同步方案
- Q1:单体模式还是集群模式?
- 全量同步的时候还要进行增量数据同步,如果集群模式,那么就要对原数据进行数据分片,由每个实例进行同步,增加了复杂性
- 避免同步数据过程中造成目标库脏数据,因为目标库前都要比对写入的数据和目标库数据的更新时间,只保留最新的数据
- Q2:增量同步的MQ的offset是自动提交还是手动提交?
- 一个服务实例处理TOPIC的所有消息,如果同步处理MQ,自动提交offset,则会降低吞吐量,容易造成消息积压。
- 异步处理+手动提交,可以提交吞吐量,手动提交offset也更加灵活可靠
全量同步
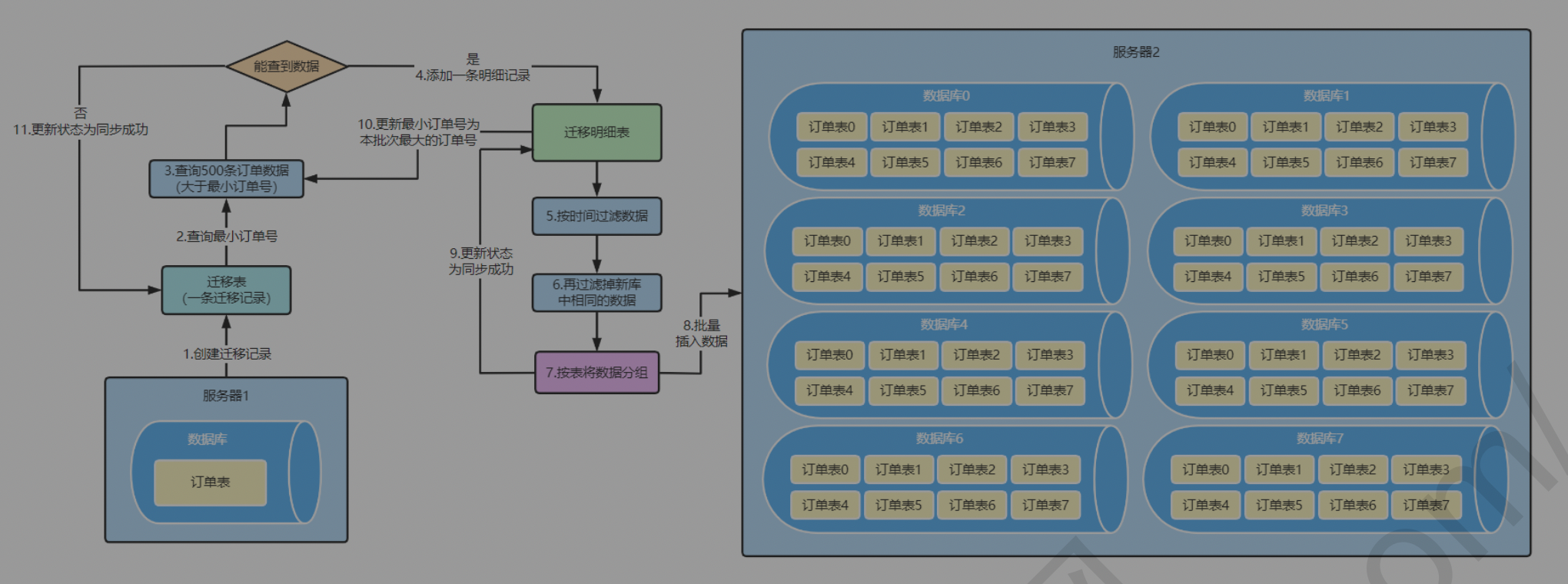
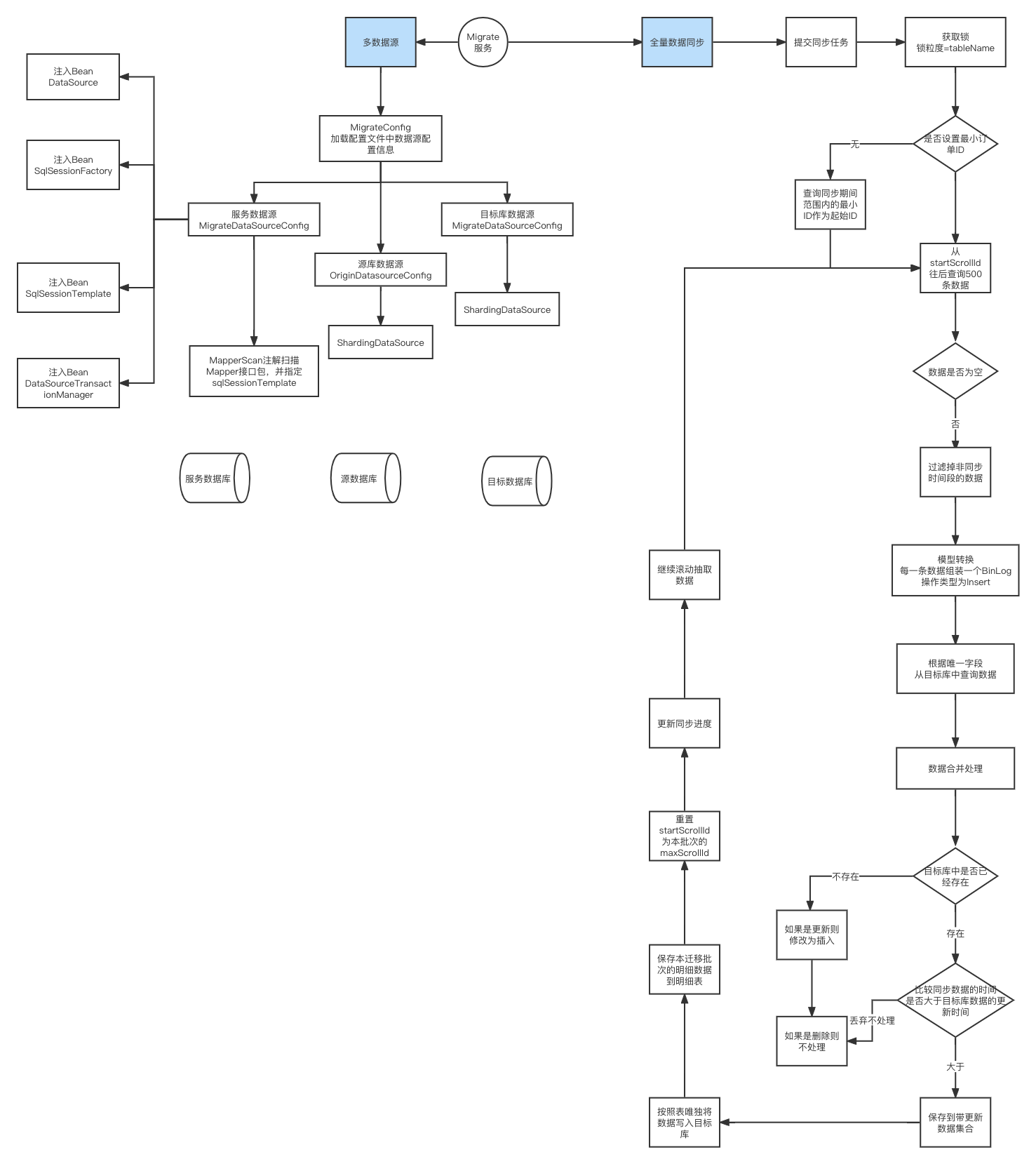
- 分批次迁移处理
- 全量同步时,由于旧库的数据量过大,我们需要进行分批次的来做迁移。我们可以根据指定时间段框定
- 一批数据进行全量同步
- 基于db进行迁移进度
- 依赖数据迁移的db,比如我们这里弄了迁移表和迁移明细表
- 使用批量操作
-
中断恢复
根据迁移明细表可以查询上次失败数据,然后继续同步
如果同步成功了,但还没更新同步状态,系统宕机了,则同步时候进行去重
增量同步
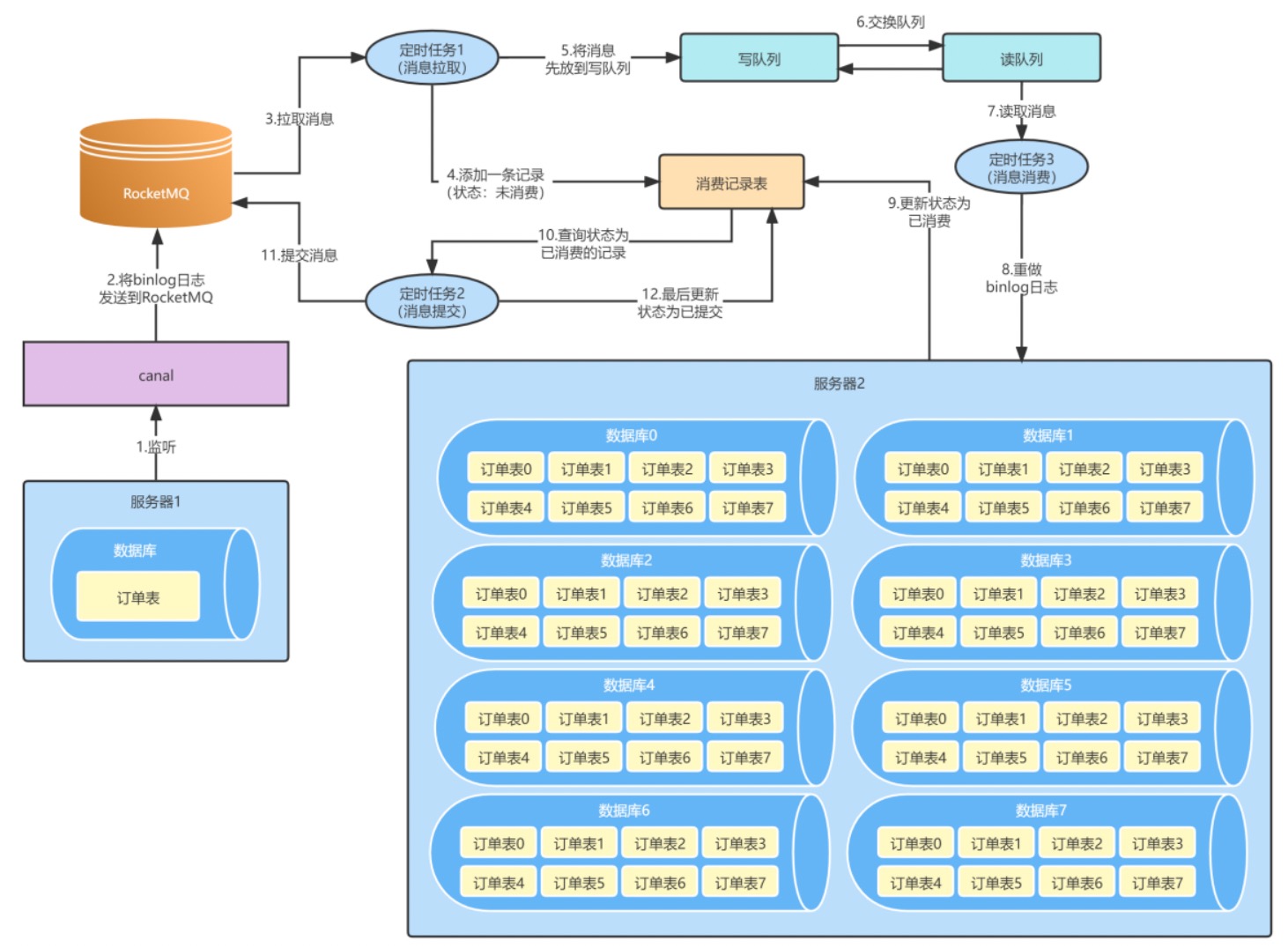
手动提交offset
- 为了避免消息的丢失
- 读写队列,批量处理mq当中的binlog
- 为了提高处理binlog的效率,把mq当中的binlog放到写队列当中,在进行增量同步的时候,进行读写
- 队列的交换。
- 同一条数据多条binlog进行合并针对同一条数据的多条binglog,我们只保留最新的(更新时间最新的)一条binlog
- 按表进行分组
同一个表 binlog都放在一起,这样插入新库时,就可以进行
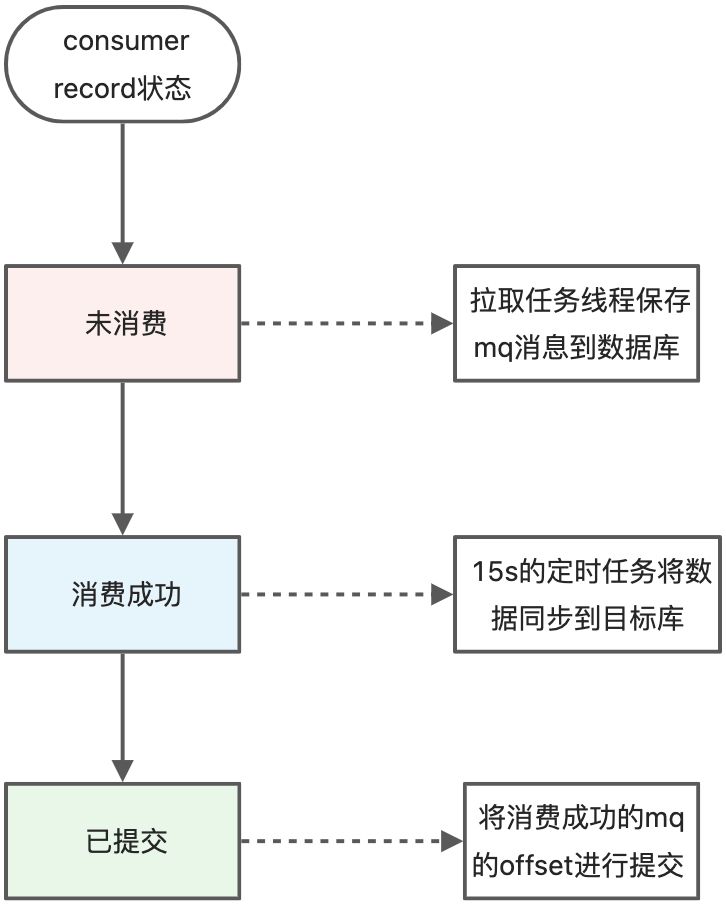
消息状态
基于队列异步处理设计
写队列负责mq消息的写入
- 读队列负责进行消息的读取处理
- 队列:由于JDK的阻塞队列只能保证一个队列的并发安全,而这里在进行读写队列切换时候要保证两个要保证两个队列同时操作时候的并发安全
- 锁:_synchronized、ReentrantLock都是偏重量级的锁,其实现也都有基于CAS的实现,这里使用_AtomicBoolean自己实现了一个cas的轻量级锁,因为业务上锁后执行的都是内存级的简单操作,耗时很短,所以不会造成严重的锁冲突锁等待,性能更好
```java public class LocalQueue {private static volatile LocalQueue localQueue;
/**
- 数据同步的写队列
/
private volatile LinkedList
writeQueue = new LinkedList<>(); /* - 数据同步的 读队列
/
private volatile LinkedList
readQueue = new LinkedList<>(); /* - 提供锁的实例对象 / private final PutBinlogLock lock = new PutBinlogLock(); /*
- 是否正在读取数据
可能是多线程并发读和写,volatile,保证线程之间的可见性 */ private volatile boolean isRead = false;
private LocalQueue(){}
/**
- 构建一个单例模式对象
- @return LocalQueue实例
*/
public static LocalQueue getInstance(){
if (null == localQueue){
} return localQueue; } }synchronized (LocalQueue.class){if (null == localQueue){localQueue = new LocalQueue();}}
- 数据同步的写队列
/
private volatile LinkedList
public class PutBinlogLock {
private final AtomicBoolean putMessageSpinLock = new AtomicBoolean(true);/*** 上锁*/public void lock() {// 假设,多个线程同时来进行加锁boolean flag;do {// 多个线程都会去进行CAS操作,只有一个人可以把true变为false// atomic变量,默认就是支持线程安全性// 只有一个线程可以完成加锁的逻辑// flag = true// 其他线程来说,cas加锁都失败了,在进入自旋,flag是falseflag = this.putMessageSpinLock.compareAndSet(true, false);}while (!flag);}/*** 解锁*/public void unlock() {// 只有一个线程可以成功的执行cas,把false->truethis.putMessageSpinLock.compareAndSet(false, true);}
}
<a name="zFrcX"></a>#### 新增binlog消息拉取处理流程- 服务启动后,创建拉取任务线程,创建Consumer,这是autoCommit为false,然后不停等拉取消息,每次拉取到消息处理完后会sleep5秒1. 根据topic、queueId、offset判断这个mq消息是否已经处理,如果已经处理则直接返回1. 对binlog消息体的json数据进行解析,解析为一个EtlBinlogConsumeRecord,插入到数据库1. 消息提交到本地队列LocalQueue的写队列中1. 每隔15s执行一次的定时任务,会负责消息的写入1. 首先根据isRead判断是否正在进行数据读取处理,如果正在是,则此次定时任务不进行操作1. 否则,现将isRead设置为true,然后将读写队列进行互换1. **数据合并**:将队列中的binlog数据进行合并,如果同一条数据有多条操作记录,则只保存最新的一条1. **数据过滤:**例如某条数据更新时间小于目标库对于记录的更新时间,过滤不处理。根据数据的唯一字段,从目标库查询出数据,在内存中和新增纪律进行判断操作1. **数据写入:**数据进行组装并拼接SQL,在目标库上执行,执行成功后,将数据EtlBinlogConsumeRecord中的状态在数据库中进行更新<a name="TuH5Z"></a>#### offset提交任务处理流程- 消息拉取和消息提交都会创建订阅相同TOPIC但不同消费组的Consumer- 消息提交的Consumer只是 用来进行offset提交1. 在循环中从数据库查询消费成功的ConsumeRecord1. consumer.seek()方法定位到消息offset的位置1. consumer.poll(),做一个poll操作,从我们指定的位置poll拉取过来一批数据,不然手动提交的东西不对1. consumer.commitSync()方法提交offset```java/*** 执行消息提交* @param consumer 消息拉取消费者*/private void commitRun (DefaultLitePullConsumer consumer){try{// 线程一旦启动,会先把topic里的queue拉取过来,他就知道你有多少queue// 把你的topic里所有的queue,都分配给你当前的这个consumer,当前的consumer他是可以拿到所有的queueCollection<MessageQueue> messageQueues = consumer.fetchMessageQueues(topic);consumer.assign(messageQueues);try {// 这里负责重试while (true) {// 取得所有已消费未提交的记录// 每一个binlog都会对应一条consume record,没有提交的record都查出来List <EtlBinlogConsumeRecord> consumedRecords = consumeRecordMapper.getNotCommittedConsumedRecords(topic);if (CollUtil.isNotEmpty(consumedRecords)){// 对每一个consumer record做遍历for (EtlBinlogConsumeRecord consumedRecord : consumedRecords){// 每个binlog都是rocketmq里的一条消息,topic、queue、offset、message -> binlog// 基于consumer,seek,直接seek定位到topic、queue、offset那个位置去consumer.seek(new MessageQueue(consumedRecord.getTopic(), consumedRecord.getBrokerName(), consumedRecord.getQueueId()), consumedRecord.getOffset());//这一步必须,不然手动提交的东西不对,做一个poll操作,从我们指定的位置poll拉取过来一批数据List<MessageExt> messageExts = consumer.poll();// 提交已消费的消息,拉取过来一批消息过后,对这批消息,就可以去执行commit,把这批消息被处理成功的offset做一个提交consumer.commitSync();// 更新消费记录状态为已提交,再把这条消息消费记录的状态,修改为committed,就正式认为说这条消息他就已经提交成功了consumedRecord.setConsumeStatus(ConsumerStatus.COMMITTED.getValue());consumeRecordMapper.updateConsumeRecordStatus(consumedRecord);}}else{Thread.sleep(5000);}}}finally {consumer.shutdown();}}catch (MQClientException | InterruptedException e){try{// 假设要拉取消息的主题还不存在,则会抛出异常,这种情况下休眠五秒再重试Thread.sleep(5000);commitRun (consumer);}catch (InterruptedException interruptedException){log.error("消息拉取服务启动失败!", e);}}}
�binlog消息处理失败方案
- 对于RocketMQ如果拉取到一批消息后,没有任何返回值,关闭了自动提交,那么Broker会重试投递
- 如果某次定时任务保存数据到目标库处理失败,则会等RocketMQ重试再进行处理
- 拉取消息的mq拉取到消息后,如果对应的consume record已经存在则进行如下逻辑:
如果系统在运行中崩溃了,重启后系统能否正常运行(可能处于同步流程的任何环节)?
后续
全量同步和增量同步进行中的数据一致性问题
全量在前,增量在后?
- 正常逻辑
- 增量在前,全量在后?
- insert:全量同步进行数据比对和过滤
- update:全量同步过程中新旧数据比对只会留下更新时间最近的那一条
- delete:增量不进行处理,全量也查不到这条数据
并发同步冲突
- update
- 假如全量同步一批数据进行insert,在执行insert之前,增量接受到这条数据的update并转为insert插入到了数据库,那么增量的insert会报错“唯一键冲突”,此时数据是增量的数据,所以结果是对的。不过全量同步由于异常没有重置maxSrowId,那边这批数据会被重新处理
- 假如上面的情况是全量先insert成功,增量执行失败,那么由于mq重试,会重新执行这条binlog,将数据补全
- insert-空删除
- update
数据检查的定时任务,随机抽数,拉取已经同步完成的旧库数据和新库数据进行比对
-
分库分表运维和扩容
运维
开发一个SQL控制台功能,基于sharding-jdbc,将DDL语句分发到所有数据库上运行

若有收获,就点个赞吧
0 人点赞
