关系型/非关系型(重点)
关系型数据库:
指采用了关系模型来组织数据的数据库,关系模型指的是二维表格模型,而一个关系型数据库就是有二维表及其之间的联系所组成的一个数据组织。关系严谨的数据库的存储
oracle,mysql,SQL server,sqlite
非关系数据库:
非关系数据库以键值对存储,且结构不固定,每一个元祖可以有不一样的字段,
- 面向高性能并发读写的
key-value数据库- 具有极高的并发读写性能
redis,memcached
- 面向 海量数据访问的面向文档数据库
- 海量数据中快速查询数据
MongoDB
mysql索引
索引是一个单独的、存储在磁盘上的数据库结构,它们包含着对数据表里所有记录的引用指针。使用索引用于快速找出在某个或多个列中有一特定值的行,所有MySQL列类型都可以被索引,对相关列使用索引是提高查询操作速度的最佳途径。
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。比如我们在查字典的时候,前面都有检索的拼音和偏旁、笔画等,然后找到对应字典页码,这样然后就打开字典的页数就可以知道我们要搜索的某一个key的全部值的信息了。
创建索引时,你需要确保该索引是应用在 SQL 查询语句的条件(一般作为 WHERE 子句的条件),而不是在select的字段中,实际上,索引也是一张“表”,该表保存了主键与索引字段,并指向实体表的记录,虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件,建立索引会占用磁盘空间的索引文件。说白了索引就是用来提高速度的,但是就需要维护索引造成资源的浪费,所以合理的创建索引是必要的。
事务的概念及其4个特性
事务是一个操作序列,这些操作要么都做,要么都不做
4个特性:
- 原子性
- 一致性
- 隔离性
- 持久性
关系模型
关系数据库就是建立在关系模型上的
- 关系模型=若干个二维表
- 二维表=记录+字段
常用数据类型如下:
- 整数 int
- 小数:decimal
- 字符串:varchar, char
- 日期:date, time , datatime
- 枚举类型:enum
数据库操作(基本)
- 显示所有数据库:
show databases - 显示时间:
show now() - 创建数据库:
create database 数据库名 charset=utf8 - 查看创建数据库语句:
show create database 数据库名 - 删除数据库:
drop database 数据库名- 如果数据库名中有
-等特殊符号,那么删除是要数据库名
- 如果数据库名中有
- 查看当前使用数据库:
select database()
数据表操作
- 显示当前数据库所有表:
show tables - 创建一个数据表:
CREATE TABLE stu_name(id int,name VARCHAR(30)) - 显示一个数据表的信息:
desc 数据表名 创建一个表ID为自动增长不为空
CREATE TABLE xxx (id INT PRIMARY KEY NOT NULL auto_increment,name VARCHAR(30))
创建
students表(id,name,age,high,gender,cls_id)CREATE TABLE students (id INT UNSIGNED NOT NULL auto_increment PRIMARY KEY,NAME VARCHAR ( 30 ),age TINYINT UNSIGNED DEFAULT 0,high DECIMAL ( 5, 2 ),gender enum ( "男", "女" ),cls_id INT UNSIGNED)
表-添加字段
alter table 表名 add 列名 类型 约束;例:alter table students add birthday datetime;
表-修改字段类型
alter table 表名 modify 列名 类型 约束;例:alter table students modify birthday date not null;
表-修改字段名和字段类型
alter table 表名 change 原名 新名 类型及约束;例:alter table students change birthday birth datetime not null;
数据的一些查询操作
查询表中所有列
select * from 表名
distinct去除重复数据-- 看到了很多重复数据 想要对其中重复数据行进行去重操作可以使用 distinctselect distinct name, gender from students;
未使用:
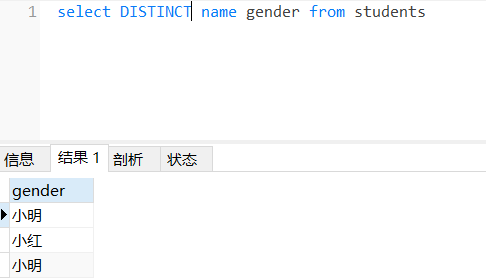
使用后: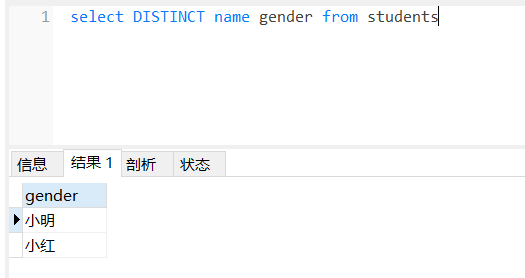
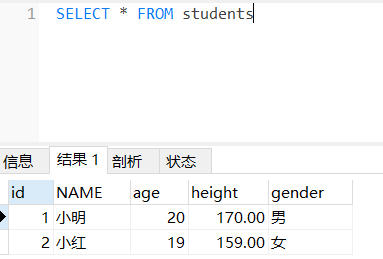
where条件查询
where条件查询语法格式如下:
select * from 表名 where 条件;例:select * from students where id = 1;
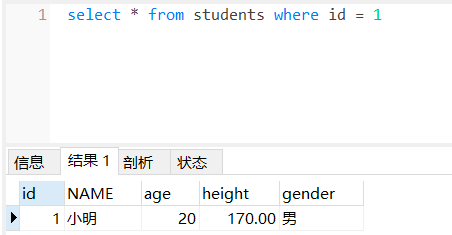
逻辑运算符查询
查询编号大于3的女同学
select * from students where id > 3 and gender=0;
查询编号小于4或没被删除的学生
select * from students where id < 4 or is_delete=0;
查询年龄不在10岁到15岁之间的学生
select * from students where not (age >= 10 and age <= 15);
说明:
查询姓黄的学生
select * from students where name like '黄%';
查询姓黄并且“名”是一个字的学生
select * from students where name like '黄_';
查询姓黄或叫靖的学生
select * from students where name like '黄%' or name like '%靖';
范围查询
between .. and ..表示在一个连续的范围内查询in表示在一个非连续的范围内查询
查询编号为3至8的学生
select * from students where id between 3 and 8;
查询编号不是3至8的男生
select * from students where (not id between 3 and 8) and gender='男';
空判断查询
- 判断为空使用:
is null - 判断非空使用:
is not null
- 查询没有填写身高的学生:
select * from students where height is null;
排序
select * from 表名 order by 列1 asc|desc [,列2 asc|desc,...]
- 先按照列1进行排序,如果列1的值相同时,则按照 列2 排序,以此类推
asc从小到大排列,即升序desc从大到小排序,即降序- 默认按照列值从小到大排列(即
asc关键字)
查询未删除男生信息,按学号降序
select * from students where gender=1 and is_delete=0 order by id desc;
显示所有的学生信息,先按照年龄从大—>小排序,当年龄相同时 按照身高从高—>矮排序
select * from students order by age desc,height desc;
分页查询
使用
limit关键字select * from 表名 limit start,count
limit是分页查询关键字start表示开始行索引,默认是0count表示查询条数
- 查询前3行男生信息
select * from students where gender=1 limit 0,3;简写select * from students where gender=1 limit 3;
聚合函数
聚合函数又叫组函数,通常是对表中的数据进行统计和计算,一般结合分组(group by)来使用,用于统计和计算分组数据。
常用的聚合函数:
count(col): 表示求指定列的总行数max(col): 表示求指定列的最大值min(col): 表示求指定列的最小值sum(col): 表示求指定列的和-
求总行数
-- 返回非NULL数据的总行数.select count(height) from students;-- 返回总行数,包含null值记录;select count(*) from students;
求最大值
-- 查询女生的编号最大值select max(id) from students where gender = 2;
求最小值
-- 查询未删除的学生最小编号select min(id) from students where is_delete = 0;
求和
-- 查询男生的总身高select sum(height) from students where gender = 1;-- 平均身高select sum(height) / count(*) from students where gender = 1;
求平均值
-- 求男生的平均身高, 聚合函数不统计null值,平均身高有误select avg(height) from students where gender = 1;-- 求男生的平均身高, 包含身高是null的select avg(ifnull(height,0)) from students where gender = 1;
说明
ifnull函数: 表示判断指定字段的值是否为null,如果为空使用自己提供的值。
聚合函数的特点
- 聚合函数默认忽略字段为null的记录 要想列值为null的记录也参与计算,必须使用ifnull函数对null值做替换。
分组查询
分组查询就是将查询结果按照指定字段进行分组,字段中数据相等的分为一组。
group by 列名 [having 条件表达式] [with rollup]
- 列名: 是指按照指定字段的值进行分组。
- HAVING 条件表达式: 用来过滤分组后的数据。
- WITH ROLLUP:在所有记录的最后加上一条记录,显示select查询时聚合函数的统计和计算结果
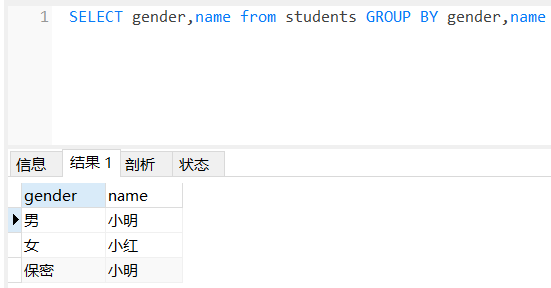
group bygroup by可用于单个字段分组,也可用于多个字段分组-- 根据gender字段来分组select gender from students group by gender;-- 根据name和gender字段进行分组select name, gender from students group by name, gender;
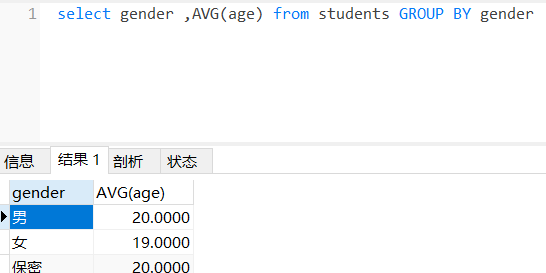
group by+聚合函数-- 统计不同性别的人的平均年龄select gender,avg(age) from students group by gender;-- 统计不同性别的人的个数select gender,count(*) from students group by gender;
连接查询-内连接(重点)
连接查询可以实现多个表的查询,当查询的字段数据来自不同的表就可以使用连接查询来完成。
连接查询可以分为:
- 内连接查询
- 左连接查询
- 右连接查询
- 自连接查询
内连接查询效果图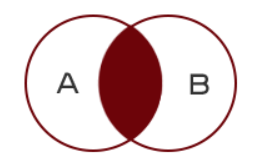
内连接查询语法格式
select 字段 from 表1 inner join 表2 on 表1.字段1 = 表2.字段2
inner join就是内连接查询关键字on就是连接查询条件
- 使用内连接查询学生表与班级表
select * from students as s inner join classes as c on s.cls_id = c.id;
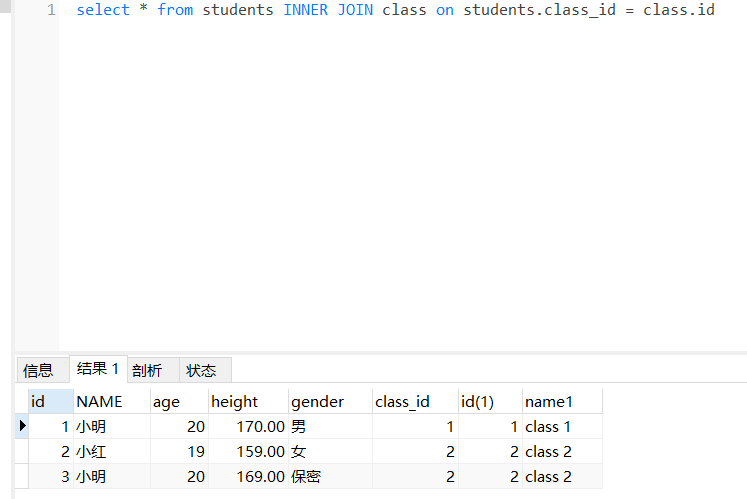
内连接根据连接查询条件取出两个表的 “交集”
连接查询-左连接(重点)
以左表为主根据条件查询右表数据,如果根据条件查询右表数据不存在使用null值填充
左连接查询效果图
左连接查询语法格式
select 字段 from 表1 left join 表2 on 表1.字段1 = 表2.字段2
说明:
left join就是左连接查询关键字on就是连接查询条件- 表1 是左表
- 表2 是右表
- 使用左连接查询学生表与班级表
select * from students as s left join classes as c on s.cls_id = c.id;
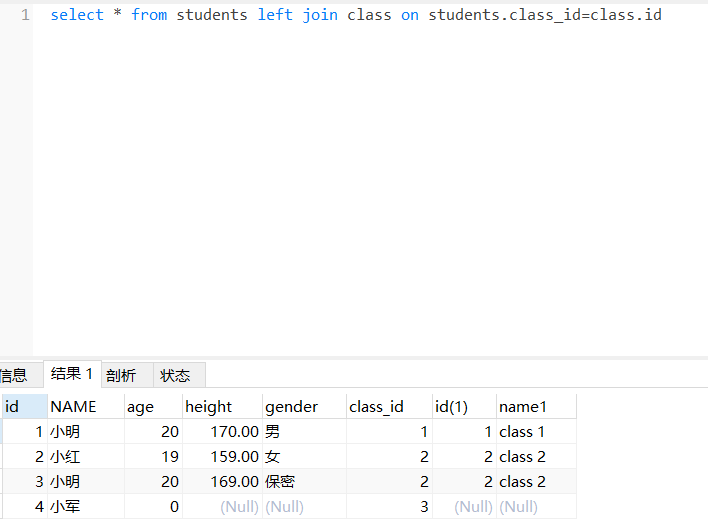
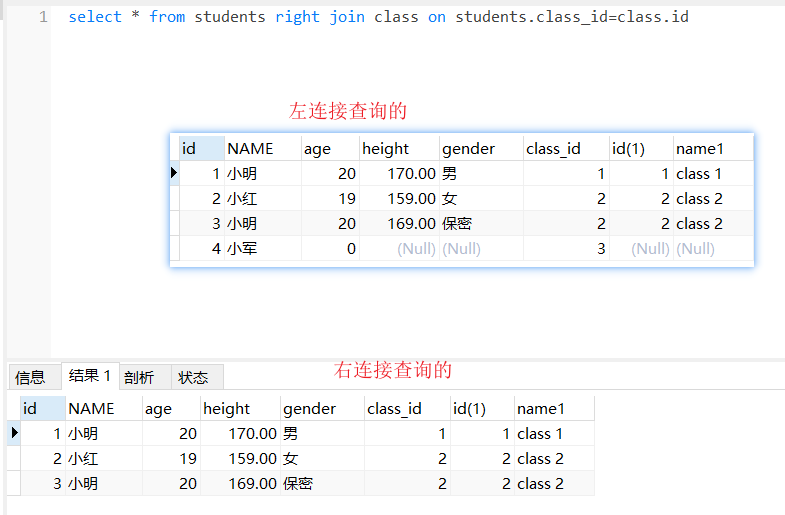
左连接以左表为主根据条件查询右表数据,右表数据不存在使用null值填充。连接查询-右连接(重点)
以右表为主根据条件查询左表数据,如果根据条件查询左表数据不存在使用null值填充
右连接查询效果图
右连接查询语法格式
select 字段 from 表1 right join 表2 on 表1.字段1 = 表2.字段2
right join就是右连接查询关键字on就是连接查询条件- 表1 是左表
- 表2 是右表
- 使用右连接查询学生表与班级表
select * from students as s right join classes as c on s.cls_id = c.id;

若有收获,就点个赞吧
0 人点赞
