DNS就是域名解析,把域名转换成IP的这样的一个服务,它的核心系统是一个三层的树状,分布式服务,包括根域名服务器,顶级域名服务器,权威域名服务器。然后从根域名服务器开始进行一个递归的查询
大公司,网络运营商也有自己的DNS服务器,这些DNS服务器叫做非权威域名服务器(比如google的8.8.8.8 电脑上可以设置 ),用来做为一个代理,将用户访问的域名和ip映射做为缓存。还有linux中的/etc/hosts中也有DNS的缓存,浏览器也有
浏览器缓存->操作系统dnscache (dns进程)->hosts文件->非权威域名服务器->根域名服务器->顶级域名服务器->二级域名服务器->权威域名服务器。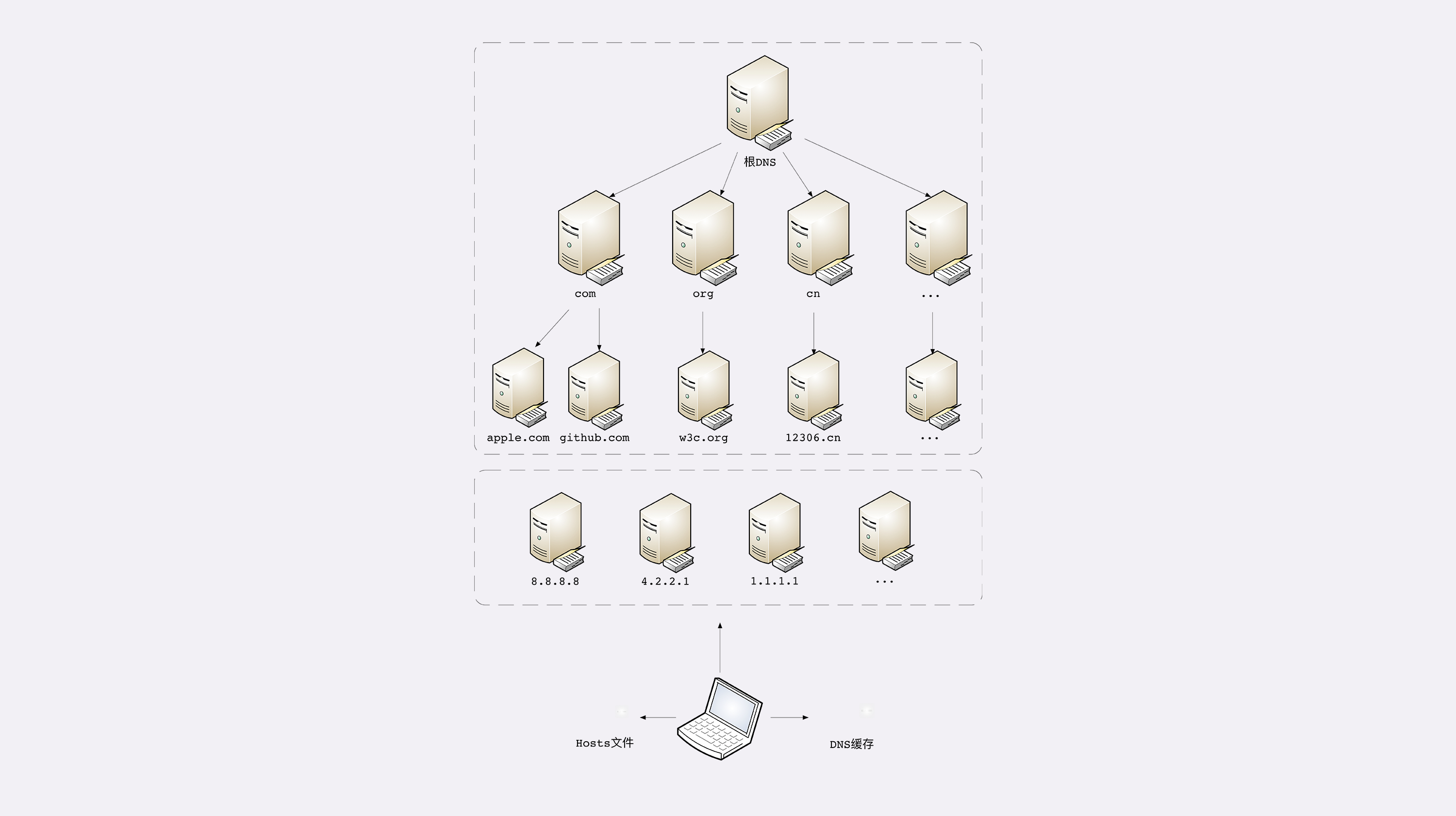
DNS可以让一个域名对应多个IP地址来实现负载均衡
“域名屏蔽”,对域名直接不解析,返回错误,让你无法拿到 IP 地址,也就无法访问网站;
“域名劫持”,也叫“域名污染”,你要访问 A 网站,但 DNS 给了你 B 网站。
1、如果域名不是ip,需要走域名解析成ip的逻辑,优先级顺序为: 1 浏览器缓存 > 2 本地hosts > 3 系统缓存 > 4 根域名 > 5 顶级dns服务器(如 com) > 6 二级dns服务器(baidu.com) > 7 三级dns服务器(www.baidu.com),如果客户端指向的dns服务器为非官方的如 8.8.8.8,那在第4步之前可能还有一层cache,当然最后解析的ip有可能是cdn的,如果cdn失效了就直接穿透到源ip,当然这个服务器这一部分可能做了四层负载均衡的设置,所以有可能每次获取的服务器ip都不一祥,也有可能到了服务器ngx层做了七层转发,所以虽然获得的ip一样,但是内部可能转发给了很多内网服务器
2、通过中间各种路由器的转发,找到了最终服务器,进行tcp三次握手,数据请求,请求分两种一种是uri请求,一种是浏览器咸吃萝卜淡操心的请求网站图标ico的资源请求,然后服务端收到请求后进行请求分析,最终返回http报文,再通过tcp这个连接隧道返回给用户端,用户端收到后再告诉服务端已经收到结果的信号(ack),然后客户端有一套解析规则,如果是html,可能还有额外的外部连接请求,是跟刚才的请求流程是同理的(假设是http1.1),只不过没有了tcp三次握手的过程,最终用户看到了百度的搜索页面。当然如果dns没解析成功,浏览器直接就报错了,不会继续请求接下来的资源

若有收获,就点个赞吧
0 人点赞
