print(sql)
在看以上代码的
sql语句,你就可以看到,查找文章的字段,除了title,其他字段都查找出来了。当然,你也可以使用article.title来获取这个文章的标题,但是会重新执行一个查询的语句。示例代码如下:articles = list(Article.objects.defer("title"))for article in articles:# 因为在上面提取的时候过滤了title# 这个地方重新获取title,将重新向数据库中进行一次查找操作print(article.title)for sql in connection.queries:print('='*30)print(sql)
defer虽然能过滤字段,但是有些字段是不能过滤的,比如id,即使你过滤了,也会提取出来。only:跟defer类似,只不过defer是过滤掉指定的字段,而only是只提取指定的字段。get:获取满足条件的数据。这个函数只能返回一条数据,并且如果给的条件有多条数据,那么这个方法会抛出MultipleObjectsReturned错误,如果给的条件没有任何数据,那么就会抛出DoesNotExit错误。所以这个方法在获取数据的只能,只能有且只有一条。create:创建一条数据,并且保存到数据库中。这个方法相当于先用指定的模型创建一个对象,然后再调用这个对象的save方法。示例代码如下:article = Article(title='abc')article.save()# 下面这行代码相当于以上两行代码article = Article.objects.create(title='abc')
get_or_create:根据某个条件进行查找,如果找到了那么就返回这条数据,如果没有查找到,那么就创建一个。示例代码如下:obj,created= Category.objects.get_or_create(title='默认分类')
如果有标题等于
默认分类的分类,那么就会查找出来,如果没有,则会创建并且存储到数据库中。
这个方法的返回值是一个元组,元组的第一个参数obj是这个对象,第二个参数created代表是否创建的。bulk_create:一次性创建多个数据。示例代码如下:Tag.objects.bulk_create([Tag(name='111'),Tag(name='222'),])
count:获取提取的数据的个数。如果想要知道总共有多少条数据,那么建议使用count,而不是使用len(articles)这种。因为count在底层是使用select count(*)来实现的,这种方式比使用len函数更加的高效。first和last:返回QuerySet中的第一条和最后一条数据。aggregate:使用聚合函数。exists:判断某个条件的数据是否存在。如果要判断某个条件的元素是否存在,那么建议使用exists,这比使用count或者直接判断QuerySet更有效得多。示例代码如下:if Article.objects.filter(title__contains='hello').exists():print(True)比使用count更高效:if Article.objects.filter(title__contains='hello').count() > 0:print(True)也比直接判断QuerySet更高效:if Article.objects.filter(title__contains='hello'):print(True)
distinct:去除掉那些重复的数据。这个方法如果底层数据库用的是MySQL,那么不能传递任何的参数。比如想要提取所有销售的价格超过80元的图书,并且删掉那些重复的,那么可以使用distinct来帮我们实现,示例代码如下:books = Book.objects.filter(bookorder__price__gte=80).distinct()
需要注意的是,如果在
distinct之前使用了order_by,那么因为order_by会提取order_by中指定的字段,因此再使用distinct就会根据多个字段来进行唯一化,所以就不会把那些重复的数据删掉。示例代码如下:orders = BookOrder.objects.order_by("create_time").values("book_id").distinct()
那么以上代码因为使用了
order_by,即使使用了distinct,也会把重复的book_id提取出来。update:执行更新操作,在SQL底层走的也是update命令。比如要将所有category为空的article的article字段都更新为默认的分类。示例代码如下:Article.objects.filter(category__isnull=True).update(category_id=3)
注意这个方法走的是更新的逻辑。所以更新完成后保存到数据库中不会执行
save方法,因此不会更新auto_now设置的字段。delete:删除所有满足条件的数据。删除数据的时候,要注意on_delete指定的处理方式。切片操作:有时候我们查找数据,有可能只需要其中的一部分。那么这时候可以使用切片操作来帮我们完成。
QuerySet使用切片操作就跟列表使用切片操作是一样的。示例代码如下:books = Book.objects.all()[1:3]for book in books:print(book)
切片操作并不是把所有数据从数据库中提取出来再做切片操作。而是在数据库层面使用
LIMIE和OFFSET来帮我们完成。所以如果只需要取其中一部分的数据的时候,建议大家使用切片操作。什么时候
Django会将QuerySet转换为SQL去执行:生成一个
QuerySet对象并不会马上转换为SQL语句去执行。
比如我们获取Book表下所有的图书:books = Book.objects.all()print(connection.queries)
我们可以看到在打印
connection.quries的时候打印的是一个空的列表。说明上面的QuerySet并没有真正的执行。
在以下情况下QuerySet会被转换为SQL语句执行:迭代:在遍历
QuerySet对象的时候,会首先先执行这个SQL语句,然后再把这个结果返回进行迭代。比如以下代码就会转换为SQL语句:for book in Book.objects.all():print(book)
使用步长做切片操作:
QuerySet可以类似于列表一样做切片操作。做切片操作本身不会执行SQL语句,但是如果如果在做切片操作的时候提供了步长,那么就会立马执行SQL语句。需要注意的是,做切片后不能再执行filter方法,否则会报错。- 调用
len函数:调用len函数用来获取QuerySet中总共有多少条数据也会执行SQL语句。 - 调用
list函数:调用list函数用来将一个QuerySet对象转换为list对象也会立马执行SQL语句。 判断:如果对某个
QuerySet进行判断,也会立马执行SQL语句。
ORM模型迁移
迁移命令:
makemigrations:将模型生成迁移脚本。模型所在的
app,必须放在settings.py中的INSTALLED_APPS中。这个命令有以下几个常用选项:- app_label:后面可以跟一个或者多个
app,那么就只会针对这几个app生成迁移脚本。如果没有任何的app_label,那么会检查INSTALLED_APPS中所有的app下的模型,针对每一个app都生成响应的迁移脚本。 - —name:给这个迁移脚本指定一个名字。
- —empty:生成一个空的迁移脚本。如果你想写自己的迁移脚本,可以使用这个命令来实现一个空的文件,然后自己再在文件中写迁移脚本。
- app_label:后面可以跟一个或者多个
- migrate:将新生成的迁移脚本。映射到数据库中。创建新的表或者修改表的结构。以下一些常用的选项:
- app_label:将某个
app下的迁移脚本映射到数据库中。如果没有指定,那么会将所有在INSTALLED_APPS中的app下的模型都映射到数据库中。 - app_label migrationname:将某个
app下指定名字的migration文件映射到数据库中。 - —fake:可以将指定的迁移脚本名字添加到数据库中。但是并不会把迁移脚本转换为SQL语句,修改数据库中的表。
- —fake-initial:将第一次生成的迁移文件版本号记录在数据库中。但并不会真正的执行迁移脚本。
- app_label:将某个
- showmigrations:查看某个app下的迁移文件。如果后面没有app,那么将查看
INSTALLED_APPS中所有的迁移文件。 sqlmigrate:查看某个迁移文件在映射到数据库中的时候,转换的
SQL语句。
migrations中的迁移版本和数据库中的迁移版本对不上怎么办?
找到哪里不一致,然后使用
python manage.py --fake [版本名字],将这个版本标记为已经映射。- 删除指定
app下migrations和数据库表django_migrations中和这个app相关的版本号,然后将模型中的字段和数据库中的字段保持一致,再使用命令python manage.py makemigrations重新生成一个初始化的迁移脚本,之后再使用命令python manage.py makemigrations --fake-initial来将这个初始化的迁移脚本标记为已经映射。以后再修改就没有问题了。
更多关于迁移脚本的。请查看官方文档:https://docs.djangoproject.com/en/2.0/topics/migrations/
根据已有的表自动生成模型:
在实际开发中,有些时候可能数据库已经存在了。如果我们用Django来开发一个网站,读取的是之前已经存在的数据库中的数据。那么该如何将模型与数据库中的表映射呢?根据旧的数据库生成对应的ORM模型,需要以下几个步骤:
Django给我们提供了一个inspectdb的命令,可以非常方便的将已经存在的表,自动的生成模型。想要使用inspectdb自动将表生成模型。首先需要在settings.py中配置好数据库相关信息。不然就找不到数据库。示例代码如下:DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql','NAME': "migrations_demo",'HOST': '127.0.0.1','PORT': '3306','USER': 'root','PASSWORD': 'root'}}
比如有以下表:
- article表:
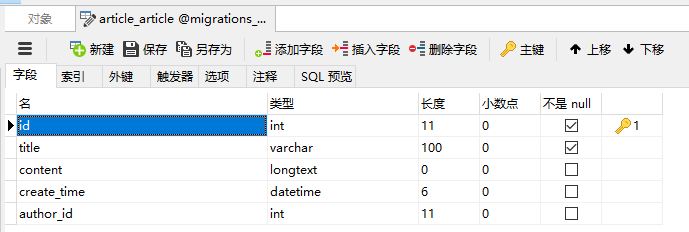
- tag表:
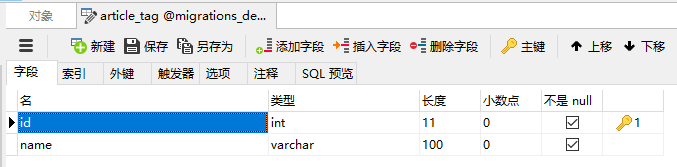
- article_tag表:
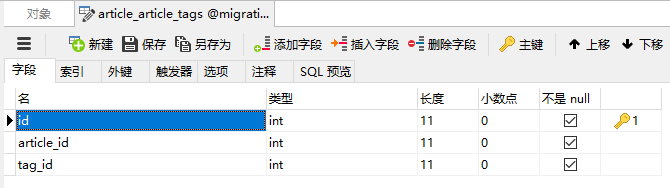
- front_user表:

那么通过python manage.py inspectdb,就会将表转换为模型后的代码,显示在终端:
from django.db import modelsclass ArticleArticle(models.Model):title = models.CharField(max_length=100)content = models.TextField(blank=True, null=True)create_time = models.DateTimeField(blank=True, null=True)author = models.ForeignKey('FrontUserFrontuser', models.DO_NOTHING, blank=True, null=True)class Meta:managed = Falsedb_table = 'article_article'class ArticleArticleTags(models.Model):article = models.ForeignKey(ArticleArticle, models.DO_NOTHING)tag = models.ForeignKey('ArticleTag', models.DO_NOTHING)class Meta:managed = Falsedb_table = 'article_article_tags'unique_together = (('article', 'tag'),)class ArticleTag(models.Model):name = models.CharField(max_length=100)class Meta:managed = Falsedb_table = 'article_tag'class FrontUserFrontuser(models.Model):username = models.CharField(max_length=100)telephone = models.CharField(max_length=11)class Meta:managed = Falsedb_table = 'front_user_frontuser'
以上代码只是显示在终端。如果想要保存到文件中。那么可以使用
>重定向输出到指定的文件。比如让他输出到models.py文件中。示例命令如下:python manage.py inspectdb > models.py
以上的命令,只能在终端执行,不能在
pycharm->Tools->Run manage.py Task...中使用。
如果只是想要转换一个表为模型。那么可以指定表的名字。示例命令如下:python manage.py inspectdb article_article > models.py
修正模型:新生成的
ORM模型有些地方可能不太适合使用。比如模型的名字,表之间的关系等等。那么以下选项还需要重新配置一下:- 模型名:自动生成的模型,是根据表的名字生成的,可能不是你想要的。这时候模型的名字你可以改成任何你想要的。
- 模型所属app:根据自己的需要,将相应的模型放在对应的app中。放在同一个app中也是没有任何问题的。只是不方便管理。
- 模型外键引用:将所有使用
ForeignKey的地方,模型引用都改成字符串。这样不会产生模型顺序的问题。另外,如果引用的模型已经移动到其他的app中了,那么还要加上这个app的前缀。 - 让Django管理模型:将
Meta下的managed=False删掉,如果保留这个,那么以后这个模型有任何的修改,使用migrate都不会映射到数据库中。 当有多对多的时候,应该也要修正模型。将中间表注视了,然后使用
ManyToManyField来实现多对多。并且,使用ManyToManyField生成的中间表的名字可能和数据库中那个中间表的名字不一致,这时候肯定就不能正常连接了。那么可以通过db_table来指定中间表的名字。示例代码如下:class Article(models.Model):title = models.CharField(max_length=100, blank=True, null=True)content = models.TextField(blank=True, null=True)author = models.ForeignKey('front.User', models.SET_NULL, blank=True, null=True)# 使用ManyToManyField模型到表,生成的中间表的规则是:article_tags# 但现在已经存在的表的名字叫做:article_tag# 可以使用db_table,指定中间表的名字tags = models.ManyToManyField("Tag",db_table='article_tag')class Meta:db_table = 'article'
表名:切记不要修改表的名字。不然映射到数据库中,会发生找不到对应表的错误。
- 执行命令
python manage.py makemigrations生成初始化的迁移脚本。方便后面通过ORM来管理表。这时候还需要执行命令python manage.py migrate --fake-initial,因为如果不使用--fake-initial,那么会将迁移脚本会映射到数据库中。这时候迁移脚本会新创建表,而这个表之前是已经存在了的,所以肯定会报错。此时我们只要将这个0001-initial的状态修改为已经映射,而不真正执行映射,下次再migrate的时候,就会忽略他。 将
Django的核心表映射到数据库中:Django中还有一些核心的表也是需要创建的。不然有些功能是用不了的。比如auth相关表。如果这个数据库之前就是使用Django开发的,那么这些表就已经存在了。可以不用管了。如果之前这个数据库不是使用Django开发的,那么应该使用migrate命令将Django中的核心模型映射到数据库中。ORM测试:
假设有以下
ORM模型:from django.db import modelsclass Student(models.Model):"""学生表"""name = models.CharField(max_length=100)gender = models.SmallIntegerField()class Meta:db_table = 'student'class Course(models.Model):"""课程表"""name = models.CharField(max_length=100)teacher = models.ForeignKey("Teacher",on_delete=models.SET_NULL,null=True)class Meta:db_table = 'course'class Score(models.Model):"""分数表"""student = models.ForeignKey("Student",on_delete=models.CASCADE)course = models.ForeignKey("Course",on_delete=models.CASCADE)number = models.FloatField()class Meta:db_table = 'score'class Teacher(models.Model):"""老师表"""name = models.CharField(max_length=100)class Meta:db_table = 'teacher'
使用之前学到过的操作实现下面的查询操作:
查询平均成绩大于60分的同学的id和平均成绩;
- 查询所有同学的id、姓名、选课的数量、总成绩;
- 查询姓“李”的老师的个数;
- 查询没学过“李老师”课的同学的id、姓名;
- 查询学过课程id为1和2的所有同学的id、姓名;
- 查询学过“黄老师”所教的“所有课”的同学的id、姓名;
- 查询所有课程成绩小于60分的同学的id和姓名;
- 查询没有学全所有课的同学的id、姓名;
- 查询所有学生的姓名、平均分,并且按照平均分从高到低排序;
- 查询各科成绩的最高和最低分,以如下形式显示:课程ID,课程名称,最高分,最低分;
- 查询没门课程的平均成绩,按照平均成绩进行排序;
- 统计总共有多少女生,多少男生;
- 将“黄老师”的每一门课程都在原来的基础之上加5分;
- 查询两门以上不及格的同学的id、姓名、以及不及格课程数;
-
ORM测试参考答案:
查询平均成绩大于60分的同学的id和平均成绩;
rows = Student.objects.annotate(avg=Avg("score__number")).filter(avg__gte=60).values("id","avg")for row in rows:print(row)
查询所有同学的id、姓名、选课的数、总成绩;
rows = Student.objects.annotate(course_nums=Count("score__course"),total_score=Sum("score__number")).values("id","name","course_nums","total_score")for row in rows:print(row)
查询姓“李”的老师的个数;
teacher_nums = Teacher.objects.filter(name__startswith="李").count()print(teacher_nums)
查询没学过“黄老师”课的同学的id、姓名;
rows = Student.objects.exclude(score__course__teacher__name="黄老师").values('id','name')for row in rows:print(row)
查询学过课程id为1和2的所有同学的id、姓名;
rows = Student.objects.filter(score__course__in=[1,2]).distinct().values('id','name')for row in rows:print(row)
查询学过“黄老师”所教的所有课的同学的学号、姓名;
rows = Student.objects.annotate(nums=Count("score__course",filter=Q(score__course__teacher__name='黄老师'))).filter(nums=Course.objects.filter(teacher__name='黄老师').count()).values('id','name')for row in rows:print(row)
查询所有课程成绩小于60分的同学的id和姓名;
students = Student.objects.exclude(score__number__gt=60)for student in students:print(student)
查询没有学全所有课的同学的id、姓名;
students = Student.objects.annotate(num=Count(F("score__course"))).filter(num__lt=Course.objects.count()).values('id','name')for student in students:print(student)
查询所有学生的姓名、平均分,并且按照平均分从高到低排序;
students = Student.objects.annotate(avg=Avg("score__number")).order_by("-avg").values('name','avg')for student in students:print(student)
查询各科成绩的最高和最低分,以如下形式显示:课程ID,课程名称,最高分,最低分:
courses = Course.objects.annotate(min=Min("score__number"),max=Max("score__number")).values("id",'name','min','max')for course in courses:print(course)
查询每门课程的平均成绩,按照平均成绩进行排序;
courses = Course.objects.annotate(avg=Avg("score__number")).order_by('avg').values('id','name','avg')for course in courses:print(course)
统计总共有多少女生,多少男生;
rows = Student.objects.aggregate(male_num=Count("gender",filter=Q(gender=1)),female_num=Count("gender",filter=Q(gender=2)))print(rows)
将“黄老师”的每一门课程都在原来的基础之上加5分;
rows = Score.objects.filter(course__teacher__name='黄老师').update(number=F("number")+5)print(rows)
查询两门以上不及格的同学的id、姓名、以及不及格课程数;
students = Student.objects.annotate(bad_count=Count("score__number",filter=Q(score__number__lt=60))).filter(bad_count__gte=2).values('id','name','bad_count')for student in students:print(student)
查询每门课的选课人数;
courses = Course.objects.annotate(student_nums=Count("score__student")).values('id','name','student_nums')for course in courses:print(course)
Pycharm配置连接数据库
进入
pycharm后,右边有一个Database的选项,点击这个选项会弹出以下界面: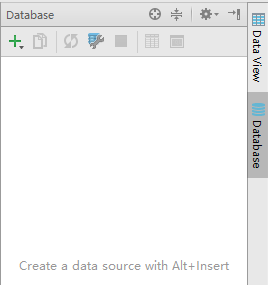
然后点击绿色的添加按钮,会出现以下界面: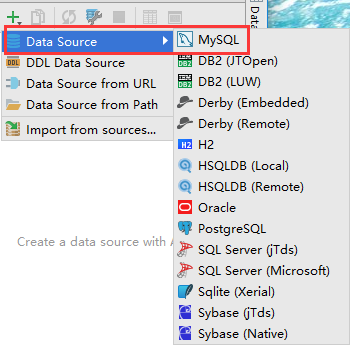
这时候我们选择MySQL,然后会弹出以下配置MySQL的对话框
填入相关的信息。然后Test Connection测试成功后,点击确定即可!关于没有Java Connector Driver:
Pycharm是用java写的,连接MySQL数据库需要一个driver文件,从以下链接中下载mysql-connector-java-5.1.46.zip:[https://dev.mysql.com/downloads/connector/j/](https://dev.mysql.com/downloads/connector/j/),然后解压后,来到以下界面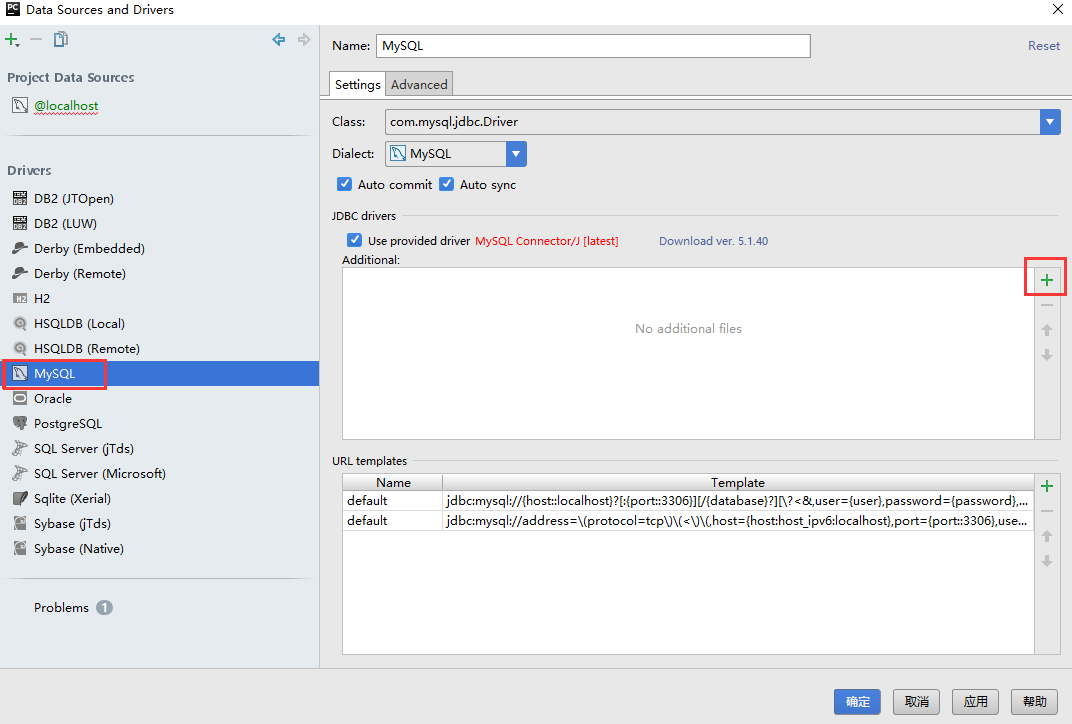
然后点击右边的加号按钮,把刚刚下载的mysql-connector-java-5.1.46-bin.jar加载进来。

若有收获,就点个赞吧
0 人点赞
