CRF的地位
1、神经网络之前hmm和crf在自然语言处理领域取得不错的成绩;
2、序列到序列的常见方案bert+biLstm+crf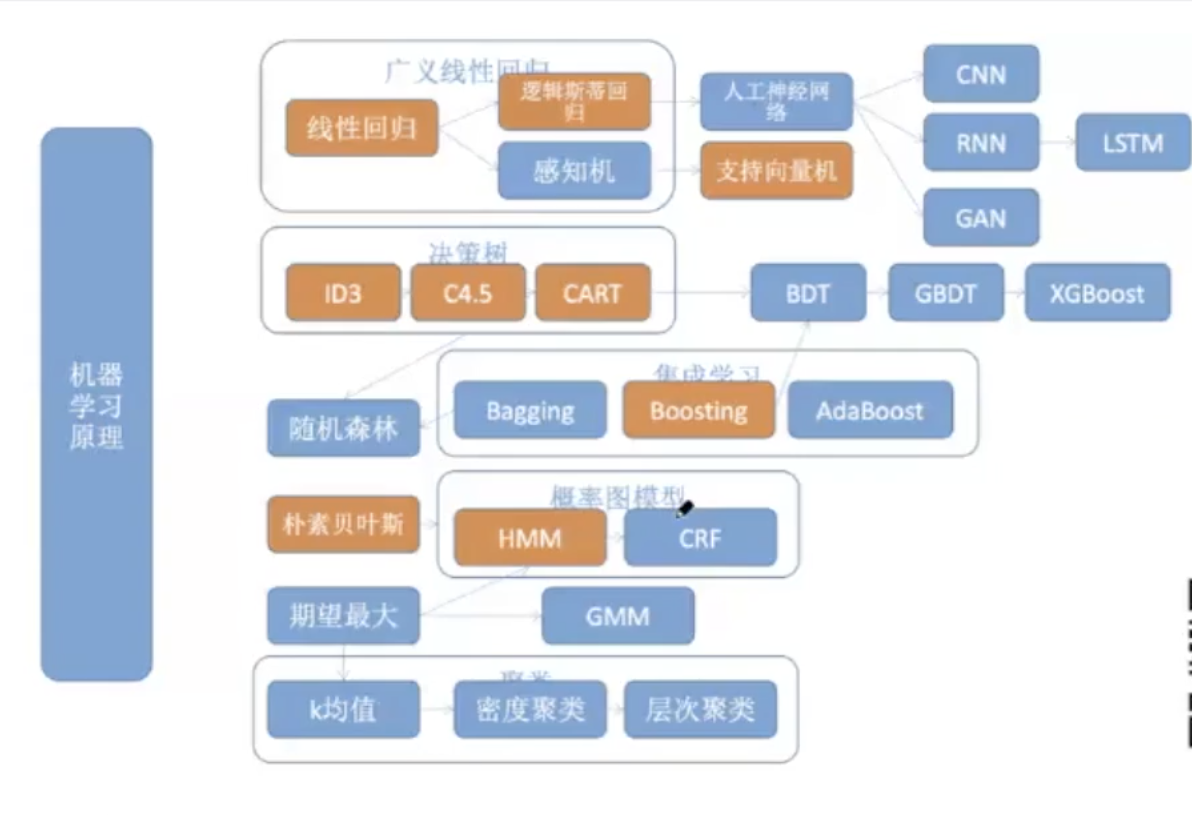
数学公式+图示+代码
1 条件随机场的定义
1.1 马尔可夫随机场
- 图是由结点及连接结点的边组成的集合。
- 结点记作𝑣,结点集合记作𝑉 ;边记作𝑒,边的集合记作𝐸;图记作𝐺 = (𝑉 , 𝐸)。
- 概率图模型是由图表示的概率分布。
- 设由联合分布
 是⼀组随机变量。 由⽆向图
是⼀组随机变量。 由⽆向图 表示概率分布
表示概率分布  ,即在图
,即在图 中,
中, 结点表示⼀个随机变量
结点表示⼀个随机变量  ;
; 边表示随机变量之间的概率依赖关系。
边表示随机变量之间的概率依赖关系。
成对马尔可夫性

其中,设 和
和 是⽆向图中任意两个没有边连接的结点,分别对应随机变量
是⽆向图中任意两个没有边连接的结点,分别对应随机变量 ;其它所有结点为
;其它所有结点为 ,对应的随机变量组是
,对应的随机变量组是 。 即,给定随机变量组的条件下随机变量
。 即,给定随机变量组的条件下随机变量 和
和 是条件独⽴的。
是条件独⽴的。
局部⻢尔可夫性

其中,设 是⽆向图中任意⼀个结点,对应的随机变量是。
是⽆向图中任意⼀个结点,对应的随机变量是。 是与有边连接的所有的结点,对应的随机变量组是
是与有边连接的所有的结点,对应的随机变量组是 。是以外的其它所有结点,对应的随机变量组是。即给定随机变量组的条件下随机变量和是条件独⽴的。
。是以外的其它所有结点,对应的随机变量组是。即给定随机变量组的条件下随机变量和是条件独⽴的。
上两式可得:
全局⻢尔可夫性

其中,设结点集合 是在⽆向图中被结点集合
是在⽆向图中被结点集合 分开的任意结点集合,对应的随机变量组是
分开的任意结点集合,对应的随机变量组是 。 即给定随机变量组
。 即给定随机变量组 的条件下随机变量
的条件下随机变量 和
和 是条件独⽴的。
是条件独⽴的。
概率⽆向图模型(⻢尔可夫随机场):设有联合概率分布,由⽆向图 表示,在图中,结点表示随机变量,边表示随机变量之间的依赖关系。如果联合概率分布满⾜成对、局部或全局⻢尔可夫性,就称联合概率分布为概率⽆向图模型,或⻢尔可夫随机场。
表示,在图中,结点表示随机变量,边表示随机变量之间的依赖关系。如果联合概率分布满⾜成对、局部或全局⻢尔可夫性,就称联合概率分布为概率⽆向图模型,或⻢尔可夫随机场。
1.2 马尔可夫随机场的因子分解
团:⽆向图中任意两个结点均有边连接的结点⼦集。
最⼤团:⽆向图中的⼀个团,并且不能再加进任何⼀个结点使其成为⼀个更⼤的团。
概率⽆向图模型的联合概率分布 
其中,是⽆向图的最⼤团, 是的结点对应的随机变量;
势函数 是严格正的
是严格正的 ;
;
 是规范化因子,保证构成一个概率分布
是规范化因子,保证构成一个概率分布  乘积是在⽆向图所有的最⼤团上进⾏的。
乘积是在⽆向图所有的最⼤团上进⾏的。
1.3 条件随机场及线性链条件随机场
条件随机场
设 与
与 是随机变量,
是随机变量, 是在给定的条件下的条件概率分布,若随机变量构成⼀个由⽆向图
是在给定的条件下的条件概率分布,若随机变量构成⼀个由⽆向图 表示的⻢尔可夫随机场,即
表示的⻢尔可夫随机场,即 
对任意结点成⽴,则称条件概率分布为条件随机场。其中, 表示在图中与结点有边连接的所有结点
表示在图中与结点有边连接的所有结点 ,
,  表示结点以外的所有结点,
表示结点以外的所有结点, 与
与 为结点与对应的随机变量。
为结点与对应的随机变量。
线性链条件随机场
设 均为线性链表示的随机变量序列,若在给定随机变量序列的条件下,随机变量序列的条件概率分布构成条件随机场,即满⾜⻢尔可夫性
均为线性链表示的随机变量序列,若在给定随机变量序列的条件下,随机变量序列的条件概率分布构成条件随机场,即满⾜⻢尔可夫性
称条件概率分布为线性链条件随机场。
2 条件随机场的表示形式
2.1 线性链条件随机场的参数形式
设为线性链条件随机场,则在随机变量取值为 的条件下,随机变量Y取值为
的条件下,随机变量Y取值为 的条件概率
的条件概率
其中,
 是定义在边上特征函数,称为转移特征,依赖于当前和前⼀个位置;
是定义在边上特征函数,称为转移特征,依赖于当前和前⼀个位置; 是定义在结点上的特征函数,称为状态特征,依赖于当前位置。特征函数和取值为1或0。
是定义在结点上的特征函数,称为状态特征,依赖于当前位置。特征函数和取值为1或0。 和
和 是对应的权值,
是对应的权值, 是规范化因⼦,求和是在所有可能的输出序列上进⾏的。
是规范化因⼦,求和是在所有可能的输出序列上进⾏的。
2.2 线性链条件随机场的简化形式
2.3 条件随机场的矩阵形式
条件概率模型
条件随机场的应用
POS tagging
分类问题可以分为硬分类和软分类两种,其中硬分类有 SVM,PLA,LDA 等。软分类问题大体上可以分为概率生成和概率判别模型,其中较为有名的概率判别模型有 Logistic 回归,生成模型有朴素贝叶斯模型。Logistic 回归模型的损失函数为交叉熵,这类模型也叫对数线性模型,一般地,又叫做最大熵模型,这类模型和指数族分布的概率假设是一致的。对朴素贝叶斯假设,如果将其中的单元素的条件独立性做推广到一系列的隐变量,那么,由此得到的模型又被称为动态模型,比较有代表性的如 HMM,从概率意义上,HMM也可以看成是 GMM 在时序上面的推广。
一般地,如果将最大熵模型和 HMM相结合,那么这种模型叫做最大熵 Markov 模型(MEMM):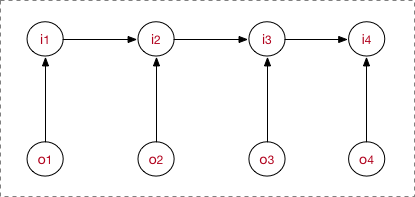
这个图就是将 HMM 的图中观测变量和隐变量的边方向反向,应用在分类中,隐变量就是输出的分类。MEMM打破了HMM 中的观测独立假设。
HMM建模:
MEMM建模:
MEMM缺点:会造成局域的概率归一化(label bias problem)
对于这个问题,我们将 之间的箭头转为直线转为无向图(破坏齐次 Markov 假设),即为线性链条件随机场,这样就只要满足全局归一了。
CRF损失函数
以BiLSTM+CRF实体识别模型为例
- CRF层可以学习到句子的约束条件
CRF层可以加入一些约束来保证最终预测结果是有效的。这些约束可以在训练数据时被CRF层自动学习得到。
可能的约束条件有:
- 句子的开头应该是“B-”或“O”,而不是“I-”。
- “B-label1 I-label2 I-label3…”,在该模式中,类别1,2,3应该是同一种实体类别。比如,“B-Person I-Person” 是正确的,而“B-Person I-Organization”则是错误的。
- “O I-label”是错误的,命名实体的开头应该是“B-”而不是“I-”。
有了这些有用的约束,错误的预测序列将会大大减少。
发射分数Emission score
LSTM的输出形状是 [T, k]维度的。其中T代表序列长度(字个数), k代表实体标签的个数!因此LSTM的输出可以理解为序列中的每一个词取每个标签的概率!(发射矩阵!)
CRF损失函数由两部分组成,真实路径的分数 和 所有路径的总分数。真实路径的分数应该是所有路径中分数最高的。
每种可能的路径的分数为Pi,共有N条路径,则路径的总分是:
如果第十条路径是真实路径,也就是说第十条是正确预测结果,那么第十条路径的分数应该是所有可能路径里得分最高的。
根据如下损失函数,在训练过程中,BiLSTM-CRF模型的参数值将随着训练过程的迭代不断更新,使得真实路径所占的比值越来越大。
对数损失:
最小化负对数损失:
比较下EM算法、HMM、CRF
这三个放在一起不是很恰当,但是有互相有关联,所以就放在这里一起说了。注意重点关注算法的思想。
(1)EM算法
EM算法是用于含有隐变量模型的极大似然估计或者极大后验估计,有两步组成:E步,求期望(expectation);M步,求极大(maxmization)。本质上EM算法还是一个迭代算法,通过不断用上一代参数对隐变量的估计来对当前变量进行计算,直到收敛。
注意:EM算法是对初值敏感的,而且EM是不断求解下界的极大化逼近求解对数似然函数的极大化的算法,也就是说EM算法不能保证找到全局最优值。对于EM的导出方法也应该掌握。
(2)HMM算法
隐马尔可夫模型是用于标注问题的生成模型。有几个参数(π,A,B):初始状态概率向量π,状态转移矩阵A,观测概率矩阵B。称为隐马尔可夫模型的三要素。
隐马尔可夫夫三个基本问题:
概率计算问题:给定模型和观测序列,计算模型下观测序列输出的概率。–>前向后向算法
学习问题:已知观测序列,估计模型参数,即用极大似然估计来估计参数。–>Baum-Welch(也就是EM算法)和极大似然估计。
预测问题:已知模型和观测序列,求解对应的状态序列。–>近似算法(贪心算法)和维特比算法(动态规划求最优路径)
(3)条件随机场CRF
给定一组输入随机变量的条件下另一组输出随机变量的条件概率分布密度。条件随机场假设输出变量构成马尔可夫随机场,而我们平时看到的大多是线性链条随机场,也就是由输入对输出进行预测的判别模型。求解方法为极大似然估计或正则化的极大似然估计。
之所以总把HMM和CRF进行比较,主要是因为CRF和HMM都利用了图的知识,但是CRF利用的是马尔可夫随机场(无向图),而HMM的基础是贝叶斯网络(有向图)。而且CRF也有:概率计算问题、学习问题和预测问题。大致计算方法和HMM类似,只不过不需要EM算法进行学习问题。
(4)HMM和CRF对比
其根本还是在于基本的理念不同,一个是生成模型,一个是判别模型,这也就导致了求解方式的不同。
逐帧softmax
CRF主要用于序列标注问题,可以简单理解为是给序列中的每一帧都进行分类,既然是分类,很自然想到将这个序列用CNN或者RNN进行编码后,接一个全连接层用softmax激活。然而,当我们设计标签时,比如用s、b、m、e的4个标签来做字标注法的分词,目标输出序列本身会带有一些上下文关联,比如s后面就不能接m和e,等等。逐标签softmax并没有考虑这种输出层面的上下文关联,所以它意味着把这些关联放到了编码层面,希望模型能自己学到这些内容,但有时候会“强模型所难”。CRF和编码层是两个不同的层。
CRF层学习的是标签之间的关联信息,也可以叫做约束信息,因为B-Peson后面不可能接I-Organization
在CRF层的损失函数有两个不同的分数,这两个分数是CRF层关键性的思想
参考
概率图模型体系:HMM、MEMM、CRF https://zhuanlan.zhihu.com/p/33397147
最通俗易懂的BiLSTM-CRF模型中的CRF层介绍 https://zhuanlan.zhihu.com/p/44042528 *
CRF 详细推导、验证实例 https://www.cnblogs.com/callyblog/p/11284370.html

若有收获,就点个赞吧
0 人点赞
