人类社会在计数的过程中采用的是十进制,大概是因为绝大数的人都拥有是个手指的缘故。而计算机世界中存储和处理的信息都是 0 和 1 这两个值,也就是二进制,大概和上古时期计算机采用穿孔纸带作为其输入输出设备的缘故,其中打孔表示 1,无孔表示 0,并且现代计算机通过有无电压表示 0 和 1 也是和二进制相契合的。
我们主要研究三种最重要的数字表示:无符号数,有符号数,浮点数。计算机的表示法是用有限的比特位来对一个数字编码,但需要编码的数字范围是无限的,因此当结果太大以至于不能表示时,就会发生溢出。
fn main() {let a: u16 = 65535;println!("65535 + 1 = {}", a + 1);}
这段 Rust 代码编译的时候就会出现错误,提示你运算将会发生溢出。
而如下对应的 C++ 代码则会错误的输出 “65535 + 1 = 0”,而不是我们期待的 65536。
int main() {short a = 65535;printf( "65535 + 1 = %d\n", a + 1);return 0;}
总之像这种溢出发生的时候都不是我们想要的情况,最好能够在编译的时候就避免掉,即使无法在编译时避免也应该在运行时报错而不是直接就这样自动做截断处理了。
fn one() -> u16 {1}fn main() {let a: u16 = 65535;println!("65535 + 1 = {}", a + one());}
比如,对于上面的 Rust 代码,在运行的时候会直接 panic 掉并报告说发生了溢出。
thread 'main' panicked at 'attempt to add with overflow', src/main.rs:7:32
举这个 Rust 和 C++ 各自对溢出情况处理的例子只是想安利一波 Rust ~~~
信息的储存和表示
在介绍三种重要的数字表示之前我们需要先了解一下信息是怎么存储的,多字节信息在内存中是如何排列的等。大多数计算机都使用 8 位的块,也就是字节,作为最小可寻址的内存单位,而不是内存中单独的比特位。机器级程序将内存视为一个非常大的字节数组,称为虚拟内存。内存中每一个字节都由一个唯一的数字来标识,称为它的地址,所有可能的地址集合称为虚拟地址空间。
比如 C/C++ 语言中的指针的值(无论它指向一个整数,一个结构体或是某个其他程序对象)都是某个存储块的第一个字节的虚拟地址,而它的类型则表明了它指向的存储块的大小。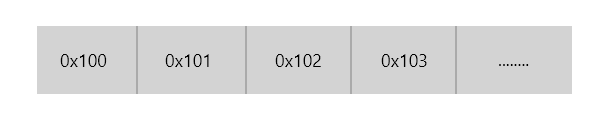
比如某个指向 int 型的指针指向了 0x100 的位置,那么读取这个指针指向的值的时候,它只会从 0x100 读取到 0x103 这个位置,它并不会一直往下读取到 0x104 的位置也不会只读取到 0x102 的位置就停止,因为 int 的大小就是 4 个字节。
十六进制表示
除了二进制以外,在计算机中用的比较多的就是十六进制了。我们知道一个字节有 8 位,那么它的值域用二进制表示就是00000000 ~ 11111111,对应的十进制表示就是0 ~ 255。这两种表示都不是很方便,二进制表示太冗长,十进制表示又不方便转换成二进制那种位模式表示。替代的方式就是用十六进制表示,那么一字节的值域就是00 ~ FF。
| 十六进制 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 十进制 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 二进制 | 0000 | 0001 | 0010 | 0011 | 0100 | 0101 | 0110 | 0111 | 1000 | 1001 | 1010 | 1011 | 1100 | 1101 | 1110 | 1111 |
十六进制和二进制之间的转换就非常简单直接,因为每次执行一个十六进制数的转换到二进制(或 4 位二进制数的转换到十六进制)即可。
比如:
有一个十六进制的数 0x173A4C。转换成二进制的时候只需展开每个十六进制数并单独转换成二进制后按原来顺序组合起来即可。
| 十六进制 | 1 | 7 | 3 | A | 4 | C |
|---|---|---|---|---|---|---|
| 二进制 | 0001 | 0111 | 0011 | 1010 | 0100 | 1100 |
最后它转换后的二进制表示就是** 0001 0111 0011 1010 0100 1100 **。
反过来,对于一个给定的二进制数** 11 1100 1010 1101 1011 0011 **,首先从最低有效位开始每 4 位分成一组来转换成十六进制,如果位总数不是 4 的倍数,在最高有效位补 0 即可。
| 二进制 | 0011 | 1100 | 1010 | 1101 | 1011 | 0011 |
|---|---|---|---|---|---|---|
| 十六进制 | 3 | C | A | D | B | 3 |
最后转成后的十六进制表示就是 0x3CADB3 。
十进制到十六进制的转换这种更一般的情况则需要不断的除商取余。比如有一个十进制数 314156 转换成十六进制的方式为:
所以,转换后的十六进制表示就是 0x4CB2C 。
反过来对于十六进制到十进制的转换,则可以用相应的 16 的幂乘以每个十六进制数并相加得到。比如有一个十六进制数 0x7AF 转换成十进制的方式为:7 * 16 + 10 * 16 + 15 * 16 = 1967。
寻址和字节顺序之大小端
定长的字节块叫做字,一个字包含的字节数就是字长,每台计算机都有一个字长,用来指明指针数据的标称大小,也就是存储指针本身用到的大小。因为虚拟地址就是用字来编码的,所以字长决定的最重要的系统参数就是虚拟地址空间的最大大小。比如对于字长为w的机器,虚拟地址的范围在0 ~ 2 - 1,程序最多访问2个字节。
对于大多数数据类型而言,都是跨越多个字节的。比如在 Rust 中除了u8,i8,bool 是一个字节外,其他像 char,i32等都是多字节的。
对于这种多字节数据,有两点需要确定:
- 这个数据对象的地址什么?
- 在内存中如何排列这些多字节?
在几乎所有机器上,多字节数据都被存储在连续的字节块中,数据的地址就是所使用的字节块中最小的地址。
假设有一个 i32 的整数数据连续的存储在0x100,0x101,0x102,0x103这四个字节中,那么我们获取这个 i32 类型的整数数据地址时,得到就是0x100这个地址。
考虑到一个w位的整数,其位表示为[ x,x,... ,x,x ]。其中x就是最高有效位,x就是最低有效位,若能将其分组成字节,则最高有效字节包括[ x,x,..., x],最低有效字节则是 [ x,x,... ,x,x ]。
某些机器选择在内存中按照从最高有效字节到最低有效字节的顺序存储,而另一些机器则选择按照从最低有效字节到最高有效字节的顺序存储。这两种分别就是大小端存储法。
假设有一个 i32 类型的变量位于地址 0x100 处,它的十六进制值为 0x01234567。
大端法:最高有效字节在最前面(低地址处)的方式。
小端法:最低有效字节在最前面(低地址处)的方式。
另外,计算机在读取内存地址的时候总是从低地址往高地址方向读取,所以我们可以通过下面的程序来检测当前系统是大端还是小端。
fn main() {union Union {a: i32,b: i8}let u = Union{ a: 0x11 };unsafe {println!("{}", if u.b == 0x11 { "Little Endian" } else { "Big Endian" });}}
布尔代数及位运算
二进制是计算机编码,存储和操作信息的核心。因此围绕数值 0 和 1 的研究已经演化出了丰富的数学知识体系。这源于一个叫布尔的数学家,他注意到通过将逻辑真值(true)和逻辑假值(false)编码成二进制 1 和 0 能够设计一种代数,以研究逻辑推理的基本准则,所以也称为布尔代数。
最简单的布尔代数是在二元集合 { 0,1 } 上定义的,如下是它定义的四种运算。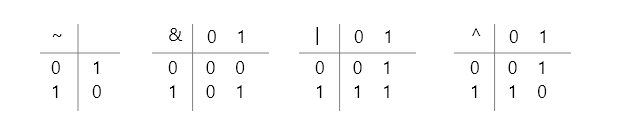
布尔运算 ~ 对应于逻辑非(not),即若 p 等于 0,则 ~p 等于 1,反之亦然。
布尔运算 & 对应于逻辑与(and),即当且仅当 p 和 q 都为 1 的时候,p & q 才等于 1。
布尔运算 | 对应于逻辑或(or),即只要 p 和 q 有一个等于 1,p | q 就等于 1。
布尔运算 ^ 对应于逻辑异或(xor),即当且仅当 p | q 等于 1 同时 q & q 等于 0 时,p ^ q 才等于 1。异或运算的符号表示为“⊕”,所以你可以把它看作是做的加法,但又不同于一般的加法,它是做的奇偶性加法,比如,0 表示偶数,1 表示奇数。
异或运算还可以叫半加运算,也就是说你可以把它看成是不带进位的二进制加法。
_
在系统级编程语言比如 C/C++,Rust 中都支持按位级的布尔运算,所使用的符号都和前面提到一致。除此之外还提供了一些移位操作,比如左移 <<,右移 >> 等。
左移顾名思义就是把整个值的比特位向做移动 k 位。右移顾名思义就是把整个值的比特位向右移动 k 位。但这样的话就带来一个问题是,移动之后,可能有一些比特位会被丢弃,同时必然**会在相反的方向空出一些比特位。一帮情况下都是直接填 0 。
比如有一个 i8 类型的十进制数 182 ,它的二进制表示为1011 0110左移两位之后就变成了1101 1000,也就是十进制的 216 ;如果 182 是一个 i16 类型或以上类型的数字,则左移之后并没有高位被丢弃,只在低位填了两个 0,移位后的二进制就是0010 1101 1000,也就是十进制的 728,也就是 182 的 4 倍。
直接在空出的比特位上补 0 对于左移是没有问题的,但是对于右移就有问题了,原因在于对于负数的情况,右移之后如果直接在高位补 0 的话,则一个负数右移之后就变正数了,明显这是有问题的,所以对于右移存在逻辑右移和算术右移。逻辑右移指的是在左端补 0,算术右移值的是在左端补最高有效位的值。
注意,对于无符号数来说,很明显,右移必须一定是逻辑右移(否则右移之后的数据还反倒增大了)。对于 Rust 语言来说,执行右移的时候会自动根据数据类型来决定是逻辑右移还是算术右移,但 C/C++ 标准并没有规定应该使用哪种右移,不过一般的编译器实现都会自动选择合适的右移。
整数的表示及运算
整数主要有两种不同的位编码方式:一种是有符号数,能够表示负数,零,正数;另一种是无符号数,只能表示非负数。
 假设一个整数 x 的二进制位有 w 位,则其位向量的表示形式为
假设一个整数 x 的二进制位有 w 位,则其位向量的表示形式为  。
。
无符号数编码
对于 :
函数  就表示从位向量到无符号整数的映射。举例:
就表示从位向量到无符号整数的映射。举例:
根据上面无符号编码的方式可知w位所能表示的范围在[00..00] ~ [11..11]之间,最小值就是 0 ,而最大值就是  。
。
并且无符号数的编码有一个重要属性,即每个介于  之间的数都有唯一一个
之间的数都有唯一一个w位的比特位值编码。
有符号数编码
上述的无符号数编码只能表示非负数,但是负数值也是很常见且必须的。对于有符号数的编码主要有三种:补码,反码,原码。
 其中用的最多的就是补码。其定义如下。
其中用的最多的就是补码。其定义如下。
对于:
最高有效位  被称为符号位,它的权重为
被称为符号位,它的权重为  ,是无符号编码中权重的相反数。符号位被设置为 1 时表示值为负数,设置为 0 时则表示值为正数。
,是无符号编码中权重的相反数。符号位被设置为 1 时表示值为负数,设置为 0 时则表示值为正数。
举例:
考虑一下一个 w 位所能表示的值的最小值是[100..0],也就是 ,因为根据上面的函数,要想整个 f(x) 的值最小,则后面的求和部分为 0 即可;最大值则是[011..1],也就是  ,同样根据上面的函数,要想整个 f(x) 的值最大,则只需前面负数部分为0,保持后面的求和部分为最大即可;
,同样根据上面的函数,要想整个 f(x) 的值最大,则只需前面负数部分为0,保持后面的求和部分为最大即可;
可以看到,补码表示的范围是不对称的,原因是因为一半的位模式表示负数,另一半的位模式表示非负数,而 0 是非负数,导致正数比负数少了一个。
同无符号数编码一样,补码编码也具有唯一性。也就说每个在范围内数字都有唯一一个w位的补码表示。
有符号数还有另外两种标准的编码方法。
反码:除了最高有效位的权是  而不是
而不是  外,它和补码是一样的。
外,它和补码是一样的。
原码:最高有效位是符号位,用来确定剩下的比特位最终应该取负权还是正权。
这两种编码方式都会导致存在两个数字 0,把[00...0]解释位 +0,而原码把[10...0]解释为 -0,同样的,反码把[11...1]解释为 -0。 因为各种原因现代机器几乎全部都是用补码,而不使用反码和原码。其中很重要的一个原因就是采用补码之后,计算机就不需要再单独设计减法器了,因为根据运算发法则,减去一个正数就等于加上它的负数,所以直接对一个负数的补码做加法相当于就是做减法了。
有符号数和无符号数之间的转换
fn main() {let a: i16 = -12345;let ua: u16 = a as u16;println!( "a={}; ua={}", a, ua );}//output: a=-12345; ua=53191
上面是一段 Rust 程序的有符号数到无符号数之间的强制转换,可以看到有符号数 -12345,转换成无符号数之后变成了 53191。根据前面的结论我们知道几乎所有的机器都是采用补码来表示有符号数,所以我们直接看 -12345 的补码表示的位向量:-12345 =``[1100 1111 1100 0111] 。
现在我们将其转换成无符号数之后,我们直接按无符号数的编码来解释这段位向量。
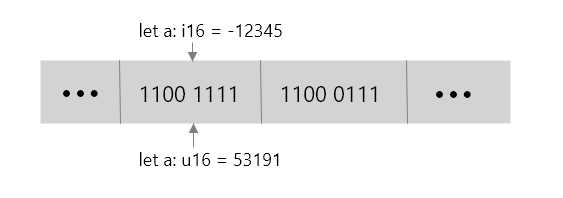
结论:相同字长强**制转换**的结果保持对应比特位值不变,只是改变了解释这些比特位的方式。这就是类型之于变量的作用,它不仅决定了这个变量占用多少个字节,还决定该如何读取这些字节,以及可以对这些字节做哪些操作。对于 C/C++ 也是如此。
不同字长的整数之间相互转换也是很常见的操作,若将一个较大的整数转换成较小的整数,高位部分则直接被截断处理。
将一个无符号数转换成一个更大的数时,只要简单的在高位添加 0 即可,这种运算称零扩展运算。
将一个补码数字转换成一个更大的数时,只要简单的在高位添加符号位的值即可,这种运算称符号扩展运算。
举例:
int main(){int a = 53191;short sa = (short) a; // -12345;高16位(都是0)被截断int b = (int) sa; // -12345;发生符号扩展,高16位全部补1printf("a=%d; sa=%d; b=%d",a, sa, b);//输出 a=53191; sa=-12345; b=-12345return 0;}
在 C/C++ 语言中存在一些隐式转换的场景,比如参数传递,一个有符号数和无符号数做算术运算等场景。这可能是一些潜在问题的根源。

若有收获,就点个赞吧
0 人点赞
