是业界最快最高性价比的关系型分布式数据库,它在开源的PostgreSQL的基础上采用MPP架构(Massive Parallel Processing,海量并行处理),具有强大的大规模数据分析任务处理能力。
GreenPlum的特点
1) 完善的标准:GreenPlum数据库支持ANSI SQL 2008和SQL OLAP 2003扩展;支持ODBC和JDBC应用编程接口。完善的标准支持使得系统开发、维护和管理都大为方便。
(而现在的 NoSQL和Hadoop 对 SQL 的支持都不完善,不同的系统需要单独开发和管理,且移植性不好。)
2) 数据的强一致性:GreenPlum数据库支持分布式事务,支持ACID,保证数据库中数据的强一致性。
3)良好的线性扩展能力:GreenPlum数据库采用MPP架构,其基本特征是有多台SMP(Symmetric Multi-Processor,对称多处理器)服务器通过节点互联网络连接而成,是一种Share Nothing(完全无共享)结构,因而扩展能力最强,理论上可以无限扩展。目前的技术可以实现512个节点互联,包含数千个CPU。
Greenplum架构
GreenPlum数据库是典型的Master/Slave架构。
如下图所示,在Greenplum集群中,存在一个Master节点和多个Segment节点。
Master实例是GreenPlum数据库服务端,服务端通过端口监听客户端连接。
Segment由Master分配,管理一部分数据存储进程,每个Segment都采用独立端口监听。
Master实例协调所有数据库实例,分布式请求Segment并且合并从Segment返回的结果。
GreenPlum数据库采用典型的Shared Nothing架构(MPP),每个节点只访问自己的本地资源(内存、存储等),节点之间的信息交互都是通过节点高速互联网络实现,这个过程一般称为数据重分配。GreenPlum数据库采用了MPP架构,其主要的优点是大规模的并行处理能力。
1) 大规模存储。GreenPlum数据库通过将数据规律地分布到多个节点上来实现大规模数据的存储,支持50PB级海量数据的存储和处理。
2) 并行处理。GreenPlum数据库通过外部表并行装载、并行备份恢复与并行查询处理实现强大的并行处理。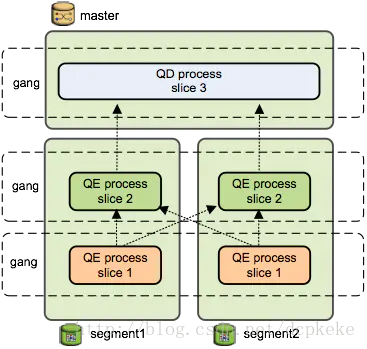
GreenPlum数据库VS传统数据库
使用传统数据库时,我们经常会通过分库分表的方式将数据打散到多个数据库实例中。
其缺点在于可能会出现不平均的情况:数据在后端被打散成许多数据分片,但是有些分片的数据量很大,热度很高,有些分片相对来说热度较低。
当进行数据统计或分析时,一部分用户数据处理速度慢,一部分用户数据处理速度快,使得许多用户的体验下降。
GreenPlum数据库采用分而治之的方法,将数据非常均衡的分布在所有节点上。而且当服务器数量不够或者计算能力不够的时候,可以在线横向扩展,此时数据库会重新做二次分片,也就是表数据需要重新分布,在保证强大处理能力的同时也时刻保持用户性能的均衡,提升用户体验。

若有收获,就点个赞吧
0 人点赞
