Scrapy框架
- scrapy框架是用纯Python实现的一个为了抓取网页内容、提取结构性数据而开发的应用框架,在数据采集领域非常流行。
- 既然是框架的话,用户在开发的时候,只需要定制开发几个模块就可以轻松地实现一个爬虫程序,完成网页内容或图片的抓取工作。
scrapy使用了Twisted异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架。并且scrapy还提供了各种中间件接口,可以灵活的完成各种需求。
1. Scrapy架构图(新版)
1.1 scrapy组件
Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler这些组件之间的控制、通信和数据传递。(类似于“中央控制器”)
- Scheduler(调度器):负责接收scrapy engine发送过来的Request请求,如队列,并按照一定的方式进行整理排列(例如:可以对请求进行去重);当scrapy engine需要时,再将Request交还给scrapy engine。
- Downloader(下载器)下载器负责根据URL获取页面数据并提供给引擎,而后提供给spider。
- Spider:Spider负责处理所有的Responses,从中分析提取数据,获取Item字段需要的数据,并将新提取的URL提交给scrapy engine,由scrapy engine交给Scheduler进行处理。 每个spider负责处理一个特定(或一些)网站。
- Item Pipeline:Item Pipeline负责处理被spider提取出来的item,并进行后期处理(过滤、存储等)。
- Downloader middlewares(下载器中间件):下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response(也包括引擎传递给下载器的Request)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能(代理设置、给请求设置User-Agent)。使用较多!
- Spider middlewares(Spider中间件):Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。这个中间件使用较少!
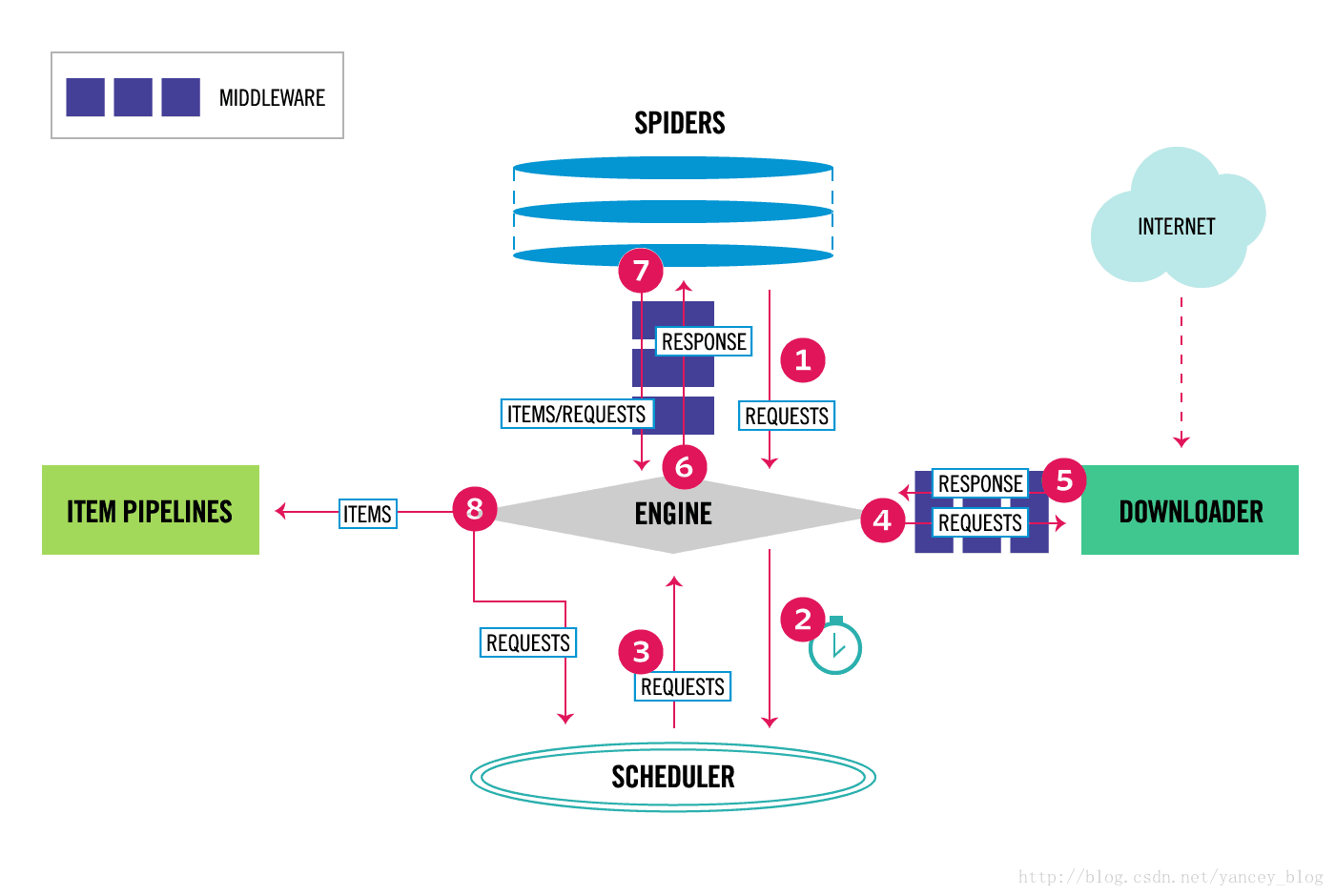
1.2 scrapy数据流向
Scrapy中的数据流由执行引擎控制,其过程如下:
- 引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
- 引擎从Spider中获取到第一个要爬取的URL的Request对象,并交给调度器(Scheduler)以调度。
- 引擎向调度器请求下一个要爬取的URL。
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
- Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
注意:只有当 调度器 中不存在任何Request时,整个程序才会停止(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
2. Scrapy的配置安装
Scrapy框架官方网址:https://scrapy.org/
Scrapy文档地址:https://docs.scrapy.org/en/latest/index.html
Scrapy中文文档:https://scrapy-chs.readthedocs.io/zh_CN/1.0/index.html
pip安装命令
Windows安装方式:pip install scrapy
Linux安装方式:sudo pip3 install scrapy
安装完成后,在命令行输入scrapy,如果出现下图所示内容,就表明scrapy已经安装成功!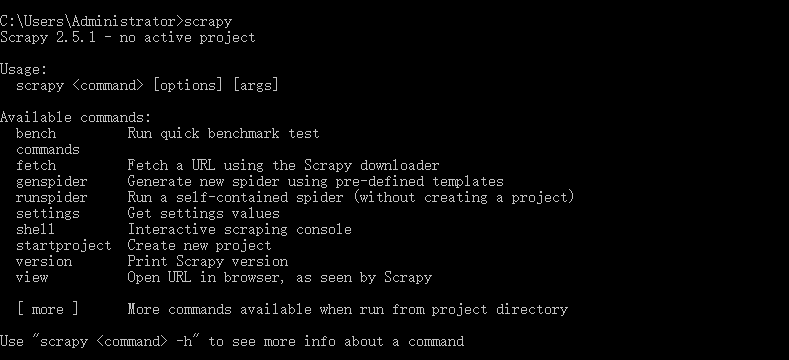
2.1 Scrapy常用命令
Usage:
scrapy
Available commands:
bench:Run quick benchmark test # 执行一个快速的性能测试scrapy bench
commands
fetch:Fetch a URL using the Scrapy downloader # 使用下载器去访问一个URL地址scrapy fetch "https://www.baidu.com"
genspider:Generate new spider using pre-defined templates # 根据定义好的模板生成一个新的spider.py文件scrapy genspider xxx xxx.com
runspider:Run a self-contained spider (without creating a project)
settings:Get settings values
shell: Interactive scraping consolescrapy shell "https://www.baidu.com"
startproject:Create new project # 创建一个新的scrapy项目
version:Print Scrapy version # 查看当前Scrapy框架的版本
view:Open URL in browser, as seen by Scrapy # 在浏览器中打开URL(浏览器视图)scrapy view "https://www.baidu.com"

若有收获,就点个赞吧
0 人点赞
