- 一、决策树的基本概念和分类:
- 二、决策树的主要步骤:
- 1、特征选择问题:
- 1)特征选择:在于选取对训练数据具有分类能力的特征,从而提高决策树学习的效率,如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征没有有效分类。特征选择的准则是信息增益或信息增益比。
- 2)信息熵:度量样本集合纯度的一种常用指标。简单的理解就是指标1(特征量)为属性时,二分类中每个分类中结果的复杂程度。
- 表示属性a取值为v时的样本集合的子集;一般而言,信息增益越大,那么意味着使用属性a来划分所获得的“纯度提升”越大。因此,遍历所有属性分别计算信息增益,信息增益最大的那个属性将作为划分属性。如果某个属性能很好的区分结果,那么他的信息增益肯定很高。">3)信息增益:这里a表述某个属性,Gain(D,a)就是对属性a划分的信息增益,|D|表示数据集合样本的总体数量,v={1,2,…,V},表示属性a的V个取值,
 表示属性a取值为v时的样本集合的子集;一般而言,信息增益越大,那么意味着使用属性a来划分所获得的“纯度提升”越大。因此,遍历所有属性分别计算信息增益,信息增益最大的那个属性将作为划分属性。如果某个属性能很好的区分结果,那么他的信息增益肯定很高。
表示属性a取值为v时的样本集合的子集;一般而言,信息增益越大,那么意味着使用属性a来划分所获得的“纯度提升”越大。因此,遍历所有属性分别计算信息增益,信息增益最大的那个属性将作为划分属性。如果某个属性能很好的区分结果,那么他的信息增益肯定很高。 - 4)增益率:信息增益公式最大的问题在于,信息增益会偏向取值多的属性进行划分,不具有较好的泛化能力。于是提出信息增益率的定义。
- 5)gini指数
- 2、决策树的正则化
- 3、交叉验证:
- 1、特征选择问题:
- 三、决策树Python实操:
- Reference:
一、决策树的基本概念和分类:
决策树:决策树是一种基本的分类和回归方法。可以简单的认为是if-then语句的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。
主要优点: 可读性高、分类速度快。
主要步骤: 特征选择、决策树的生成、决策树的修建。
常见的决策树模型:ID3算法、C4.5算法、CART算法。
决策树的计算方法:从根节点开始时,对实例的某一特征进行测试,根据测试结果,将实例分配到其子节点;对每个子节点对应的特征进行一个取值。如此递归的对实例进行测试并分配,直至达到叶节点。最后将实例分配到叶节点的类中。
**
二、决策树的主要步骤:
1、特征选择问题:
1)特征选择:在于选取对训练数据具有分类能力的特征,从而提高决策树学习的效率,如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征没有有效分类。特征选择的准则是信息增益或信息增益比。
2)信息熵:度量样本集合纯度的一种常用指标。简单的理解就是指标1(特征量)为属性时,二分类中每个分类中结果的复杂程度。
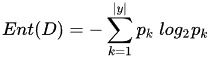
3)信息增益:这里a表述某个属性,Gain(D,a)就是对属性a划分的信息增益,|D|表示数据集合样本的总体数量,v={1,2,…,V},表示属性a的V个取值, 表示属性a取值为v时的样本集合的子集;一般而言,信息增益越大,那么意味着使用属性a来划分所获得的“纯度提升”越大。因此,遍历所有属性分别计算信息增益,信息增益最大的那个属性将作为划分属性。如果某个属性能很好的区分结果,那么他的信息增益肯定很高。

经典的ID3算法就是代表性的信息增益算法。
4)增益率:信息增益公式最大的问题在于,信息增益会偏向取值多的属性进行划分,不具有较好的泛化能力。于是提出信息增益率的定义。

IV(a)称为属性a的“固有值”,属性a 的取值数目越多,则其越大,这样就平衡了信息增益对取值较多的属性的偏好;然而增益率又会对取值数目较少的属性有偏好,因此又有一个“启发式”的规则:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
C4.5决策树算法采用增益率指标选择划分属性。
5)gini指数
样本的集合数据集的纯度除了可以用熵来衡量,还可以使用基尼值进行度量(均是衡量数据集复杂程度的度量单位。)
基尼值:反应从数据集中随机抽取两个样本,其类别标记不一致的概率,因此基尼值越小,则数据集纯度越高。
基尼指数:对属性a进行划分时,则基尼指数定义为:

划分属性时,选择基尼指数最小的属性作为划分属性。CART算法就是使用基尼指数来作为属性划分指标。
信息熵和基尼指数的选择:两种属性划分方式选择的决策树相同,但是gini值计算的更快一些。但是gini指数划分趋向于孤立数据集中数量多的类,将它们分配到一个树叶中,而信息熵则偏向于构建平衡树,将数量多的类,尽可能的分散到不同的叶子中去。
**
2、决策树的正则化
正则化:模型结构风险最小化策略的实现;
正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值越大;
主要通过选择经验风险与模型复杂度同时较小的模型。
决策树的正则化就是决策树剪枝,消除过拟合从而获得泛化能力的过程。决策树的剪枝存在两种,预剪枝和后剪枝两种。
预剪枝:抑制了很多分支的展开,降低过拟合的同时还减少了训练时间,但是却存在欠拟合的风险,预剪枝基于“贪心”策略,往 往可以达到局部最优解却不能达到全局最优解,也就是说预剪枝生成的决策树不一定是最佳的决策树。
XGBoost和lightGBM
后剪枝:后剪枝技术通常比预剪枝保留了更多的分支,它是自底向上的剪枝,因此它的欠拟合风险较小,泛化能力往往优于预剪 枝,然而因为总是要完全生长一棵树,这就要花费很多时间训练了,数据集规模大、维度高时并不适用实际应用。
3、交叉验证:
给定的样本数据充足时,将样本分成三部分:训练集、验证集、测试集。
训练集用于训练模型,验证集用于模型的选择,测试机用于 最终对学习方法的评估。但是在实际应用中数据是不充足的,为了选择好的模型,可以采用交叉验证的方法。
三、决策树Python实操:
from itertools import productimport numpy as npimport matplotlib.pyplot as pltfrom sklearn import datasetsfrom sklearn.tree import DecisionTreeClassifier# 仍然使用自带的iris数据iris = datasets.load_iris()X = iris.data[:, [0, 2]]y = iris.target# 训练模型,限制树的最大深度4,可以选择计算,可选信息熵或者基尼系数等clf = DecisionTreeClassifier(max_depth=4,criterion="gini")#拟合模型clf.fit(X, y)# 画图x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1),np.arange(y_min, y_max, 0.1))Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)plt.contourf(xx, yy, Z, alpha=0.4)plt.scatter(X[:, 0], X[:, 1], c=y, alpha=0.8)plt.show()

决策树作为一种非常基础的分类算法,这里就不过多的描述了。决策树在面对多变量大数据的情况下,还是非常的吃力。
Reference:
1、https://zhuanlan.zhihu.com/p/32053821 #这篇其实写的非常好,比我的还要详细。

若有收获,就点个赞吧
0 人点赞
