嵌套循环连接(Nested-Loop Join)
当我们连接两张表时,我们可以把两张表所有数据加载到一个连接表视图中,但如果两张表数据量很大,加载所有的表数据必然会影响到效率。
所以,在 MySQL 中,使用了 Nested-Loop Join 的算法思想去优化两张表的连接,Nested-Loop Join 翻译成中文则是“嵌套循环连接”。基本原理就是把符合过滤条件的数据加入到结果集中。
举个例子:
select * from t1 inner join t2 on t1.id=t2.tid
t1 称为外层表,也可称为驱动表。 t2 称为内层表,也可称为被驱动表。
伪代码表示:
把符合的 r1.id = r2.tid 过滤条件的数据加入到结果集中。
List<Row> result = new ArrayList<>();
for(Row r1 in List<Row> t1){
for(Row r2 in List<Row> t2){
if(r1.id = r2.tid){
result.add(r1.join(r2));
}
}
}
Nested-Loop Join 3 种实现的算法:
- Simple Nested-Loop Join:SNLJ,简单嵌套循环连接
- Index Nested-Loop Join:INLJ,索引嵌套循环连接
- Block Nested-Loop Join:BNLJ,缓存块嵌套循环连接
在选择 Join 算法时,根据谁快谁优先原则,合理判断选择合适的连接算法:
Index Nested-LoopJoin > Block Nested-Loop Join > Simple Nested-Loop Join
Simple Nested-Loop
简单嵌套循环连接实际上就是简单粗暴的嵌套循环,如果 table1 有 1 万条数据,table2 有 1 万条数据,那么数据比较的次数= 1 万 * 1 万 = 1 亿次,这种查询效率会非常慢。
所以 MySQL 继续优化,然后衍生出 Index Nested-LoopJoin 、Block Nested-Loop Join 两种 NLJ 算法。在执行 join 查询时 MySQL 会根据情况选择两种之一进行 join 查询。
Index Nested-Loop Join(减少内层表数据的匹配次数)
索引嵌套循环连接是基于索引进行连接的算法,索引是基于内层表的,通过外层表匹配条件直接与内层表索引进行匹配,避免和内层表的每条记录进行比较,从而利用索引的查询减少了对内层表的匹配次数,优势极大的提升了 join 的性能:
原来的匹配次数 = 外层表行数 内层表行数 优化后的匹配次数= 外层表的行数 内层表索引的高度
使用场景:只有内层表 join 的列有索引时,才能用到 Index Nested-LoopJoin 进行连接。
由于用到索引,如果索引是二级索引且查询数据没有覆盖索引,则会产生回表,多了一些IO操作。
Block Nested-Loop Join(减少外层表数据的循环次数)
缓存块嵌套循环连接通过一次性缓存多条数据,把参与查询的列缓存到 join Buffer 里,然后拿 join buffer 里的数据批量与内层表的数据进行匹配,从而减少了外层循环的次数。
但是,BNL 算法在大表 join 的时候性能就差多了,比较次数等于两个表参与 join 的行数的乘积,很消耗 CPU 资源。
当不使用 Index Nested-Loop Join 的时候,默认使用 Block Nested-Loop Join 。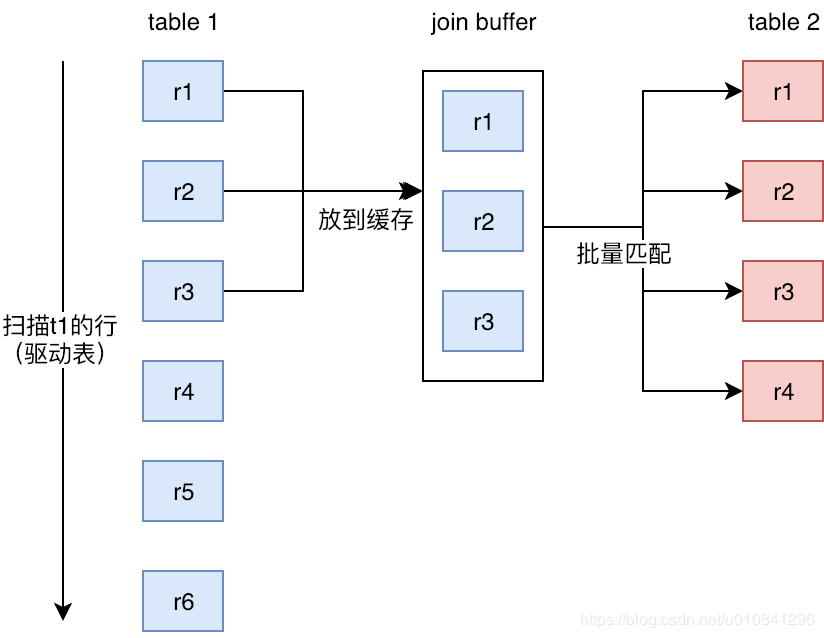
什么是Join Buffer?
Join Buffer 会缓存所有参与查询的列而不是只有 Join 的列。
使用 Block Nested-Loop Join 算法需要开启优化器管理配置的 optimizer_switch 的设置 block_nested_loop 为 on,默认为开启。
join_buffer_size 的默认值是 256K,join_buffer_size 的最大值在 MySQL 5.1.22 版本前是 4G-1,而之后的版本才能在 64 位操作系统下申请大于 4G 的 Join Buffer 空间。
如果 join_buffer 放不下表 t1 的所有数据,策略很简单,就是分开放。
执行过程:
- 扫描表 t1,顺序读取数据行放入 join_buffer 中,放完第 88 行 join_buffer 满了,继续第 2 步;
- 扫描表 t2,把 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回;
- 清空 join_buffer;
继续扫描表 t1,顺序读取最后的 12 行数据放入 join_buffer 中,继续执行第 2 步。
执行流程图:

图中的步骤 4 和 5,表示清空 join_buffer 再复用。 这个流程才体现出了这个算法名字中“Block”的由来,表示“分块去 join”。优化join速度
如何选择小表
在决定哪个表作为驱动表的时候,应该是两个表按照各自的条件过滤。过滤完成之后,计算参与 join 的各个字段的总数据量,数据量小的那个表,就是小表(驱动表)。
参考资料:
- 极客时间专栏,《MySQL实战45讲》,到底可不可以使用join。

若有收获,就点个赞吧
0 人点赞
