结构
参考 MySQL是怎么运行的 chapter6
mysql> CREATE TABLE index_demo(-> c1 INT,-> c2 INT,-> c3 CHAR(1),-> PRIMARY KEY(c1)-> ) ROW_FORMAT = Compact;Query OK, 0 rows affected (0.03 sec)mysql> INSERT INTO index_demo VALUES(1, 4, 'u'), (3, 9, 'd'), (5, 3, 'y');Query OK, 3 rows affected (0.01 sec)Records: 3 Duplicates: 0 Warnings: 0mysql> INSERT INTO index_demo VALUES(4, 4, 'a');Query OK, 1 row affected (0.00 sec)
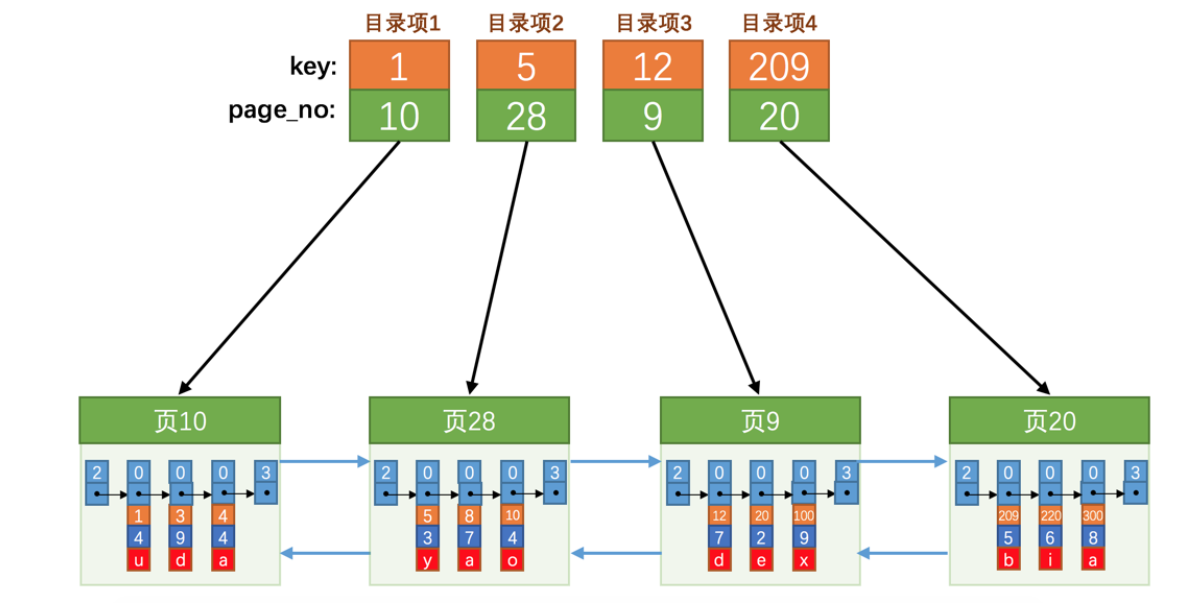
类型
- 唯一索引。对于单列索引,不允许有重复值出现;对于多列(复合)索引,不允许出现重复的组合值。
- 常规(非唯一性)索引。获得索引的好处,但会出现重复值。
- fulltext索引。用于全文检索,本仅限于MyISAM表,但MySQL5.6.4之后,InnoDB也支持。
- spatial索引。只适用于包含空间值得MyISAM表
- hash索引。memory表的默认索引类型
```sql
索引的创建
alter table tbl_name add unique index_name (index_columns); alter table tbl_name add index index_name (index_columns); alter table tbl_name add primary key index_name (index_columns); alter table tbl_name add fulltext index_name (index_columns); alter table tbl_name add spatial index_name (index_columns);
除了primary key,大部分索引都可以用create index来创建
create index index_name on tbl_name (index_columns); create unqiue index_name on tbl_name (index_columns); create fulltext index_name on tbl_name (index_columns); create spatial index_name on tbl_name (index_columns);
create table tbl_name{ …列定义… index index_name (index_columns), unqiue index_name (index_columns), primary key index_name (index_columns), fulltext index_name (index_columns), spatial index_name (index_columns),
}
索引的删除
drop index index_name on tal_name alter table tbl_name drop index index_name
<a name="SWIc7"></a>
###
<a name="zWEMH"></a>
### 无索引查询的情况
```sql
create table det (a int(2));
insert into det values(1);
explain select * from det where a = 1;
#查询类型为type
1,SIMPLE,det,,ALL,,,,,1,100,Using where
构建高性能索引的策略
关于日期类型索引的处理
see 《MySQL技术内幕》 chapter5
- MySQL 5.7.21 有问题
``sql CREATE TABLEmember(member_idint(10) unsigned NOT NULL AUTO_INCREMENT,last_namevarchar(20) NOT NULL,first_namevarchar(20) NOT NULL,suffixvarchar(5) DEFAULT NULL,expirationdate DEFAULT NULL,emailvarchar(100) DEFAULT NULL,streetvarchar(50) DEFAULT NULL,cityvarchar(50) DEFAULT NULL,statevarchar(2) DEFAULT NULL,zipvarchar(10) DEFAULT NULL,phonevarchar(20) DEFAULT NULL,interestsvarchar(255) DEFAULT NULL, PRIMARY KEY (member_id`) ) ENGINE=InnoDB AUTO_INCREMENT=103 DEFAULT CHARSET=utf8
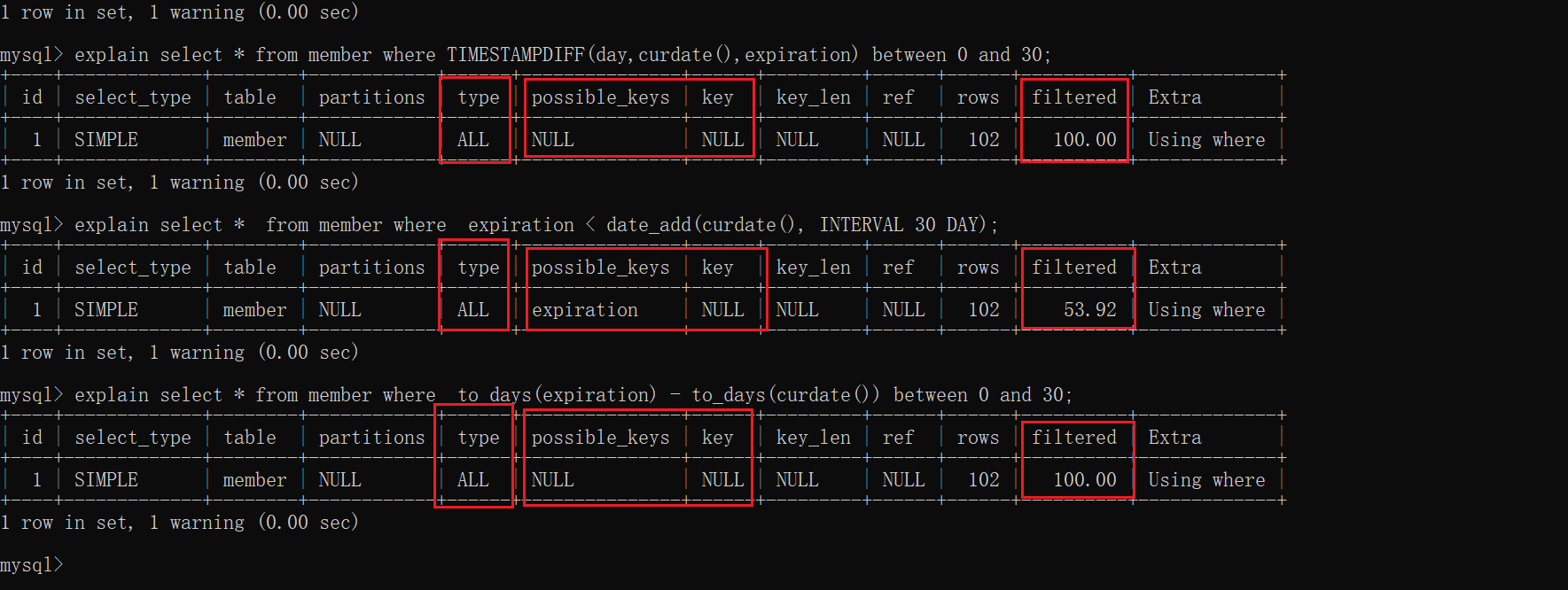
select count(*) from member where TIMESTAMPDIFF(day,curdate(),expiration) between 0 and 30;
select count(*) from member where to_days(expiration) - to_days(curdate()) between 0 and 30;
需求:查询任期距离当前日期不足一月的数据
to_days函数用法示例
select to_days(curdate()) - to_days(‘2021-05-01’)
随机修改日期为今年度
update member set expiration = concat(‘2021’,’-‘,floor(1+rand()12),’-‘,floor(1+rand()30));
step1,添加数据库
alter table member add index (expiration);
以下查询类型全为all
explain select * from sampdb.member where to_days(expiration) -to_days(curdate()) < 30;
explain select * from sampdb.member where to_days(expiration) < 30 + to_days(curdate());
查看该表中有那些索引
show index from member;
explain select * from member where expiration < date_add(curdate(),interval 30 day);
<a name="NUXuI"></a>
##### 日期范围的查询
```sql
mysql> explain select * from member where expiration between '2021-06-01' and '2021-06-30';
+----+-------------+--------+------------+-------+---------------+------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | member | NULL | range | expiration | expiration | 4 | NULL | 12 | 100.00 | Using index condition |
+----+-------------+--------+------------+-------+---------------+------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from member where expiration >='2021-06-01' and expiration <= '2021-06-30';
+----+-------------+--------+------------+-------+---------------+------------+---------+------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+-------+---------------+------------+---------+------+------+----------+-----------------------+
| 1 | SIMPLE | member | NULL | range | expiration | expiration | 4 | NULL | 12 | 100.00 | Using index condition |
+----+-------------+--------+------------+-------+---------------+------------+---------+------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)
索引列不能是表达式的一部分或函数的一部分
create table t3(id int primary key auto_increment,name varchar(10)) engine = InnoDb;
insert into t3(name) values ('a'),('b'),('c');
explain select * from t3 where id+1 =2;
1,SIMPLE,t3,,ALL,,,,,3,100,Using where
前缀索引的选择处理
CREATE TABLE sakila.city_demo(city VARCHAR(50) NOT NULL);
INSERT INTO sakila.city_demo(city) SELECT city FROM sakila.city;
-- Repeat the next statement five times:
INSERT INTO sakila.city_demo(city) SELECT city FROM sakila.city demo;
-- Now randomize the distribution (inefficiently but convenientiy):
UPDATE sakila.city_demo
SET city = (SELECT city FROM sakila.city ORDER BY RAND() LIMIT 1);
#完整性列表
select count(*) as cnt,city from sakila.city_demo group by city order by cnt desc limit 10;
select count(*) as cnt,left(city,3) as pref from sakila.city_demo group by pref order by cnt desc limit 10;
#接近完整列
select count(*) as cnt,left(city,7) as pref from sakila.city_demo group by pref order by cnt desc limit 10;
#计算完整列的选择性
select count(distinct city) /count(*) from sakila.city_demo;
#使前缀的选择性接近于完整列的选择性
select count(*) as cnt,left(city,7) as pref from sakila.city_demo group by pref order by cnt desc limit 10;
select count(distinct city) /count(*) from sakila.city_demo;
select count(distinct LEFT(city,3))/count(*) as sel3,
count(distinct LEFT(city,4))/count(*) as sel4,
count(distinct LEFT(city,5))/count(*) as sel5,
count(distinct LEFT(city,6))/count(*) as sel6,
count(distinct LEFT(city,7))/count(*) as sel7 from sakila.city_demo;
#增加索引
alter table sakila.city_demo add key (city(7));
联合索引
create table people (
last_name varchar(50) not null ,
first_name varchar(50) not null ,
dob date not null ,
gender enum('m','f') not null ,
key(last_name,first_name,dob)
);
#可以使用索引的情况
#全职匹配
explain select * from people where last_name='li' and first_name = 'si' and dob = '2010-05-20';
#匹配最左前缀
explain select * from people where last_name = 'zhao';
#匹配列前缀
explain select * from people where last_name like 'l%';
#匹配列后缀 无法使用索引
explain select * from people where last_name like '%l';
#匹配范围值
explain select * from people where last_name > 'li' and last_name < 'wang';
#精确匹配某一列并范围匹配另外一列
explain select * from people where last_name = 'li' and last_name > 'er';
#只访问索引的查询
explain select last_name, first_name, dob from people;
####无法使用索引的情况
#不是按照索引的最左列开始查找,出生日期同理
explain select * from people where first_name = 'si';
#索引列在函数中 无法使用
explain select * from people where left(last_name,1) = 'l';

若有收获,就点个赞吧
0 人点赞
