UUID
不建议
- 优点:
- 实现简单,ID单调自增,数值类型查询速度快
- 缺点:
- DB单点存在宕机风险,无法扛住高并发场景
数据库自增ID(双主)
前边说了单点数据库方式不可取,那对上边的方式做一些高可用优化,换成主从模式集群。害怕一个主节点挂掉没法用,那就做双主模式集群,也就是两个Mysql实例都能单独的生产自增ID。
那这样还会有个问题,两个MySQL实例的自增ID都从1开始,会生成重复的ID怎么办?
解决方案:设置起始值和自增步长
那如果集群后的性能还是扛不住高并发咋办?就要进行MySQL扩容增加节点,这是一个比较麻烦的事
增加第三台MySQL实例需要人工修改一、二两台MySQL实例的起始值和步长,把第三台机器的ID起始生成位置设定在比现有最大自增ID的位置远一些,但必须在一、二两台MySQL实例ID还没有增长到第三台MySQL实例的起始ID值的时候,否则自增ID就要出现重复了,必要时可能还需要停机修改。
优点:
- DB单点存在宕机风险,无法扛住高并发场景
- 解决DB单点问题
缺点:
不利于后续扩容,而且实际上单个数据库自身压力还是大,依旧无法满足高并发场景
基于数据库的号段模式
CREATE TABLE id_generator (id int(10) NOT NULL,max_id bigint(20) NOT NULL COMMENT '当前最大id',step int(20) NOT NULL COMMENT '号段的布长',biz_type int(20) NOT NULL COMMENT '业务类型',version int(20) NOT NULL COMMENT '版本号',PRIMARY KEY (`id`))
biz_type :代表不同业务类型
max_id :当前最大的可用id
step :代表号段的长度
version :是一个乐观锁,每次都更新version,保证并发时数据的正确性
等这批号段ID用完,再次向数据库申请新号段,对max_id字段做一次update操作,update max_id= max_id + step,update成功则说明新号段获取成功,新的号段范围是(max_id ,max_id +step]。update id_generator set max_id = #{max_id+step}, version = version + 1 where version = # {version} and biz_type = XXX
由于多业务端可能同时操作,所以采用版本号version乐观锁方式更新,这种分布式ID生成方式不强依赖于数据库,不会频繁的访问数据库,对数据库的压力小很多。
基于Redis模式
原理就是利用redis的 incr命令实现ID的原子性自增
用redis实现需要注意一点,要考虑到redis持久化的问题。redis有两种持久化方式RDB和AOFRDB会定时打一个快照进行持久化,假如连续自增但redis没及时持久化,而这会Redis挂掉了,重启Redis后会出现ID重复的情况。
- AOF会对每条写命令进行持久化,即使Redis挂掉了也不会出现ID重复的情况,但由于incr命令的特殊性,会导致Redis重启恢复的数据时间过长
基于雪花算法(Snowflake)模式
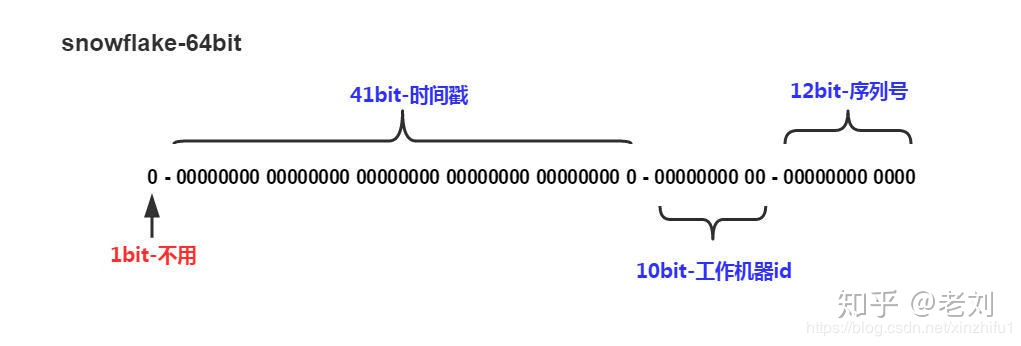
Snowflake ID组成结构:正数位(占1比特)+ 时间戳(占41比特)+ 机器ID(占5比特)+ 数据中心(占5比特)+ 自增值(占12比特),总共64比特组成的一个Long类型。
- 第一个bit位(1bit):Java中long的最高位是符号位代表正负,正数是0,负数是1,一般生成ID都为正数,所以默认为0。
- 时间戳部分(41bit):毫秒级的时间,不建议存当前时间戳,而是用(当前时间戳 - 固定开始时间戳)的差值,可以使产生的ID从更小的值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L 60 60 24 365) = 69年
- 工作机器id(10bit):也被叫做workId,这个可以灵活配置,机房或者机器号组合都可以。
序列号部分(12bit),自增值支持同一毫秒内同一个节点可以生成4096个ID
解决时钟回拨问题
等待一定时间让机器时间追上来
保存过去一段时间内每一台机器在当前这一毫秒产生的ID的最大值,比如使用Map形式,就是
-
美团(Leaf)
百度(uid-generator)
滴滴(Tinyid)

若有收获,就点个赞吧
0 人点赞
