DQL:Data QueryLanguage 数据查询语言标准语法
1 基础查询
group分组查询
- group by 会将null值也分为一组

- 一般来讲,能用分组前筛选的,尽量使用分组前筛选,提高效率,即使用where先过滤数据。
in查询
select from A where id in(select id from B)
该语句等价于:
for select id from B
for select from A where A.id=B.id;
总结:当B表的数据集小于A表的数据集,用in优于exists,小表驱动大表
exists查询
select from A where exists(select from B where B.id=A.id);
该语句等价于:
for select from A
for select from B where B.id=A.id;
总结:当A表的数据集小于B表时,用exists优于in
核心原则:小表驱动大表,被驱动表的字段应该建索引。order by排序查询
语法:select 查询列表 from 表名 【where 筛选条件】order by 排序的字段或表达式;
特点:
1、asc代表的是升序,可以省略,desc代表的是降序
2、order by子句可以支持 单个字段、别名、表达式、函数、多个字段
3、order by子句在查询语句的最后面,除了limit子句join联合查询
union:联合查询:将多条查询语句的结果合并成一个结果。
应用场景:要查询的结果来自于多个表,且多个表没有直接的连接关系,但查询的信息一致时。
特征:
- 要求多条查询语句的查询列数是一致的(MySQL和SQLServer要求是一样的)
- 要求多条查询语句的查询的每一列的类型和顺序最好一致
union关键字默认去重,如果使用union all 可以包含重复项(MySQL和SQLServer要求是一样的)
select 1 union all select 1;select 1 union select 1;
limit分页查询
语法:
select 查询列表
from 表 【join type join 表2
on 连接条件
where 筛选条件
group by 分组字段
having 分组后的筛选
order by 排序的字段】
limit 【offset】,【size】;
特点:offset要显示条目的起始索引(起始索引从0开始)
- size 要显示的条目个数
- limit语句放在查询语句的最后
- 公式:要显示的页数 page,每页的条目数size
2 嵌套子查询
| 分类标准 | 内容 | | —- | —- | | 按结果集的行列数不同 | 标量子查询(结果集只有一行一列)
列子查询(结果集只有一列多行)
行子查询(结果集有一行多列)
表子查询(结果集一般为多行多列) | | 按所在位置 | select后面:仅仅支持标量子查询
from后面:支持表子查询
where或having后面:均支持
exists后面(相关子查询):支持表子查询 |
where或having后面子查询
特点
- 子查询放在小括号内
- 子查询一般放在条件的右侧
- 标量子查询,一般搭配着单行操作符使用(如:> < >= <= = <>)
- 列子查询,一般搭配着多行操作符使用(in、any/some、all)
- 子查询的执行优先于主查询执行,主查询的条件用到了子查询的结果
后面可以加的数据
- 标量子查询(单行子查询)
正确例子:select from Log where LogId>(select LogId from Log where LogId=3);
错误例子:select from Log where LogId>(select LogId from Log where LogId>=3);
错误原因
- 列子查询(多行单列子查询)
使用in、any、all
select * from User where UserId in(1,2);select * from User where UserId >any(select UserId from User>1);//只要大于子查询里面的一项即可,约等同于select * from User where UserId>(select Min(UserId) from User);select * from User where UserId >all(select User from UserId>1);//要大于子查询里面的所有值,约等于:select * from User where UserId>(select Max(UserId) from User);
- 行子查询(多列多行)
语法:select * from User where (UserId,CityId)=(select Min(UserId),Min(CityId) from User);
from后面子查询
特点:将子查询结果充当一张表,要求必须起别名
select u. from Users u inner join (select from AreaSchool) as nt where u.AreaSchhol=nt.AreaSchool;
exists后面子查询(相关子查询)
语法:exists(完整的查询语句)
结果:1或0
可以直接使用select exists(select * from User)
该语句结果值为1(注:该语句在SQLServer下失败)
特点:
- exists也叫相关子查询
- 一般而言,能用exists都可以用in等
- exists(subquery)只返回true/false,因此子查询的select *也可以是select 1或select ‘X’,官方说法是实际执行会忽略select清单,因此没有区别
select后面子查询
语法(略鸡肋,建议用表连接代替)select u.*,(select school.AreaSchool from AreaSchool school where school.AreaSchool=u.AreaSchool) from User u;
特点
仅仅支持标量子查询
多行或多列均会报错:
select *,(select Id,Value from idname where idname.Id=idn.Id) from idname idn;
3 Join连接查询
划分
- 按年代
sql92标准(仅仅支持内连接)
sql99标准(支持内连接+外连接(左外和右外,mysql不支持全外fulljoin连接)+交叉连接)
- 按功能分类
内连接、等值连接、非等值连接、自连接、外连接、左外连接、右外连接、全外连接、交叉连接
内连接(inner join)
等值连接:select from sys_user inner join sys_menu on sys_user.user_id=sys_menu.create_by
非等值连接(相对于等值即其on连接不是相等的):select from sys_user inner join sys_menu on sys_user.user_id!=sys_menu.create_by
自连接:select * from sys_user s1 inner join sys_user s2 on s1.user_id=s2.user_id
等值连接:多表等值连接的结果为多表的交集部分。SELECT NAME,boyName FROM boys,beauty WHERE beauty.boyfriend_id= boys.id;自连接:SELECT e.employee_id,e.last_name,m.employee_id,m.last_name FROM employees e,employees m WHERE e. manager_id=m. employee_id;
外连接(left/right/full out join)
特点:
- 如果从表中有和它匹配的,则显示匹配的值,如果从表中没有和它匹配的,则显示null。
- (左/右)外连接查询结果=内连接结果+主表中有而从表没有的记录。
- 全外连接=内连接的结果+表1中有但表2没有的+表2中有但表1没有的
注:mysql不支持全外fulljoin连接
4. sql92语法中不支持外连接。
细分为:
左外连接:select from idname LEFT OUTER JOIN idnameky on idname.Id=idnameky.idKey
右外连接:select from idname RIGHT OUTER JOIN idnameky on idname.Id=idnameky.idKey
全外连接(mysql 99标准不支持)
交叉连接(cross join)
表进行笛卡尔积得到的表数据:select * from idname CROSS JOIN idnameky
七种join图解
- 内连接

select * from A inner join B where A.key=B.key;
- 左连接

select * from A left join B on A.key=B.key where B.key is null;
- 右连接

select * from A right join B on A.key=B.key where A.key is null;
- 左外连接

select * from A left join B on A.key=B.key;
- 右外连接

select * from A right join B on A.key=B.key
- 全外连接

select from A left join B where A.key=B.key
union
select from A right join B where A.key=B.key;
备注:mysql不支持full outer join
另:union默认是去重的,如果不去重可使用union all
- 两表独有的数据集

select from A left join B on A.key=B.key where B.key is null union select from A right join B on A.key=B.key where A.key is null;
附录:cross join 笛卡尔积(===灵魂画手===)
4 join连接原理分析
join方式连接多个表,本质就是各个表之间数据的循环匹配。MySQL5.5版本之前,MySQL只支持一种表间关联方式,就是嵌套循环(Nested Loop Join)。如果关联表的数据量很大,则join关联的执行时间会非常长。在MySQL5.5以后的版本中,MySQL通过引入BNLJ算法来优化嵌套执行。
驱动表和被驱动表
概念:驱动表就是主表,被驱动表就是从表、非驱动表。
- 对于内连接来说:A JOIN B,A表就一定是驱动表吗?不一定。
- 对于外连接来说:MySQL的查询优化器会根据情况内部会将其变为内连接,然后根据情况选择驱动表
结论1:对于内连接来说,查询优化器可以决定谁来作为驱动表,谁作为被驱动表出现。
- 子结论1:对于内连接来讲,如果表的连接条件中只能有一个字段有索引,则有索引的字段所在的表会被作为被驱动表。
- 子结论2:对于内连接来说,在两个表的连接条件都存在索引的情况下,会选择小表作为驱动表。
结论2:对于外连接来说,查询优化器会根据情况将其改造成内连接,然后使用上面的结论1选择驱动表。
原则
- 小表驱动大表
- 有索引的字段会尽量作为被驱动表
小结:表关联优化原则
- 整体效率比较:INLJ > BNLJ > SNLJ
- 保证被驱动表的JOIN字段已经创建了索引(减少内层表的循环匹配次数),且需要JOIN 的字段,数据类型保持绝对一致
- 小结果集驱动大结果集
- LEFT JOIN 时,选择小表作为驱动表, 大表作为被驱动表 。减少外层循环的次数。
- INNER JOIN 时,MySQL会自动将小结果集的表选为驱动表 。选择相信MySQL优化策略。
note:left/join等于其各自取反如下两个语法的值是一样的
select * from user u left join userdata ud on u.userid=ud.userid;select * from userdata u right joinuserud on u.userid=ud.userid;
由于MySQL表关联的算法是 Nest Loop Join,是通过驱动表的结果集作为循环基础数据,然后一条一条地通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。
故优化的重要原则:尽可能减少JOIN中Nested Loop的循环次数。以此保证:永远用小结果集驱动大结果集(其本质就是减少外层循环的数据数量,小的度量单位指的是表行数*每行大小)。
案例:表A有1000条数据,表B有500条数据
- 表A加了where过滤后查出来5条数据,表B再加了where过滤后查出来8条数据,如果A和B的数据类型一样,则表A为小的结果集。
- 如果表A的类型是long,表B的类型为int,则表B变成了小结果集。
- 如果在做select的时候,A表的数据字段多的多,则A是大结果集
总结:结果集不是看表的数据多少,是看做表关联的时候查询出来的表的行数*每行的大小,因为这个驱动表要加载到JoinBuffer,JoinBuffer容量有限,数据集少了可以加载更多,减少磁盘I/O。

- 能够直接多表关联的尽量直接关联,不用子查询。(减少查询的趟数)
- 不建议使用子查询,建议将子查询SQL拆开结合程序多次查询,或使用 JOIN 来代替子查询
- 衍生表建不了索引
- 根据情况调整join buffer size的大小(一次缓存的数据越多,那么内层包的扫表次数就越少)
减少驱动表不必要的字段查询(字段越少,join buffer所缓存的数据就越多)
Nestes嵌套算法原则
MySQL在做表连接的时候(假如有A/B/C三张表),是遵循怎样的连接规则呢,是先将A/B两个表先做表连接再关联C表,还是A/B/C三表的循环嵌套连接或者是其他算法呢?
答:MySQL的join连接采用的算法是Nested-Loop Join,即嵌套循环连接算法。简而言之,即mysql会确定好所有表的连接顺序(即驱动表和被驱动表)不是两两联合之后,再去联合第三张表,而是驱动表的一条记录穿到底,匹配完所有关联表之后,再取驱动表的下一条记录重复联表操作。
细分算法,Nested-Loop Join算法又有三种变形,分别为- 简单嵌套循环连接:Simple Nested-Loop Join
- 索引嵌套循环连接:Index Nested-Loop Join
- 块索引嵌套连接:Block Nested-Loop Join
其中在使用索引关联的情况下,有 Index Nested-Loop join 和 Batched Key Access join 两种算法;
在未使用索引关联的情况下,有 Simple Nested-Loop join 和 Block Nested-Loop join 两种算法;
SNLJ:简单循环嵌套连接Simple Nested-Loop Join
简单嵌套循环,简称 SNL,逐条逐条匹配,伪代码即像如此。即如果有三个表,外层是驱动表,最内层则是最后一个被驱动表,多表间循环嵌套。

for each row in t1 matching range {for each row in t2 matching reference key {for each row in t3 {if row satisfies join conditions, send to client}}}
这种算法简单粗暴,但毫无性能可言,时间性能上来说是 n(表中记录数) 的 m(表的数量) 次方,所以 MySQL 做了优化,联表查询的时候不会出现这种算法,即使在无WHERE条件且ON的连接键上无索引时,也不会选用这种算法(其他算法总体思路差不多,都是多层循环嵌套计算)。
BNLJ:缓存块嵌套循环连接Block Nested-Loop Join
如果存在索引,那么会使用下面的下一小节的INLJ的方式进行join,如果join的列没有索引,被驱动表要扫描的次数太多了。每次访问被驱动表,其表中的记录都会被加载到内存中,然后再从驱动表中取一条与其匹配,匹配结束后清除内存,然后再从驱动表中加载一条记录,然后把被驱动表的记录在加载到内存匹配,这样周而复始,大大增加了Io的次数(该思路即为上一节的SNLJ)。为了减少被驱动表的I/O次数,就出现了Block Nested-Loop Join的方式。
BNLJ即为缓存块嵌套循环连接,是对 INLJ 的一种优化,其不再是逐条获取驱动表的数据,引入了Join Buffer缓冲区的概念,其会将驱动表相关的部分数据列(大小受join buffer的限制)缓存到JoinBuffer中,然后全表扫描被驱动表,被驱动表的每一条记录一次性和JoinBuffer中的所有驱动表记录进行匹配(内存中操作),将简单嵌套循环中的多次比较合并成一次,降低了被驱动表的访问频率。
将内部循环中读取的每一行与缓冲区中的所有记录进行比较,这样就可以减少内层循环的读表次数。举个例子,如果没有 Join Buffer,驱动表有 30 条记录,被驱动表有 50 条记录,那么内层循环的读表次数应该是 30 50 = 1500,如果 Join Buffer 可用并可以存 10 条记录(Join Buffer 存储的是驱动表中参与查询的列,包括 SELECT 的列、ON 的列、WHERE 的列,而不是驱动表中整行整行的完整记录),那么内层循环的读表次数应该是 30 / 10 50 = 150,被驱动表必须读取的次数减少了一个数量级。当被驱动表在连接键上无索引且被驱动表在 WHERE 过滤条件上也没索引时,常常会采用此种算法来完成联表。
注意
- 这里缓存的不只是关联表的列,select后面的列也会缓存起来。
- 在一个有N个join关联的sql中会分配N-1个join buffer。所以查询的时候尽量减少不必要的字段,可以让joinbuffer中可以存放更多的列。
- 可以通过更改join_buffer_size调整缓存区的大小。
- join_buffer_size变量决定buffer大小。
- 只有在join类型为all, index, range的时候才可以使用join buffer。
- 能够被buffer的每一个join都会分配一个buffer,也就是说一个query最终可能会使用多个join buffer。
- 第一个nonconst table不会分配join buffer,即便其扫描类型是all或者index。
- 在join之前就会分配join buffer, 在query执行完毕即释放。 join buffer中只会保存参与join的列, 并非整个数据行。


for each row in t1 matching range {for each row in t2 matching reference key {store used columns from t1, t2 in join bufferif buffer is full {for each row in t3 {for each t1, t2 combination in join buffer {if row satisfies join conditions, send to client}}empty join buffer}}}if buffer is not empty {for each row in t3 {for each t1, t2 combination in join buffer {if row satisfies join conditions, send to client}}}
INLJ索引嵌套循环Index Nested-Loop Join
索引嵌套循环,简称 INLJ,是基于被驱动表的索引进行连接的算法;驱动表的记录逐条与被驱动表的索引进行匹配,避免和被驱动表的每条记录进行比较,减少了对被驱动表的匹配次数,大致流程如下图。
驱动表中的每条记录通过被驱动表的索引进行访问,因为索引查询的成本是比较固定的,故mysql优化器都倾向于使用记录数少的表作为驱动表(外表)。
如果被驱动表加索引,效率是非常高的,但如果索引不是主键索引,所以还得进行一次回表查询。相比,被驱动表的索引是主键索引,效率会更高。

详细图

BKA批量key访问Batched Key Access
批量key访问,简称 BKA,是对 INL 算法的一种优化;
BKA 对 INL 的优化类似于 BNL 对 SNL 的优化
Hash Join
从MySQL的8.0.20版本开始将废弃BNLJ,因为从MySQL8.0.18版本开始就加入了hash join默认都会使用hash join
5 语句的执行顺序(已验证)
说明
参考链接:SQL语句执行深入讲解
//1.0 人写SELECT DISTINCT <select_list>FROM <left_table><join_type> JOIN <right_table> ON <join_condition>WHERE <where_condition>GROUP BY <group_by_list>HAVING <having_condition>ORDER BY <order_by_condition>LIMIT <limit_number>//2.0 然而机器的执行顺序是这样的FROM <left_table>ON <join_condition><join_type> JOIN <right_table>WHERE <where_condition>GROUP BY <group_by_list>HAVING <having_condition>SELECTDISTINCT <select_list>ORDER BY <order_by_condition>LIMIT <limit_number>

关于ONLY_FULL_GROUP_BY的设置
问题链接
为什么mysql having的条件表达式可以直接使用select后的别名
问题描述
问题1:为什么mysql having的条件表达式可以直接使用select后的别名
题目补充:即MySQL可以这么用:select id as i from Users group by i;该情况在MSSQL下是不允许的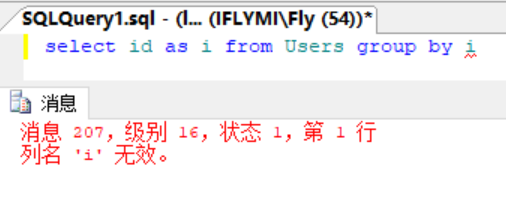
问题2:为什么select、having和 order by list中可以不用聚合函数就可以使用没有出现在group by list中的字段?
题目补充:MySQL可以这么用:MySQL-Select查询:select idValue from idnameky group by idKey;该情况在MSSQL下是不允许的。
MySQL也可以这么用:MySQL-having查询:select idValue from idnameky group by idKey having idValue>1;该情况在MSSQL下也是不允许的
Mysql可以在Order by中这么用:select idValue from idnameky group by idKey having idValue>1 order by idValue;同理,该用法在MSSQL也是不允许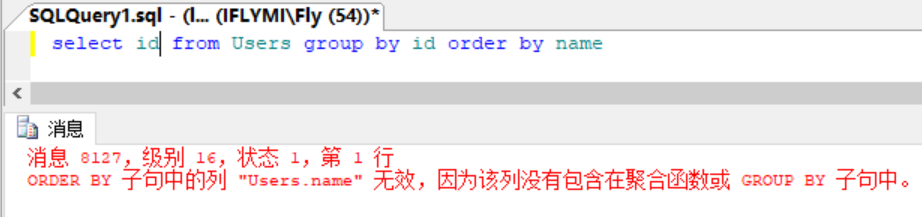
问题解释
SQL语句的语法顺序为:
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> DISTINCT -> UNION -> ORDER BY ->LIMIT
因此一般不能在having condition中使用select list中的alias。但是mysql对此作了扩展。在mysql 5.7.5之前的版本,ONLY_FULL_GROUP_BY sql mode默认不开启。在5.7.5或之后的版本默认开启。
如果ONLY_FULL_GROUP_BY sql mode不开启,那么mysql对标准SQL的扩展可以生效:
- 允许在having condition中使用select list中的alias
- 允许在select list、having condition和order by list中使用没有出现在group by list中的字段。

若有收获,就点个赞吧
0 人点赞
