https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/learn-flink/etl/
四大基石
Time
https://blog.51cto.com/mapengfei/2554583
Event Time
是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink 通过时间戳分配器访问事件时间戳。
Ingestion Time
Processing Time
是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是 Processing Time。
例如:
一条日志进入 Flink 的时间为 2019-08-12 10:00:00.123,到达 Window 的系统时间为2019-08-12 10:00:01.234
日志的内容如下:
2019-08-02 18:37:15.624 INFO Fail over to rm2
对于业务来说,要统计 1min 内的故障日志个数,哪个时间是最有意义的?—— eventTime
因为我们要根据日志的生成时间进行统计。
Window
https://blog.51cto.com/mapengfei/2554577
streaming 流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集,而 window 是一种切割无限数据为有限块进行处理的手段。Window 是无限数据流处理的核心,Window 将一个无限的 stream 拆分成有限大小的”buckets”桶,我们可以在这些桶上做计算操作。
Window 可以分成两类:
CountWindow:按照指定的数据条数生成一个 Window,与时间无关。
TimeWindow:按照时间生成 Window。
对于 TimeWindow,可以根据窗口实现原理的不同分成三类:
滚动窗口 [Tumbling Window]

滑动窗口 [Sliding Window]

会话窗口 [Session Window]
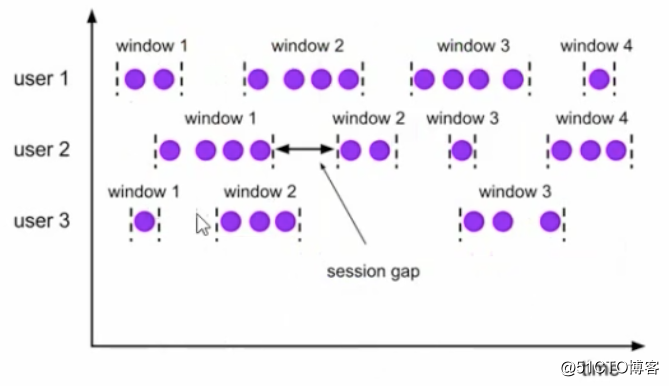
间隔gap时间无数据,则新启一个窗口。所以窗口的size是可变的。
Checkpoint
它能够根据配置周期性地基于 Stream 中各个 Operator/task 的状态来生成快照,从而将这些状态数据定期 持久化存储下来,当 Flink 程序一旦意外崩溃时,重新运行程序时可以有选择地从这些快照进行 恢复,从而修正因为故障带来的程序数据异常。
State
https://blog.51cto.com/mapengfei/2554666
state 一般指一个具体的 task/operator 的状态
【state 数据默认保存在 java 的堆内存中,TaskManage 节点的内存中】【operator 表示一些算子在运行的过程中会产生的一些中间结果】 checkpoint
checkpoint【可以理解为 checkpoint 是把 state 数据定时持久化存储了】,则表示了一个 Flink Job 在一个特定时刻的一份全局状态快照,即包含了所有 task/operator 的状态注意:task(subTask)是 Flink 中执行的基本单位。operator 指算(transformation)。 State 可以被记录,在失败的情况下数据还可以恢复。
Flink 中有两种基本类型的 State:
Keyed State
Operator State
原始状态(raw state)
托管状态(managed state)
获取source的方式
基于文件:readTextFile()
基于socket:socketTextStream
基于集合:fromCollection(Collection)
自定义数据源:addSource
实现SourceFunction<>接口,重写run、cancel,单并行度数据源
实现ParallelSourceFunction<>接口,Kafka多少个分区,这里设置多少个并行度
Flink自带的connector
Kafka
常见Transformation操作
https://blog.51cto.com/mapengfei/2547236
Map和filter
FlatMap、keyby、sum
一行变多行flatmap、一行对一行用map
keyBy按key分组
union:两个数据流合并到一起
connect、conMap和conFlatMap
split(new OutputSelector{…})
对流按规则进行切分,可用select(“XXX”,…)按规则名取出
map()
调用用户定义的MapFunction对DataStream[T]数据进行处理,形成新的Data-Stream[T],其中数据格式可能会发生变化,常用作对数据集内数据的清洗和转换。例如将输入数据集中的每个数值全部加1处理,并且将数据输出到下游数据集。
map()基本是一对一服务,即输入一个元素输出一个元素。
flatMap()
将嵌套集合转换并平铺成非嵌套集合。
对于map()来说,实现MapFunction也只是支持一对一的转换。
那么有时候你需要处理一个输入元素,但是要输出一个或者多个输出元素的时候,就可以用到flatMap()。
使用接口中提供的 Collector ,flatmap() 可以输出你想要的任意数量的元素,也可以一个都不发。
KeyBy
分组处理。
类似数据库的groupby,可单个字段,也可多个字段组合。
aggregate
聚合方式,可通过实现AggregateFunction接口自定义自己的聚合逻辑。
每来一条数据操作一次。
aggregate
Process
https://blog.51cto.com/mapengfei/2554673
之前的转换算子是无法访问事件的时间戳信息和水位线信息的,而这在一些应用场景下,极为重要。例如MapFunction这样子的map转换算子就无法访问时间戳或者当前事件的事件事件。
基于此,DataStream API提供了一系列LOW-LEVEL的转换算子调用。可以访问时间戳,watermark以及注册定时事件,还可以输出特定的一些事件,例如超时时间等。
process function用来构建事件驱动的应用以及实现自定义的业务逻辑(使用之前的window函数和转换算子无法实现)。例如Flink SQL就是使用Process Function实现的。
process不用每来一条数据都定义怎么做,而是把对应的数据会放到内存里面,当窗口结束后进行统一处理,比较耗内存,看实际使用场景。
常见sink操作
https://blog.51cto.com/mapengfei/2547250
https://blog.51cto.com/mapengfei/2547266
https://blog.51cto.com/mapengfei/2547246
https://blog.51cto.com/mapengfei/2547243
Print()/printToErr()<br /> writeAsText()<br /> 自定义sink() 到redis<br /> New flinkJedisPoolConfig.Builder().setHost()…<br /> 实现RedisMapper接口,重写getKeyFromData、getValueFromData、getCommandDescriptor<br /> RedisCommad.LPUSH数据结构选择<br /> Flink自带的connector->kafka、ES
watermark
https://blog.51cto.com/mapengfei/2554654
水位线的意义
watermark最大的作用其实就是为了解决数据乱序问题。

若有收获,就点个赞吧
0 人点赞
