现象
前不久在生产环境上遇到的一个问题,DBA反馈说,入库业务有积压,集群的某个节点,ssh登录都非常卡顿。
分析
由于没有监控,只能通过当时的日志去推断问题的原因,我们在系统日志里面发现了这个消息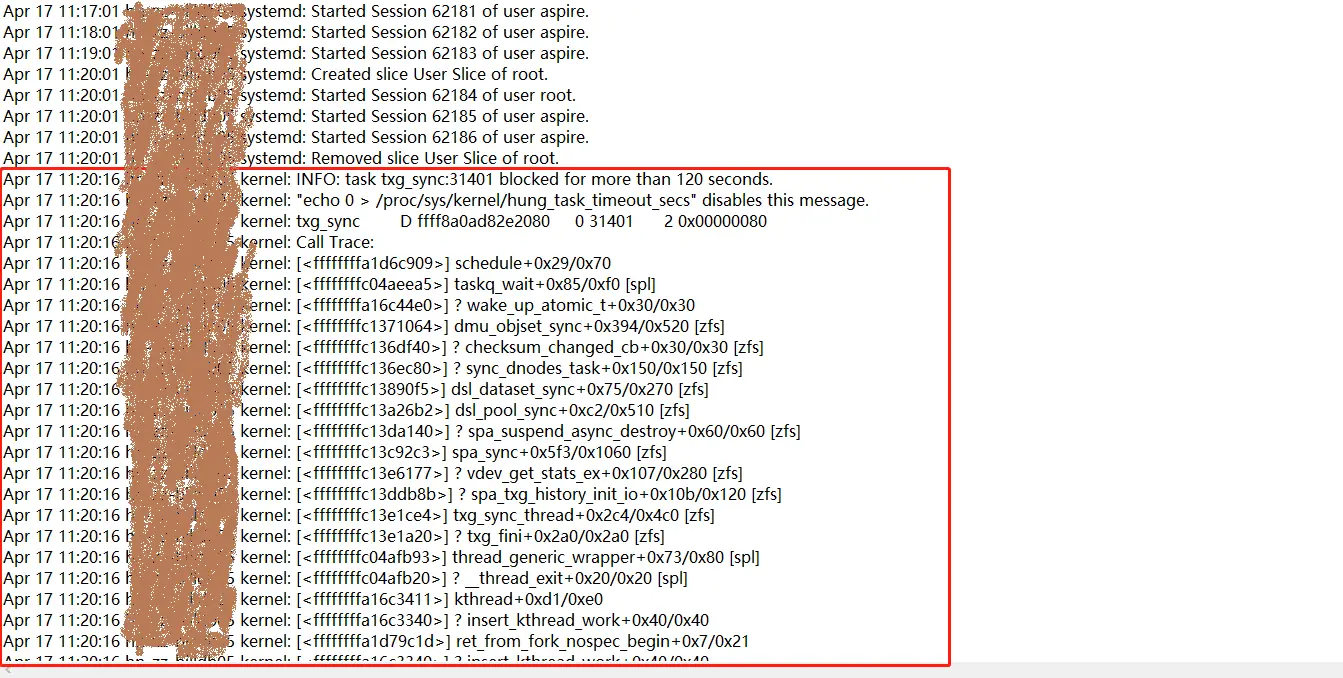
于此同时,数据库的高可用发生了切换(failover),自动切换的进程判断认为主库已经挂了。那么大概率是某些进程发生的IO拥堵,导致文件系统的写缓存耗尽了OS的内存?所以整个机器卡顿的不行,连高可用的检活SQL都没有响应(所以判断主库挂了)。
因为PG的shared_buffers本身是一层缓存,文件系统又有一层缓存,相当于数据要双份缓存之后,才会真正落盘。
因此我考虑是不是可以将这种写非常重,读不多的系统,把shared_buffers降到物理内存的15%到20%,然后把这两个内核参数改一下
# 更积极的去把脏数据刷盘vm.dirty_ratio = 5# 给大一点的OS缓存,让突发的IO有更多的缓存可用,让IO更平滑(到达60%才会强制同步刷盘)vm.dirty_background_ratio = 60~80
同时要注意下连接数和work_mem的值,保证日常连接的内存够用。
实际效果有待压测验证一下。
补充
查看缓存有多少脏页未刷盘
cat /proc/vmstat | egrep 'dirty|writeback'nr_dirty 5563 -- 脏页数nr_writeback 0nr_writeback_temp 0nr_dirty_threshold 2625645nr_dirty_background_threshold 656411

若有收获,就点个赞吧
0 人点赞
