1、go 相关
编译型语言- 兼容性好,支持多种操作系统平台
- 可以指定编译输出的平台
- 类 C 语言语法
天生支持并发- 静态类型语言
- 静态语言是 编译时变量的数据类型就可确定, 也就是声明变量需要类型, int a;
- 具有垃圾回收机制 GC
2、变量和声明
go 语言中声明变量和赋值最准确的方式:
package mainimport ("fmt")func main() {var power intpower = 9000fmt.Printf("It's over %d\n", power)}
%d 是占位符 ,类似 C 语言, var 关键字声明变量, 不同的是 变量名在变量类型之前
格式:
var 变量名 变量类型
var power int
- 定义了一个 int 类型的变量 power
- go 会为变量分配默认值,
- int 初始 0
- boolean 初始 false
- string 初始 “”
声明和 赋值可以连接起来var power int = 9000
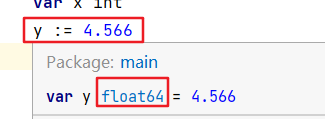
此外 go 提供了方便的 短变量声明运算符 := 可以自动推断变量的类型
power := 900//go 会自动推断 power 为 int 型
还可以和 函数结合起来使用
func main(){power := getPower() // 短变量声明 power 去接 getPower() 调用的 返回值}func getPower(){return 9001}
[ go 支持多个变量同时赋值 ]
func main(){name, power := "zhang", 9000fmt.Printf("%s's power is over %d\n", name, power)}// 此外, 多变量赋值时, 只要有一个变量是新的, 就可以使用 :=func main(){power := 9000name,power := "zhang", 100}// 尽管 power 使用了两次 := ,但是编译器不会在第 2 次使用 := 时报错// 因为这时有一个新变量 name 可以使用 :=// 然后不能改变 power变量的类型,因为它已经被被声明成一个整型,所以只能赋值整数。
[ go 不允许声明未使用的变量 ]
- // 声明了就要用,否则编译不过
func main() {name, power := "Goku", 1000fmt.Printf("default power is %d\n", power)}// 编译失败,因为 name 是一个被声明但是未被使用的变量
3、垃圾回收
一些变量,在创建的时候,就拥有 简单定义的生命周期。
- 对于函数中的变量,会在函数执行完后进行销毁。
- 对于开发人员难以确认的,手动释放,例如 C 里的 free();
- go、java、python、JavaScript 等是 会对变量进行跟踪, 并在没有使用它们的时候进行释放
- 垃圾回收会增加 额外的开销 和 致命的 bug
4、代码运行
代码执行 go run 或者 go build
- go run 包含了编译和运行
- 实际上是 使用一个临时目录来构建程序,执行完然后清理掉临时目录。
查看临时文件的位置
zhang@ubuntu:~/go/src/hello$ go run --work helloworld.goWORK=/tmp/go-build641920312Hello World by go
go 中的入口必须是 main 函数,而且是在main 包内
5、倒入包
go 中有很多内建函数
例如 println ,可以在没有引用情况下直接使用。
其他三方的库, 用关键字 import 去声明文件中代码要使用的包。
比如 导入 os 包
package mainimport(f "fmt"o "os" //can use o.Exit ,the same as os)func main(){if (len(o.Args) != 2 ){o.Exit(1)}f.Println("It's over ","param 1:",o.Args[0]," param 2", o.Args[1])}zhang@ubuntu:~/go/src/importOS$ go run main.go 1It's over param 1: /tmp/go-build250455258/command-line-arguments/_obj/exe/main param 2 1zhang@ubuntu:~/go/src/importOS$ go run main.goexit status 1
这时用到了 go 的两个标准包, fmt 和 os
以及另一个内建函数
len- len() 可以返回: 字符串的长度、字典值的数量、数组元素的数量
注意:
- go 中导入包没有使用的话同样会导致编译不通过
6、函数
6.1 函数声明
函数声明使用 func 关键字
func log(message string){ //无返回值}func add(a int , b int) int { // 返回 int 类型}func power(name string) (int,bool) { // 多个返回值}// 多返回值使用value, exits := power("zhang")if exists == false{// to do}// 有时多个返回值只关注其中给一个,将其他的返回值赋值给空白符_ :_, exists := power("zhang")if exists == false{// to do}
_是空白标识符, 实际上并没有赋值
[ 相同类型参数可以简写 ]
func( a,b int) int{}
7、数据结构
7.1 结构体
go 不像 c++、java、c# 一样的面向对象语言
- 所以 go 没有对象和继承的概念
- 也没有很多与面向对象相关的概念: 比如多态和 重载
go 所具有的是结构体的概念, 这一点和 C 很相似,可以将一些方法和结构体关联。
[ 定义结构体 ]
type Test struct{Name stringPower int}
使用关键字 type 定义类型为 struct 的结构体变量 Test
[ 声明和初始化 ]
// 最简单的创建结构体的 方式mTest := Test{Name:"zhang", //注意,每一个结构体成员之间的 , 是必须的power:9000,}// 还可以mTest := Test{}ormTest := Test{Name:"zhang"}mTest.power = 9000// 如果不写字段名, 依赖字段顺序去初始化结构体 (但是为了可读性,你应该把字段名写清楚)mTest := {"zhang", 9000}
拓展:
很多时候,不想让一个变量直接关联到值, 而是想让它的值为 一个指针, 通过指针关联到值
- 一个指针就是内存中的 一个地址
- 指针的值就是实际值的地址
为什么想要指针指向值而不是直接包含该值 ?
- 归结到 go 中函数传递参数的方式 : 镜像复制 ```go package main import “fmt”
type Test struct{
Name stringpower int
}
func super(m Test){ m.power += 100 // equals m.power=m.power+100 }
func main(){ var mTest Test = Test{Name:”zhang”,power:900} super(mTest) fmt.Println(mTest.power)
}
// 运行 zhang@ubuntu:~/go/src/struct01$ go build main.go zhang@ubuntu:~/go/src/struct01$ ls main main.go zhang@ubuntu:~/go/src/struct01$ ./main 900
// 结果是 900 而不是预期的 1000 // 因为 super 函数修改了原始值 mTest 的复制版本, 而不是它本身 // 所以 super 函数中的修改并不影响上层调用者
// 为了实现预期, 采用 指针传递
func super2(m *Test){ m.power +=100 }
func main(){ //var mTest Test = Test{Name:”zhang”,power:900} var pTest *Test = &Test{Name:”zhang”,power:900} super2(pTest) fmt.Println(pTest.power) }
// 运行 zhang@ubuntu:~/go/src/struct01$ go build -o main2 zhang@ubuntu:~/go/src/struct01$ l main main2 main.go zhang@ubuntu:~/go/src/struct01$ ./main2 1000
关于代码修改:<br />使用 `&` 操作符获取了 Test{Name:"zhang",power:900} 结构体的地址<br />之后修改 函数传参类型为 ` *Test` 为 Test 类型的指针- 用指针实际上仍然传递了 一个 pTest 的值的副本给 super 函数- 但是此时 **_pTest 的值是一个地址, pTest 是一个指针变量_**- 所以 pTest 副本的值 和 原来pTest 的值是一样的,都是一个存放 power int 变量值的地址- 类比理解:- 间接传值, 就好像复制了一个指向饭店的标志牌, 你所拥有的是一个标志牌的副本,**但是标志牌还指向原来的方向**,然后根据标志牌找到饭店进行了修改- 而原来的直接传值,你复制了一个饭店副本,修改的只是自己的数据,原来的数据没有发生改变```gofunc super(m Test){m.power += 100 // equals m.power=m.power+100fmt.Println("fuben:",m.power) //这个地方是副本 1000}func main(){var mTest Test = Test{Name:"zhang",power:900}super(mTest)fmt.Println(mTest.power) // 原来的还是 900}zhang@ubuntu:~/go/src/struct01$ go run main.gofuben: 1000900
[ 关于指针传指 ]
- 复制一个指针 比 复制一个复杂的结构的消耗小的多
- 64 bit 机器上一个指针占据 64 bit 的空间
- 指针的真正价值在于能够分享它所指向的值。
[ 结构体上的函数 ]
可以把一个方法关联在一个结构体上:
package mainimport("fmt")type Test struct{Name stringpower int}func (m *Test ) super() {m.power += 1000}func main(){var mTest *Test = &Test{Name:"zhang",power:900}mTest.super()fmt.Println(mTest.power)}// 运行zhang@ubuntu:~/go/src/struct02$ go run main.go1900zhang@ubuntu:~/go/src/struct02$
怎么理解 func (m *Test ) super() { } 函数的定义 ?
可以理解为 *Test 类型是 super() 方法的接受者
然后通过 mTest.super() 方法去调用
[ 结构体的字段 ]
字段可以是任何类型
- 包括其他结构体类型以及 array、maps、slice、interfaces 和 functions 等
拓展 Test 结构体
type Test struct{Name stringpower intFather *Test}// 初始化var mTest Test = &Test{Name:"zhang", power:1000,Father:&Test{Name:"f",power:1,Father:nil,}, }或者mTest := &Test{Name:"zhang", power:1000,Father:&Test{Name:"f",power:1,Father:nil,}, }
组合
go 支持组合,-> 将一个结构 包含进另一个结构的行为
- java 中通过 继承 来拓展结构
public class Person{private String name;public String getName(){return this.name;}}// Test 类中包含着 Person 对象public class Test{private Person person;// 将请求发送到 Person 中public String getName(){return this.person.getName();}...}// 可能会比较繁琐, Person 的每个方法都需要在 Test 中重复
go 看上去更简洁
package mainimport "fmt"type Person struct{Name string}func (p *Person) Introduce() {fmt.Printf("hi,i am %s \r\n", p.Name)}type Test struct{person *Personpower int}// usefunc main(){mTest := &Test{person: &Person{"z"},power:100,}mTest.person.Introduce()}
- 所以组合实际上是一种好的组织代码的方式
7.2 Array 数组
go 是静态语言,所以数据类型在编译之前确定
像数组,编译之前确定长度,一旦声明时指定长度,则长度值不可变
var scores [10]int //声明 初始化没赋值,默认为 {0,0,0....}scores[0] = 100 //赋值// 也可以在 初始化数组的时候赋值var scores = [4]int{1,2,3,4}orscores := [...]int{1,2,3,4}
- go 中数组下标也是 0 开始
数组很高效、但是由于长度确定有时会显得非常 呆板
很多时候事先不知道 数组的长度是多少
比如写一个求和函数 func returnSum() int{} 传入的参数怎么确定呢 ?? 如果只能做固定数量的求和,真的就呆板
所以 —> 引入 切片 slice
7.3 Slice 切片
go 语言中其实很少直接的 使用数组
- 取而代之的是使用
slice切片
关于 slice:
- 切片是轻量的包含并表示数组的一部分结构
引入切片:
需求: 想要实现一个求和函数
func arraySum( x [3]int ) int {sum := 0for _,v := range x{sum = sum +v}return sum}// 弊端就是,只能接收 [3]int 的数组类型, 其他都不支持// 因为 go 中数组的长度也作为类型的一部分// 而且 数组不支持动态扩容 // 这就有点扯犊子了/*a := [3]int{1,2,3}之后就不能继续往 a 中添加新元素了,*/
解决办法: 切片 slice
[ 什么是切片 ]
- 切片 slice 是一个拥有 相同类型元素的 可变长度 的序列
- 基于数组类型 Array 的一层封装,使用灵活
- 支持 自动扩容
- 是 引用类型 , 内存结构包含: 地址、长度、容量
- 不支持直接比较, 只能直接和 nil 比较
- slice 并发不安全
正式解释:
- slice 切片就是对 数组 Array 的一个连续片段的引用
- 这个片段可以是 整个数组, 也可以是 由起始和终止索引标识的一些项的子集
- 注意: 终止索引标识的项不包含在切片内, 即左闭右开区间 [ )
还不懂 ?
看图 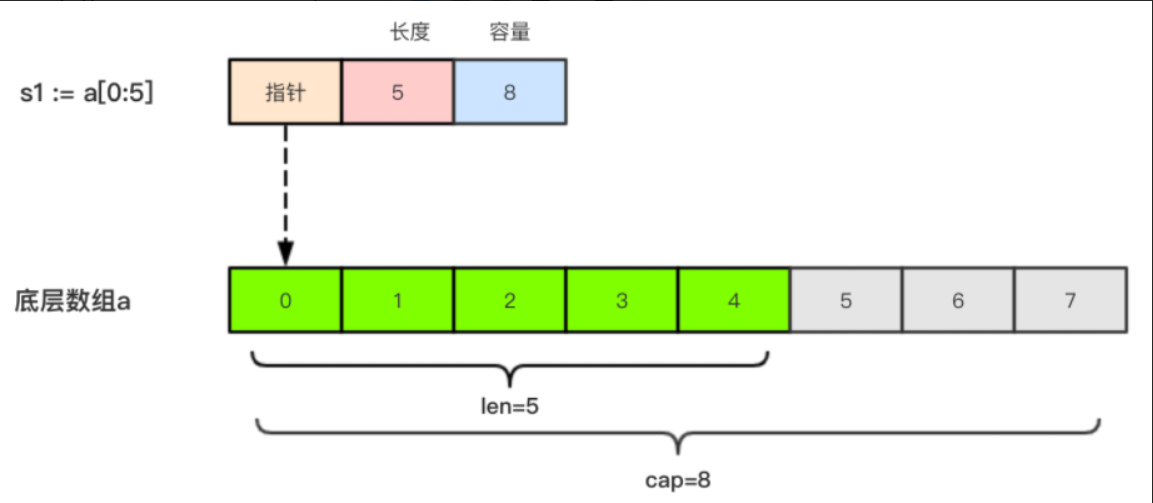
[ 切片定义 ]
切片声明:var name []数据类型
- name:变量名
- 例如: var test []int ```go // 声明切片 slice var a []string //声明一个字符串 切片 var b = []int{} //声明一个整型 切片并且初始化 var c = []bool{true,false} var d = []bool{true,false}
fmt.Println(len(a)) //0 fmt.Println(b) //[] fmt.Println(c) //[true false] fmt.Println( a== nil ) // true fmt.Println( c==d ) //false // slice can only be compared to nil // 切片是引用数据类型, 不支持直接比较, 只能和 nil 比较
<a name="WkpS6"></a>### _[ 基于数组构造切片 ]_也被称为**_ "切片表达式"_**<br />切片底层是数组, 所以 切片可以基于数据通过切片表达式得到- 左包含,右不包含- 切片长度 = high - low- 容量:得到的切片的底层数组的容量- 切片容量 cap = max-low //max是对应的底层数组的最大长度有两种变体- 1、指定 low 和 high 两个索引界限值的简单形式,- 2、**_除了 low 和 high 之外 还指定容量的完整的形式。_**简单形式<br />`var slice1 []int = array[low:high]` // array := [5]int{1,2,3,4,5}完整形式:<br />`var slice2 []int = array[low:high:max] ````go// 简单定义测试package main// 切片定义import "fmt"func main(){ac := [5]int{1,2,3,4,5} // 定义 [5]int 类型的数组 acfmt.Println("ac's cap ", cap(ac) ) //ac's cap 5s := ac[1:3] // s:=a[low:high] // 左开右闭,对应截取 下标1到2 ,也就是数字 2和3fmt.Printf("s:%v, len(s):%v cap(s):%v, \r\n",s,len(s),cap(s))// s:[2 3], len(s):2 cap(s):4,}
为什么 cap(ac) = 5
而基于 ac 的切片 s :cap(s) = 4 ???
上图吧: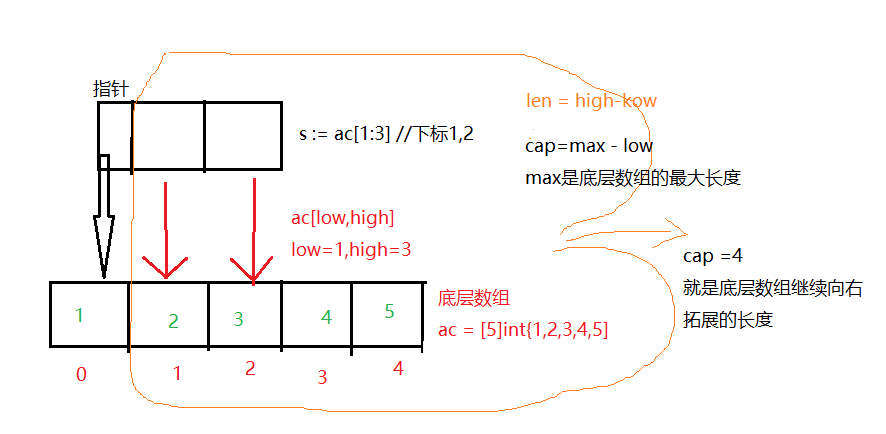
cap 返回的是 数组切片分配的空间的大小,
- 或者理解为对应的底层数组可供继续拓展的空间大小
// 完整定义测试
package main
import "fmt"
func main(){
var aa [6]int = [6]int{1,2,3,4,5,6}
var slice2 []int = aa[1:3:5]
// 1:3 对应下标 1~2 ,对应数字 2,3 max=5 代表底层对应的数组的最大长度是5
// len=high-low=2 cap=max-low=4
fmt.Printf("slice2: %v,len=%d,cap=%d\r\n",slice2,len(slice2),cap(slice2))
// slice2: [2 3],len=2,cap=4
}
为了便利, 也可以省略切片表达式中的索引值
- 省略了 low, 则默认为 0
- 省略了 high,则默认为切片操作数的长度, ```go a[2:] // 等同于 a[2: len(a)]
a[:3] // 等同于 a[0:3]
a[:] // 等同于 a[0: len(a)]
对于数组或字符串, 如果 0 <=low <=high <=len(a) ,则索引合法,否则就会索引越界(out of range)。
// high 可以 <= len 是因为 索引的右边取不到,索引范围是 [ low, high )
```go
test := "he"
fmt.Println(len(test)) //2
fmt.Printf("%c",test[1]) //e ascii 码是101
// test[2] 就会报 out of range
[ 直接构造切片 ]
var sliceName []类型 = []类型{}
// 创建切片
var scores []int = []int{1,4,23,8,4} // 数据类型是 []int
or
scores := []int{1,4,23,8,4}
// 和数组有所区别的是, 定义切片时没有在 [] 中定义长度
[ make函数构造切片 ]
slice := make([]数据类型, size, cap)
- size:切片中 元素的数量
- cap:切片的容量 ```go // 另外还可以使用 make() 函数来构建 slice var scores []int = make([]int, 10) or scores := make([]int, 10) // 指定长度, 省略了容量cap, 默认 cap=len
// demo: test := make([]int, 2, 10) //元素2个,容量10个 fmt.Println(test) // [0,0]
//内部存储空间已经分配了10个,但实际上只用了2个。
使用 `make` 关键字来代替 new,是**_因为 创建一个切片不仅是只分配一段内存 _** (这个是 new 关键字的功能)<br />具体讲:
- 必须为 底层数组分配一段内存, 同时也要初始化这个切片
- scores :=make([]int, 10) //初始化了一个 长度是10,容量是 10的切片slice
- **_长度是切片的长度_**
- **_容量是 底层数组的长度_**
- 在使用 make 创建切片时,我们可以分别的指定切片的长度和容量:
- `score := make([]int, 0 , 10)` //创建长度0, 容量 10 的切片
---
<a name="m1MzC"></a>
### _[ 切片的容量和长度 ]_
内置函数
- len() 求车行度
- cap() 求切片的容量
`**数组**`中由于 长度是固定不变的,`所以 len(arr)和 cap(arr) 输出永远相同`
---
实例:
```go
package main
import (
"fmt"
)
/*
description:关于 slice 的 make 创建方式
author:Hao Zhang
data:2021-06-13
*/
func main(){
scores := make([]int,0,10)
//scores[7] = 13
//fmt.Println(scores)
/*
运行失败
goroutine 1 [running]:
main.main()
D:/Env/golang/GOPATH/src/slice01/make01/main.go:13 +0x52
原因是 分配的slice切片的查那个度是 0,
底层数组可以放 10 个元素,但是我们需要显式的扩展切片,才能访问到底层数组的元素。
*/
// 1、通过关键字 append 来实现
scores = append(scores,5)
fmt.Println(scores) //prints [5]
// 重新切片
scores =scores[0:8]
scores[7]=100
fmt.Println(scores) //[5 0 0 0 0 0 0 100]
}
[ 切片的本质 ]
切片的本质是 —> 对底层数组的封装
包含了 3 个信息:
- 底层数组的指针
- 切片的长度 len
- 切片的容量 cap
slice 底层的结构体:
type slice struct{
array unsafe.Pointer
len int // 长度
cap int // 容量
}
举例:
a := [8]int{0,1,2,3,4,5,6,7}
切片 b := a[:5] //0~5 取下标 0,1,2,3,4// 对应数字 0,1,2,3,4,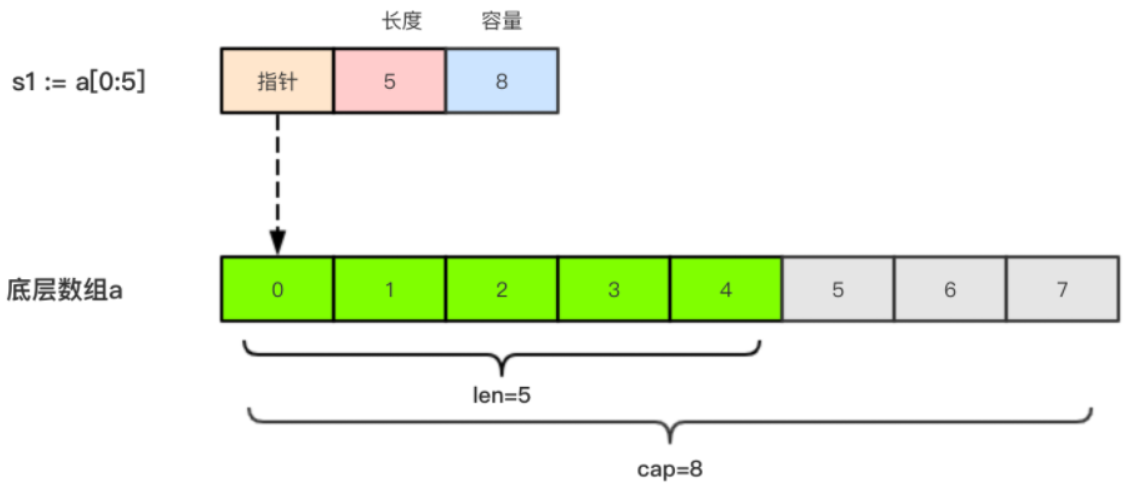
如果 切片是 s2 := s1[3:6]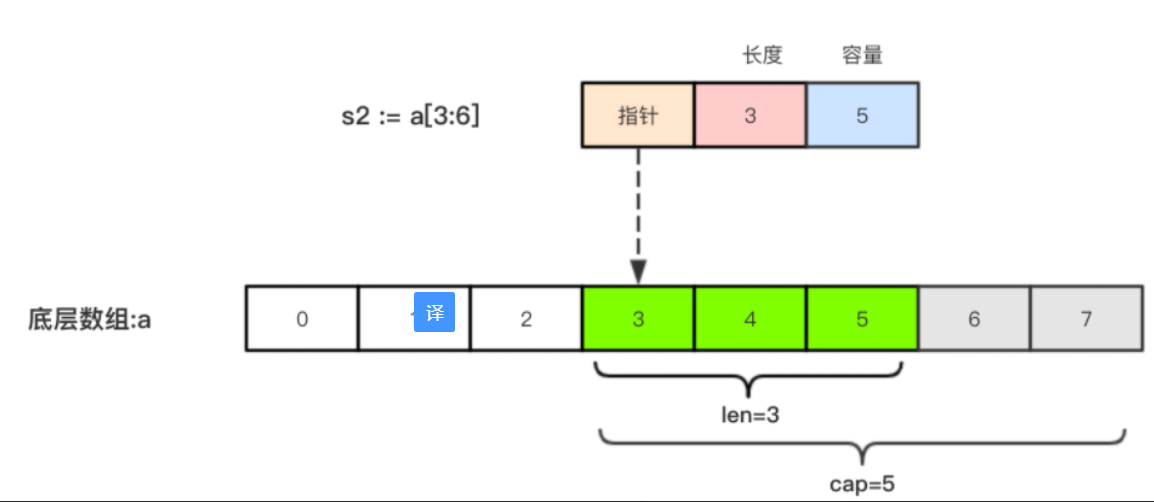
所以说: 如果是从数组上截取的切片的容量 cap 是从截取位置到数组末尾的长度
cap = max - low = 8-3=5
[ 切片判空 ]
检查切片是否为空, 用len(s) == 0 来判断, 不能用 s==nil 判断
一个 nil 值的切片并没有底层数组
- 一个 nil 值的切片的长度和容量都是 0,
- 但是不能说一个 长度和容量都是0的切片一定是 __nil
怎么理解 ?
s := []int{} // 直接定义初始化了, len 和 cap 都是0 ,但是不为 nil
怎么理解 不能用 s==nil 判断切片为空 ?
slice 有可能已经被 初始化s := []int{} // 直接声明的时候就可以初始化
/* 测试为什么 不能用 nil 判空slice */
var slice1 []int // nil
slice2 := []int{} //短变量缩略声明 并 初始化
fmt.Println("slice1 == nil:", slice1 ==nil) // nil == true
fmt.Println("slice1 len:", len(slice1))
fmt.Println("slice2 == nil:", slice2 ==nil) // nil == false 但是长度为 0, 没有元素
fmt.Println("slice2 len:", len(slice2))
//slice1 == nil: true
//slice1 len: 0
//slice2 == nil: false
//slice2 len: 0
[ 切片的赋值拷贝 ]
- 拷贝前后的两个 slice 变量是共享一个 底层数组的
- 所以对 一个切片的修改 会 影响另一个切片的内容 ```go / slice 拷贝赋值前后slice 共享一个底层数组, 对一个切片的修改会影响另一个变量 /
sss := make([]int, 3,) // 3是size,元素的数量 [0,0,0] 没有 定义cap容量的话, 默认=size sss2 := sss // sss2 是 sss 的赋值拷贝 sss2[0] = 100 // 对 sss2[0] 修改也会影响到 sss[0] 的值 //!!! fmt.Println(sss) // [100 0 0] fmt.Println(sss2) // [100 0 0]
<a name="OZ1t8"></a>
### _[ 切片遍历 ]_
切片的遍历方式和数组是 一致的,
- 支持 **索引遍历**
- 和 **for range 遍历**
```go
/* slice 的遍历: 1、索引遍历 2、 for range 循环 */
ssss := []int{1,3,5}
for i:=0; i<len(sss);i++{
fmt.Println(i, ssss[i])
}
for index,value := range ssss{
fmt.Println(index,value)
}
//0 1
//1 3
//2 5
//0 1
//1 3
//2 5
[ 切片方法 ]
[ append 追加切片 ]
go 语言中的内建函数 append() 可以为切片slice 动态的添加元素 ~
- 可以一次添加一个元素
- 可以添加多个元素
- 可以添加 添加另一个切片中的元素( 后面加
**…**)
//demo
/* test append to malloc slice */
//也可以添加另一个切片中的元素(后面加…)
var sappend []int
sappend = append(sappend, 1) //向后扩容 , 之后为 [1]
sappend = append(sappend,2,3,4) // [1 2 3 4]
sappend2 := []int{5,6,7}
sappend = append(sappend2,sappend...) // [5 6 7 1 2 3 4 ]
fmt.Println(sappend)
注意 attention :
通过var 关键字声明的 零值切片可以在 append 中直接使用, 而无需初始化
var s []int
s = append(a,1,2,3) // [1,2,3]
// 关于 slice 切片的 append 问题:
关于容量 cap,为什么
//为什么 append 之后 cap != 8+5=13 ???
/* test append to malloc slice */
//也可以添加另一个切片中的元素(后面加…)
var sappend []int
sappend = append(sappend, 1) //向后扩容 , 之后为 [1]
fmt.Println("sappend 1 : cap =,len=",cap(sappend), len(sappend)) //cap=1 len=1
sappend = append(sappend,2,3,4) // [1 2 3 4]
fmt.Println("sappend 2 : cap =,len=",cap(sappend), len(sappend)) //cap=4 len=4
sappend2 := []int{5,6,7}
sappend = append(sappend2,sappend...) // [5 6 7 1 2 3 4 ]
fmt.Println("sappend 3 : cap =,len=",cap(sappend), len(sappend)) //cap=8 len=7
sstest := make([]int,5) // 和上述不一样的是 make 构建的,省略了cap, 默认 cap=len=5
fmt.Println("sstest:cap // len",cap(sstest), len(sstest)) // cap = len = 5
sappend = append(sappend,sstest...) //为什么 append 之后 cap != 8+5=13 ???
fmt.Println("sappend 4 : cap =,len=",cap(sappend), len(sappend)) //cap = 16 len=12
个人猜测和 slice 的扩容策略有关:
- 待解决
package main
import "fmt"
func main(){
var slice1 []int
slice1 = append(slice1,1,2,3,4) //cap=len=4
slice2 := []int{5,6,7} //cap=len=3
slice1 = append(slice1,slice2...) //len=7, cap=8
// 长度 len=7=3+4 没什么好说的
// cap=8 是因为 append 追加切片元素时底层数组的 cap=4不足以容纳新元素
// 触发底层扩容策略 ,小于1024字节扩容为原有容量的2倍,
// cap = 4*2 =8
slice3 := make([]int,5) // == make([]int,5,5) 只指定len, 容量cap默认=len
fmt.Println(len(slice3),cap(slice3)) //len=cap=5
fmt.Println(len(slice1),cap(slice1))
// cap 仍然不够, cap*2=16
slice1 = append(slice1,slice3...)
fmt.Printf("slice1: %v, len=%v, cap=%d\r\n",slice1,len(slice1),cap(slice1))
// slice1: [1 2 3 4 5 6 7 0 0 0 0 0], len=12, cap=16
}
注解:
每个 切片slice 会指向一个底层数组, 这个底层数组的容量 够用就添加新元素。
- 当底层数组不能继续容纳新增元素时, 切片就会按照一定的 策略 进行扩容
- 此时, 该切片指向的底层数组 就会发生变换
- “扩容” 操作往往发生在 append 函数调用时,
- 所以我们通常都需要 用原变量接收append函数的返回值 。
/* slice 在 append 调用时的扩容 */
var numSlice []int
for i:=0;i<10;i++{
numSlice = append(numSlice, i)
fmt.Printf("%v len:%v cap:%d ptr:%p \r\n",numSlice,len(numSlice),cap(numSlice),numSlice)
}
// 输出结果 ,results
[0] len:1 cap:1 ptr:0xc00000a188
[0 1] len:2 cap:2 ptr:0xc00000a1a0
[0 1 2] len:3 cap:4 ptr:0xc000010240
[0 1 2 3] len:4 cap:4 ptr:0xc000010240
[0 1 2 3 4] len:5 cap:8 ptr:0xc00000e2c0
[0 1 2 3 4 5] len:6 cap:8 ptr:0xc00000e2c0
[0 1 2 3 4 5 6] len:7 cap:8 ptr:0xc00000e2c0
[0 1 2 3 4 5 6 7] len:8 cap:8 ptr:0xc00000e2c0
[0 1 2 3 4 5 6 7 8] len:9 cap:16 ptr:0xc000126100
[0 1 2 3 4 5 6 7 8 9] len:10 cap:16 ptr:0xc000126100
Process finished with the exit code 0
// 发现每一次扩容过之后 地址都发生了变化
// cap是 1 2 4 8 16 的 x2 扩容
// 按照二倍增长后capacity依然不够用时,会将capacity设置为当前数组的length+1.
// - append() 函数将 元素追加到 slice 切片的最后 并 return 该 slice
append() 函数还支持 一次性 追加多个元素 ~~
var citySlice []string
// 追加一个元素
citySlice = append(citySlice,"北京") // 追加一个元素
citySlice = append(citySlice,"上海","广州","深圳") //追加多个元素
as := []string{"成都","重庆"} // 追加 切片
citySlice = append(citySlice,as...)
fmt.Println(citySlice) //[北京 上海 广州 深圳 成都 重庆]
[ copy 复制切片]
直接赋值就完了,为什么还要用 copy() 进行复制呢 ?
// slice copy demo:
// 1、直接赋值
acopy := []int{1,2,3,4,5}
bcopy := acopy
fmt.Println(acopy) //[1 2 3 4 5]
fmt.Println(bcopy) //[1 2 3 4 5]
bcopy[0] = 1000
fmt.Println(acopy)
fmt.Println(bcopy)
//[1000 2 3 4 5]
//[1000 2 3 4 5]
发现改变 bcopy 的同时把 acopy 的值也给改了
这是因为:
- 切片是
引用类型 - 所以 acopy 和 bcopy 其实都指向了同一块 内存地址
- 修改 bcopy 的值同时 acopy 的值也会发生变化,
go 的内建函数 copy 可以迅速的将一个 切片的数组复制到另一个切片空间中 。copy(destSlice []Type, srcSlice []Type)
- srcSlice :数据来源切片
- destSlice:目标切片
/* copy 的使用, slice */
aaaaCopy := []int{1,2,3,4,5}
ccccCopy := make([]int,5,5) // size=5, len=5
copy(ccccCopy, aaaaCopy) // aaaaCopy 复制给 ccccCopy
fmt.Println(ccccCopy) // [1 2 3 4 5]
fmt.Println(aaaaCopy) // [1 2 3 4 5]
ccccCopy[0] = 1000
fmt.Println(ccccCopy) // [1000 2 3 4 5]
fmt.Println(aaaaCopy) // [1 2 3 4 5]
// 这样 copy 而不是直接赋值的话,就不会影响 两个 slice 的值
[ 切片删除元素 ]
go 语言中没有 删除元素的 专用方法
- 所以使用 切片本身的 特性来删除元素
- 原理就是 切片 append 还有构建时的 [ ) 左闭右开, high是不含的
- a = append( a[:index], a[index+1:]…) 就把 index 下标的元素删掉了
// slice 删除元素 demo:
adelete := []int{30,31,32,33,34,35,36,37}
// 比如: 要删除索引 为 2 的元素
adelete = append(adelete[:2], adelete[3:]... ) // adelete[:2]相当于 adelete[0:2]
// adelete[3:] 相当于 adelete[3:len(adelete)]
// 把 adelete的 3:len 的 33,34,35,36,37 append 添加到 adelete 的 0~2, 30, 31
fmt.Println(adelete) // [30 31 33 34 35 36 37]
// 总结就是:要从切片 a 中删除索引为 index 的元素,
// 操作方法是: a = append( a[:index], a[index+1:]...) 就把 index 下标的元素删掉了
7.4 Map 映射
go 语言的映射, 相当于其他语言的 hash 表或者 字典
- 是一种无序的 基于 key-value 的数据结构
- 映射是动态变化的 ~
- go语言的 映射map是 引用类型,必须初始化才能使用。
工作方式:
- 定义键和值,并且可以获取,设置和删除其中的值。
映射 map 和 切片一样,使用make 来创建
[ make创建map ]
// make( map[keyType]valueType, [cap]) // cap 是容量
// cap 参数不是必须, 但是我们应该在初始化map的时候就为其指定一个合适的容量
// 1、不指定 map 的初始大小
var lookup map[string]int = make(map[string]int)
or
lookup := make(map[string]int)
lookup["z"] = 900
value, ok := map[key] 查看是否存在某 key
power, exists := lookup["w"] // value 是返回的 key 对应的值,不存在返回默认,int 默认 0
fmt.Println(power, exists)
// 打印 0 false
// 2、指定 map 的初始化大小
func main(){
scoreMap := make(map[string]int, 8) // 容量cap =8, key是 string, value是 int
fmt.Println(scoreMap) // map[]
scoreMap["zhang"] = 90
scoreMap["li"] = 60
fmt.Println(scoreMap)
// map[li:60 zhang:90]
fmt.Println(scoreMap["li"]) //60
fmt.Printf("type of a:%T \r\n", scoreMap) //%T 打印 type of a:map[string]int
// %v 打印: type of a:map[li:60 zhang:90]
}
// map 还支持声明的时候就 填充元素
func main(){
userinfo := map[string]string{ // 声明 userinfo 并且同时初始化
"username" : "zhang",
"passwd" : "123",
}
}
- 使用
len方法获取映射的 键的数量 - 使用
delete方法来删除一个键对应的值
映射是动态变化的, 可以通过传递 第二个参数到 make 来设置一个初始大小
scoreMap := make(map[string]int, 8)
fmt.Println(scoreMap,len(scoreMap)) //len获取是键的数量
// map[] 0
/*
陷阱
当一个map变量被创建后,可以指定 map 的容量, 但是不能 cap(s) 求映射map的容量
cap: 返回的是数组切片分配的空间大小, 根本不能用于map
所以 怎么获得 map 的cap容量值呢 ?
*/
[ map删除键值对 ]
delete 格式
delete( map,key)
demo:
delete(Map3,"z")
[ map判断某个键是否存在 ]value, ok := map[key]
// demo
demo:
Map1 := make(map[string]int)
Map1["张"] = 90
Map1["李"] = 80
// 如果 key 存在, ok 为 true, v 为对应的值
// 不存在的话 ok 为false, v为值类型的 零值
v,ok := Map1["王"]
if ok{
fmt.Println(v)
}else {
fmt.Println("----",v)
}
//---- 0
[ map的遍历 ]
用for range 来遍历map
Map3 := make(map[string]int)
Map3["z"] = 99
Map3["l"] = 90
Map3["a"] = 49
for index,value := range Map3{
fmt.Println(index,value)
}
// z 99
// l 90
// a 49
如果只想遍历 key,不需要遍历 value 时, 以下写法:
for k := range Map3{
fmt.Println(k)
}
//z
//l
//a
[ 按指定顺序遍历map ]
[ map作为结构体字段 ]
type Test struct{
Name string
Friends map[string]*Test // map[key]value
}
初始化
test1 := &Test{
Name : "z",
Friends: make(map[string]*Test ), // key 是string value 是 *Test
}
test1.Friends["zz"] = ..... //加载或创建 zz, 类型是 *Test, Test类型的指针
testzz := &Test{}
// go 还有一种定义和 初始化值的方式, 像make
// make 特定用于 数组 和 映射
lookup := map[string]int{
"goku":9001,
"gohan":2044,
}
// 用 for range 迭代
for key,value := range lookup{
// to do
}
注意: map 的 for range 迭代是没有顺序的, 每次迭代查找将会 随机返回键值对
[ 指针类型vs值类型 ]
// 关于 切片
a := make([]Test , 10)
or
a := make([]*Test, 10)
只有当改变 切片和 映射的值的时候, 指针和值传递才会看到区别~
决定使用指针数组还是值数组归结为你如何使用单个值,而不是你用数组还是映射。
[ map探究 ]
c++中map实现基于 红黑树
java实现map:HashMap 、TreeMap、 LinkedHashMap、
go:
- 采用 hash table+ 链表 实现
- 使用链表来解决 hash 冲突的问题
- 所有的 map 公用一份代码
go map 源码在 /src/runtime/map.go
8、构造器
go 里的结构体没有 构造器, 但是可以创建一个 返回所期望类型的实例的函数 (类似于 工厂)
func TestFactory(mname string, mpower int) Test{
return Test{
Name:mname,
power:mpower,
}
}
8.1 New
go 里的结构体缺少构造器, 但是有 new 内置函数
- 可以使用
new函数来分配类型所需要的 内存 memory new(x)与&x{}相同 ```go mTest := new(Test) // same as mTest := &Test{} // 更具有可读性
mTest := new(Test) mTest.Name = “z” mTest.power = 1
// vs
mTest := &Test{ // 可能更直观 Name:”z”, power:1, } ```
9、指针 vs 值
写 go 代码的时候, 有时候会纠结: 是用值传递 还是 用指向值的指针 ?
一般纠结的点是:
- 局部变量赋值
- 结构体指针
- 函数返回值
- 函数参数
- 方法接收器
如果不确定,就用指针
- 值传递是一个使数据不可变的好办法 ( 函数中改变它不会反映到 调用代码中)

若有收获,就点个赞吧
0 人点赞
