1 JVM
JVM (Java Virtual Machine) 是一种虚拟机,具有 2 个主要特性:
- 支持跨平台程序:JVM 定义了 Java 字节码,JVM 字节码是一套虚拟的指令集,他不与任何具体平台(CPU, 操作系统)绑定。JVM 通过将 Java 字节码指令翻译成具体平台的指令,使得用 Java 字节码表示的程序能够运行在不同平台上。对于用任一语言编写的程序,只要其源代码能被编译成 Java 字节码,那么该程序就可以跨平台运行。目前支持 Java 字节码的语言有:Java, Kotlin, Scala, Groovy。
- 自动管理内存:在 JVM 上运行的程序,其运行期间内存的分配和无用内存的回收,由 JVM 自动管理,而不是由程序管理。
2 NIO
2.1 I/O模型
网络程序的读网络数据操作包含 2 个步骤:
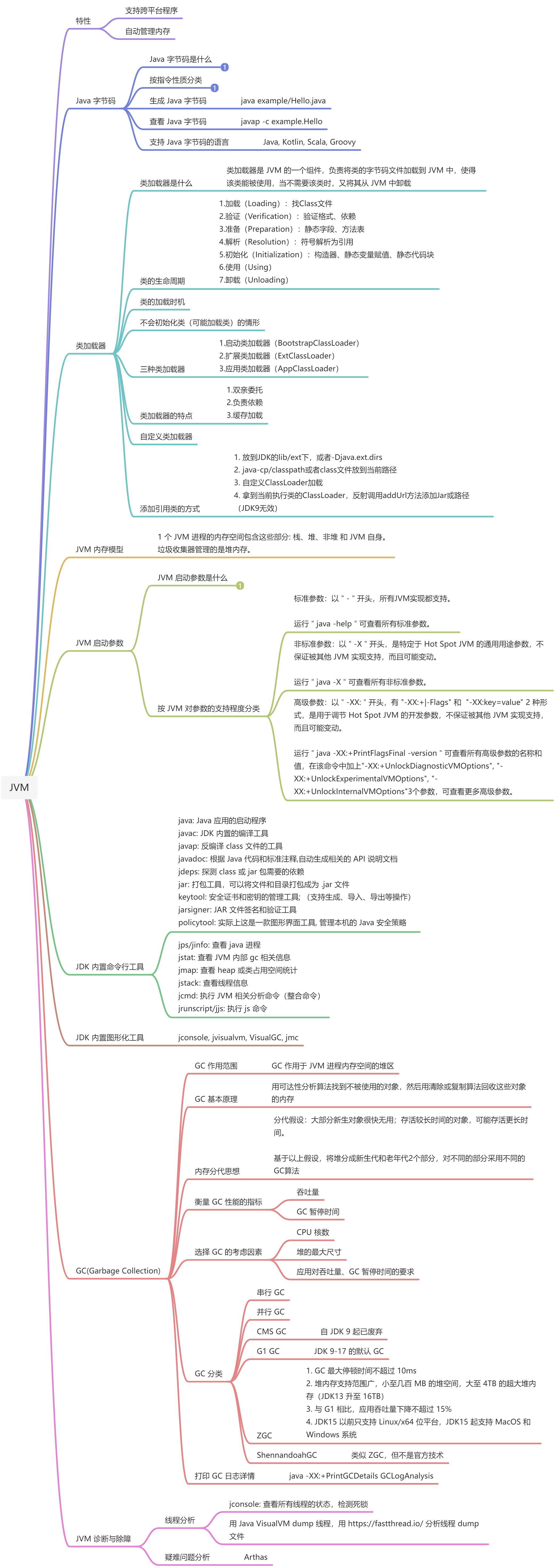
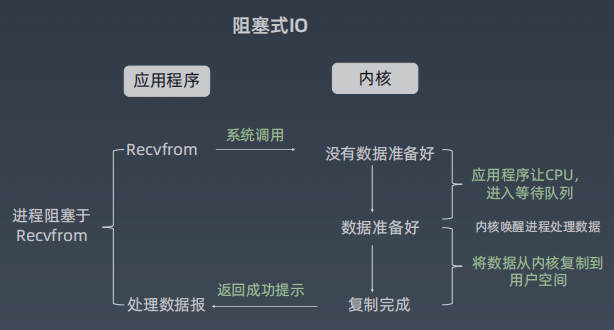
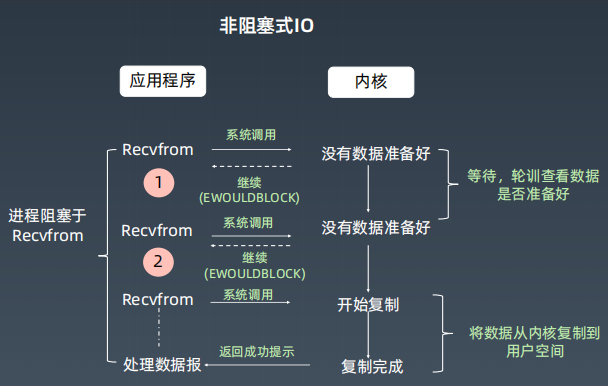
- 步骤1:等待对端进程发送的数据被写到本机的内核缓冲区
- 步骤2:从内核缓冲区复制数据到用户空间。仅当内核缓冲区有数据时,才能执行后一步骤。
网络编程 API 按其对这 2 个步骤的处理方式,可以分成 5 个模型:
- 阻塞I/O(BIO)模型:线程在 2 个步骤中都被阻塞(指线程失去参与线程调度的资格)。
- 非阻塞I/O(NIO)模型:若步骤1未完成,则读操作直接返回,即步骤1不会阻塞线程。若步骤1已完成,则执行步骤2,步骤2是阻塞的。
- I/O多路复用模型:该模型为应用提供 selector 接口,应用将多个网络连接注册到一个 selector 上,然后用该 selector 查询这些网络连接的步骤1是否完成,这个查询是阻塞的,直到至少有 1 个网络连接的步骤1完成,然后就可以对完成了步骤1的连接执行步骤2,步骤2是阻塞的。Linux 通过 epoll 系统调用实现该模型。该模型是高并发网络应用的常用模型。
- 信号驱动的I/O模型:对于步骤1,应用线程向内核发信号,表示要读取数据,然后线程即可继续执行,即步骤1不阻塞线程。等步骤1完成后,内核向应用线程发信号,然后应用线程执行步骤2,步骤2是阻塞的。
- 异步I/O模型:应用线程读fff操作后,即可继续执行,等步骤1完成后,内核完成步骤2,然后向应用线程发信号。Windows 实现了该模型,Linux 没有实现该模型。
阻塞I/O(BIO)模型
非阻塞I/O(NIO)模型
I/O多路复用模型
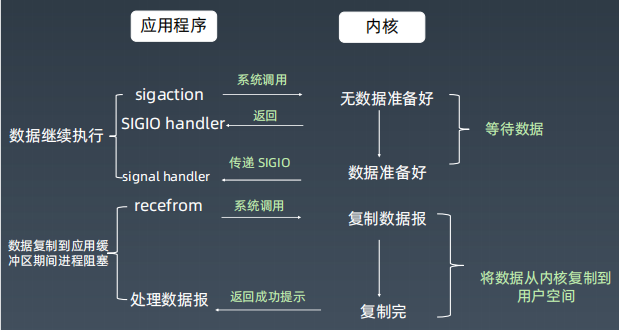
信号驱动的I/O模型
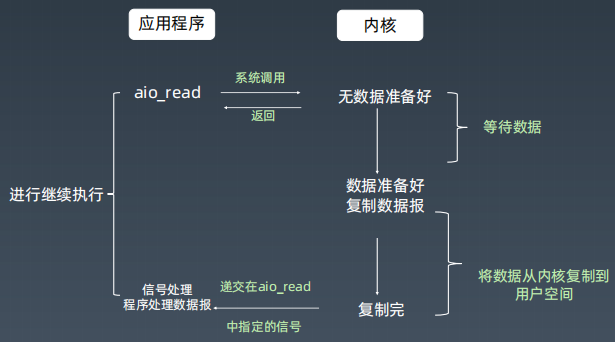
异步I/O模型
图片来源:极客时间,秦金卫,Java进阶训练营,Week2-02.pdf
2.2 Netty
Netty 是一个优秀的网络应用开发框架,他基于I/O多路复用模型。
3 并发编程
3.1 并发编程是什么
事务:事务有开始时间、结束时间,从开始时间到结束时间的时段称为事务的生存期。事务有执行中、暂停2种状态。
并发:若2个事务的生存期存在重叠,则说这2个事务在重叠时段内是并发的,或简单地说这2个事务是并发的。
并发程序:若一个程序的进程包含多个并发线程(通常这些线程协作完成同一任务),则称这个程序是并发程序。
3.2 为什么要并发编程
简化编程:某些场景明显具有多个执行流,例如控制台贪吃蛇游戏有更新蛇的位置和监听玩家输入2个执行流,在这些场景下,并发编程比单线程编程更简单。
提高资源利用率和系统性能:充分利用CPU等资源,提高系统性能(并发量、吞吐量、延迟)。
3.3 并发编程的问题
3.4 并发编程图谱
并发编程图谱: https://www.yuque.com/zixiu1991/ik6gvs/kz705l
4 Spring 和 ORM 等框架
Spring: Spring 框架的核心是 IoC(Inversion of Control) 和 AOP(Aspect Oriented Programming)。Bean 的生命周期是 Spring 框架的重要知识点,对于理解 Spring IoC/AOP 的运行机制很重要。
Spring MVC: 用于 Web 开发的 MVC(Model-View-Controller) 框架。
Spring Boot: 加速开发 Spring 应用的脚手架,核心思想:约定大于配置,注解大于 XML。
Spring Boot Starter: Spring Boot 集成第三方组件的机制。
ORM: ORM(Object-Relational Mapping)指将关系数据库的记录转换成面向对象编程语言的对象,或反之。Java 领域常用 ORM 库有: JPA, Hibernate, MyBatis 等。Spring 集成了常用 ORM 库,既能用于关系数据库,也能用于非关系数据库(Redis, MongoDB 等)。
Lombok: Lombok 是基于 jsr269 实现的一个 java 类库,用他的注解可以自动生成类的 get、set方法及构造函数,还能自动生成 logger、toString、hashCode、Builder 等 Java 特色的函数或是符合设计模式的方法,从而简化 Java 代码。 Lombok 基于字节码增强技术,在编译期处理。Lombok 可以配合开发工具(IntelliJ IDEA, Eclipse 等)使用。
Guava: Google 出品的 Java 常用功能库,被广泛使用,部分特性被引进 JDK。
Hutool: 国产 Java 常用功能库,很实用,有名气。
5 MySQL 数据库和 SQL
5.1 为什么要优化 MySQL 性能
对于数据密集型系统,数据库性能是系统性能的瓶颈,为提升系统性能,应重点考虑提升数据库性能。
5.2 MySQL 服务器配置优化
优化 MySQL 服务器配置,即 my.cnf/my.ini 文件中的参数,可以提升 MySQL 性能。
主要可优化参数如下:
1)连接请求的变量
1、max_connections
2、back_log
3、wait_timeout和interative_timeout
2)缓冲区变量
4、key_buffer_size
5、query_cache_size(查询缓存简称 QC)
6、max_connect_errors
7、sort_buffer_size
8、max_allowed_packet=32M
9、join_buffer_size=2M
10、thread_cache_size=300
3)配置 Innodb 的几个变量
11、innodb_buffer_pool_size=128M
12、innodb_flush_log_at_trx_commit
13、innodb_thread_concurrency=0
14、innodb_log_buffer_size
15、innodb_log_file_size=50M
16、innodb_log_files_in_group=3
17、read_buffer_size=1M
18、read_rnd_buffer_size=16M
19、bulk_insert_buffer_size=64M
20、binary log
5.3 数据库设计优化
如何恰当选择引擎?
- 库表如何命名?
- 如何合理拆分宽表?
- 如何选择恰当数据类型:明确、尽量小
- char、varchar 的选择
- (text/blob/clob)的使用问题?
- 文件、图片是否要存入到数据库?
- 时间日期的存储问题?
- 数值的精度问题?
- 是否使用外键、触发器?
- 创建恰当索引:索引字段、字段顺序、索引类型(Hash, B+树)唯一约束和索引的关系?
- 是否可以冗余字段?
- 是否使用游标、变量、视图、自定义函数、存储过程?
- 自增主键的使用问题?
- 能够在线修改表结构(DDL 操作)?
- 逻辑删除还是物理删除?
- 要不要加 create_time,update_time 时间戳?
- 数据库碎片问题?
- 如何快速导入导出、备份数据?5.4 应用侧 SQL 使用优化
大批量写入的优化:
PreparedStatement 减少 SQL 解析
Multiple Values/Add Batch 减少交互
Load Data,直接导入
数据更新优化:
数据的范围更新
注意 GAP Lock 的问题
导致锁范围扩大
模糊查询优化:
Like 的问题
前缀匹配
否则不走索引
全文检索
solr/ES
连接查询优化:
驱动表的选择问题
避免笛卡尔积
索引失效的情况汇总:
隐式数据类型、字符编码转换
NULL,not,not in,函数等
减少使用 or,可以用 union(注意 union all 的区别),以及前面提到的 like
大数据量下,放弃所有条件组合都走索引的幻想,改用“全文检索”
必要时可以使用 force index 来强制查询走某个索引
SQL 使用指南:
查询数据量和查询次数的平衡
避免不必须的大量重复数据传输
避免使用临时文件排序或临时表
分析类需求,可以用汇总表
5.5 诊断 MySQL 性能问题的方法
6 MySQL 复制、读写分离、分库分表
6.1 单机 MySQL 的问题和解决方案
单机 MySQL 的问题:
- 容量不足:单机的存储空间不能满足系统的需求。
- 并发能力不足:单机的CPU,内存,网络带宽等资源不足以支撑系统需要的并发读写量。
- 可用性低:一旦部署 MySQL 的机器宕机,整个数据库系统就不可用了,进而导致系统不可用。
以下解决方案可解决以上问题:
| 解决方案名称 | 解决的问题 | 解决方案描述 |
|---|---|---|
| 复制 | 可用性低 | 思想:把一个数据库重复部署在多个 MySQL 实例上,只要至少 1 个 MySQL 实例正常运行,数据库系统就可用。 原理:MySQL binlog 记录了数据库修改操作,从节点获取主节点的 binlog,并在本节点上执行,使得从节点的数据与主节点一致。 |
| 读写分离 | 并发能力不足 | 读写分离基于复制,让主节点处理写请求,多个从节点分摊读请求。对于读请求远多于写请求(例如 10:1)的场景,可以大大降低每个节点的读请求压力。 |
| 数据库垂直拆分 | 容量不足,并发能力不足 | 1 将不同业务的数据拆分到不同的数据库,并部署在不同的 MySQL 实例上。 2 将有很多字段的表拆分到不同的表。 3 将大字段拆分到单独的表。 |
| 数据库水平拆分 | 容量不足,并发能力不足 | 对于记录很多的表,创建多个结构一样的表,这些表分别容纳部分记录,这些表可以放在同一个数据库,也可放在不同数据库(位于不同 MySQL 实例) |
6.2 分布式事务
数据库拆分以后,存在事务跨多个 MySQL 实例的问题,这种事务称为分布式事务。
有 2 种分布式事务解决方案:
- 强一致性事务:如 MySQL 自带的基于 XA 分布式事务协议的 XA 事务。
- BASE 柔性事务:BASE 柔性事务具有基本可用(Basically Available),柔性状态(Soft state)和最终一致性(Eventually consistent)3 个特性。
BASE 柔性事务有以下模式:
- TCC: TCC 模式即将每个服务业务操作分为两个阶段,第一个阶段检查并预留相关资源,第二阶段根据所有服务业务的 Try 状态来操作,如果都成功,则进行 Confirm 操作,如果任意一个 Try 发生错误,则全部 Cancel
- SAGA: 与 TCC 相比,Saga 模式没有 try 阶段,直接提交事务。复杂情况下,对回滚操作的设计要求较高
- AT: AT 模式就是两阶段提交,自动生成反向 SQL
分布式事务产品:
- Seata: Seata 是阿里集团和蚂蚁金服联合打造的分布式事务框架,支持 TCC 和 AT 2 种 BASE 柔性事务模式。
- Hmily: Hmily 是一个高性能分布式事务框架,支持 TCC 和 TAC 2 种 BASE 柔性事务模式。使用 Java 语言开发(JDK1.8+),天然支持 Dubbo、SpringCloud、Motan 等微服务框架的分布式事务。
- ShardingSphere; ShardingSphere 自身并没有实现分布式事务,而是通过整合其他分布式事务产品来提供分布式事务能力。整合现有的成熟事务方案,为本地事务、两阶段事务和柔性事务提供统一的分布式事务接口,并弥补当前方案的不足,提供一站式的分布式事务解决方案是 Apache ShardingSphere 分布式事务模块的主要设计目标。ShardingSphere 支持 XA 事务的常见几个开源实现,支持 Seata 柔性事务。
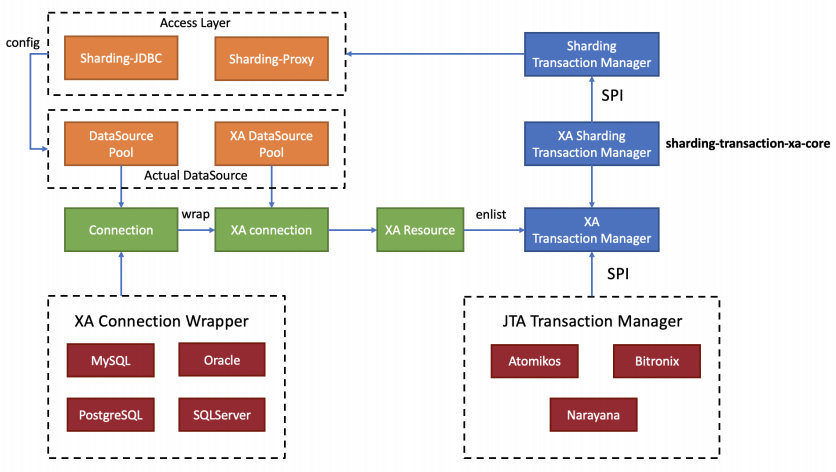
ShardingSphere 支持的 XA 事务产品(图片来源:极客时间,秦金卫,Java进阶训练营,Week8-02.pdf)
6.3 应用如何使用读写分离和分库分表
为了使用读写分离和分库分表技术,一方面要部署 MySQL 集群,另一方面应用侧也要接入这些技术。
ShardingSphere-JDBC 和 ShardingSphere-Proxy 以不同的方式为应用提供读写分离和分库分表技术:
- ShardingSphere-JDBC: ShardingSphere-JDBC 作为程序库,与应用运行在同一个进程中。
- ShardingSphere-Proxy: ShardingSphere-Proxy 作为 MySQL 服务器的代理,运行在单独的进程中,一般部署在与应用不同的机器上,应用连接 ShardingSphere-Proxy 而不是连接 MySQL 服务器。
7 RPC 和微服务
7.1 RPC
7.1.1 RPC 是什么
远程服务调用(一台机器上的程序调用另一台机器上的服务,这里服务泛指应用编程接口)是网络应用的常见情景。
HTTP + JSON 是远程服务调用的一种常见形式,服务端对客户端暴露 HTTP 接口,客户端向服务端发送 HTTP 请求(请求体是 JSON 文本),得到服务端的 HTTP 响应(响应体是 JSON 文本)后,将 响应体转换成领域对象,再用领域对象执行业务。客户端使用 HTTP + JSON 调用远程的根据用户ID获取用户信息服务演示:
OkHttpClient client = new OkHttpClient();String url = "http://localhost:8080/user/123";Request request = new Request.Builder().url(url).build();Response response = client.newCall(request).execute()String responseBody = response.body().string();User user = JSON.parseObject(responseBody, User.class)// ... 使用 user 执行业务
而 RPC(Remote Procedure Call) 则是远程服务调用的另一种形式。客户端使用 RPC 框架得到实现了服务接口的代理对象,然后调用该代理对象的方法,即实现了远程服务调用。客户端使用 RPC 调用远程的根据用户ID获取用户信息服务演示:
String remoteServerUrl = "http://localhost:8080/";// 使用 RPC 框架得到实现了服务接口的代理对象UserService userService = RpcFramework.create(UserService.class, remoteServerUrl);User user = userService.findById(123);// ... 使用 user 执行业务
7.1.2 为什么要使用 RPC
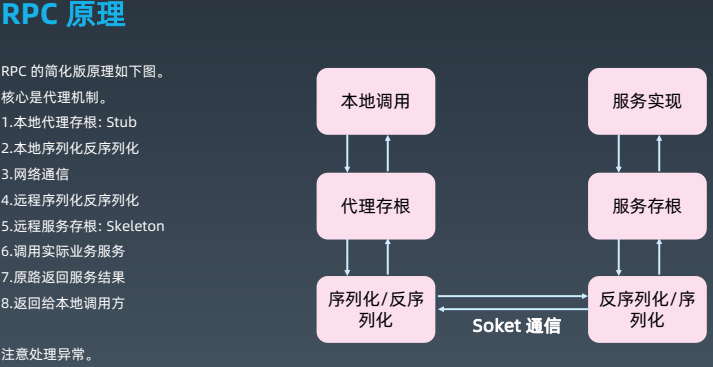
上图展示了 RPC 原理,RPC 原理涉及 5 个方面:设计,代理,序列化,网络传输 和 查找实现类。
- 设计:RPC 是基于接口的远程服务调用,要设计客户端和服务端需要共享的信息,比如与接口相关的所有数据类型的定义。
- 代理:RPC 是基于接口的远程服务调用。Java 下,代理可以选择动态代理,或者 AOP 实现。C# 直接有远程代理。
- 序列化:远程服务调用的请求和响应消息在网络间传输需要序列化、反序列化。序列化方案有:
- 语言原生的序列化,RMI,Remoting
- 二进制平台无关,Hessian,avro,kyro,fst 等
- 文本,JSON、XML 等
- 网络传输:RPC 请求和响应消息的传输方式。最常见的传输方式:
- TCP/SSL/TLS
- HTTP/HTTPS
查找实现类:服务端收到 RPC 请求后,需要找到服务的实现类的机制。一般是注册方式,例如 dubbo 默认将接口和实现类配置到 Spring。
7.2 微服务
7.2.1 微服务是什么
微服务是一种软件架构,核心思想是为了实现复杂系统,将整体系统拆分成恰当粒度的子系统,进行独立的开发、部署、运维,每个子系统实现的服务比较微小,所以叫微服务。可以从以下几个视图看待微服务架构:
用例视图:每个子系统负责部分业务。
- 开发视图:每个子系统有独立的源代码工程。
- 进程视图:子系统间通过 RPC 相互调用,整体系统的外界通过网关与子系统通讯。
- 物理视图:每个子系统运行在独立的机器、进程上。
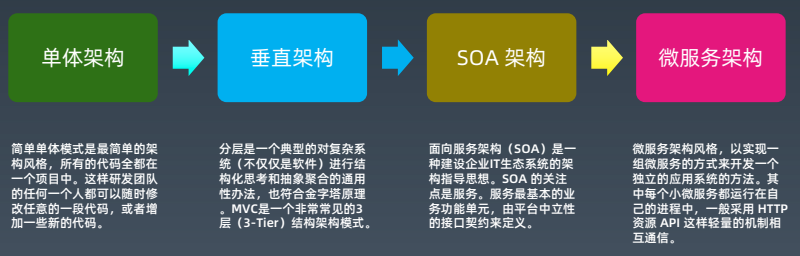
软件架构发展路径(图片来源:极客时间,秦金卫,Java进阶训练营,Week10-02.pdf)
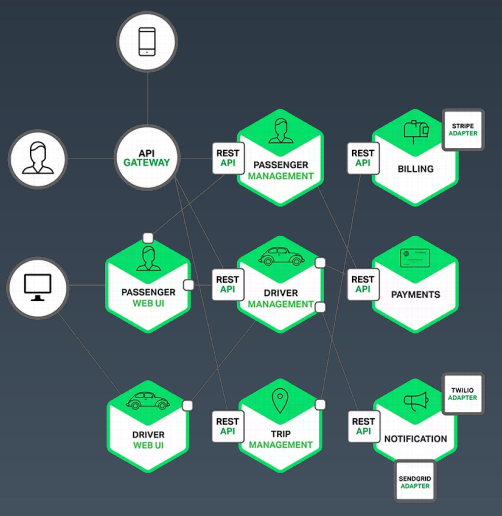
微服务架构示意图(图片来源:极客时间,秦金卫,Java进阶训练营,Week10-02.pdf)
7.2.2 微服务相关技术问题
1、多个相同服务如何管理? ==> 集群/分组/版本 => 分布式与集群
2、服务的注册发现机制? ==> 注册中心/注册/发现
3、如何负载均衡,路由等集群功能? ==> 路由/负载均衡
4、熔断,限流等治理能力。 ==> 过滤/流控
5、心跳,重试等策略。
6、高可用、监控、性能等等。
7.2.3 微服务相关产品
7.2.3.1 Dubbo
Apache Dubbo 是一款高性能、轻量级的开源 Java 服务框架。具有六大核心能力:面向接口代理的高性能 RPC 调用,智能负载均衡,服务自动注册和发现,高度可扩展能力,运行期流量调度,可视化的服务治理与运维。
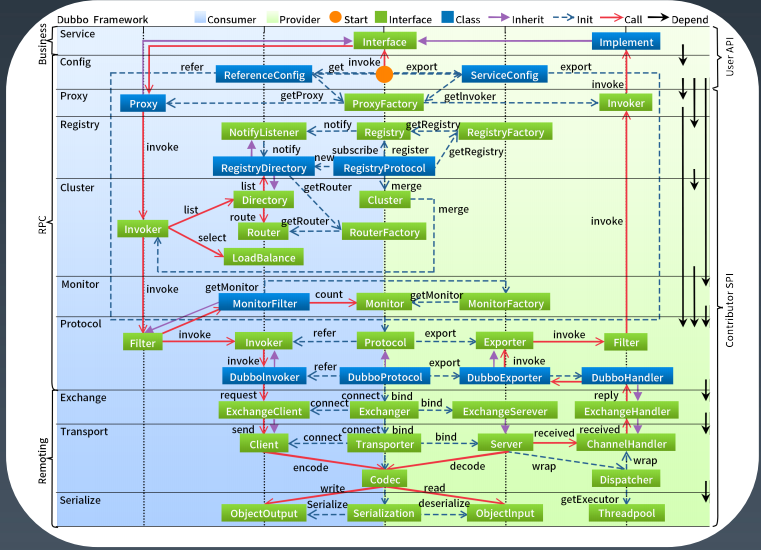
Dubbo 整体架构(图片来源:极客时间,秦金卫,Java进阶训练营,Week9-02.pdf)
- config 配置层:对外配置接口,以 ServiceConfig, ReferenceConfig 为中心,可以直接初始化配置类,也可以通过 spring 解析配置生成配置类
2. proxy 服务代理层:服务接口透明代理,生成服务的客户端 Stub 和服务器端 Skeleton, 以 ServiceProxy 为中心,扩展接口为 ProxyFactory
3.registry 注册中心层:封装服务地址的注册与发现,以服务 URL 为中心,扩展接口为 RegistryFactory, Registry, RegistryService
4. cluster 路由层:封装多个提供者的路由及负载均衡,并桥接注册中心,以 Invoker 为中心,扩展接口为Cluster,Directory,Router,LoadBalance
5. monitor 监控层:RPC 调用次数和和调用时间监控,以 Statistics 为中心,扩展接口为 MonitorFactory, Monitor, MonitorService
6. protocol 远程调用层:封装 RPC 调用,以 Invocation,Result 为中心,扩展接口为 Protocol,Invoker,Exporter
7. exchange 信息交换层:封装请求响应模式,同步转异步,以 Request,Response 为中心,扩展接口为Exchanger,ExchangeChannel,ExchangeClient,ExchangeServer
8. transport 网络传输层:抽象 mina 和 netty 为统一接口,以 Message 为中心,扩展接口为 Channel,Transporter,Client,Server,Codec
9. serialize 数据序列化层:可复用的一些工具,扩展接口为 Serialization,ObjectInput, ObjectOutput,ThreadPool7.2.3.2 Spring Cloud
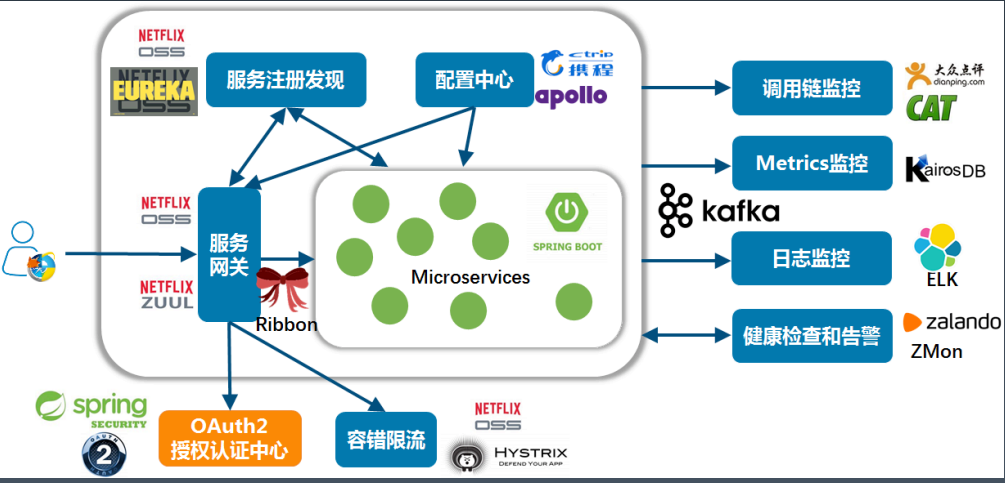
Spring Cloud 技术体系(图片来源:极客时间,秦金卫,Java进阶训练营,Week10-02.pdf)7.2.3.3 其他产品
APM(应用性能监控):
- Apache Skywalking
- Pinpoint
- Zipkin
- Jaeger
监控:
- ELK
- promethus+Grafana
- MQ+时序数据库(InfluxDB/openTSDB 等)
权限控制:权限控制核心问题有 Authentication, Authorization 和 Audit 3 个,针对这 3 个问题有以下产品:
缓存有多级,如进程内内存缓存,本地磁盘缓存,远程缓存。
远程缓存产品:Redis/Memcached 缓存中间件,Hazelcast/Ignite 内存网格。
缓存淘汰策略:FIFO/LRU, 按国定时间过期,按业务时间加权。
9 分布式消息队列
消息队列是一种系统间通信方式,具有以下优点:
- 异步通信:异步通信,减少线程等待,特别是处理批量等大事务、耗时操作。
- 系统解耦:系统不直接调用,降低依赖,特别是不在线也能保持通信最终完成。
- 削峰平谷:压力大的时候,缓冲部分请求消息,类似于背压处理。
- 可靠通信:提供多种消息模式、服务质量、顺序保障等
常见的 2 种消息处理模式:
- 点对点:PTP,Point-To-Point对应于Queue
- 发布订阅:PubSub,Publish-Subscribe,对应于 Topic
开源消息中间件/消息队列:
一代:ActiveMQ/RabbitMQ
二代:Kafka/RocketMQ(目前的主流产品)
三代:Apache Pulsar

若有收获,就点个赞吧
0 人点赞
