本文实践基于 Ververica 开源的 flink-sql-benchmark、flink-sql-gateway、flink-jdbc-driver 项目,基于 Flink 1.10
本文主要基于新发布的Flink 1.10 版本分享以下四个方面的内容:
- 1.10 版本中Batch的相关功能介绍
- 基于Ververica开源工程 (flink-sql-benchmark) 构建 Hive 数仓
- Ververica开源工程(Flink SQL Gateway and JDBC Driver)介绍
- Flink 1.11 展望
作者: 李劲松(之信) · 阿里巴巴 / 技术专家
整理: 苗浩冲(Apache Flink China 社区志愿者)
校对: 赵阳(Apache Flink China 社区志愿者)
1. Flink 1.10 Batch 解析(Hive 的生产级别集成及TPC-DS的全面覆盖)
首先1.10 版本开始支持Hive的生产级别集成,主要体现在:
- 多版本支持,在1.9版本时只支持 hive 的2.3.4 和 1.2 这俩个版本,在1.10版本中支持 Hive 从1.0 到 3.x的大部分版本,社区测试了8个主要的大版本,同时完善了文档、优化依赖和startup,尽量解决用户使用过程中依赖的问题。
- 支持 Hive 内置函数,Flink 之前版本内置函数较少,对从 Hive 迁移过来的用户不友好,因为 Hive 有更多的内置函数,所以 Flink 1.10 开始支持 Hive 内置函数。
- 完整类型支持,Flink 1.10 增加了 timestamp 数据类型的支持。
- Partition 支持,增加了对 Parttion pruning、writing、统计信息等的支持
其次1.10 版本实现了TPC-DS的全面覆盖,目的是让用户方便快速的运行 Batch,主要包括:
- 内存管理,1.9版本时 Operator 的内存由用户配置,用户配置多少Operator就能使用多少,如果 Operator 使用过多内存时,task 会因申请不到足够的内存而挂掉,或者 Operator 配置的内存远远小于 slot 的内存,导致slot 的内存使用率过低。1.10 版本做了很多底层架构的优化,去除了Operator 内存配置,现在是slot有多少内存,Operator就可以使用多少内存。
- ORC 优化(Vectorization),支持了 Hive 2.x 以上版本的向量图
- Shuffile 改进及压缩,对易用性和性能两个方面进行了一定的优化
-
2. 构建Hive数仓(基于 flink-sql-benchmark)
下面使用 flink-sql-benchmark 这个开源工程构建 Hive 数仓, 此实验具体的详细步骤可见工程的
README.md。TPC-DS相关内容见官网 TPC-DS
cloneflink-sql-beachmark 工程至本地,工程地址: flink-sql-beachmarkgit clone https://github.com/ververica/flink-sql-benchmark
生成 Hive 测试数据集
- 环境准备
确保集群中已安装 hadoop 和 hive,同时 gcc 已安装 下载并构建数据生成器
cd hive-tpcds-setup./tpcds-build.sh
生成 TPC-DS 数据集
cd hive-tpcds-setup./tpcds-setup.sh 10000 #其中后面的参数是要产生数据集的大小(单位为 GB 并且必须大于 1GB)
以上脚本将启动一个
Mapreduce任务最终生成text格式的文件,文件默认放置在 HDFS 集群上的 /tmp/tpcds-generate/目录,如果该目录已经存在则 Mapreduce 任务将跳过。数据生成后,数据将会被加载至 Hive 表中,所以请确保通过系统 PATH 路径中能找到 hive 可执行文件,或者你可以通过环境变量 HIVEBIN 来指定 hive 指令。同时以上脚本还会根据 text 格式的文件生成 hive 外部表,这些表属于 tpcds_text 这个数据库,脚本将把 text 格式转换为更优的格式,转换后的表放置在 tpcdsbin_ 这个数据库中,默认的优化格式是 orc. 你可以通过在环境变量中的 FORMAT 参数指定不同的文件存储格式,例如: FORMAT=parquet HIVE_BIN=/path/to/hive ./tpcds-setup.sh 1000
数据加载至 hive 后,就可以使用数据库 tpcds_bin
运行基准测试。
- 查看加载至 hive 中的数据情况并在 sql-client 执行查询任务
- 首先使用 sql-client.sh 进行简单的测试
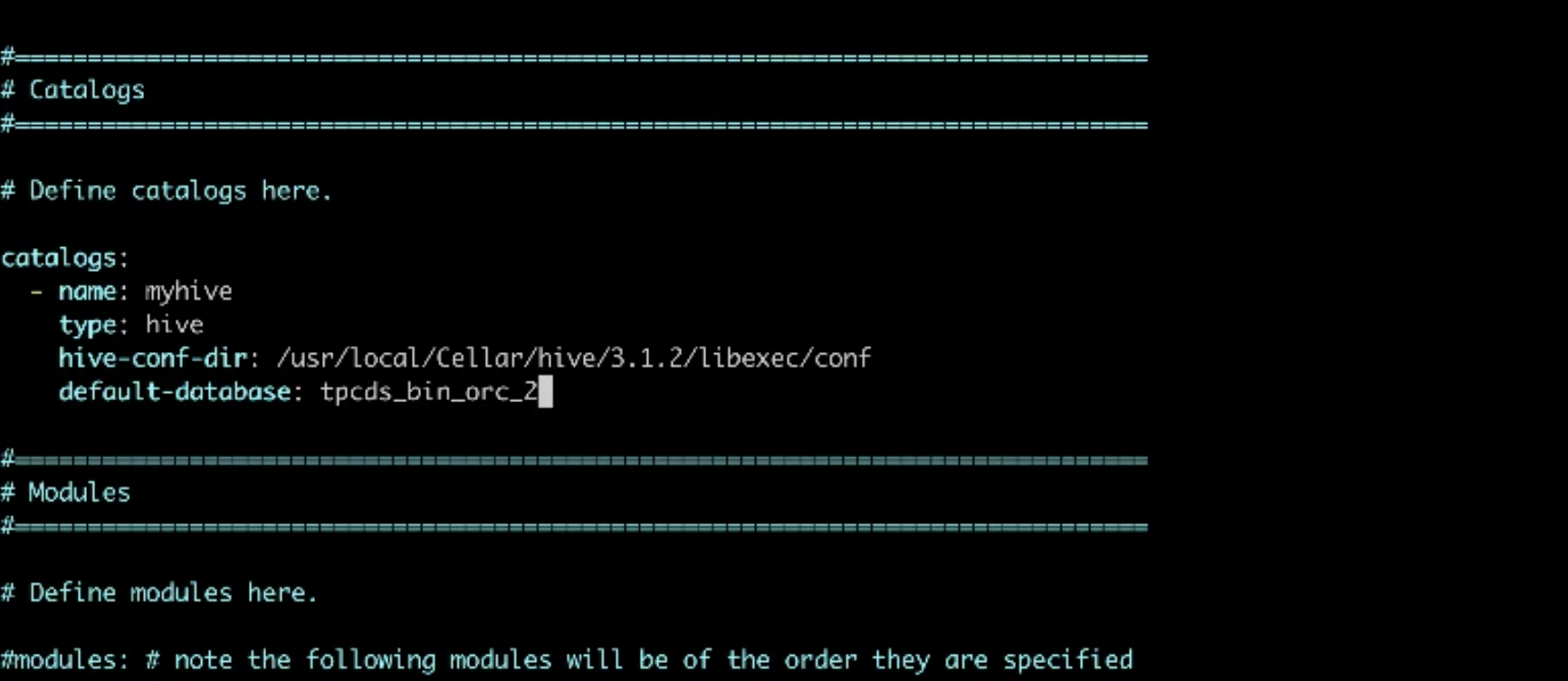
-配置sql-client-defaults.yaml文件中 hive catalogs 项,指定hive 的配置路径和数据库,如下所示:

-运行./bin/sql-client.sh embedded
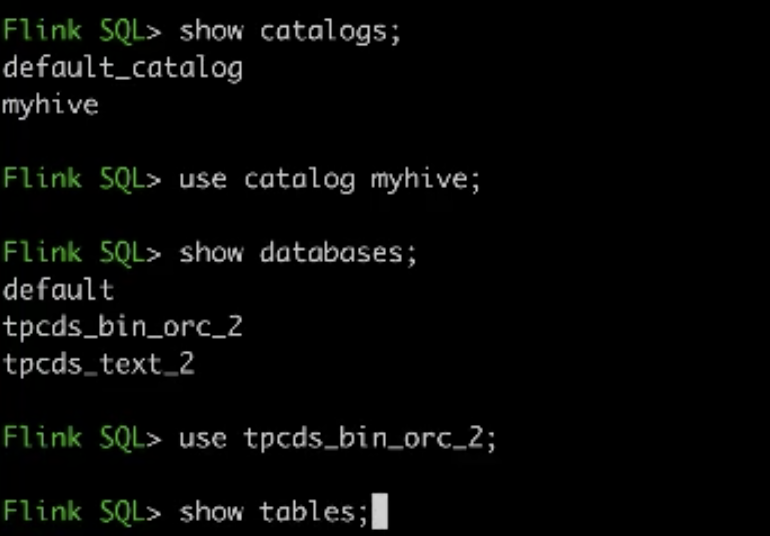
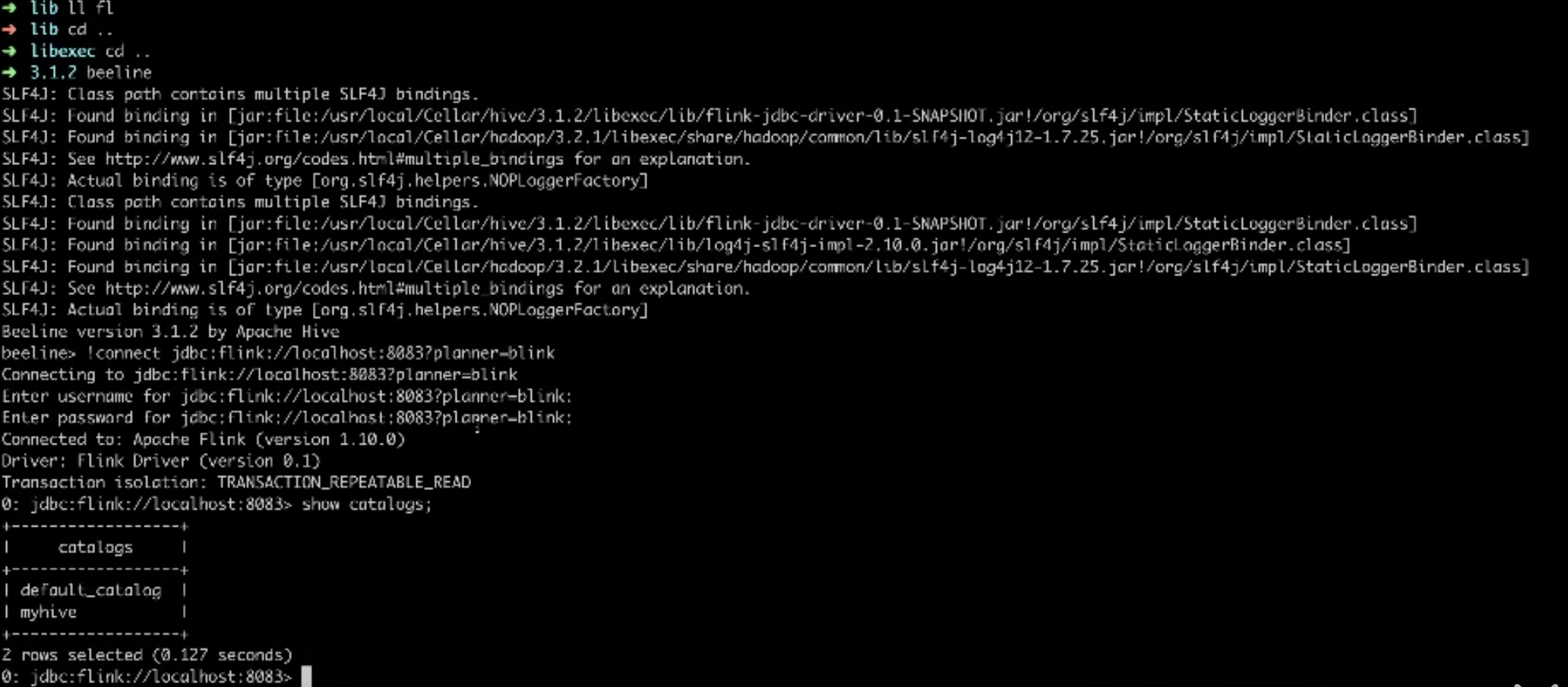
-查看并使用上面配置的 hive catalogsshow catalogs;use catalog myhive
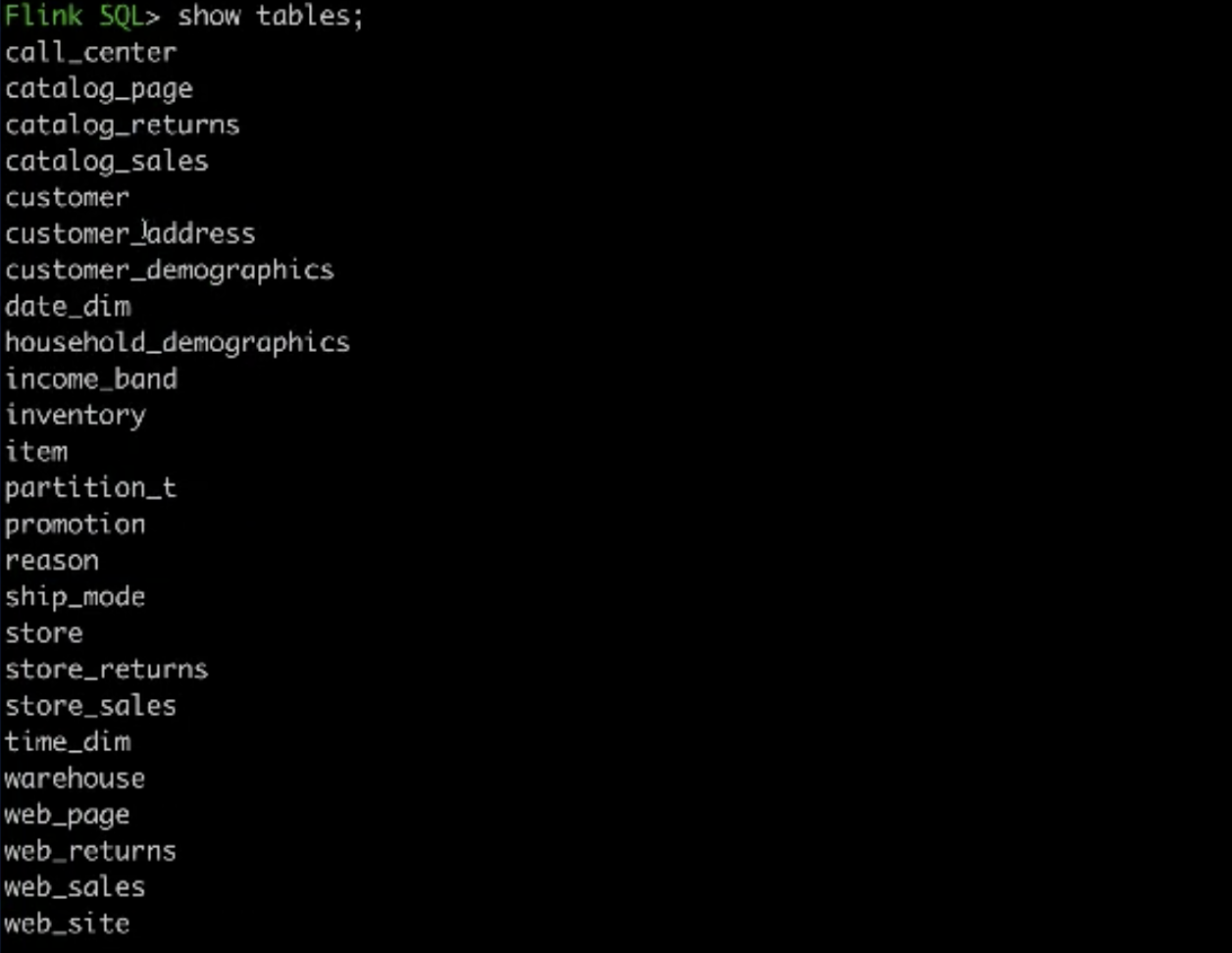
-查看数据库和测试表show databases;use tpcds_bin_orc_2;show tables
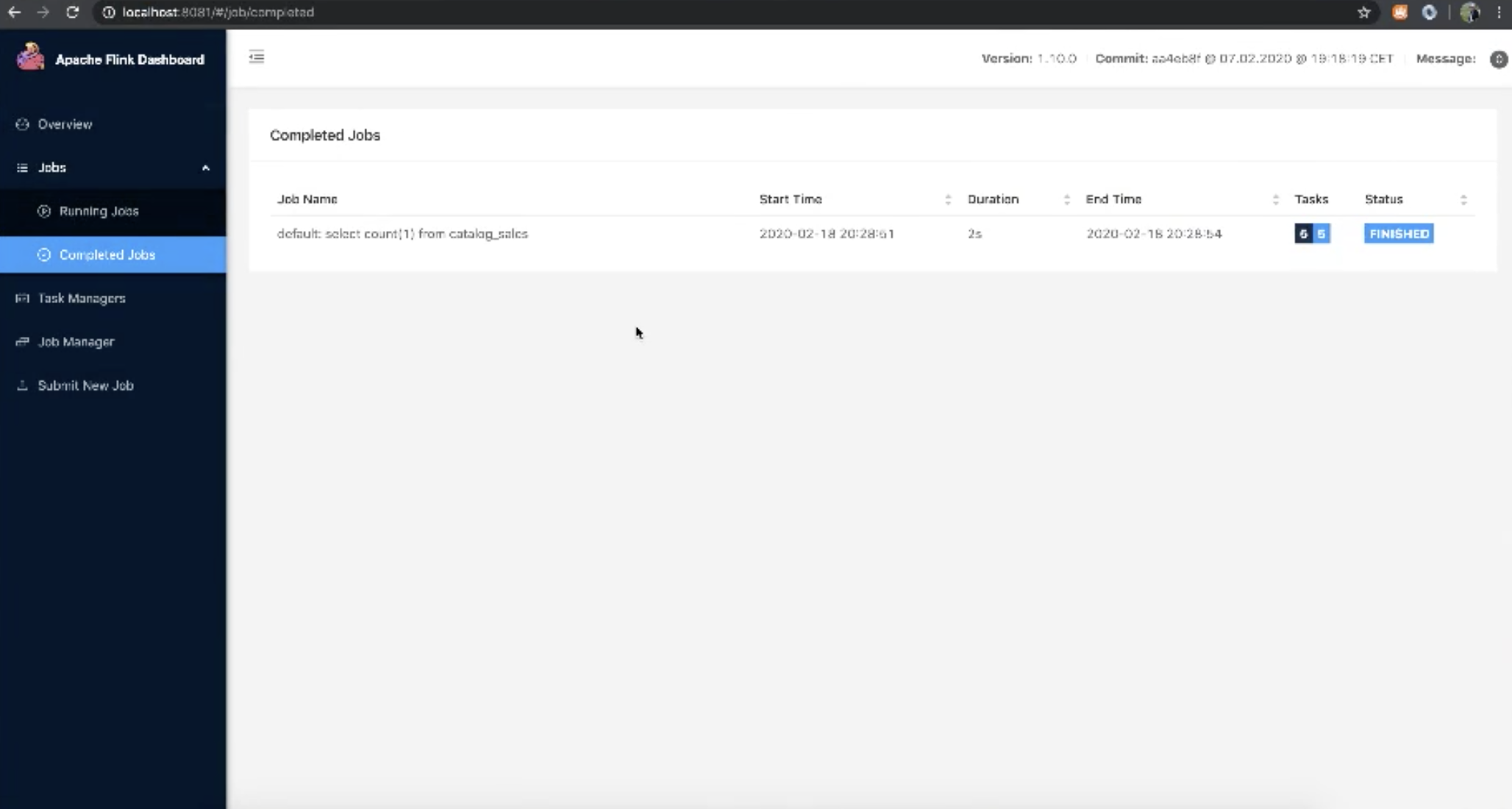
-执行一个简单的查询操作select count(1) from catalog_sales
-查询执行过程中,可通过flink web 页面查看任务详情
-再执行一个复杂的查询,sql语句在工程目录中的位置是:flink-sql-benchmark/flink-tpcds/src/main/resources/queries
-查询执行过程中,可通过flink web 页面查看任务详情
- 在 flink 集群中运行基准测试
- 准备 flink 环境,包括:
-配置 flink-conf.yaml 可参考:Recommended Conf
-安装 hive 依赖:Hive dependencies
-配置集成 Hadoop :Hadoop environment
-配置 flink 集群:Standalone cluster or Yarn session - 构建测试用 jar 包
-修改pom.xml文件中的 flink 和 hive 版本
-mvn clean install - 运行
-flink_home/bin/flink run -c com.ververica.flink.benchmark.Benchmark ./flink-tpcds-0.1-SNAPSHOT-jar-with-dependencies.jar --database tpcds_bin_orc_10000 --hive_conf hive_home/conf
-选项 —location : sql 查询路径,默认用 jar 中的查询
-选项 —queries : sql 查询名称,如果值是 all ,所有的查询都会被执行,比如:q1.sql
-选项 —iterations : 每个案例运行几次,默认是一次
-选项 —parallelism : 并发度,默认是 800 - 执行过程中,可在 flink web 页面查看任务进度
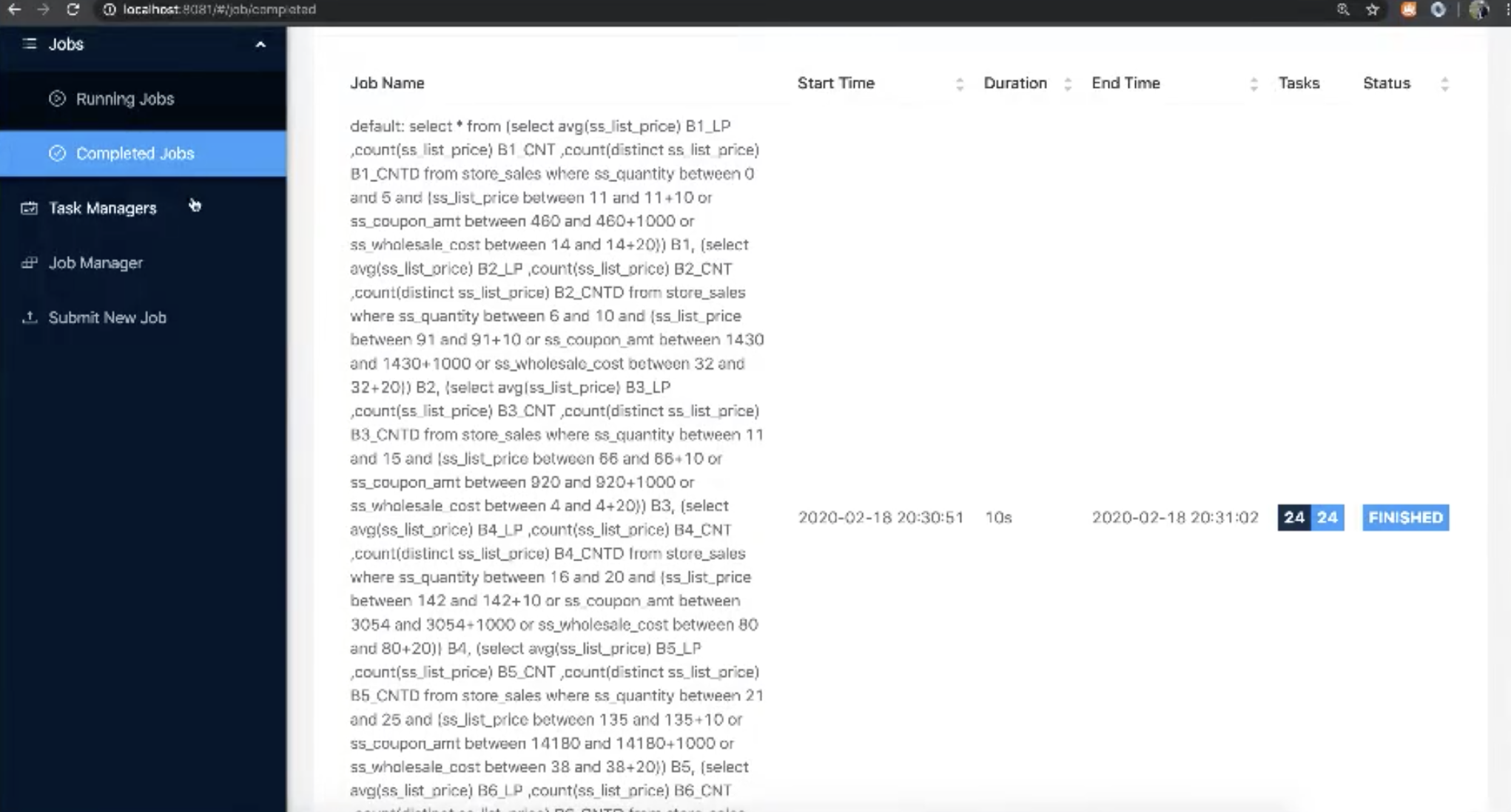
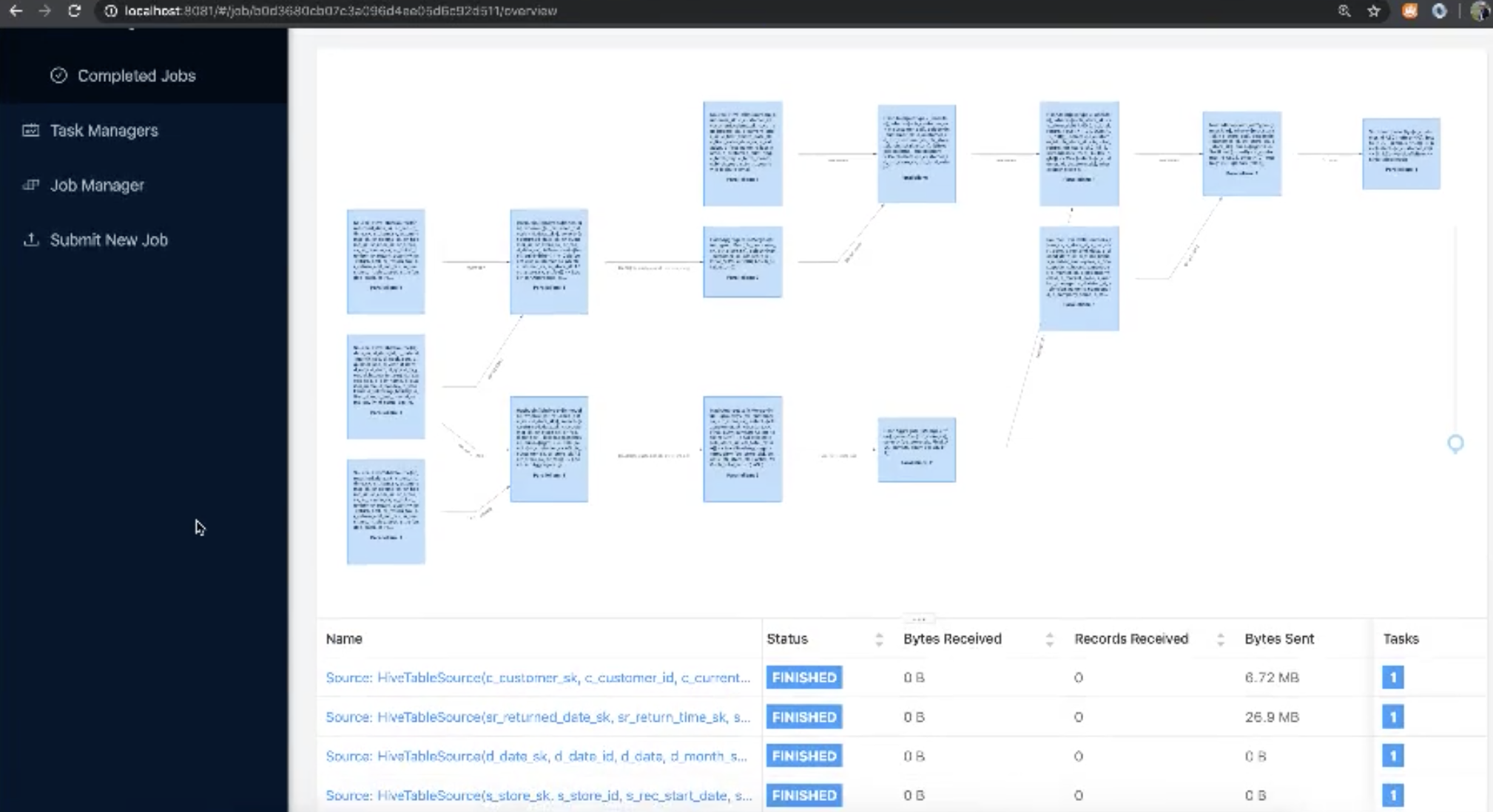
- 该任务会依次执行 jar 包中的103个查询,最后输出查询结果和每条查询所花费的时间
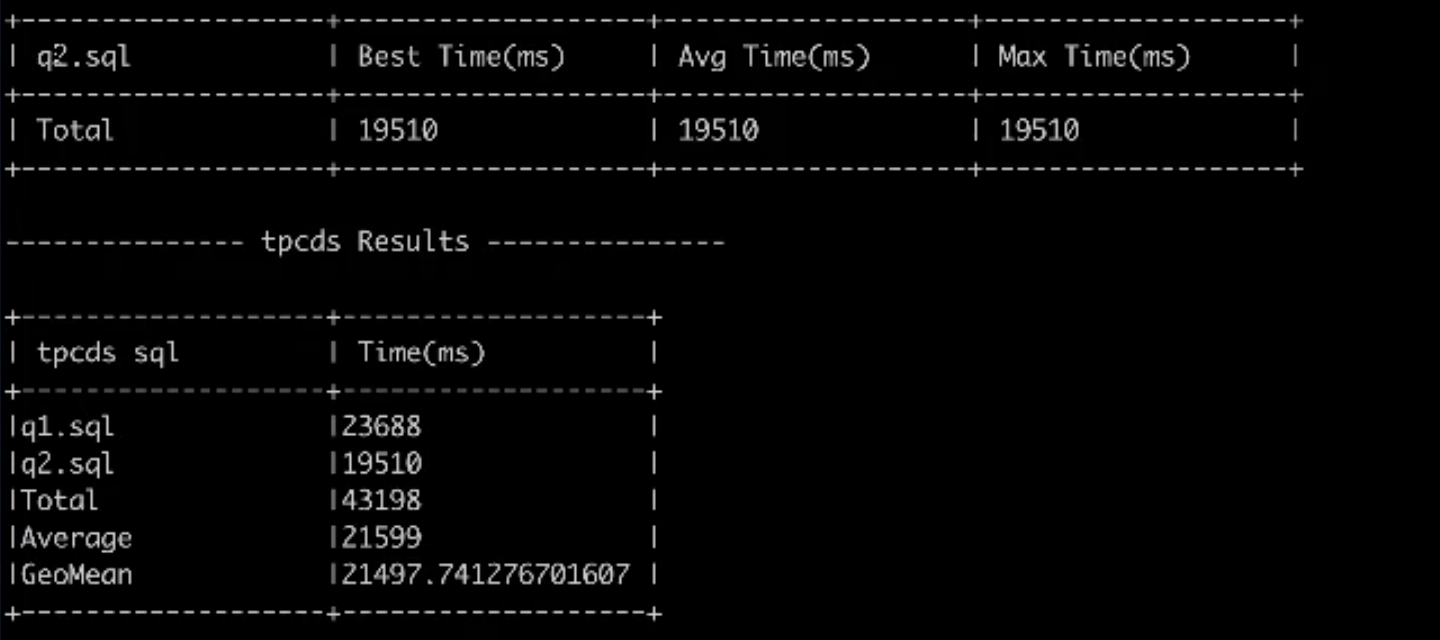
- 使用其他分析引擎运行
由于生成的数据是 Hive 的标准数据集,大家可以使用其他分析引擎进行基准测试,此文不再展开细说。下图是对 HiveOnMR、HiveOnTez、Flink 做的性能结果对比:

图1.性能测试结果比较
下图是以上整个操作流程的示意图,整个过程算是比较简单的: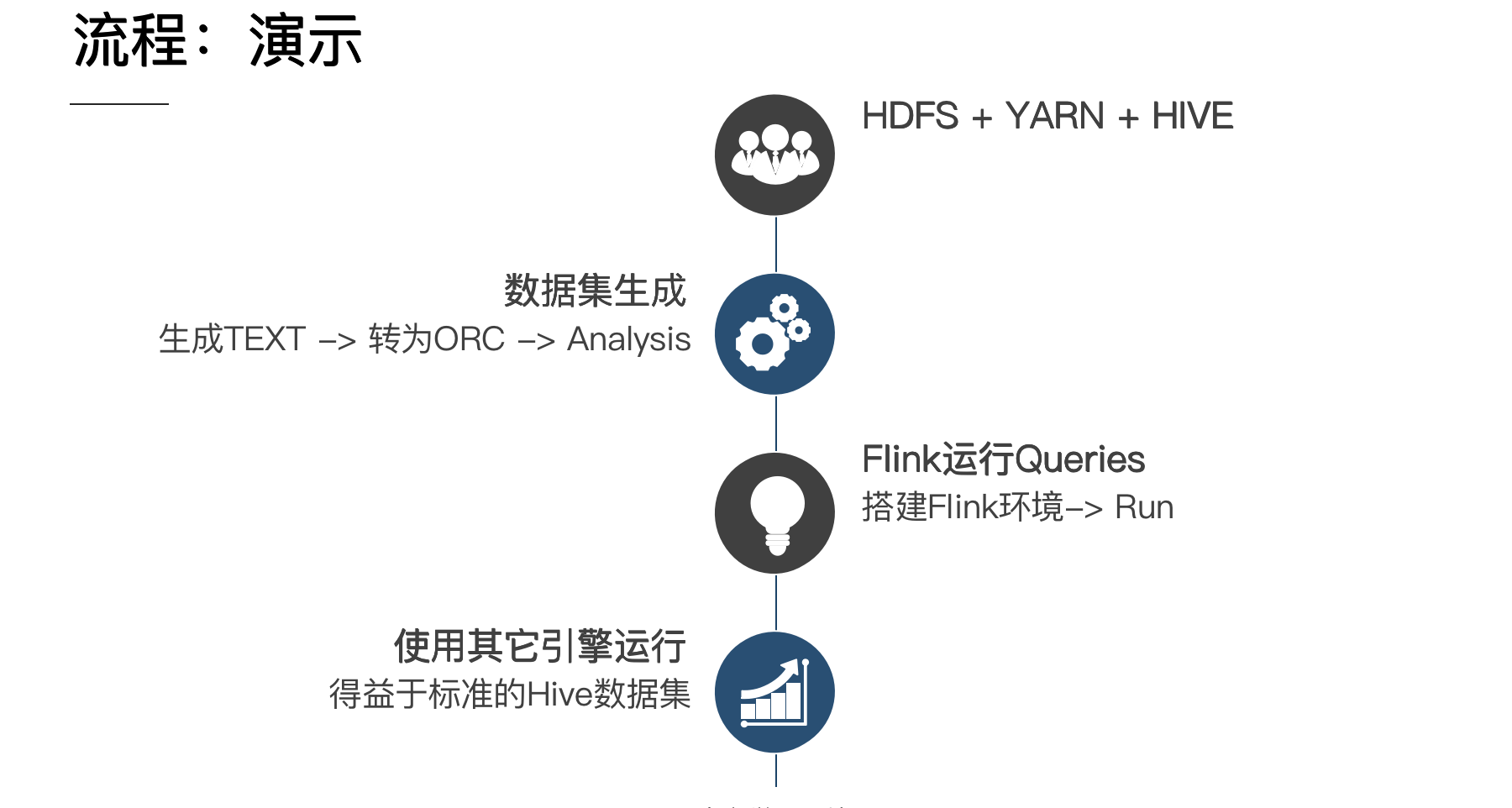
3. JDBC Driver (flink-sql-gateway and flink-jdbc-driver)
上面的 sql-client 存在一个问题,当前只支持 embedded 模式,不能 remote 模式,这样的话只能去集群上执行sql,这种模式不合适终端用户。所以开源了 flink-sql-gateway 和 flink-sql-driver 两个工程,这里简单介绍一下:
- flink-sql-gateway : 提供了 REST API 接口服务,允许其他程序方便的与 flink 集群交互,比如应用(e.g. Java/Python/Shell program, Postman)可以使用 REST API 提交查询、取消任务、获取结果等。
- flink-jdbc-driver : 支持 JDBC client 通过 REST API 连接至 flink-sql-gateway
当前 REST API 接口是内部接口集合,所以这里推荐用户通过 JDBC API 与 gateway 交互,flink-sql-gateway 会将会话信息存入内存,如果服务停止或者崩溃,所有属性信息会丢失,社区后续会进行优化。
下图是大概的演示流程: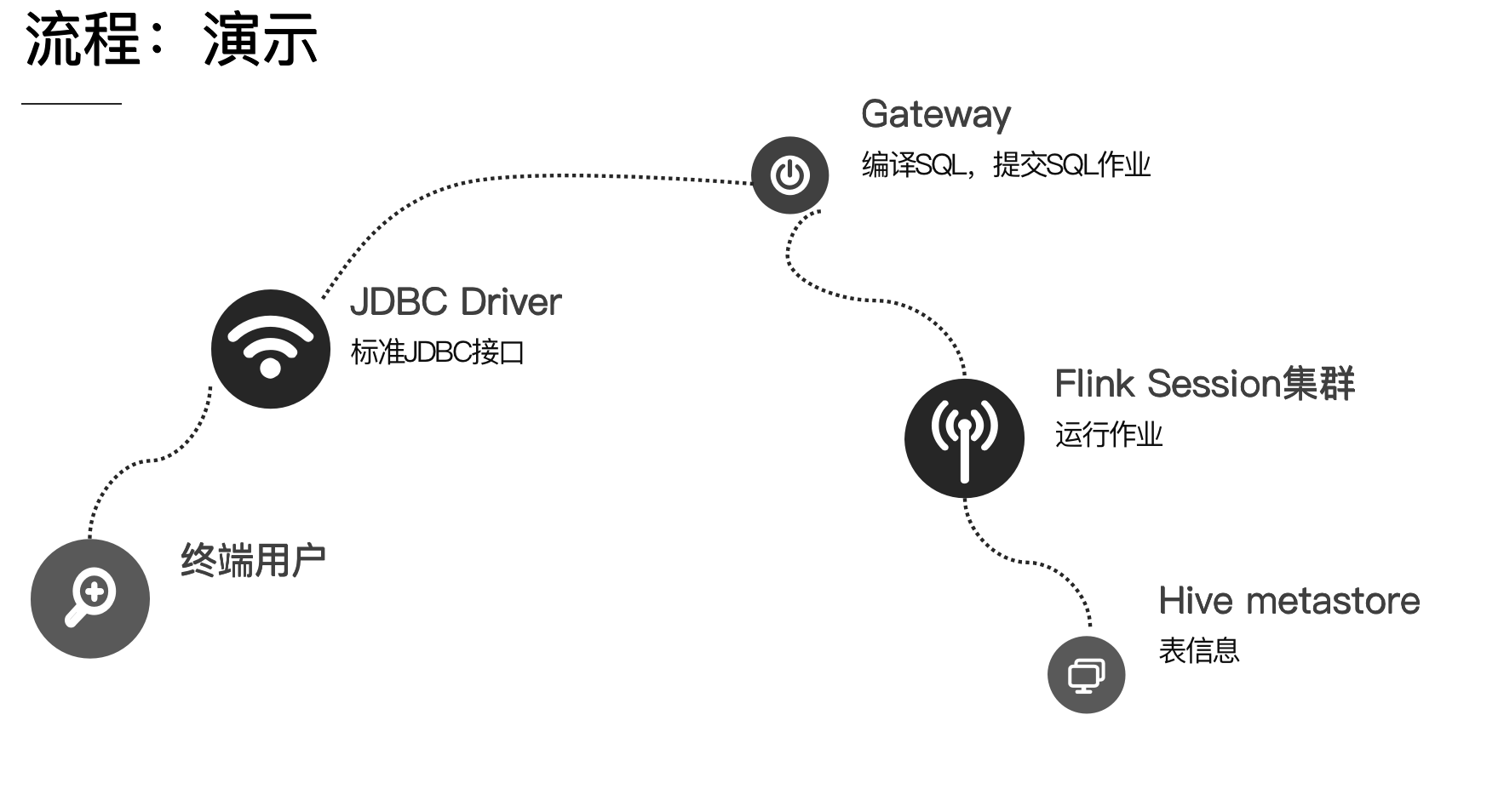
大致的过程就是终端用户通过标准的 JDBC 接口提交 SQL 至 Gateway,Gateway 启动了一个 thrift server 的进程,此进程用于编译 SQL、提交 SQL 作业,最终SQL 作业被提交至 Flink 集群中运行。
下面带着大家使用运行一下以上两个工程,工程下载地址:
git clone https://github.com/ververica/flink-sql-gatewaygit clone https://github.com/ververica/flink-jdbc-driver
以下步骤默认环境已具备 Flink 1.10 集群,且环境已配置 FLINK_HOME,具体的环境配置可参考:环境配置
- 下载以上两个工程至本地
- 配置 sql-gateway-defaults.yaml 文件中的 catalog 选项 ,其他项可以保持默认值无需配置。
启动 Gateway 进程
./bin/sql-gateway.sh # 该启动脚本后可跟参数#-d,--defaults <default configuration file> 指定定义的配置文件,默认为 gateway-default-conf#-h,--help 打印帮助信息#-j,--jar <JAR file> 导入到会话中的 jar 包,jar 包中可能包括:自定义函数、表执行的source 和 sink ,导入的包在当前会话中有效,可使用多次。# -l,--library <JAR directory> 新会话初始化时加载的 jar 包路径# -p,--port <service port> 客户端连接访问的端口,默认端口是 8083
Gateway 支持具体的配置项及其支持的 statements 可以参考 配置
构建 flink-jdbc-driver-(VERSION)jar 包
cd flink-jdbc-drivermvn clean install
将构建上步构建的 flink-jdbc-driver-(VERSION).jar 放置在 $HIVE_HOME/lib
运行 hive 的beeline并连接至 Flink SQL Gateway,可以在连接的 url 里指定 planner(比如blink 或 old),目前 Flink SQL Gateway 忽略用户名和密码,配置为空即可
beeline> !connect jdbc:flink://localhost:8083?planner=blink
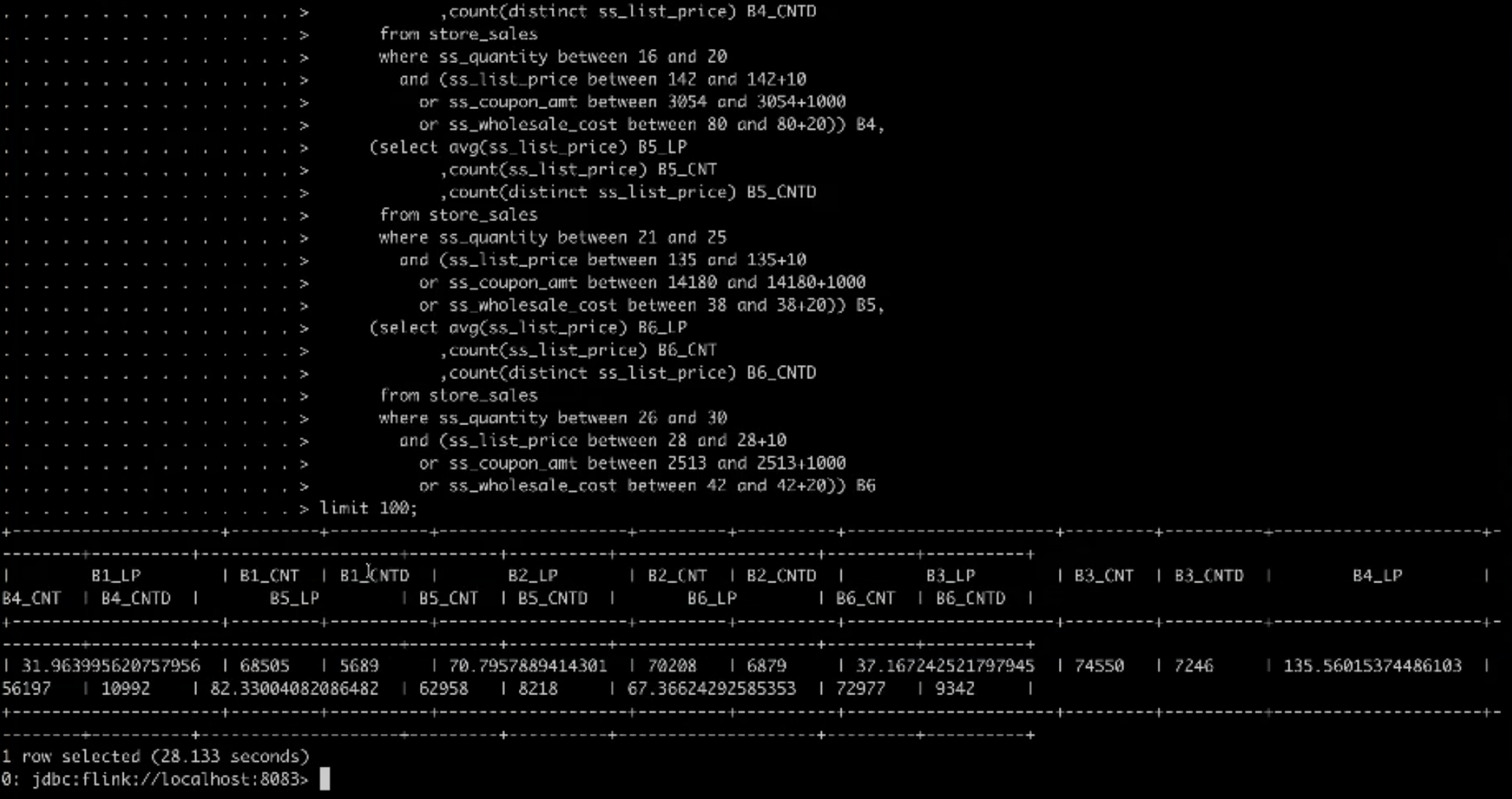
连上后执行此次执行以下 SQL
select count(1) as cnt from catelog_sales;-- start query 1 in stream 0 using template query28.tpl and seed 444293455select *from (select avg(ss_list_price) B1_LP,count(ss_list_price) B1_CNT,count(distinct ss_list_price) B1_CNTDfrom store_saleswhere ss_quantity between 0 and 5and (ss_list_price between 11 and 11+10or ss_coupon_amt between 460 and 460+1000or ss_wholesale_cost between 14 and 14+20)) B1,(select avg(ss_list_price) B2_LP,count(ss_list_price) B2_CNT,count(distinct ss_list_price) B2_CNTDfrom store_saleswhere ss_quantity between 6 and 10and (ss_list_price between 91 and 91+10or ss_coupon_amt between 1430 and 1430+1000or ss_wholesale_cost between 32 and 32+20)) B2,(select avg(ss_list_price) B3_LP,count(ss_list_price) B3_CNT,count(distinct ss_list_price) B3_CNTDfrom store_saleswhere ss_quantity between 11 and 15and (ss_list_price between 66 and 66+10or ss_coupon_amt between 920 and 920+1000or ss_wholesale_cost between 4 and 4+20)) B3,(select avg(ss_list_price) B4_LP,count(ss_list_price) B4_CNT,count(distinct ss_list_price) B4_CNTDfrom store_saleswhere ss_quantity between 16 and 20and (ss_list_price between 142 and 142+10or ss_coupon_amt between 3054 and 3054+1000or ss_wholesale_cost between 80 and 80+20)) B4,(select avg(ss_list_price) B5_LP,count(ss_list_price) B5_CNT,count(distinct ss_list_price) B5_CNTDfrom store_saleswhere ss_quantity between 21 and 25and (ss_list_price between 135 and 135+10or ss_coupon_amt between 14180 and 14180+1000or ss_wholesale_cost between 38 and 38+20)) B5,(select avg(ss_list_price) B6_LP,count(ss_list_price) B6_CNT,count(distinct ss_list_price) B6_CNTDfrom store_saleswhere ss_quantity between 26 and 30and (ss_list_price between 28 and 28+10or ss_coupon_amt between 2513 and 2513+1000or ss_wholesale_cost between 42 and 42+20)) B6limit 100-- end query 1 in stream 0 using template query28.tplinsert into partition_t select 1,2,'aa','bb';select * from partition_t where a = 'aa';

当前的 flink-sql-gateway 和 flink-jdbc-driver 还处于早期版本,如果大家有什么问题或者建议可联系社区的开发人员。4. Flink 1.11 展望
社区目前有很多的plan,但是个人认为 Flink 1.11 版本关于此部分优化的点主要集中在以下四个方面:
- 完善 Gateway,社区将继续优化 Flink-sql-gateway 和 jdbc-driver,尽可能的让大家在生产环境上真正的用起来。
- 向量化读,支持 parquet 和 Orc 1.x 的向量化读。
- Hive 语法兼容,进一步兼容 Hive 语法和语义,做到完全兼容,hive 的 sql 拿过来可以直接执行。
- N-Ary Operator,现在 flink 的 chain 都是放在 runtime 层做的,如果把 chain 在 table 层就可以做更多的事情和优化,如果知道上下游是什么,就可以避免更多的 shuffle 操作。
最后对 flink-sql-benchmark 配置参数进行简单的介绍
Table 层参数:
- table.optimizer.join-recorder-enabled =
true: 需要手工打开,目前各大引擎的 JoinRecorder 少有默认打开的,在统计信息比较完善时,是可以打开的,一般来说 recorder 错误的情况是比较少见的 - table.optimizer.join.broadcast-threshold =
10*1024*1024: 从默认值 1MB 调整至 10MB,目前 Flink 的广播机制还有待提高,所以默认值为1MB,但是在并发规模不是那么大的情况下,可以开到 10MB。 - table.exec.resource.default-parallelism = 800 : Operator 的并发设置,针对 10T 输入,建议开到 800 的并发,不建议太大的并发,并发越大,对系统各方面的压力越大。
TaskManager 参数分析:
- taskmanager.numberOfTaskSlots = 10 :单个 TM 里的 slot 个数。
- TaskManager 内存参数:Taskmanager 的内存主要分为三种,管理内存、网络内存、JVM 相关的其他内存,需要理解官方的文档,才能有效的设置这些参数。
- taskmanager.memory.process.size = 15000m :TaskManager 的总内存,减去其他内存后一般留给堆内存3-5GB 的内存。
- taskmanager.memory.managed.size = 8000m :管理内存,用于Operator 的计算,留给单个 slot 300 - 800MB 的内存是比较合理的。
- taskmanager.network.memory.max = 2200mb :Task点到点的通信需要4个Buffers,根据并发大概计算得出需要 2GB,可以通过尝试得出,Buffers 不够会抛出异常
网络参数分析:
- taskmanager.network.blocking-shuffle.type = mmap : Shuffle read 使用 mmap 的方式,直接靠系统管理内存,是比较方便的形式。
- taskmanager.network.blocking-shuffle.compression.enabled = true : 使用压缩,这个参数是批流复用,强烈建议给批作业开启压缩,不然瓶颈就会在磁盘。
调度参数分析:
- cluster.evenly-spread-out-slots = true :在调度Task时均匀调到到每个 TaskManager 中,这有利于使用所有资源。
- jobmanager.exection.failover-strategy = region : 默认全局重试,需打开region重试才能enable单点的failover。
- restart-strategy = fixed-delay : 重试策略需要手动设置,默认是不重试的。

若有收获,就点个赞吧
0 人点赞
